文章目錄
- 一、物理內存和磁盤交換數據的最小單位
- 二、操作系統如何管理內存
- 三、文件的頁緩沖區
- 四、基數樹or基數(字典樹)
- 五、總結
一、物理內存和磁盤交換數據的最小單位
我們知道系統當中除了進程管理、文件管理以外,還有內存管理
內存的本質就是對數據的一種臨時存取,所以我們可以把內存看作一個非常大的緩沖區就可以了。
當內存需要數據的時候,可以直接從磁盤中讀取,不需要的時候可以直接釋放或者與磁盤進行交換
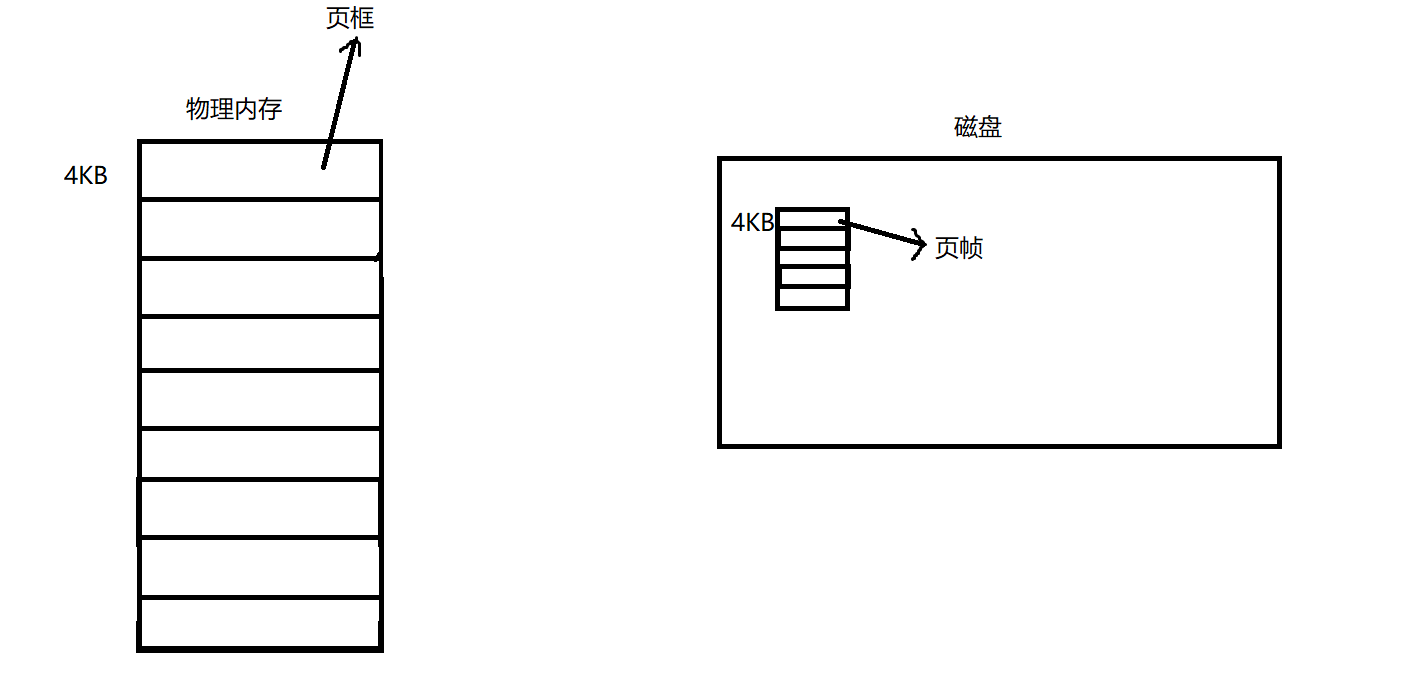
為了方便物理內存與磁盤進行交互,我們會將物理內存看作一個一個的小格子,內存也是一種線性的。這個一個個的小單位是4KB
像我們平時形成的可執行程序也是一個一個的以4KB為單位的小的數據段。
也就是說,如果一個可執行程序是4M,那么其實這個可執行程序也是4KB,4KB進行劃分的。這是因為文件系統中數據塊的大小就是4KB。
所以可執行程序在文件系統中天然就是每讀一個塊就是4KB
而我們就將物理內存的這一個個4KB就叫做頁框,將磁盤當中的這一個個4KB叫做頁幀
那么為什么必須是4KB,可以是1KB,2KB嗎?
當然是可以的,不過這樣我們需要修改操作系統的底層源代碼。最終重新編譯操作系統
而我們為什么要選擇4KB呢,我們的文件壓根可能就沒有4KB。可能就是1KB,那么那3KB就浪費了。即便某個文件只有一個比特位,我們也不能只拿這1個比特位,必須將這4KB全部加載進來。
我們知道磁盤本身就是一個機械設備,注定了它IO時候訪問的周期比較長,即比較慢,一次4KB很顯然要比一次1KB效率要更高一些。(因為只需要磁頭定位一次即可。比要定位四次快得多)
其次就是計算機中存在著局部性原理:在訪問某些代碼和數據時候,它附近的代碼和數據也有很大概率被訪問。而且因為機械運動才是慢的主要矛盾,有可能我們的文件只有100字節,但是我們也要讀取4KB,這兩個的效率其實差不多。而且100字節可能更加分散,需要更加精細
所以就有了基于局部性原理的預加載機制
它可以減少IO的次數,從而對系統整體進行提速 ----硬件
基于局部性原理,有了預加載機制 ----軟件
注意這里的4KB是物理內存和磁盤交換數據的單位
二、操作系統如何管理內存
在操作系統層面上,要管理內存,肯定會用到虛擬地址。
而操作系統管理內存,也肯定是能看到內存的物理地址的。
那么操作系統如何管理內存呢??
先描述后組織
所以在操作系統里面肯定有一個東西
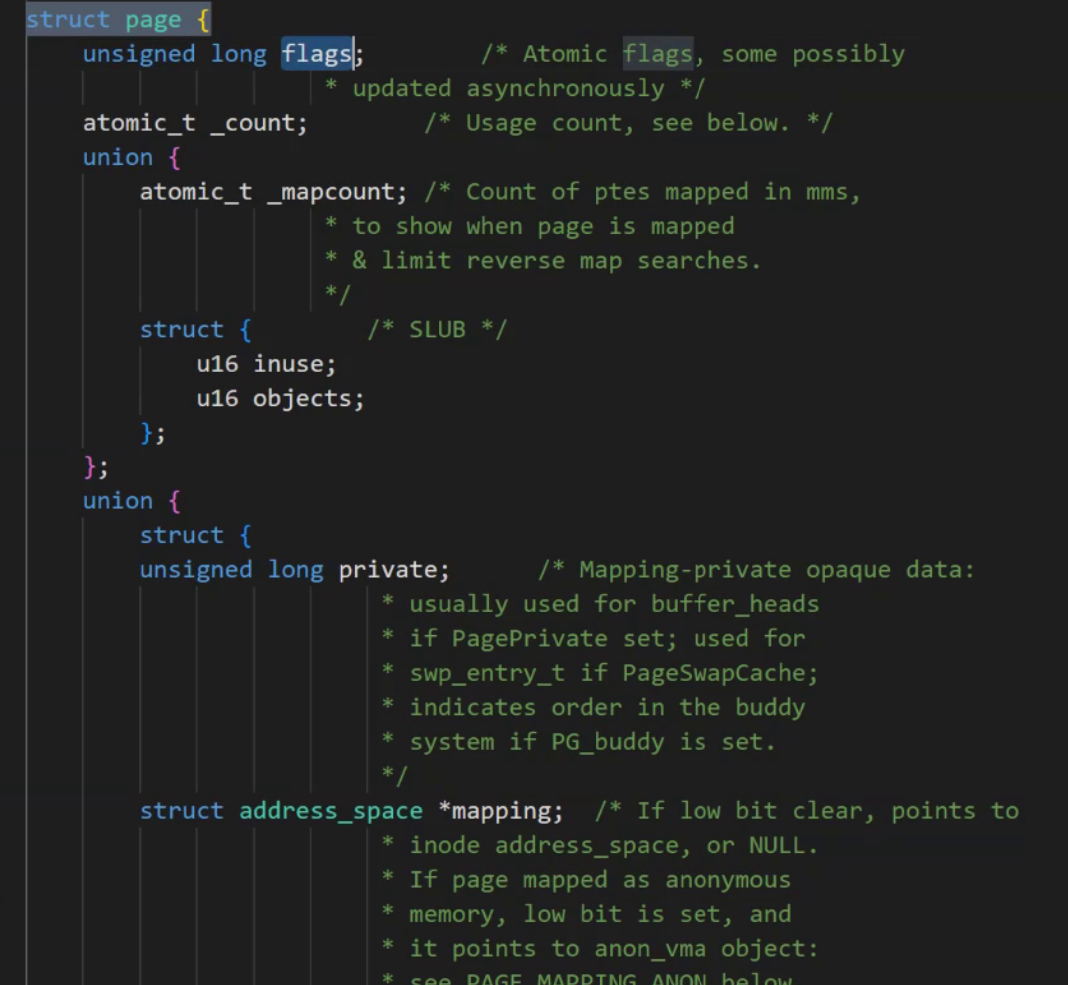
struct page {//page頁必要的屬性信息。 };? 像我們的系統如果有4GB的內存的話,那么最終會存在1024*1024*\1024*4 /4/1024,即約100萬多個頁。
然后我們在操作系統內核里面直接定義
struct page mem_array[1048579]所以我們發現對內存的管理變為了對數組的管理。
即先描述后組織
而我們知道數組是天然有下標的,所以我們就天然的有了頁號的概念
所以以后當有了一個地址以后,我們就可以知道它是在哪一個頁號上的
因為4KB,需要用12位
所以我們只需要將這個低12位全部清零即可
比如0x11223344,我們直接讓他按位與上0xFFFFF000
所以它最終的頁號就是0x11223000
所以我們就直接用這個頁號就找到了對應的屬性
所以,我們要訪問一個內存,我們只需要先直接找到這個4KB對應的Page,就能在系統中找到對應的物理頁框
在我們系統中,所有申請內存的動作,都是在訪問內存Page數組
而且這個Page結構體不會很大,因為會有一個Page類型的數組,它最終也是要在內存中存放著的,所以它不能太大,所以這也再次說明了前面的頁框大小不能太小,因為它越小,這個數組就越大,占據的內存空間越大。
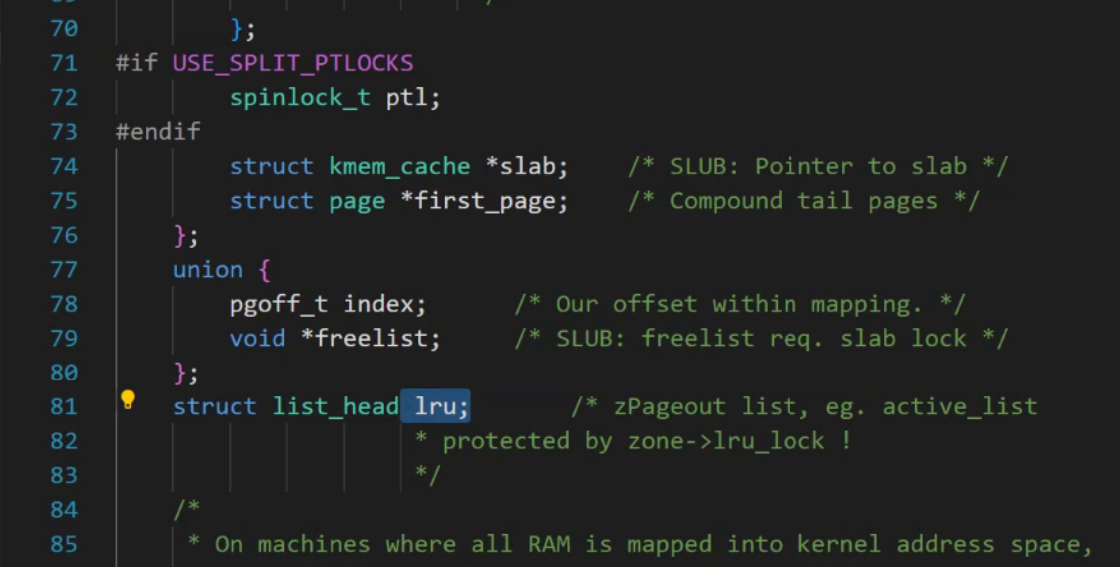
如下所示,它的page里面都是一些union,這個flags代表它的使用狀態。(每一個比特位都有它的含義,比如當我要使用這個頁框的時候,我們只需要判斷其中的一個標志位是否為0,如果為0那么改為1,這個內存就被使用了)。下面的這個count代表的就是引用計數。用來判斷該內存被多少人使用。
同時在這個Page中還有一個lru,它是最近最少使用。也就是說操作系統會將最近最少使用的東西拿出來給刷新出去。
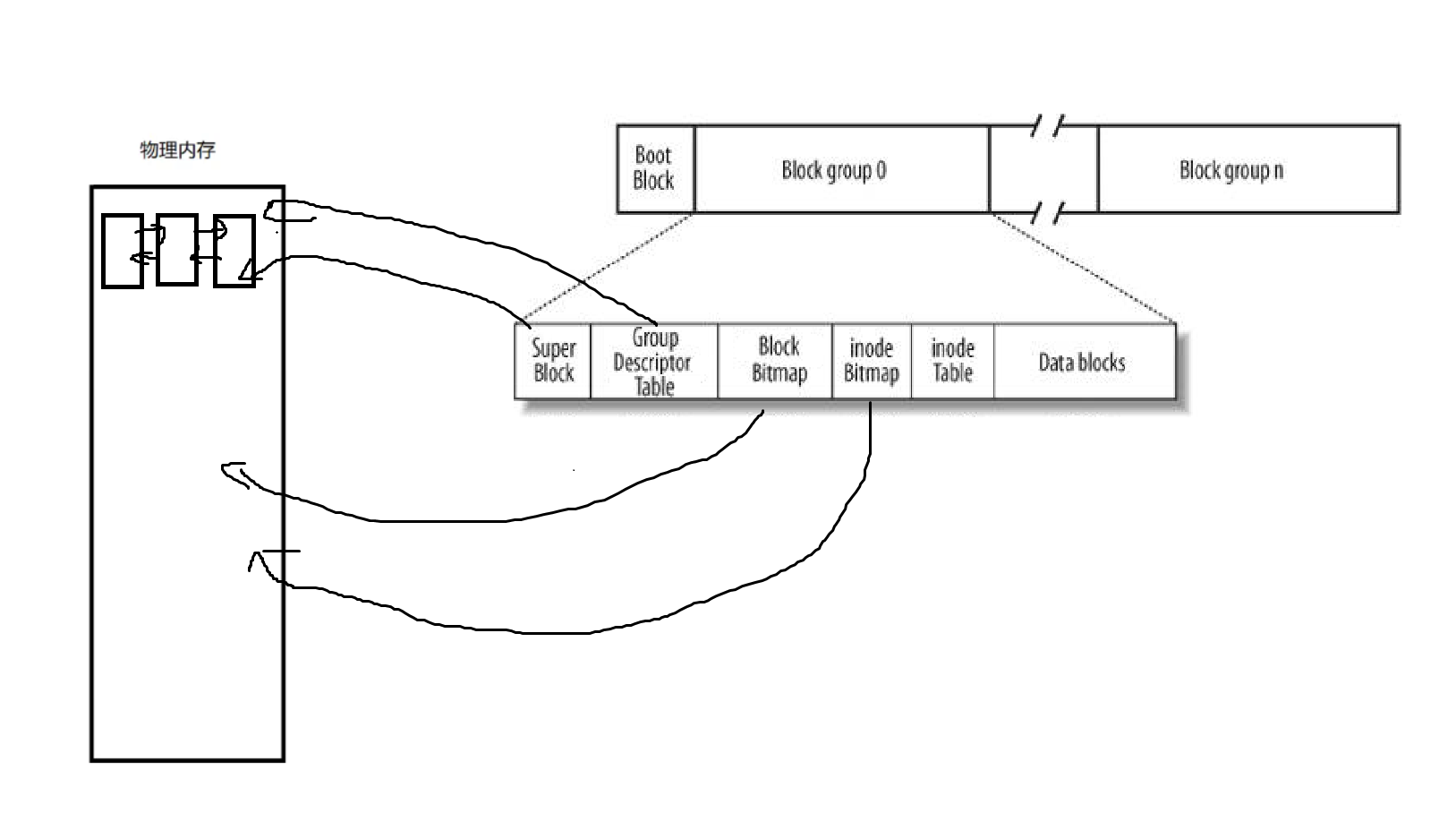
三、文件的頁緩沖區
如下圖所示
在我們開機的時候,不僅僅是為我們創建了進程了,內存管理做好了等等。
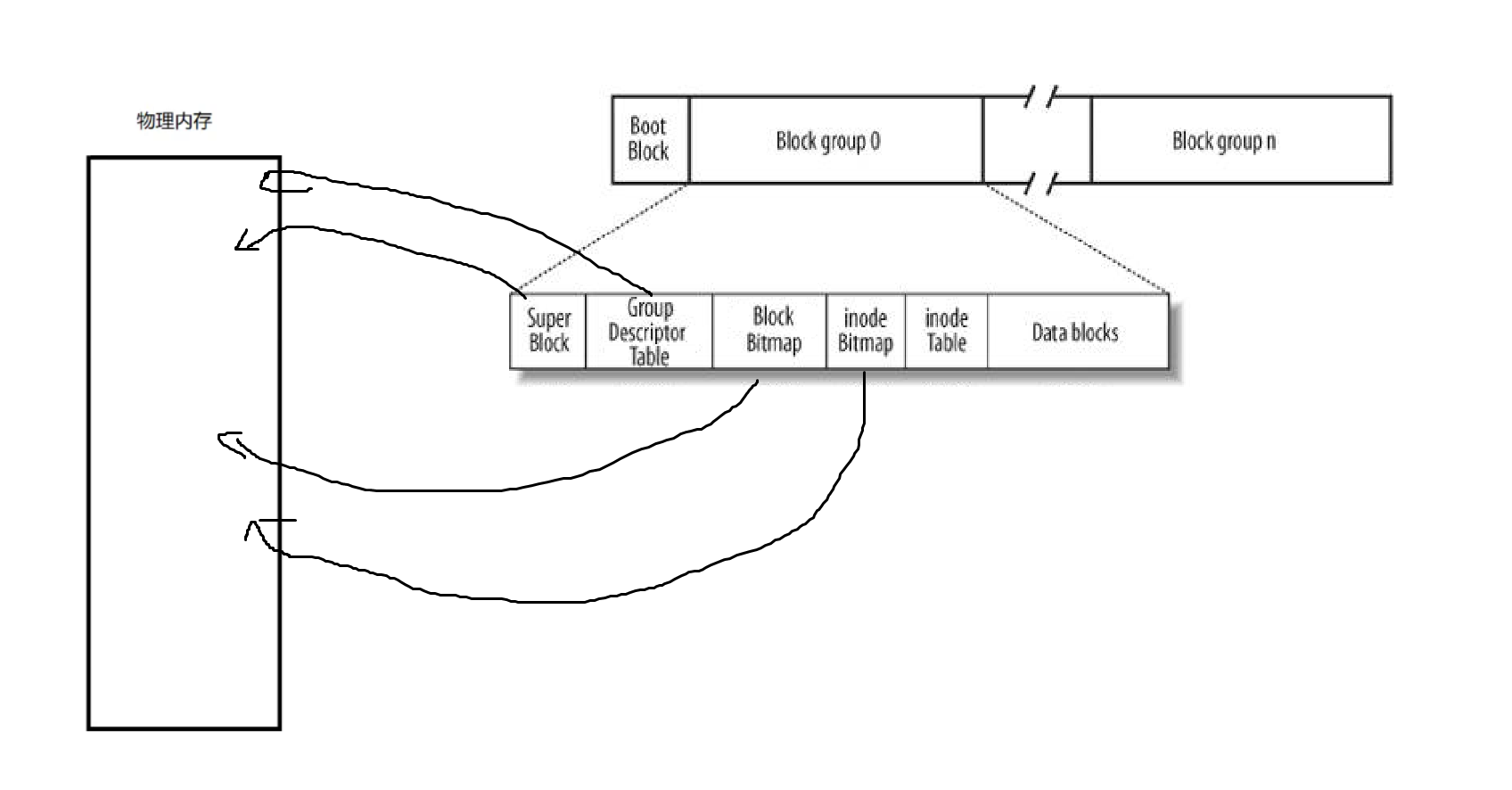
還會將我們文件系統相關的數據都已經預加載到內存了,尤其是Super Block等這些文件系統相關的信息
我們可能會說,那在操作系統上存在著很多分區,這也無所謂,因為可以用鏈表將他們組織起來
如下是一個操作系統,里面有進程、files_struct等內核數據結構
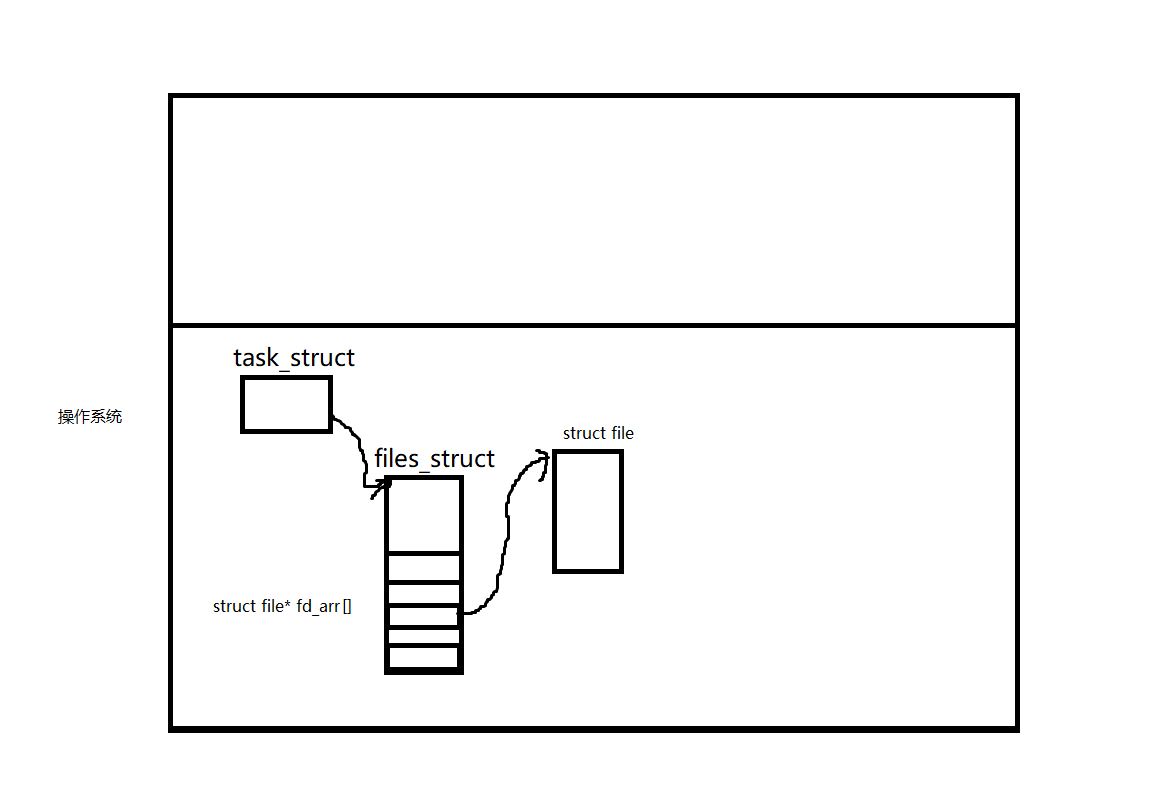
所以最終操作系統上層用的都是fd文件描述符
當我們在打開文件的時候,我們必須知道這個文件的路徑+文件名,然后我們就能讀取當前目錄的數據塊,從而找到文件的inode
因為這些inode Bitmap,Block Bitmap已經被提前加載到內存中了。然后我們確認這個inode是否存在,如果存在,直接將這個inode給加載進來,最后也就能讀取到對應的數據塊了。
以上都是一個文件被加載到內存當中的過程。
而現在我們關心的是這兩件東西:文件的屬性+文件的內容
所以我們需要做的就是,文件的屬性如何被拿到。
我們知道文件的屬性都在inode里面,struct file里面也有文件的屬性,不過只有少量的屬性。
所以我們會創建一個內核數據結構,struct inode,然后直接將磁盤中的inode里面的內容填寫到這個內核數據結構中。而這個struct file是可以找到struct inode的
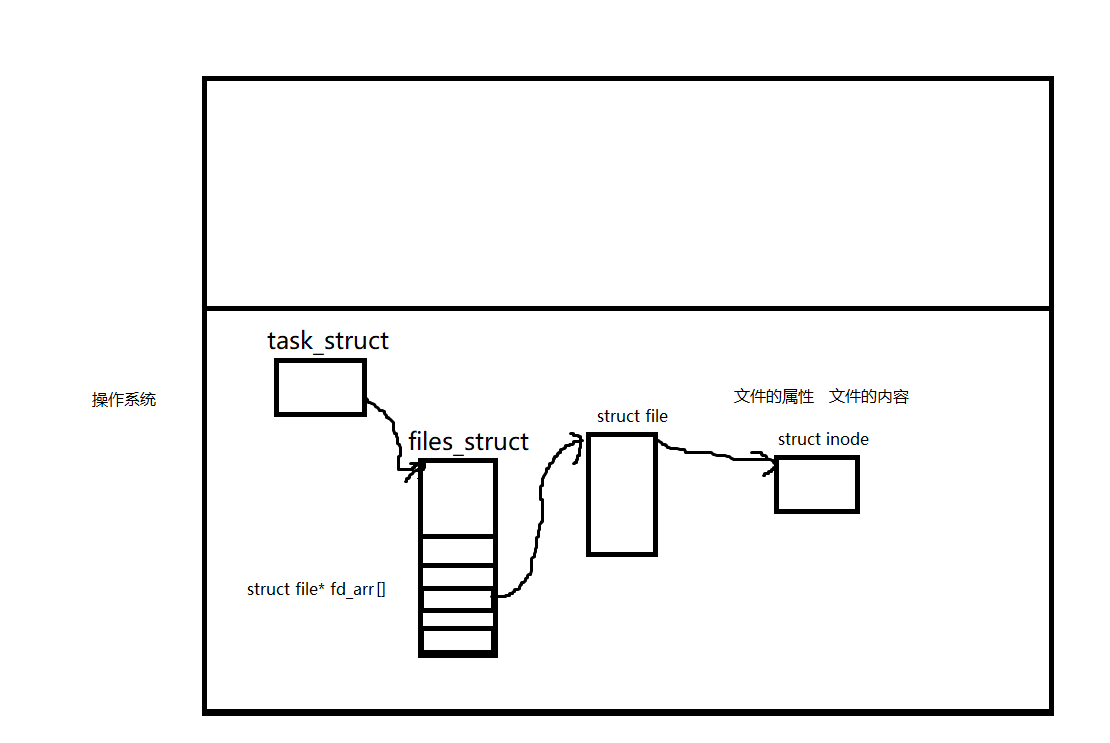
可是我們之前說過,我們在上層調用fprintf以后,就會通過這個fd,往對應進程中找到對應的文件描述符,從而去找到struct file結構體。那么在這里如何將數據寫到磁盤中呢?
我們現在只能去找到文件的屬性
其實在struct file里面還存在一個結構叫做address_space。
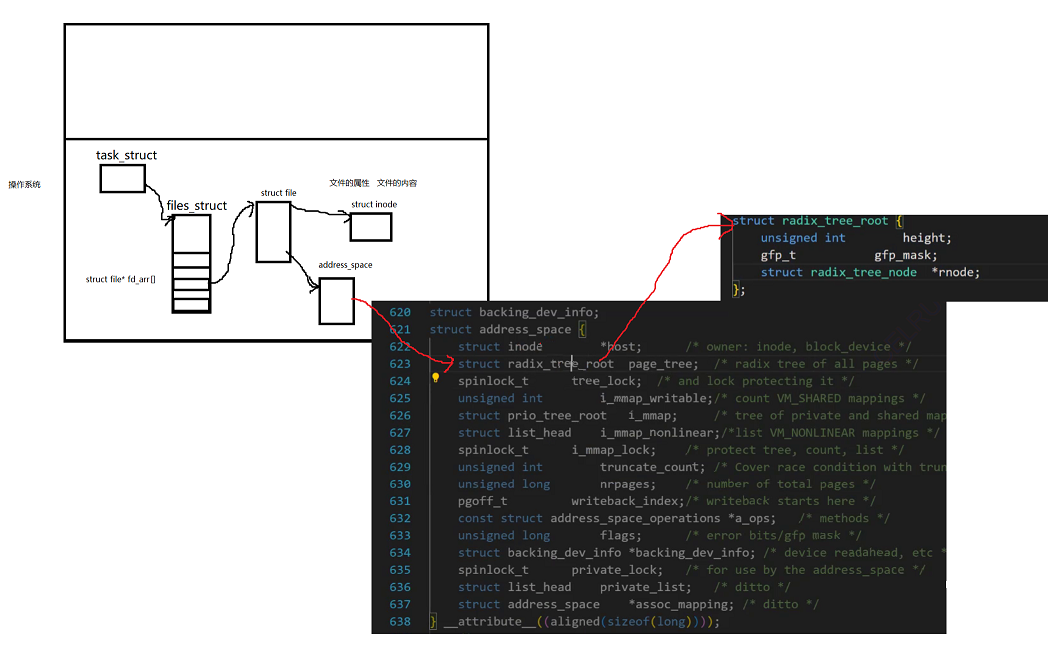
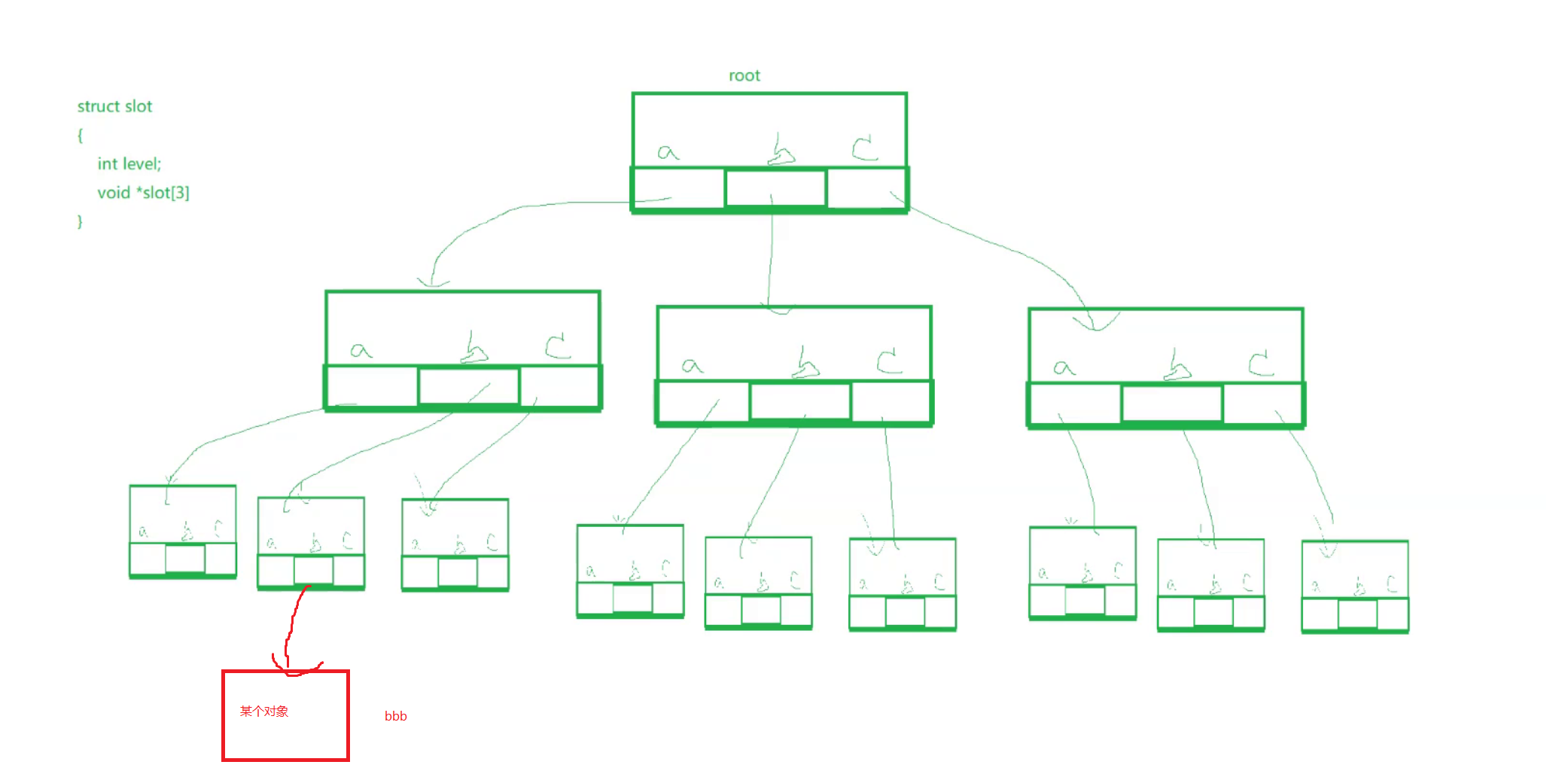
而radix_tree_root它是一顆多叉樹
它結點里面是這樣的結構
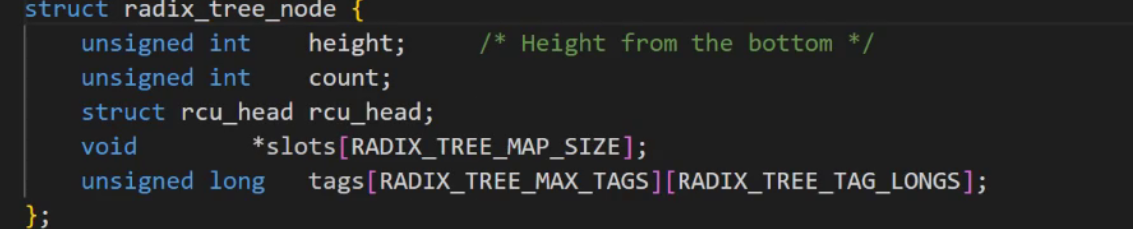
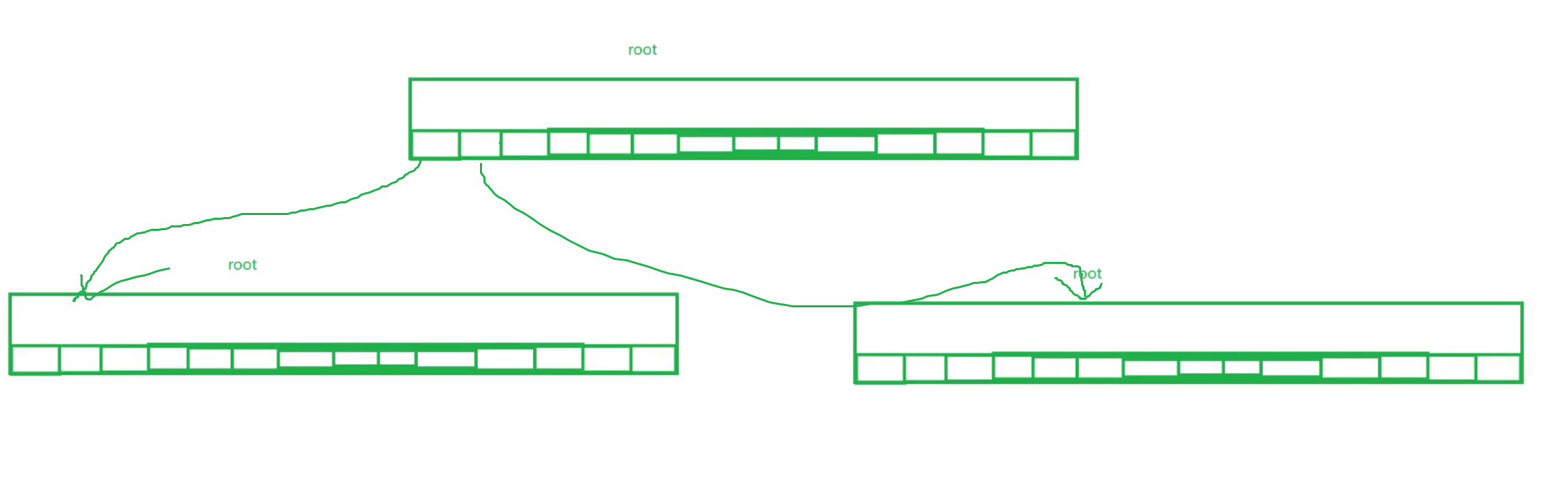
如下圖所示,它的每一個葉子結點都指向一個struct page對象,而這樣的每一個struct page對象都對應著4KB的內存大小
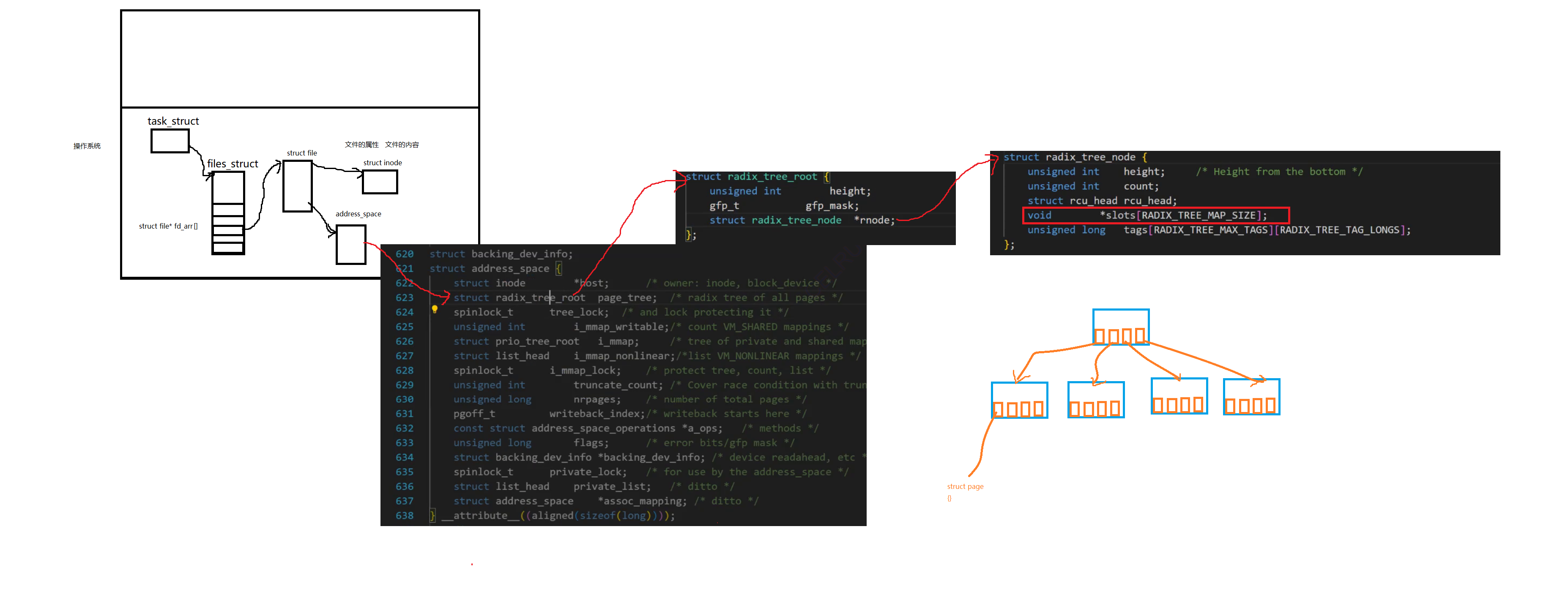
所以說當我們將數據拷貝到struct file以后,就會找到address_space,然后一路找到這棵樹的葉子節點中,最終通過這個葉子節點的struct page去管理對應的內存
而上面這個就是文件的頁緩沖區
四、基數樹or基數(字典樹)
在Linux中,我們的每一個進程,打開的每一個文件都要有自己的inode屬性和自己的文件頁緩沖區
什么是字典樹呢?
類似于下面的26叉樹每個結點可以指向26個字母
我們可以用下面這個3個字母簡單的來代替
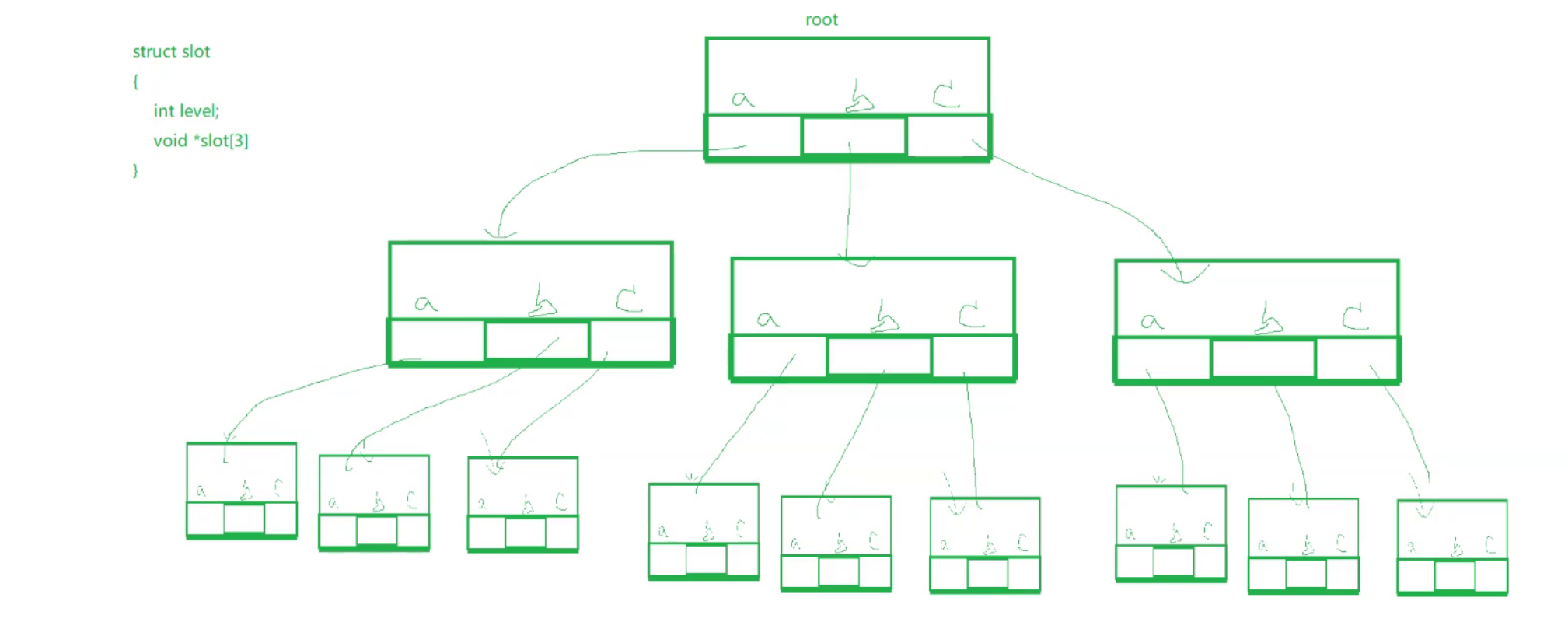
當我們要查找某個對象的時候,我們可以用bbb來作為key值,從而找到某個對象
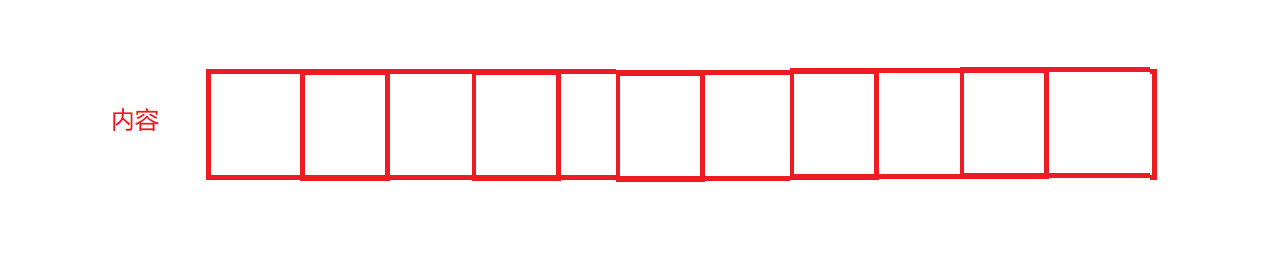
文件的內容按照4kb是有偏移量的
比如一個10MB的文件,它占據的內存就是10*1024*1024
而文件的內容是按照4KB一塊一塊的進行存儲著的
而這剛好就是2560塊
所以我們就可以給他進行編號[1,2560]
而每一塊乘以4KB就是他們的相對于原始數據的偏移量
所以前面的這一批數字[1,2560]它剛好每一個編號都是一個int類型的
而int類型是占據32位的
比如有一個數據是0xFF FF FF FF
這個整數我們可以將第一個數字看作一個b,第二個數字看作一個c,第三個數字看作一個a
如果我們可以像前面那樣構建出一顆字典樹
我們就可以利用這個文件的內容所在的區域
就可以利用字典樹,找到對應的page的映射關系。
所以當我們進行讀寫文件的時候,從開頭讀,每一個讀寫都有偏移量。
根據這個偏移量,就可以將這個偏移量轉化為樹中的某一個page
這樣我們就可以根據它的page偏移量,就確定先刷新哪一個page,后刷新哪一個page,就可以讓文件有序的進行刷新了
最終我們的數據就成功的寫入到了內存中
當我們將數據寫入到了內存中以后,后序數據從內存如何寫入到磁盤,就不是操作系統需要關心的事情了,這就導致了當我們突然斷電以后,內存里面的數據都無法保存起來
上面的這個從內存刷新到磁盤當中的過程就是驅動層的事情了, 需要IO子系統來進行完成
五、總結
總之上面的過程其實就是下面的這張圖
也就是說,操作系統里面也有一個文件緩沖區,最后它會被刷新到磁盤上去
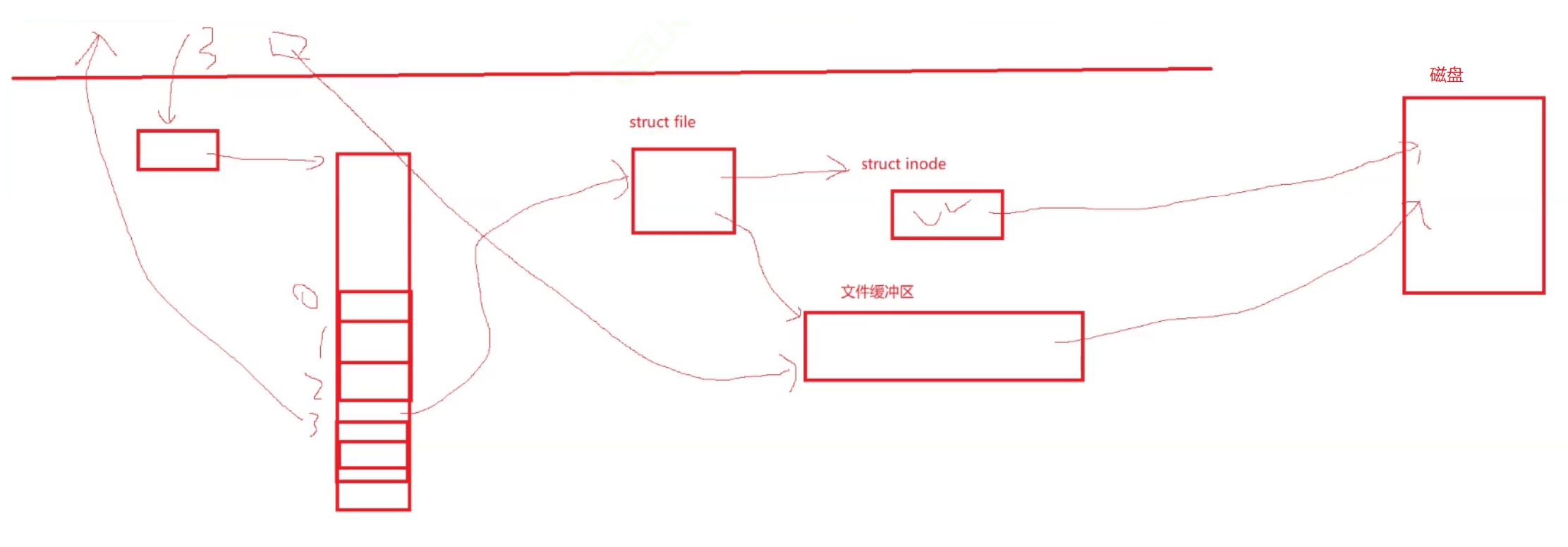
上面的過程,我們就把打開文件和文件系統的文件 產生關聯了!
我們也可以發現,這里一共要經歷三次拷貝,第一次將數據寫入到C語言緩沖區中,第二次將數據從C語言緩沖區寫入到文件緩沖區中,第三次是寫在磁盤當中去

![[香橙派]orange pi zero 3 燒錄Ubuntu系統鏡像——無需HDMI數據線安裝](http://pic.xiahunao.cn/[香橙派]orange pi zero 3 燒錄Ubuntu系統鏡像——無需HDMI數據線安裝)




性能測試)











隨機森林分類模型)
