Gemini
【一句話總結,對標GPT4,模型還是transformer的docoder部分,提出三個不同版本的Gemini模型,Ultra的最牛逼,Nano的可以用在手機上。】
谷歌提出了一個新系列多模態模型——Gemini家族模型,包括Ultra,Pro,Nano(1.5B Nano-1,3.25BNano-2)三種尺寸(模型由大到小)。在圖像、音頻、視頻和文本理解方面都表現出現,Gemini Ultra在32個benchmarks實現了30個sota。在MMLU中甚至達到了人類專家的性能。
Bard具體使用體驗待更新…
1. 引言
Gemini的目標:建立一個模型,該模型不僅具有跨模態的強大通用能力,而且在每個領域都具有尖端的理解和推理性能。
Gemini 1.0 包括三個版本:Ultra 適用于高度復雜的任務,Pro 適用于高性能和大規模部署的場景,Nano 適用于設備上的應用。
Gemini Ultra,在文本推理上實現10/12,圖片理解9/9,視頻理解6/6,語音識別和翻譯5/5。

AlphaCode 團隊基于Gemini構建出AlphaCode2,在 Codeforces 競技編程平臺的參賽者中名列前 15%,與名列前 50%的前代產品相比有了很大提高。
此外,還發布了Gemini Nana【針對邊緣計算設備的,這個蠻有意思的,想體驗一下。】
在下面的章節中,首先概述了模型架構、訓練基礎設施和訓練數據集。然后,介紹了 Gemini 模型系列的詳細評估,其中包括文本、代碼、圖像、音頻和視頻方面經過充分研究的基準和人類偏好評估–其中包括英語性能和多語言能力。討論了作者負責任的部署方法2,包括影響評估、制定模型政策、評估以及在部署決策前減輕危害的過程。最后,討論了 Gemini 的廣泛影響、局限性及其潛在應用–為人工智能研究與創新的新時代鋪平道路。
2. 模型架構
模型同樣使用的Transformer的Decoder部分,對模型架構和的模型優化進行了改進。最大支持32K上下文。

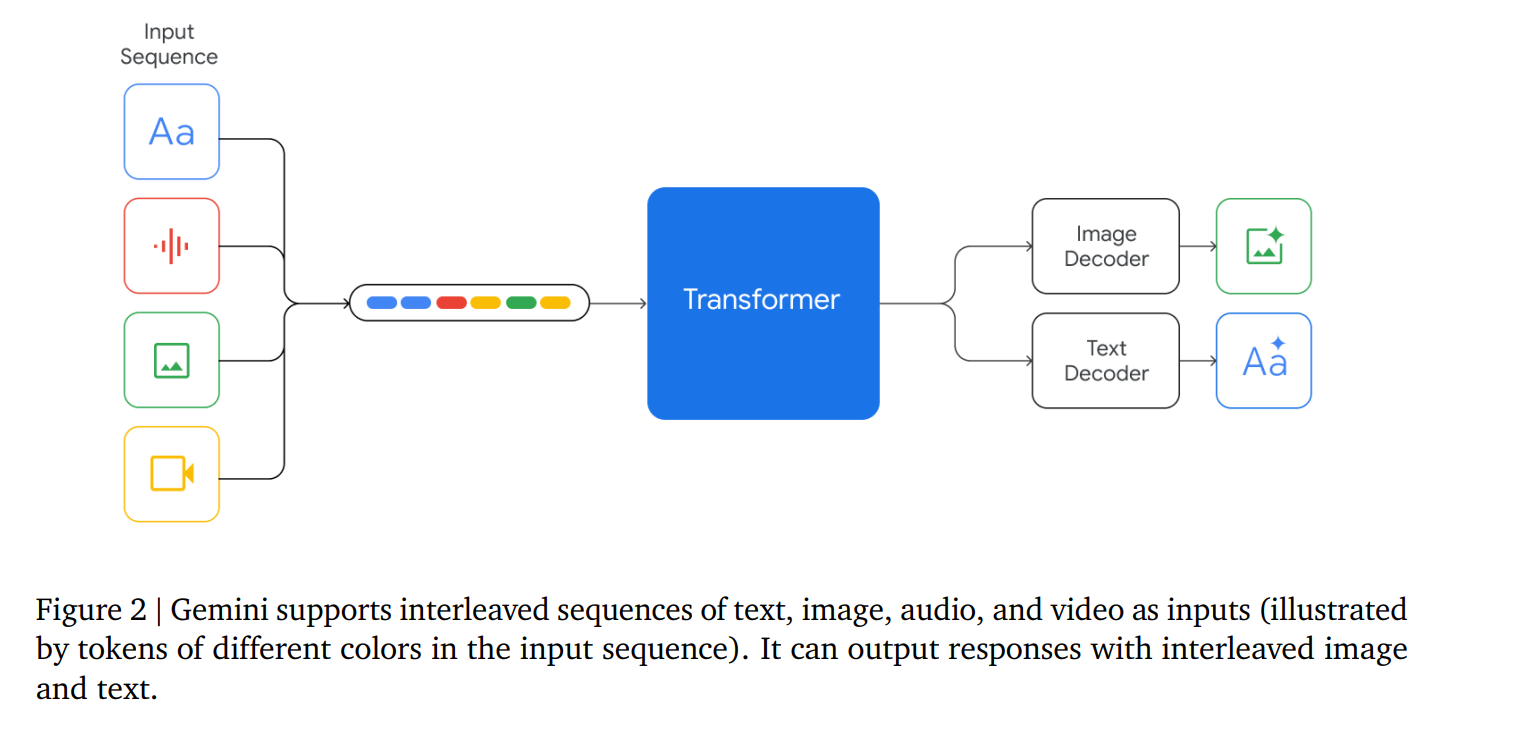
Gemini的輸入可以是文字與各種音頻和視覺的組合(如自然圖像、圖表、截圖、PDF 和視頻),輸出是為文本和圖像。The visual encoding of Gemini models is inspired by our own foundational work on Flamingo (Alayrac et al., 2022), CoCa (Yu et al., 2022a), and PaLI (Chen et al., 2022), with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens (Ramesh et al., 2021; Yu et al., 2022b).【視覺編碼是來源于下面這些工作的。】
視頻理解是通過將視頻編碼為大型上下文窗口中的幀序列來實現的。視頻幀或圖像可與文本或音頻自然交錯,作為模型輸入的一部分。
Gemini 可以直接從通用語音模型(USM)(Zhang 等人,2023 年)特征中獲取 16kHz 的音頻信號。這使得該模型能夠捕捉到音頻被簡單地映射到文本輸入時通常會丟失的細微差別(例如,請參閱網站上的音頻理解演示)
3. 訓練基礎設施
用的是Google自己的TPU資源。【圖片來自Gemini的blog,每一次看都感覺很震撼……大力出奇跡】

4. 訓練數據集
預訓練數據集使用了來自網絡文檔、書籍和代碼的數據,還包括圖像、音頻和視頻數據
tokenizer使用的是SentencePiece tokenizer。并且發現,在整個訓練語料庫的大量樣本上訓練標記化器可以提高推斷詞匯量,從而提高模型性能。例如,發現 Gemini 模型可以有效地標記非拉丁文【比如漢語】腳本,這反過來又有利于提高模型質量以及訓練和推理速度。用于訓練最大模型的token數量是按照霍夫曼等人(2022)的方法確定的。對于較小的模型,則使用更多的token進行訓練,以提高給定推理預算下的性能,這與 Touvron 等人(2023a)所提倡的方法類似。
我們使用啟發式規則和基于模型的分類器對所有數據集進行質量過濾。我們還進行了安全過濾,以去除有害內容。我們從訓練語料庫中過濾評估集。最終的數據混合物和權重是通過對較小模型的消減確定的。我們進行階段性訓練,以便在訓練過程中改變混合物的組成–在訓練接近尾聲時增加領域相關數據的權重。我們發現,數據質量對高性能模型至關重要,并認為在尋找預訓練的最佳數據集分布方面仍存在許多有趣的問題。
5. Evalution
Gemini 模型是原生的多模態模型,因為它們是跨文本、圖像、音頻和視頻進行聯合訓練的。一個懸而未決的問題是,這種聯合訓練是否能產生一個在每個領域都有強大能力的模型–即使與狹隘地針對單一領域的模型和方法相比也是如此。我們發現情況確實如此:在廣泛的文本、圖像、音頻和視頻基準測試中,Gemini 樹立了新的技術典范。
5.1. Text
5.1.1. Academic Benchmarks
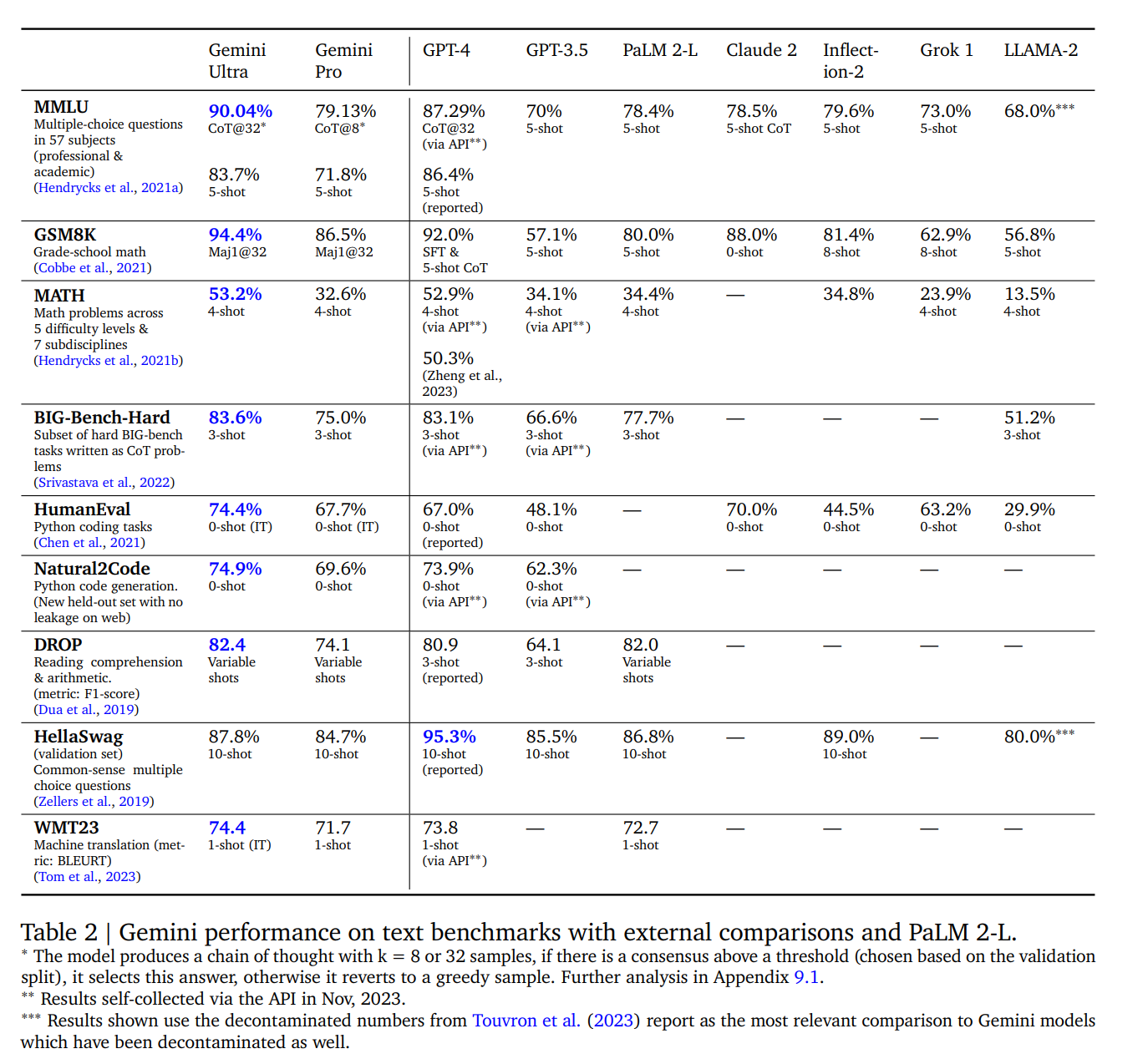
在一系列基于文本的學術基準測試中,我們將 Gemini Pro 和 Ultra 與一套外部 LLM 和我們之前的最佳模型 PaLM 2 進行了比較,測試內容包括推理、閱讀理解、STEM 和編碼。我們在表 2 中報告了這些結果。總的來說,我們發現 Gemini Pro 的性能優于 GPT-3.5 等推理優化模型,并可與現有的幾種能力最強的模型相媲美,而 Gemini Ultra 則優于目前所有的模型。
我們發現,當 Gemini Ultra 與考慮到模型不確定性的思維鏈提示方法(Wei 等人,2022 年)結合使用時,其準確率最高。該模型會產生一個包含 k 個樣本(例如 8 個或 32 個)的思維鏈。如果存在高于預設閾值的共識(根據驗證分割選擇),它就會選擇這個答案,否則就會返回到基于最大似然選擇的貪婪樣本,而不進行思維鏈。【這個CoT@32….挺有意思】
5.1.2. Trends in Capabilities
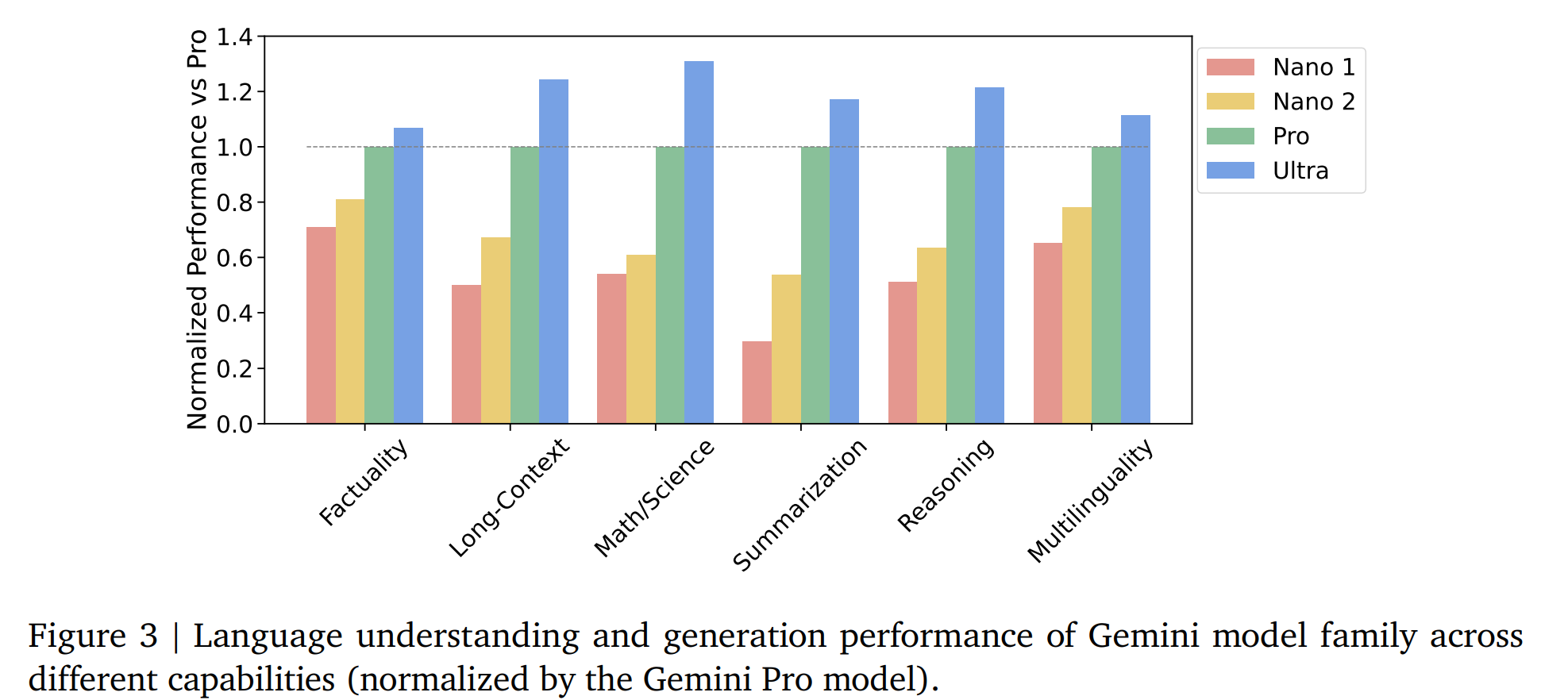
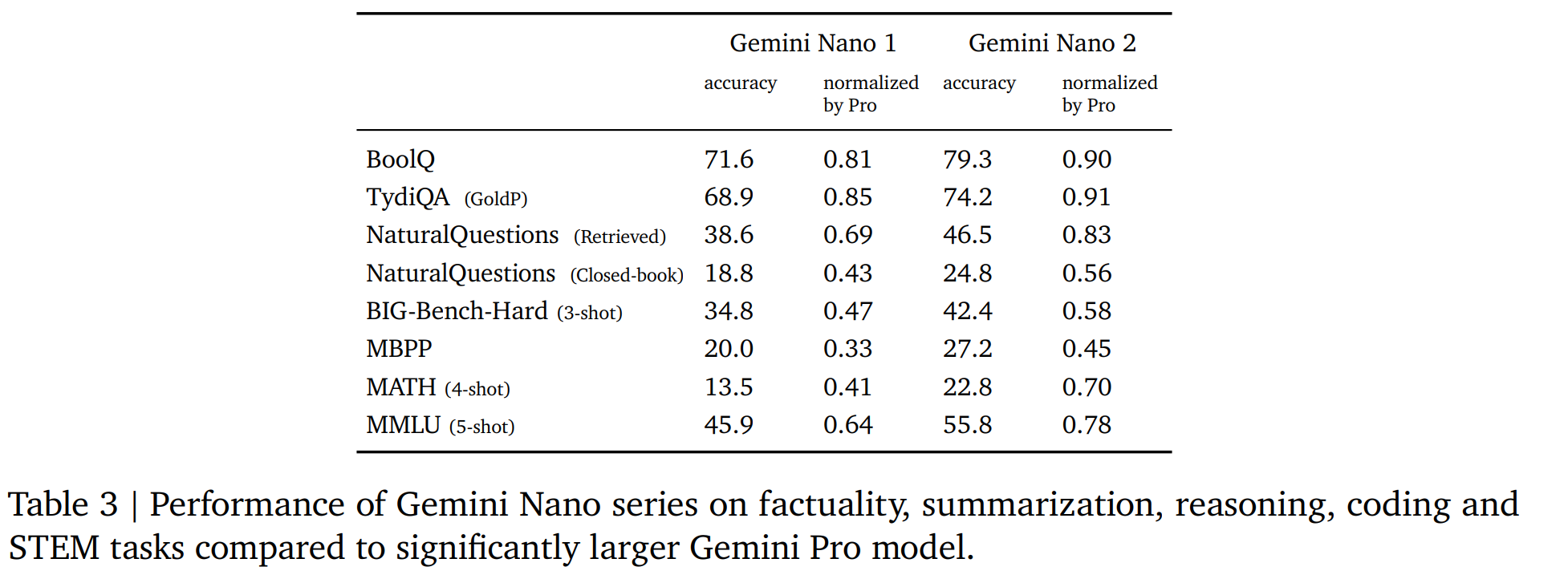
5.1.3. Nano
【個人感覺Nano是最友好的,Nano-1:1.8B的參數,Nano-2:3.25B的參數】
5.1.4. Multilinguality
多語言翻譯
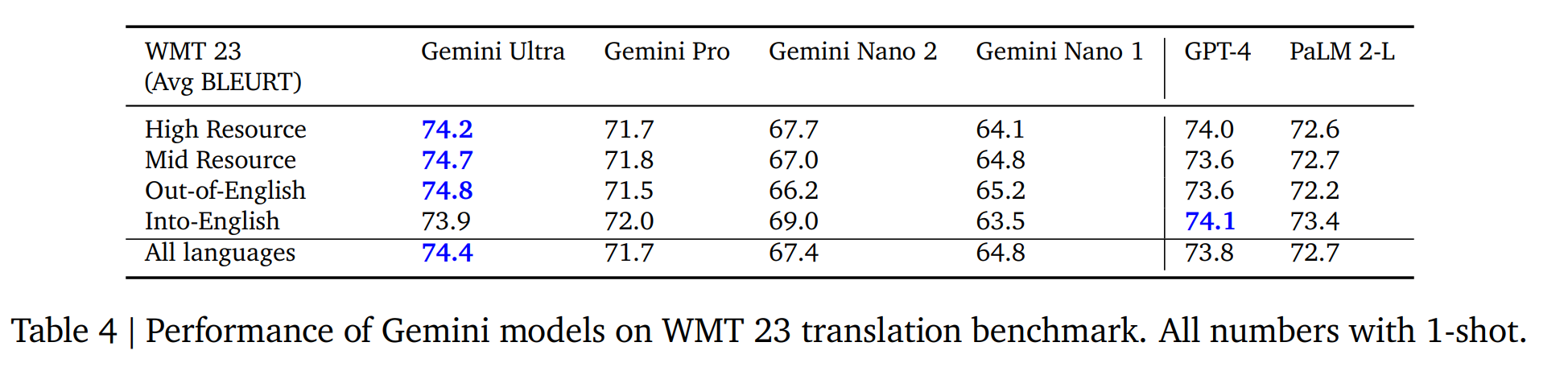
多語言數學與總結

5.1.5. Long Context
Gemini是在32768個token的情況下進行訓練的【seq_len = 32768】
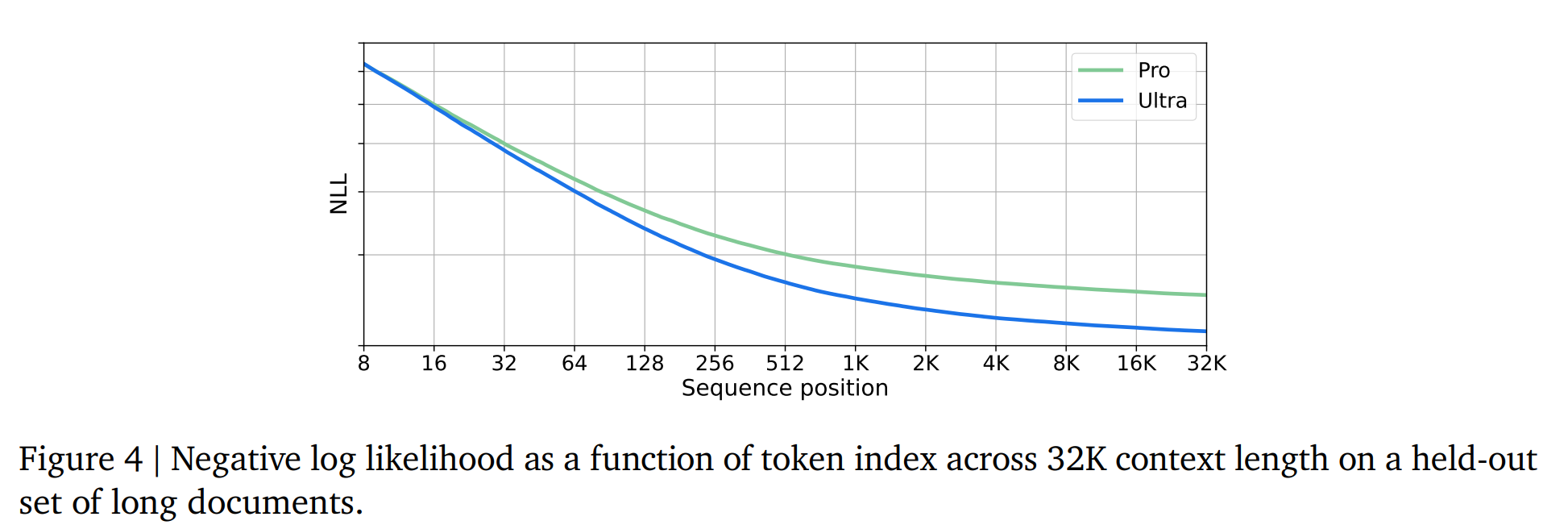
5.1.6. Human Preference Evaluations

5.1.7. Complex Reasoning Systems
5.2. Multimodal
雙子座模型天生就是多模態的。如圖 5 和圖 12 所示,這些模型具有獨特的能力,能將其跨模態能力(如從表格、圖表或圖形中提取信息和空間布局)與語言模型的強大推理能力(如其在數學和編碼方面的一流性能)無縫結合起來。這些模型在辨別輸入中的細粒度細節、聚合跨時空的上下文以及將這些能力應用于與時間相關的視頻幀和/或音頻輸入序列方面也表現出色。下文將對模型在不同模式(圖像、視頻和音頻)下的表現進行更詳細的評估,并舉例說明模型在圖像生成方面的能力以及在不同模式下整合信息的能力。
5.2.1. Image Understanding
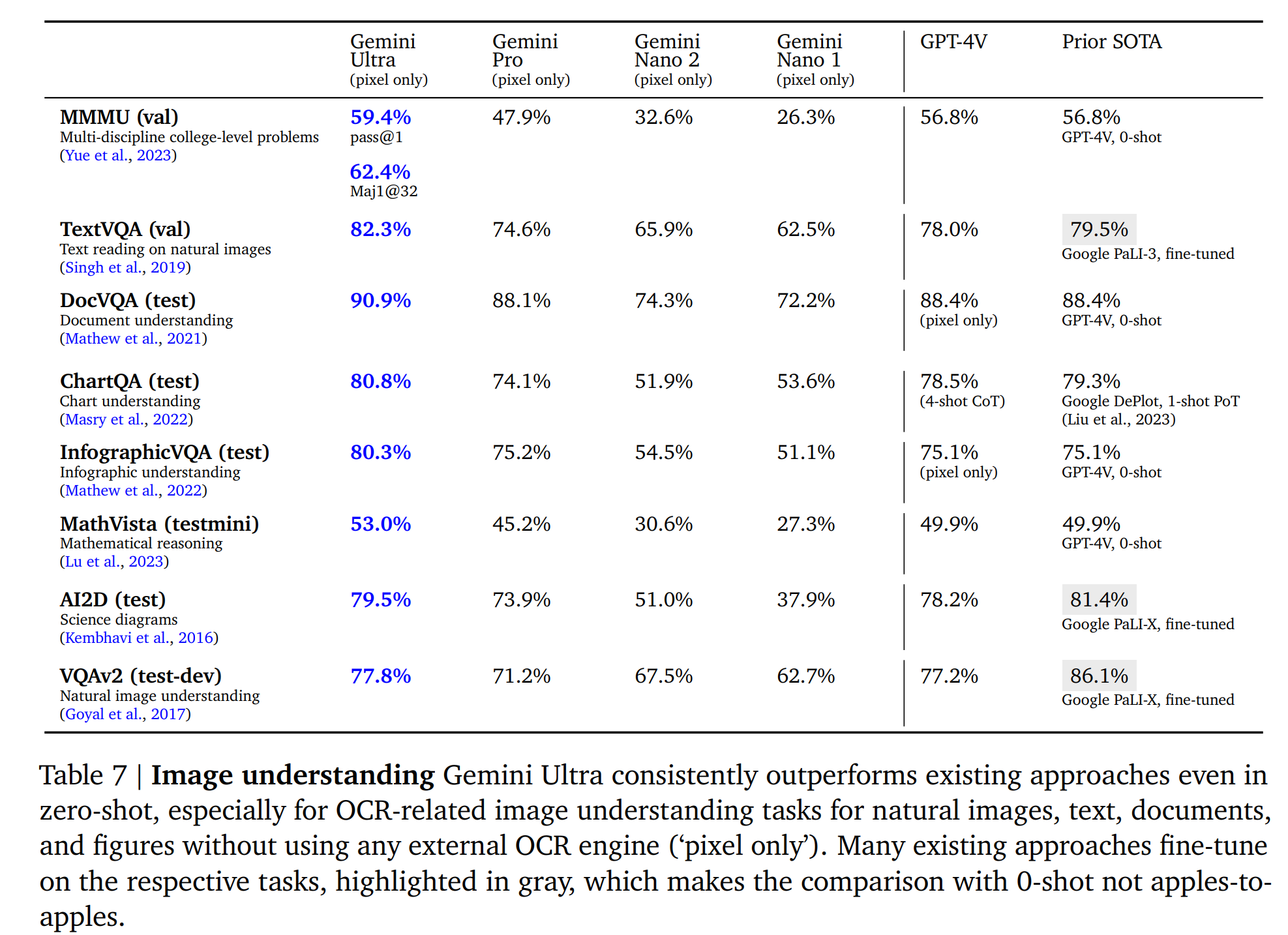
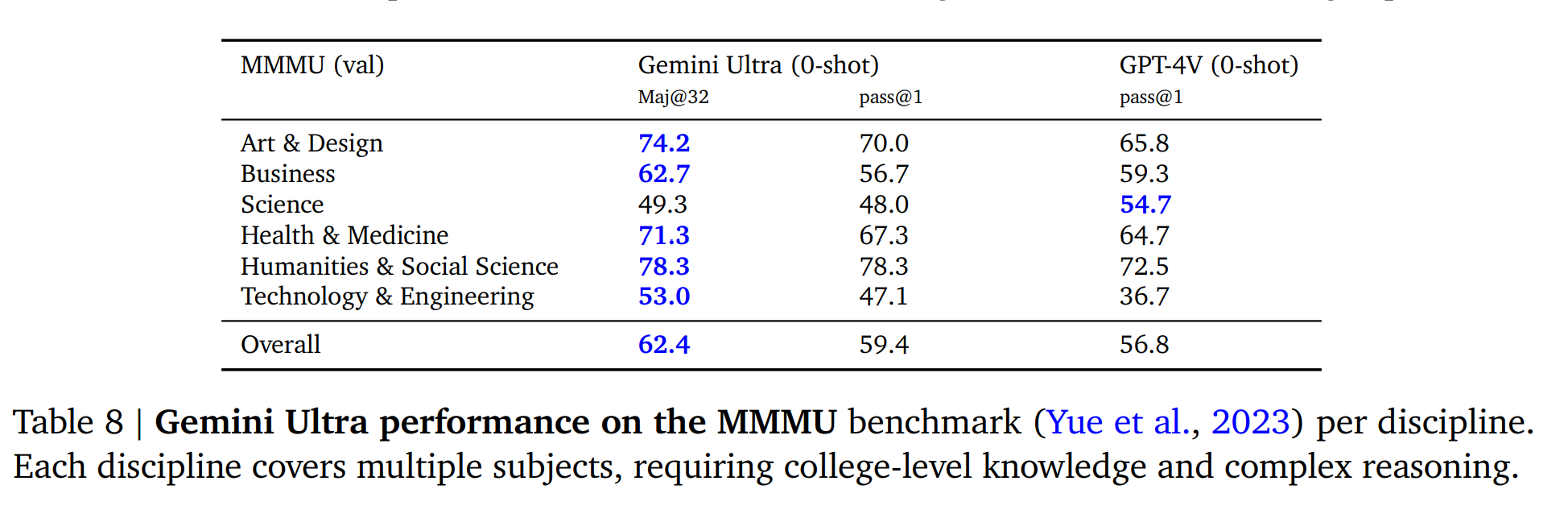
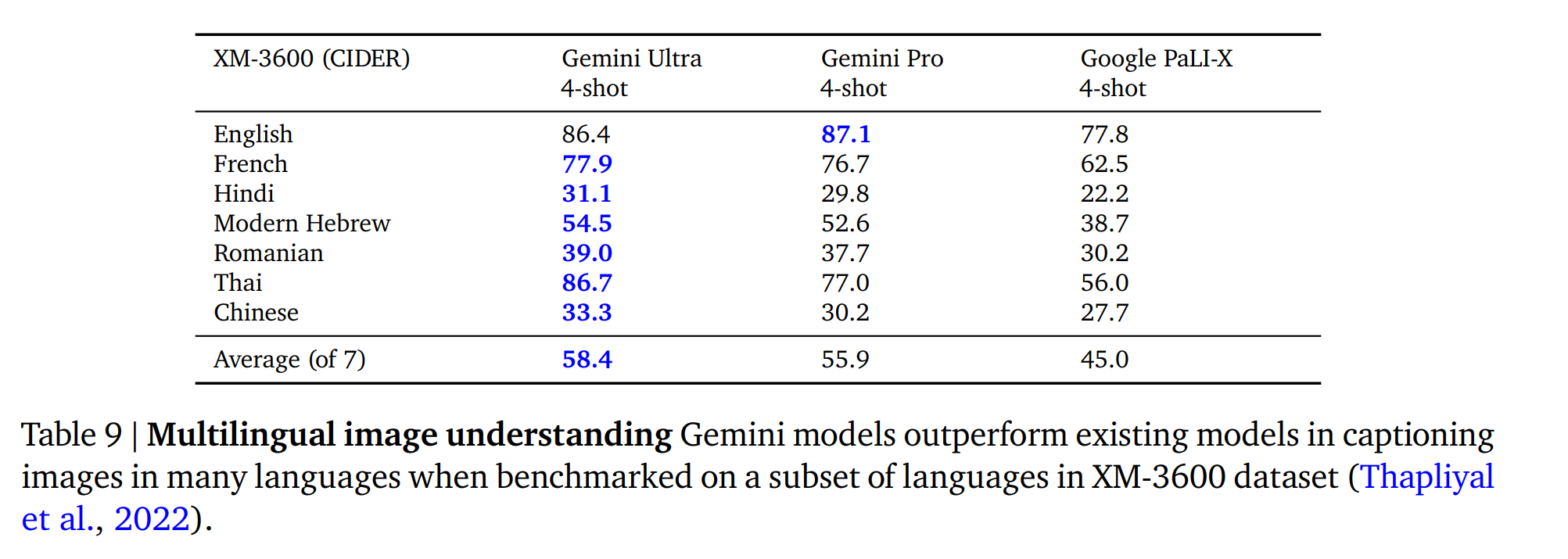
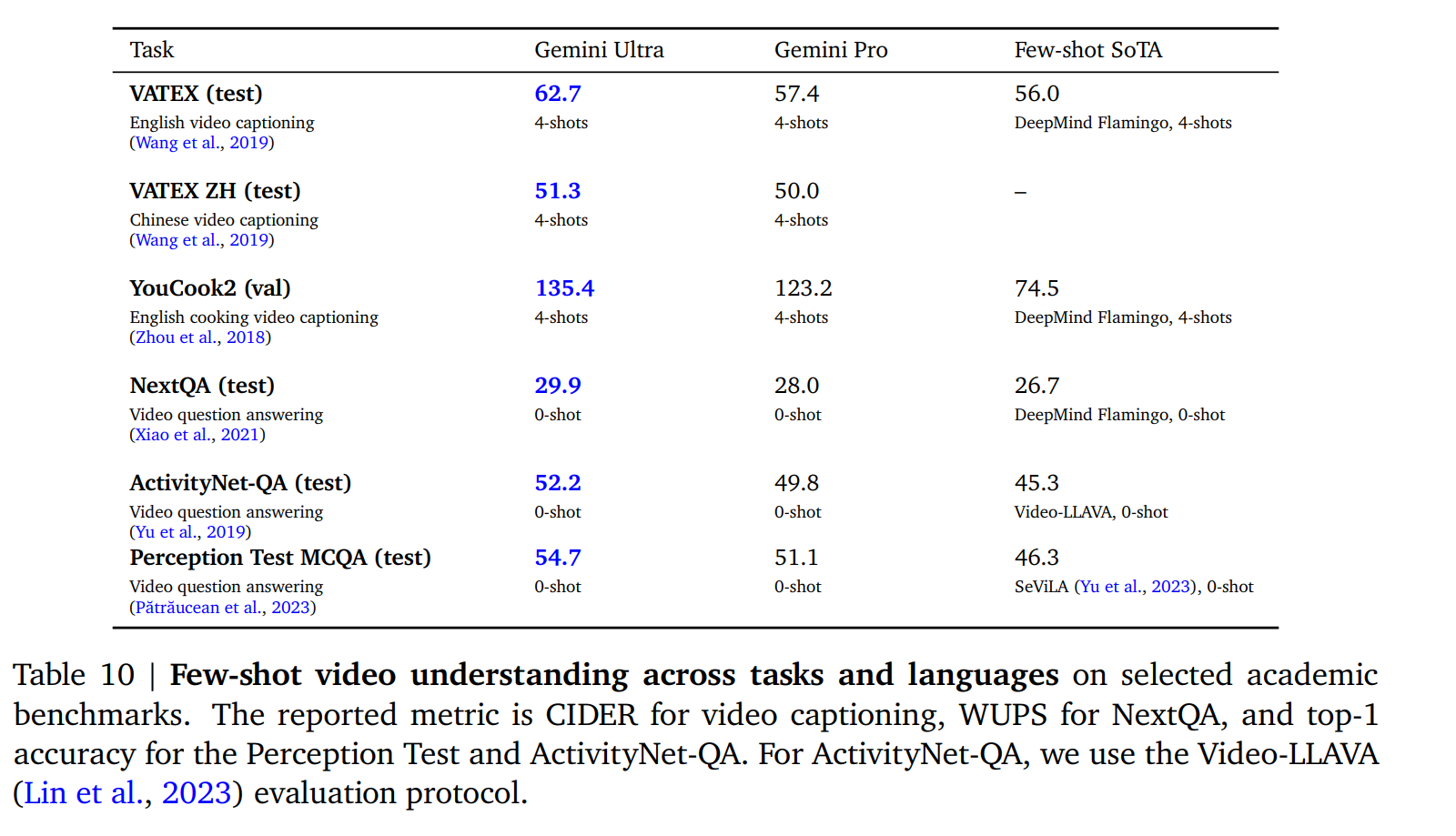
5.2.2. Video Understanding
從每個視頻片段中抽取 16 個間隔相等的幀,并將其輸入 Gemini 模型
5.2.3. Image Generation

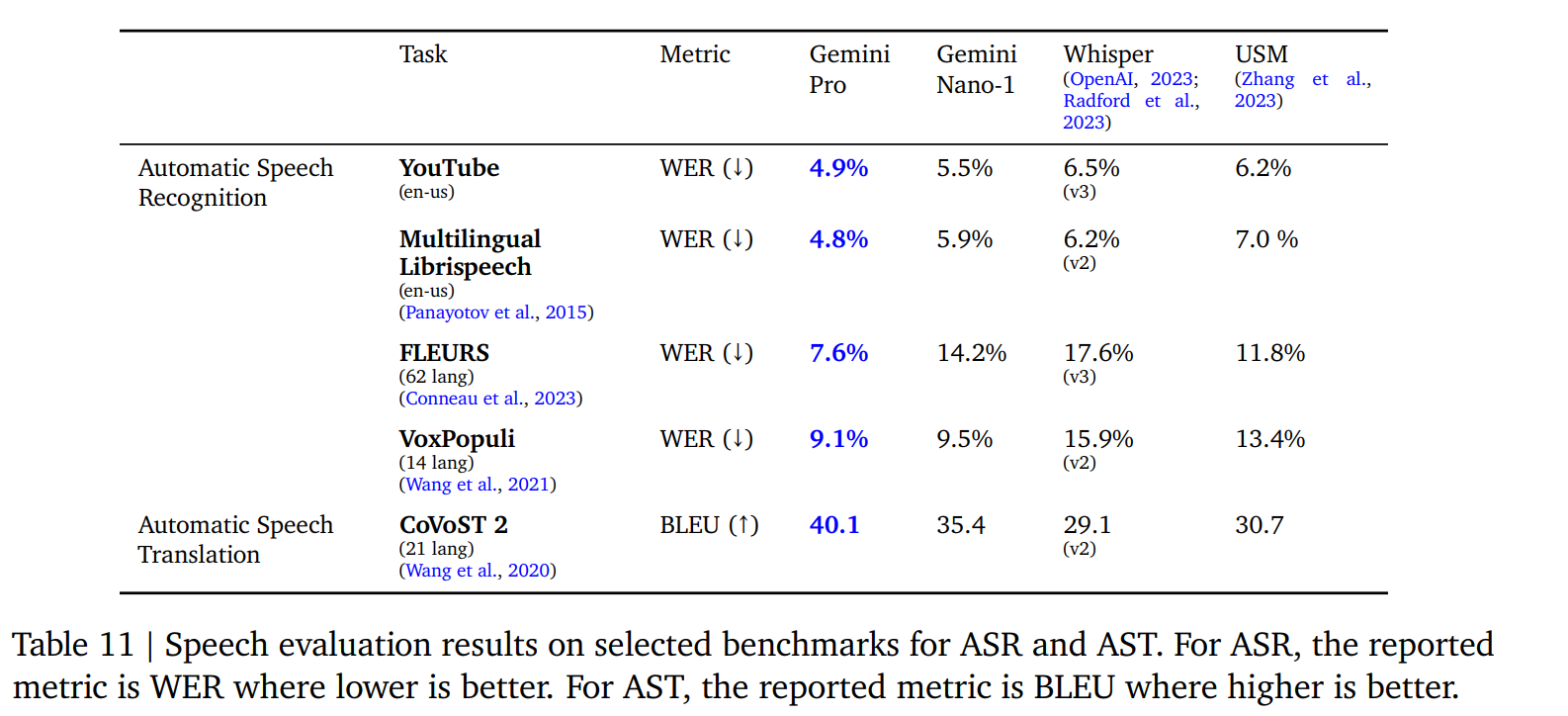
5.2.4. Audio Understanding

5.2.5. Modality Combination

6. Responsible Deployment
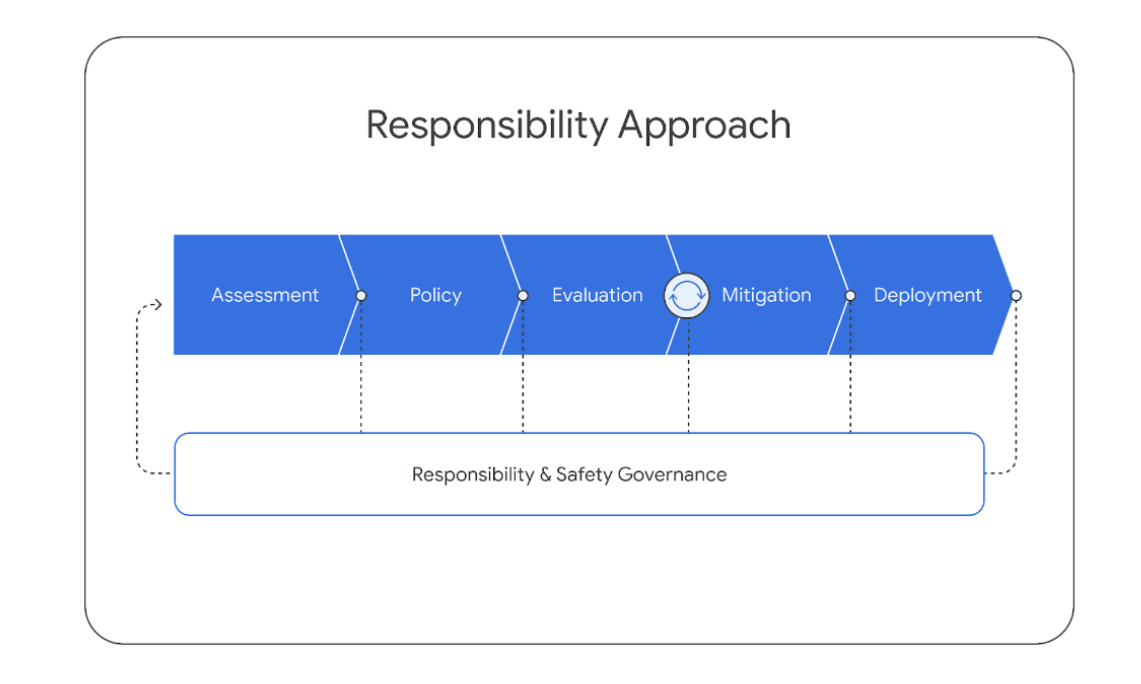
6.1. Impact Assessment
6.2. Model Policy
6.3. Evaluations
6.4. Mitigations
6.4.1. Data
6.4.2. Instruction Tuning
指令調整包括監督微調(SFT)和使用獎勵模型通過人類反饋進行強化學習(RLHF)。我們在文本和多模式設置中應用指令調整。指令調整配方經過精心設計,以平衡幫助性的增加和與安全性和幻覺相關的模型危害的減少(Bai 等人,2022a)。 “質量”數據的管理對于 SFT、獎勵模型訓練和 RLHF 至關重要。使用較小的模型消除數據混合比率,以平衡有用性(例如遵循指令、創造力)和模型危害減少的指標,并且這些結果可以很好地推廣到較大的模型。我們還觀察到,數據質量比數量更重要(Touvron et al., 2023b; Zhou et al., 2023),特別是對于較大的模型。同樣,對于獎勵模型訓練,我們發現平衡數據集與模型更喜歡說“我無能為力”的示例(出于安全原因)和模型輸出有用響應的示例至關重要。我們使用多目標優化以及有用性、真實性和安全性獎勵分數的加權總和來訓練多頭獎勵模型。我們進一步闡述了降低有害文本生成風險的方法。我們在各種用例中列舉了大約 20 種傷害類型(例如仇恨言論、提供醫療建議、建議危險行為)。我們生成這些類別中潛在危害性查詢的數據集,要么由政策專家和機器學習工程師手動生成,要么通過以主題關鍵字作為種子提示高性能語言模型來生成。考慮到會造成傷害的查詢,我們探索 Gemini 模型并通過并排評估來分析模型響應。如上所述,我們平衡了模型輸出響應無害與有幫助的目標。根據檢測到的風險區域,我們創建額外的監督微調數據來展示理想的響應。
6.4.3. Factuality
6.4.3. Factuality
6.6. Responsible Governance
7. Discussion and Conclusion
【一句話總結:Gimini最牛逼,是谷歌集大成之作】
除了基準測試中最先進的結果之外,我們最興奮的是 Gemini 模型支持的新用例。 Gemini 模型的新功能可解析復雜圖像(例如圖表或信息圖表),對圖像、音頻和文本的交錯序列進行推理,并在響應時生成交錯文本和圖像,從而開啟了各種新應用。正如報告和附錄中的數據所示,Gemini 可以在教育、日常問題解決、多語言交流、信息總結、提取和創造力等領域實現新方法。我們期望這些模型的用戶會發現各種有益的新用途,而這些用途在我們自己的調查中只觸及了表面。
Gemini 是我們朝著解決智能問題、推進科學發展和造福人類的使命邁出的又一步,我們熱切地希望看到 Google 及其他公司的同事如何使用這些模型。我們建立在機器學習、數據、基礎設施和負責任的開發方面的許多創新之上,這些都是我們在 Google 十多年來一直追求的領域。我們在本報告中提出的模型為我們更廣泛的未來目標提供了堅實的基礎,即開發一個大規模、模塊化的系統,該系統將在多種模式中具有廣泛的泛化能力。
8. 人員
9. Appendix
9.1. Chain-of-Thought Comparisons on MMLU benchmark
9.2. Capabilities and Benchmarking Tasks
9.3. Qualitative Examples
9.3.1. Chart understanding and reasoning over data
9.3.2. Multimodal question answering
9.3.3. Interleaved image and text generation
9.3.4. Image understanding and reasoning
9.3.5. Geometrical reasoning
9.3.6. Information seeking about objects
9.3.7. Multimodal reasoning based on visual cues
9.3.8. Multimodal humor understanding
9.4. Commonsense reasoning in a multilingual setting
9.4.1. Reasoning and code generation
9.4.2. Mathematics: Calculus
9.5. Multi-step reasoning and mathematics
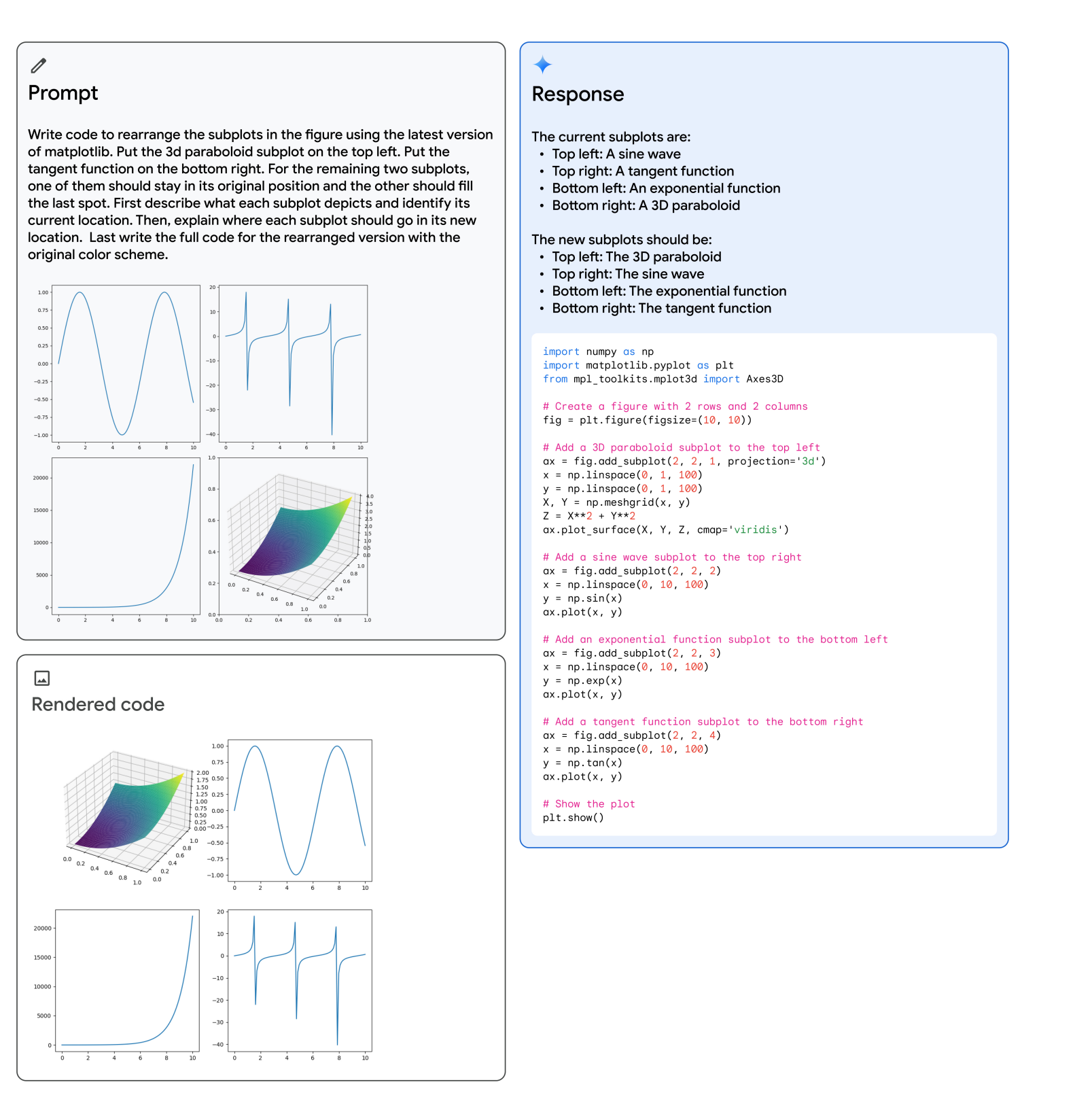
9.5.1. Complex image understanding, code generation, and instruction following
9.5.2. Video understanding and reasoning



)



(第15講))



)







