數組和鏈表
數組:
存儲區間是連續,且占用內存嚴重,空間復雜也很大,時間復雜為O(1)
優點:是隨機讀取效率很高,原因數組是連續(隨機訪問性強,查找速度快)。
缺點:插入和刪除數據效率低,因插入數據,這個位置后面的數據在內存中要往后移的,且大小固定不易動態擴展。
鏈表:
區間離散,占用內存寬松,空間復雜度小,時間復雜度O(N)
優點:插入刪除速度快,內存利用率高,沒有大小固定,擴展靈活。
缺點:不能隨機查找,每次都是從第一個開始遍歷(查詢效率低)。
HashMap
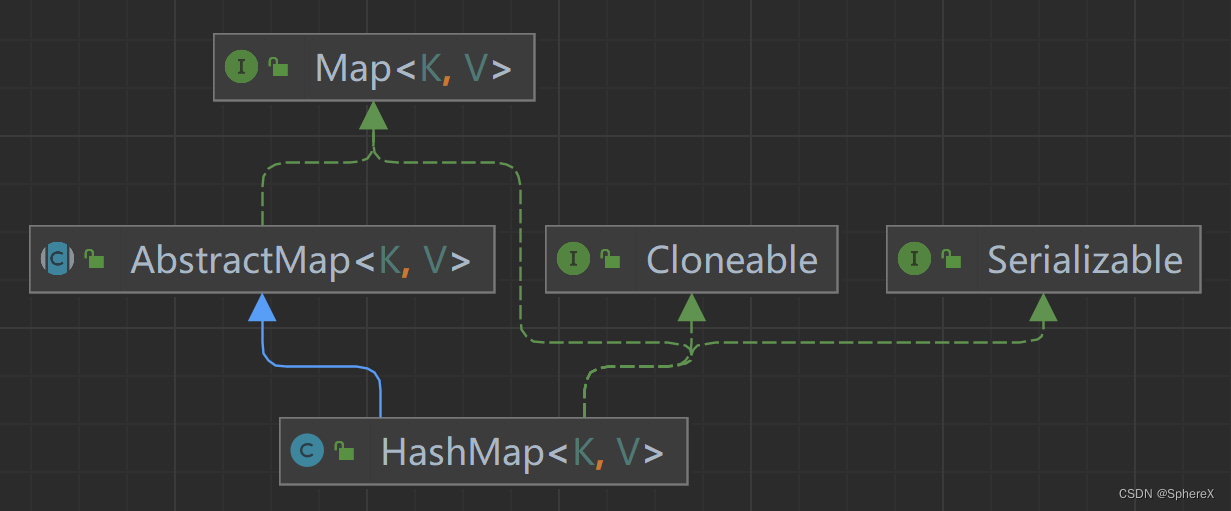
HashMap是一個集合,鍵值對的集合,源碼中每個節點用Node<K,V>表示
Node是一個內部類,這里的key為鍵,value為值,next指向下一個元素
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;HashMap的數據結構為?數組+(鏈表或紅黑樹),java7 之前是數組+鏈表 ,之后是 數組+鏈表/紅黑樹,這種結構完美的解決了數組和鏈表的問題,使得查詢和插入,刪除的效率都很高。
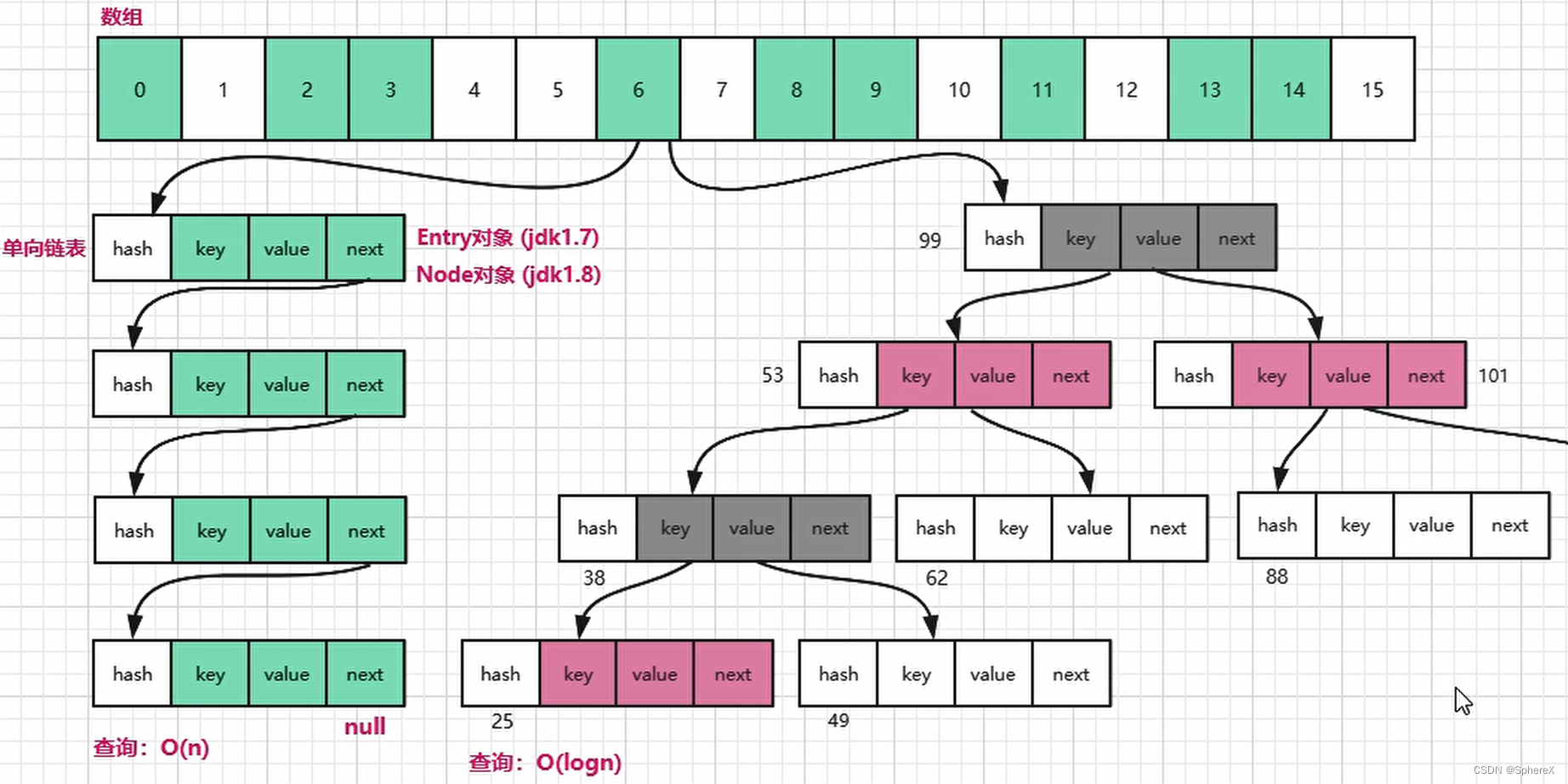
hashmap剛開始是左邊鏈表形態
在達到某條件后原本是左邊的鏈表形態會轉為右邊紅黑樹形態
同樣,在達到某條件后,原本轉成了右邊紅黑樹形態會轉回左邊鏈表形態
這里都畫出來是為了表示方便,左右兩種形態是不同時空下的hashmap內部形態。
?
HashMap存儲元素的過程:
HashMap<String,String> map = new HashMap<String,String>();
map.put("劉德華","張惠妹");
map.put("張學友","大S");計算出鍵“劉德華”的hashcode,該值用來定位要將這個元素存放到數組中的什么位置.
在Object類中有一個方法:public native int hashCode();
該方法用native修飾,所以是一個本地方法,所謂本地方法就是非java代碼,這個代碼通常用c或c++寫成,在java中可以去調用它。
調用這個方法會生成一個int型的整數,我們叫它哈希碼,哈希碼和調用它的對象地址和內容有關.
通過hashcode值和數組長度取模我們可以得到元素存儲的下標。
1. 數組索引的地方是空的,這種情況很簡單,直接將元素放進去就好了。
2. 已經有元素占據了索引的位置,這種情況下我們需要判斷一下該位置的元素和當前元素是否相等,使用equals來比較。
如果使用默認的規則是比較兩個對象的地址。也就是兩者需要是同一個對象才相等,當然我們也可以重寫equals方法來實現我們自己的比較規則最常見的是通過比較屬性值來判斷是否相等。
如果兩者相等則直接覆蓋,如果不等則在原元素下面使用鏈表的結構存儲該元素
因為鏈表中元素太多的時候會影響查找效率,所以當鏈表的元素個數達到8的時候使用鏈表存儲就轉變成了使用紅黑樹存儲,原因就是紅黑樹是平衡二叉樹,在查找性能方面比鏈表要高.
HashMap中的兩個重要的參數
HashMap中有兩個重要的參數:初始容量大小和加載因子,初始容量大小是創建時給數組分配的容量大小,默認值為16,加載因子默認0.75f,用數組容量大小乘以加載因子得到一個值,一旦數組中存儲的元素個數超過該值就會調用rehash方法將數組容量增加到原來的兩倍,專業術語叫做擴容.
在做擴容的時候會生成一個新的數組,原來的所有數據需要重新計算哈希碼值重新分配到新的數組,所以擴容的操作非常消耗性能.
HashMap的put(k,v)實現
首先將k,v封裝到Node對象當中(節點)
調用K的hashCode()方法得出hash值
通過哈希表函數/哈希算法,將hash值轉換成數組的下標,下標位置上如果沒有任何元素,就把Node添加到這個位置上。
如果說下標對應的位置上有鏈表。此時,就會拿著k和鏈表上每個節點的k進行equal。如果所有的equals方法返回都是false,那么這個新的節點將被添加到鏈表的末尾。
如其中有一個equals返回了true,那么這個節點的value將會被覆蓋。
java8中put 源碼:put 中調用 putVal()方法:
1.首先判斷map中是否有數據,沒有就執行resize方法
2.如果要插入的鍵值對要存放的這個位置剛好沒有元素,那么把他封裝成Node對象,放在這個位置上即可
3.如果這個元素的key與要插入的一樣,那么就替換一下。
4.如果當前節點是TreeNode類型的數據,執行putTreeVal方法
5.遍歷這條鏈子上的數據,完成了操作后多做了一件事情,判斷,并且可能執行treeifyBin方法
static final int TREEIFY_THRESHOLD = 8;public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab;Node<K,V> p;int n, i;//如果當前map中無數據,執行resize方法。并且返回nif ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//如果要插入的鍵值對要存放的這個位置剛好沒有元素,那么把他封裝成Node對象,放在這個位置上即可if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);//否則的話,說明這上面有元素else {Node<K,V> e; K k;//如果這個元素的key與要插入的一樣,那么就替換一下。if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//1.如果當前節點是TreeNode類型的數據,執行putTreeVal方法else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//還是遍歷這條鏈子上的數據,跟jdk7沒什么區別for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//2.完成了操作后多做了一件事情,判斷,并且可能執行treeifyBin方法if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null) //true || --e.value = value;//3.afterNodeAccess(e);return oldValue;}}++modCount;//判斷閾值,決定是否擴容if (++size > threshold)resize();//4.afterNodeInsertion(evict);return null;}HashMap的map.get(k)實現
先調用k的hashCode()方法得出哈希值,并通過哈希算法轉換成數組的下標
通過上一步哈希算法轉換成數組的下標之后,在通過數組下標快速定位到某個位置上,如果這個位置上什么都沒有,則返回null。
如果這個位置上有單向鏈表,那么它就會拿著參數K和單向鏈表上的每一個節點的K進行equals,如果所有equals方法都返回false,則get方法返回null。
如果其中一個節點的K和參數K進行equals返回true,那么此時該節點的value就是我們要找的value了,get方法最終返回這個要找的value。
java 1.7 和 java1.8 HashMap 的區別
jdk1.7中HashMap采用的是位桶+鏈表的方式,即我們常說的散列鏈表的方式,而jdk1.8中采用的是位桶+鏈表/紅黑樹的方式,也是非線程安全的。當某個位桶的鏈表的長度達到某個閥值(8)的時候,這個鏈表就將轉換成紅黑樹。
在jdk1.8中,如果鏈表長度大于8且節點數組長度大于64的時候,就把鏈表下所有的節點轉為紅黑樹。
樹形化還有一個要求就是數組長度必須大于等于64,否則繼續采用擴容策略
總的來說,HashMap默認采用數組+單鏈表方式存儲元素,當元素出現哈希沖突時,會存儲到該位置的單鏈表中。但是單鏈表不會一直增加元素,當元素個數超過8個時,會嘗試將單鏈表轉化為紅黑樹存儲。但是在轉化前,會再判斷一次當前數組的長度,只有數組長度大于64才處理。否則,進行擴容操作。
HashMap鏈表轉紅黑樹
當鏈表長度大于或等于閾值(默認為 8)的時候,如果同時還滿足容量大于或等于 MIN_TREEIFY_CAPACITY(默認為 64)的要求,就會把鏈表轉換為紅黑樹。
同樣,后續如果由于刪除或者其他原因調整了大小,當紅黑樹的節點小于或等于 6 個以后,又會恢復為鏈表形態。
? ? ? ?每次遍歷一個鏈表,平均查找的時間復雜度是 O(n),n 是鏈表的長度。紅黑樹有和鏈表不一樣的查找性能,由于紅黑樹有自平衡的特點,可以防止不平衡情況的發生,所以可以始終將查找的時間復雜度控制在 O(log(n))。最初鏈表還不是很長,所以可能 O(n) 和 O(log(n)) 的區別不大,但是如果鏈表越來越長,那么這種區別便會有所體現。所以為了提升查找性能,需要把鏈表轉化為紅黑樹的形式。
? ? ? ?還要注意很重要的一點,單個 TreeNode 需要占用的空間大約是普通 Node 的兩倍,所以只有當包含足夠多的 Nodes 時才會轉成 TreeNodes,而是否足夠多就是由 TREEIFY_THRESHOLD 的值決定的。而當桶中節點數由于移除或者 resize 變少后,又會變回普通的鏈表的形式,以便節省空間。
? ? ? ?默認是鏈表長度達到 8 就轉成紅黑樹,而當長度降到 6 就轉換回去,這體現了時間和空間平衡的思想,最開始使用鏈表的時候,空間占用是比較少的,而且由于鏈表短,所以查詢時間也沒有太大的問題。可是當鏈表越來越長,需要用紅黑樹的形式來保證查詢的效率。
? ? ? ?在理想情況下,鏈表長度符合泊松分布,各個長度的命中概率依次遞減,當長度為 8 的時候,是最理想的值。
? ? ? ?事實上,鏈表長度超過 8 就轉為紅黑樹的設計,更多的是為了防止用戶自己實現了不好的哈希算法時導致鏈表過長,從而導致查詢效率低,而此時轉為紅黑樹更多的是一種保底策略,用來保證極端情況下查詢的效率。
? ? ? ?通常如果 hash 算法正常的話,那么鏈表的長度也不會很長,那么紅黑樹也不會帶來明顯的查詢時間上的優勢,反而會增加空間負擔。所以通常情況下,并沒有必要轉為紅黑樹,所以就選擇了概率非常小,小于千萬分之一概率,也就是長度為 8 的概率,把長度 8 作為轉化的默認閾值。
? ? ? ?如果開發中發現 HashMap 內部出現了紅黑樹的結構,那可能是我們的哈希算法出了問題,所以需要選用合適的hashCode方法,以便減少沖突。?
?
總結
HashMap基于哈希散列表實現 ,可以實現對數據的讀寫。
將鍵值對傳遞給put方法時,它調用鍵對象的hashCode()方法來計算hashCode,然后找到相應的bucket位置(即數組)來儲存值對象。
當獲取對象時,通過鍵對象的equals()方法找到正確的鍵值對,然后返回值對象。
HashMap使用鏈表來解決hash沖突問題,當發生沖突了,對象將會儲存在鏈表的頭節點中。HashMap在每個鏈表節點中儲存鍵值對對象,當兩個不同的鍵對象的hashCode相同時,它們會儲存在同一個bucket位置的鏈表中,如果鏈表大小超過閾值(TREEIFY_THRESHOLD,8),鏈表就會被改造為樹形結構。
1.7擴容時需要重新計算哈希值和索引位置,1.8并不重新計算哈希值,巧妙地采用和擴容后容量進行&操作來計算新的索引位置。


)





)
![[完美解決]Accelerate設置單卡訓練報錯,成功設置單卡訓練](http://pic.xiahunao.cn/[完美解決]Accelerate設置單卡訓練報錯,成功設置單卡訓練)



![[每周一更]-(第76期):Go源碼閱讀與分析的方式](http://pic.xiahunao.cn/[每周一更]-(第76期):Go源碼閱讀與分析的方式)





筆記——C99對數學計算的新增支持)