
論文:https://arxiv.org/pdf/1811.11168.pdf
代碼:https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch
1. 介紹
可變形卷積能夠很好地學習到發生形變的物體,但是論文觀察到當盡管比普通卷積網絡能夠更適應物體形變,可變形卷積網絡卻可能擴展到感興趣區域之外從而使得不相關的區域影響網絡的性能,由此論文提出v2版本的可變形卷積神經網絡(DCNv2),通過更有效的建模能力和訓練使網絡關注更恰當的圖像區域。
其中建模能力的增強得益于兩方面:
- 更多的可變形卷積層
- 調節能力,即學習偏移的同時還會加入每一個采樣點的權重
當然網絡也需要更強大的訓練方式,借鑒知識蒸餾的思想,使用一個R-CNN作為Teacher指導網絡的訓練,因為這個網絡可以預測有效的提議框的類別即只受到框里面內容的影響而不會受到框外區域的干擾,DCNv2在ROI層之后的特征趨向于模仿R-CNN的特征,如此一來,DCNv2就增強了自己可變形采樣的能力。
2.對可變形卷積的表現進行分析
為了更好地理解可變形卷積的工作機制,論文對以下三個環節進行了可視化分析,這個三部分為理解潛在目標區域對網絡節點的貢獻提供了詳盡的視角。
- 有效感受野:感受野內的像素點對網絡的影響是不相同的,這種影響程度的不同可以使用有效感受野來表示,有效感受野的值用每一個像素點對節點梯度的擾動來表示,利用有效感受野可以評價單個的像素點對網絡節點的影響但是并不反映整個圖像區域的結構性信息。
- 有效的采樣位置:用采樣區域對網絡節點梯度的影響表示有效采樣區域來理解不同采樣的位置對網絡的共享。
- 顯著性區域邊界錯誤:網絡節點計算的結果不會因為移除圖像不想管區域而發生變化,基于此,論文可以將有效的區域縮到最小,和全圖相比誤差很小,這個稱為邊界定位有偏差的顯著性區域,可以通過不斷遮擋圖像來計算節點的結果。
可視化結果如下圖所示:

能夠觀察到
- 標準卷積也具有一定程度的對物體的幾何形變進行建模的能力
- 通過引入可變形卷積,這種能力顯著增強,空間上網絡接收了更大的區域,覆蓋整個目標的同時也包含了更多的不相關的背景信息
- 第三種類型很明顯采樣區域更加有效
通過上面的可視化及其分析,很明顯可變形卷積能夠更好的提升網絡對幾何形變進行建模的能力,對潛在區域的采樣區域更大,因此論文提出需要對這個更大的區域進行進一步的分析,得到一個介于原區域與更大區域二者之間的采樣區域以提升精度。
3. 更強大的可變形建模能力
為了提升網絡對幾何形變進行建模的能力,論文提出了一些變化。
3.1 加入更多的可變形卷積層
因為可變形卷積的特殊能力,論文大膽地(╮(︶﹏︶")╭)提出使用更多的可變形卷積層進一步增強整個網絡對于幾何形變的建模能力。
該論文將ResNet50的conv3,conv4和conv5階段中的3x3卷積都替換為可變形卷積也就是一共12層可變形卷積(v1版本只有conv5階段的三層),在較為簡單的Pascal VOC數據集上觀察到更多可變形卷積層的表現更為優秀。
3.2 可調節的變形模塊
論文引入一種調節機制,不但能夠調整接收輸入的特征的位置,還能調節不同輸入特征的振幅(重要性),極端情況下,一個模塊可以通過將重要性設置為0來表示不接收該特征,結果對應采樣區域的圖像像素點顯著減少同時不影響模塊的輸出,因此這種調節機制能夠給網絡模塊新維度上的能力去調節支持區域。





3.3 R-CNN特征融合
可以從上面三圖中看到,deformable RoIPooling使得采樣區域增大,但是包含了過多的無關區域甚至可能降低其精度,而可調節的deformable RoIPooling使得區域更加合理。
此外,作者發現這種無關的圖像語義信息可能是Faster R-CNN的誤差來源,結合一些其他的動機(比如分類分支和邊界框回歸分支共享一些特征),作者提出將Faster R-CNN和R-CNN的分類分數結合從而獲得最終的檢測分數,這是由于R-CNN分類分數只專注于輸入RoI內的圖像內容,這會有助于解決重復語義信息的問題從而提升準確性。然而簡單的結合Faster R-CNN和R-CNN會使訓練和推斷都很慢,論文提出使用R-CNN作為一個教師網絡,讓DCNV2的RoI池化之后的feature去模擬R-CNN的特征,如下圖所示,除了Faster R-CNN外加一個R-CNN分支用于特征模仿,
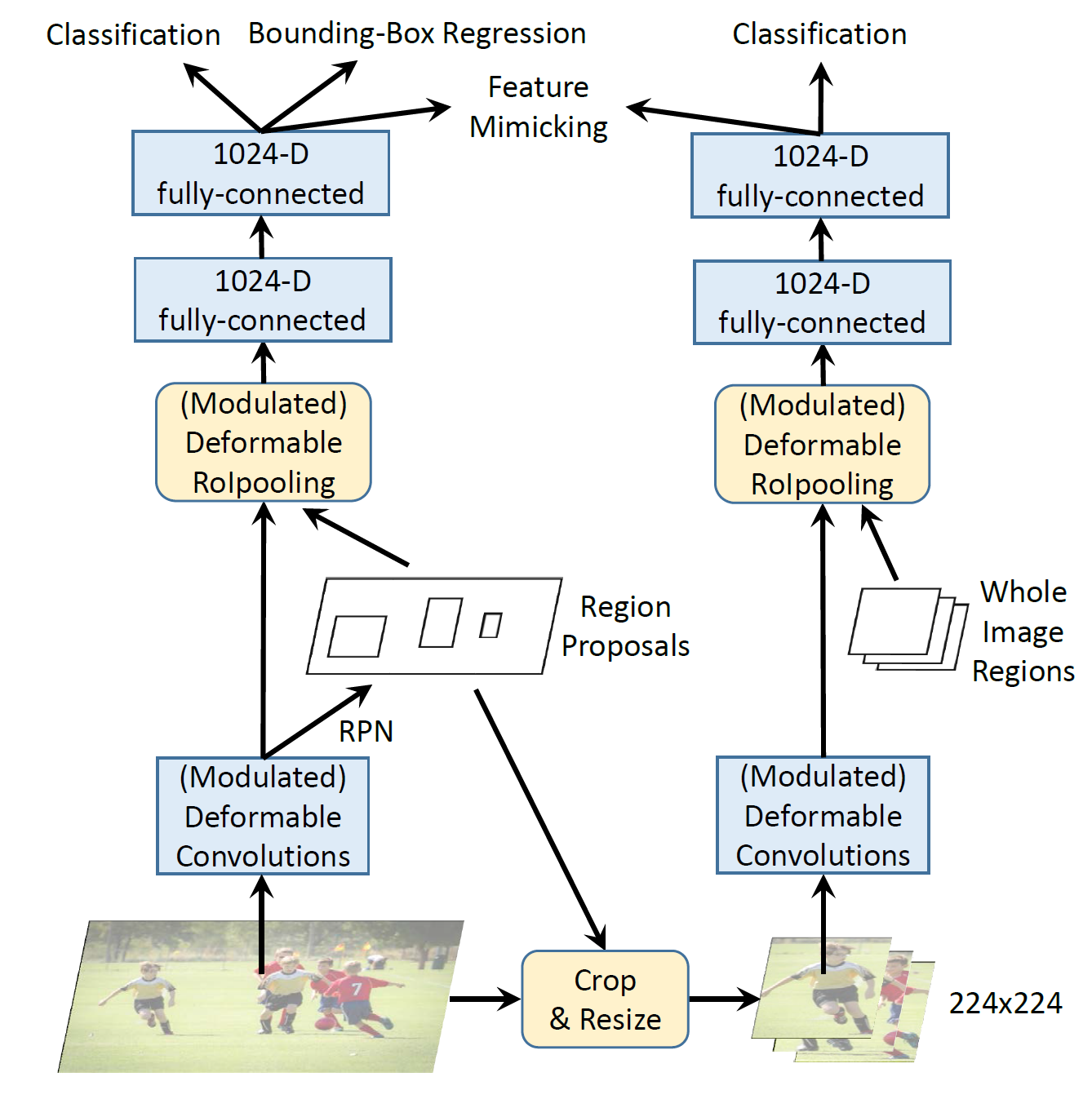



4. 實驗
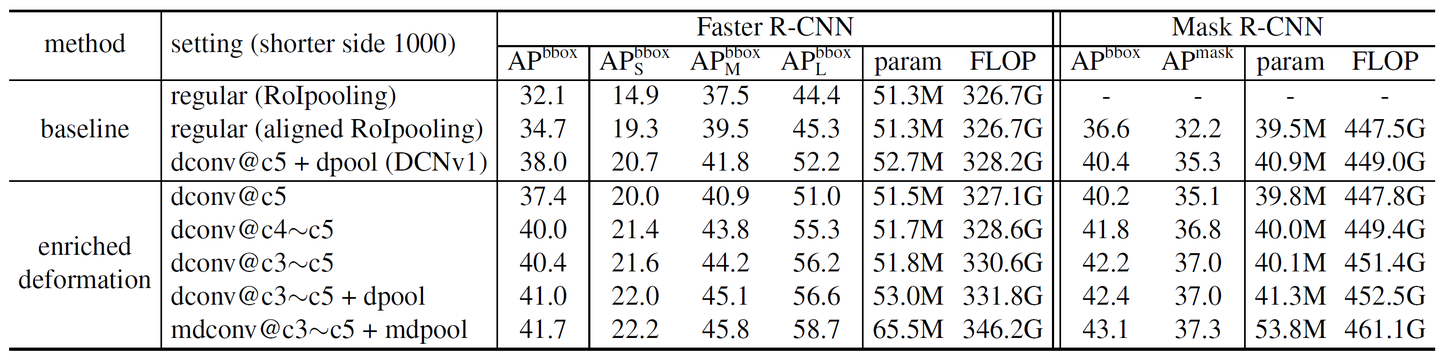
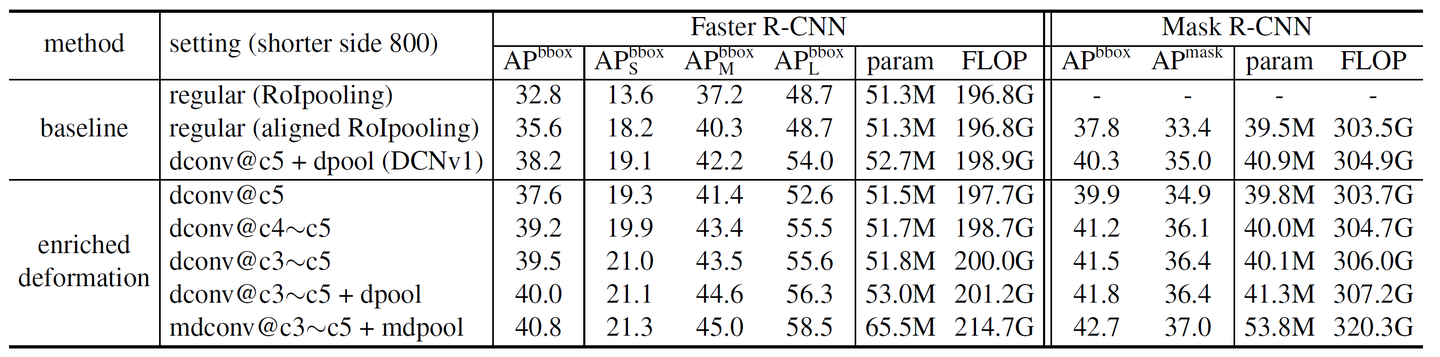
有無可變形卷積/RoI池化和多層可變形卷積(輸入圖像的短邊1000和800)
從哪個階段開始R-CNN特征模仿的影響

主干網絡的影響

不同尺度的目標
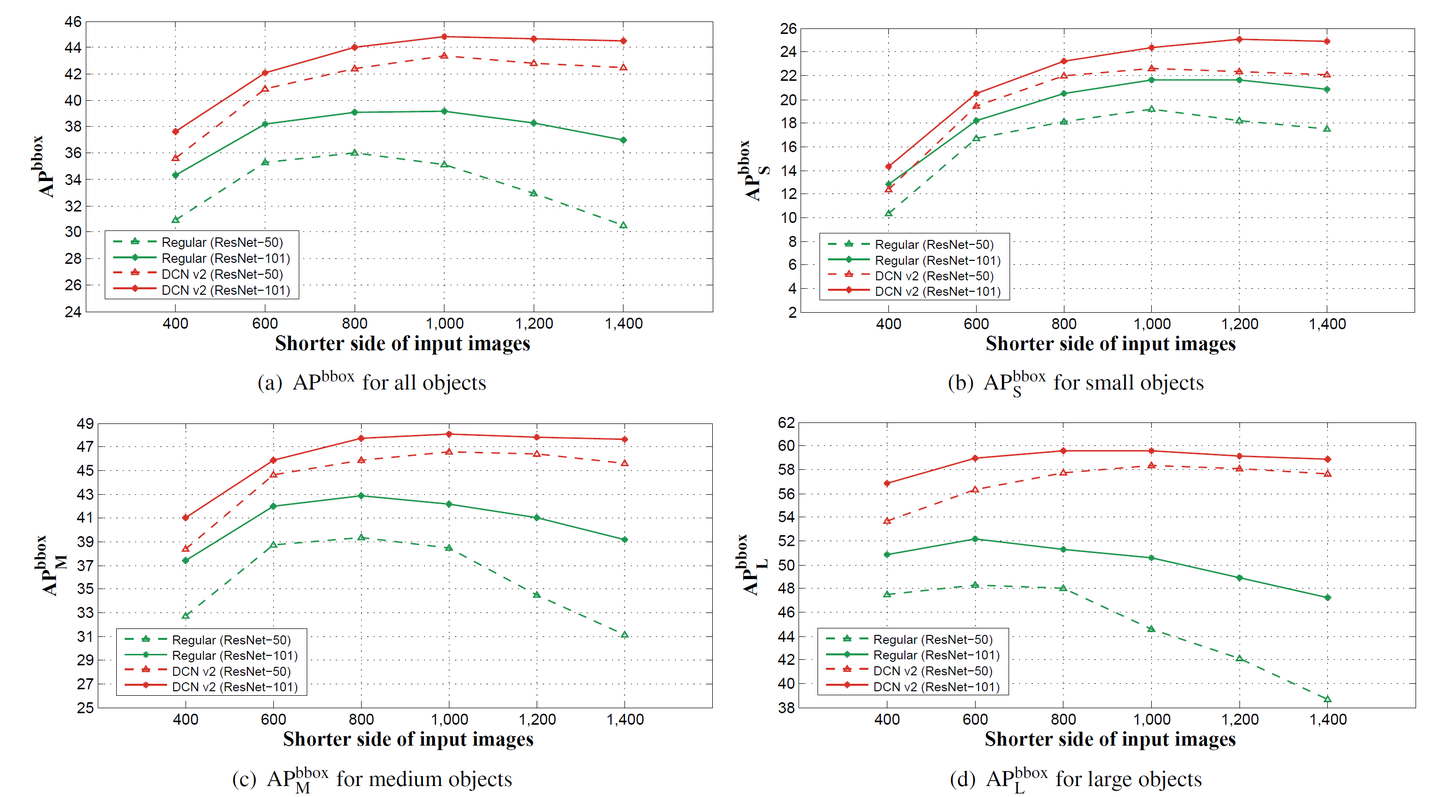
不同大小的輸入短邊

輸入圖像的分辨率

不同主干網絡的分類精度不同
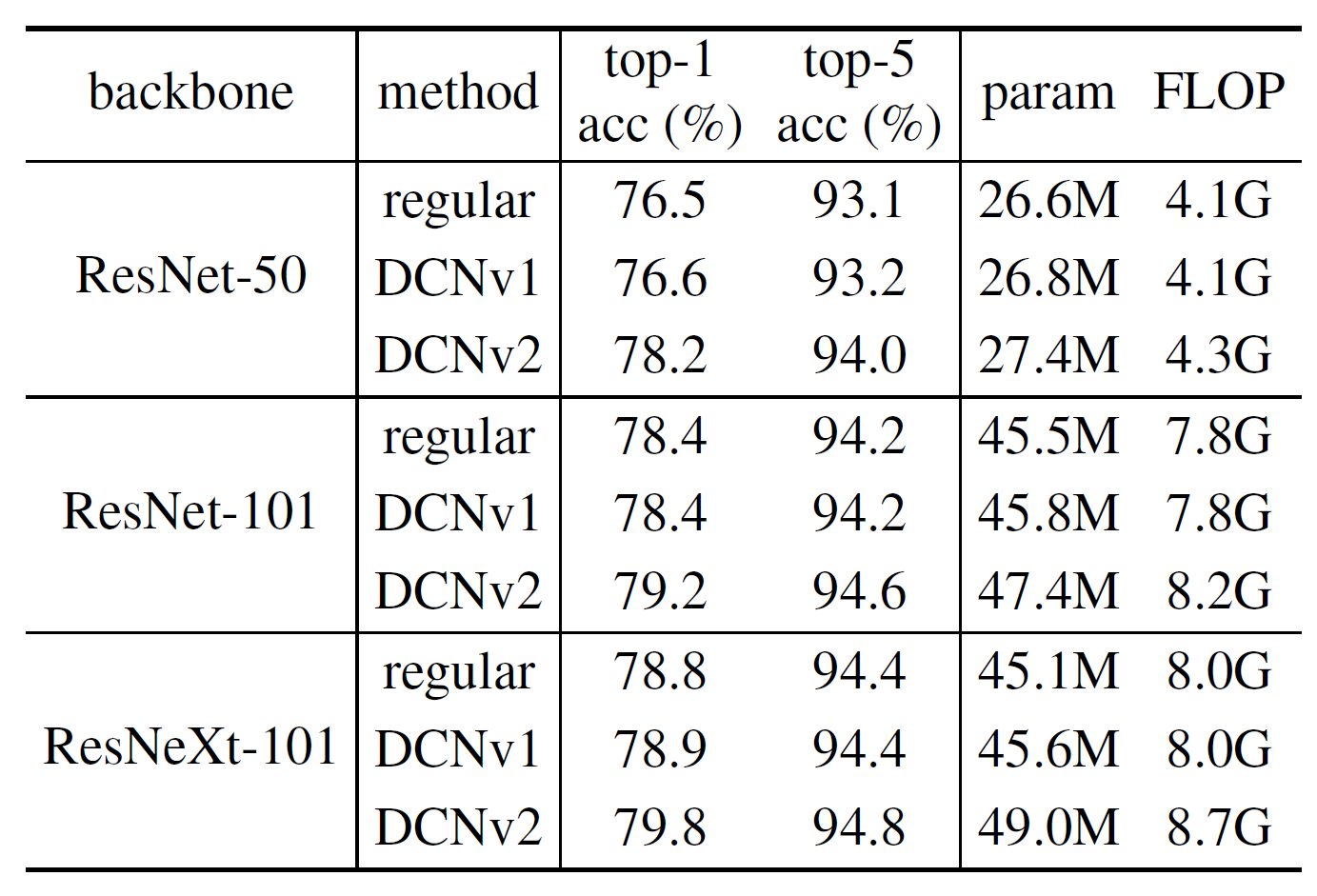
是否ImageNet預訓練?
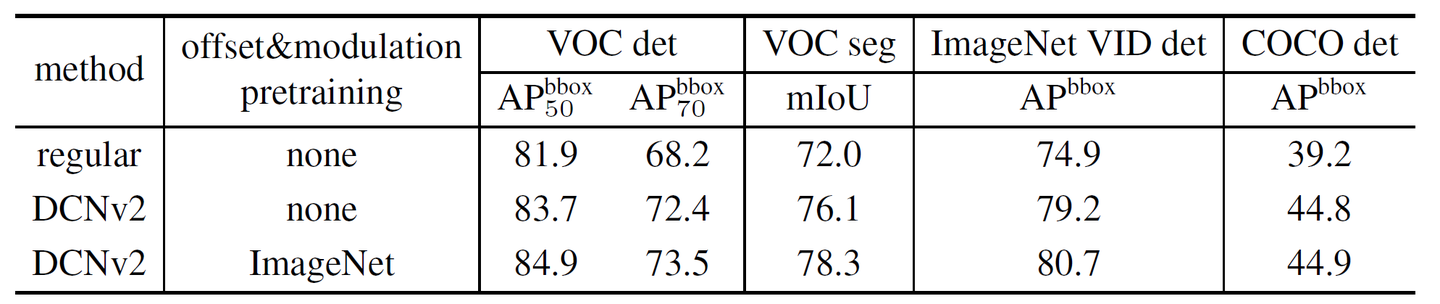
?

(第15講))



)












----變量的線程安全分析)
