文章目錄
- 前言
- 7.1 Adreno GPU OpenCL內存
- 7.1.1 內存聲明周期
- 7.1.2 Loacl Memory
- 7.1.3 Constant memory(常量內存)
- 7.1.4 Private Memory
- 7.1.5 Global Memory
- 7.1.5.1 Buffer Object
- 7.1.5.2 Image Object
- 7.1.5.3 Image object vs. buffer object
- 7.1.5.4 Use of both Image and buffer objects
- 7.1.5.5 Global memory vs. local memory
- 7.2 優化內存 load/store
- 7.2.1 Coalesced memory load/store
- 7.2.2 Vectorized load/store
- 7.2.3 Optimal data type
- 7.2.4 16-bit vs. 32-bit data type
- 7.3 Atomic functions in OpenCL 1.x
- 7.4 Zero copy
- 7.4.1 使用內存映射而不是 COPY
- 7.4.2 避免為非由OpenCL分配的對象進行內存復制
- 7.4.2.1 ION/dmabuf memory extensions
- 7.4.2.2 QTI Android native buffer (ANB) extension
- 7.4.2.3 Android Hardware Buffer (AHB) extension
- 7.4.2.4 Using standard EGL extensions
- 7.5 Shared virtual memory (SVM)
- 7.6 Improve the GPU’s L1/L2 cache usage
- 7.7 CPU cache operations
- 7.8 減少能耗
- 總結
前言
內存優化是最關鍵且有效的OpenCL性能技術。許多應用程序受限于內存而非計算能力。因此,精通內存優化對于OpenCL優化至關重要。
7.1 Adreno GPU OpenCL內存
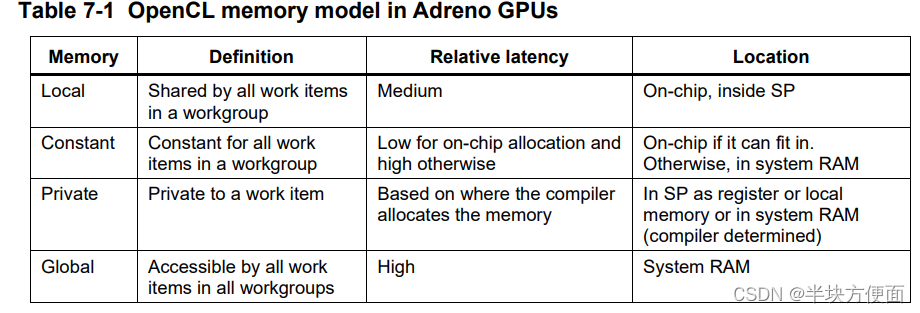
OpenCL定義了四種類型的內存(全局、本地、常量和私有),了解它們之間的差異對性能優化至關重要。圖7-1說明了這四種內存類型的概念布局。

OpenCL標準僅在概念上定義了這些內存類型,它們的實現是供應商特定的。物理位置可能與其概念位置不同。例如,私有內存對象可能位于離GPU很遠的片外系統內存中。
表7-1列出了Adreno GPU中四種內存類型的定義,以及它們的延遲和物理位置。在Adreno GPU上,本地內存和常量內存都位于芯片上,其延遲比片外系統內存要短得多。
一般來說,內核應該使用本地(Local)和常量內存來存儲需要頻繁訪問以利用低延遲特性的數據。更多詳細信息在接下來的章節中會有介紹。
7.1.1 內存聲明周期
一個典型的問題是如何將內存對象的內容從一個內核傳遞到下一個內核。例如,如何在內核的本地內存中共享內容,以便在后續內核中使用。以下是開發者應該遵循的原則:
- 本地內存是每個工作組獨有的,其內容的生命周期在工作組執行完成后結束。因此,無法在一個工作組的本地內存內容或從一個內核到另一個內核中進行共享。
- 常量內存內容在工作組中的所有工作項之間是一致的。一旦內核執行完成,內容可能被 GPU 上運行的其他任務(如圖形工作負載)覆蓋。
- 單個工作項擁有私有內存,一旦工作項執行完成,就不能共享。
- 全局內存由主機創建的緩沖區和圖像對象支持,可以由主機和 GPU 訪問。因此,如果對象沒有被釋放,它可以通過不同的內核訪問。
7.1.2 Loacl Memory
Adreno GPU支持快速的片上 Loacl Memory,但 Loacl Memory 的大小在不同系列/層級 GPU 之間會有所變化。在使用 Loacl Memory 之前,最好使用以下API查詢設備每個工作組可用的 Loacl Memory :
clGetDeviceInfo(deviceID, CL_DEVICE_LOCAL_MEM_SIZE, ... )
以下是使用本地內存的指南: ps: 工作項(work item)是任務的最小執行單元
- 使用本地內存來存儲在內核中的兩個階段(兩次操作)之間需要重復訪問的數據或中間結果。
- 理想情況是當工作項多次訪問相同內容且超過兩次時。
- 例如,考慮使用對象匹配進行視頻處理的基于窗口的運動估計。假設每個工作項處理一個16x16像素的搜索窗口內的8x8像素小區域,導致相鄰工作項之間存在數據重疊。在這種情況下,使用本地內存可以很好地存儲像素,以減少冗余獲取。
- 理想情況是當工作項多次訪問相同內容且超過兩次時。
- 在工作項之間進行數據同步的屏障可能會很昂貴。
- 如果工作項之間存在數據交換,例如,工作項A將數據寫入本地內存,工作項B從中讀取,由于OpenCL的松散內存一致性模型,需要進行屏障操作。
- 屏障通常會導致同步延遲,使ALUs停滯,從而降低利用率。
- 在某些情況下,將數據緩存到本地內存會導致同步延遲,抵消了使用本地內存的好處。在這種情況下,直接使用全局內存以避免屏障可能是更好的選擇。
- 使用矢量化的本地內存加載/存儲。
- 推薦使用32位對齊的多達128位(例如,vload4_float)的矢量化加載。
- 有關矢量化數據加載/存儲的更多詳細信息,請參見第7.2.2節。
- 允許每個工作項參與本地內存數據加載,而不是使用一個工作項執行整個加載。
- 避免僅使用一個工作項來加載/存儲整個工作組的本地內存。
- 避免使用名為async_work_group_copy的函數。對于編譯器來說,生成加載本地內存的最佳代碼通常很棘手,因此最好由開發人員手動編寫代碼將數據加載到本地內存中。
7.1.3 Constant memory(常量內存)
Adreno GPUs支持芯片上的常量內存,如果得當使用,可以在四種內存類型中提供卓越的性能。常量內存通常在以下情況下使用:
- 標量和矢量變量使用
constant定義。 - 如果在程序范圍內定義了帶有
constant的數組(例如,編譯器可以確定其大小),它將適應常量內存。 - 內核參數是標量或矢量數據類型。例如,以下示例中的coeffs將存儲在常量內存中:
__kernel void myFastKernel(__global float* bar, float8 coeffs)
{ //coeffs will be loaded to constant RAM }
- 標量和矢量變量以及帶有 __constant 但不適合常量內存的數組將被分配到系統內存中。
以下是對于常量內存的一個重要建議。如果一個內核具有以下兩個特點:
- 作為內核參數的小數組,例如5x5高斯濾波器的系數。
- 該數組的元素在子組或工作組內均勻讀取。
其性能可以通過使用名為 max_constant_size(N) 的屬性將數組加載到常量內存中而顯著提高。該屬性用于指定為該數組所需的最大字節數。在以下示例中,為變量 foo 在常量內存中分配了1024字節
__kernel void myFastKernel( __constant float *foo __attribute__( (max_constant_size(1024)))
{ . . . }
指定 max_constant_size 屬性是至關重要的。如果沒有這個屬性,數組將存儲在片外系統內存中,因為編譯器不知道緩沖區的大小,無法將其提升到芯片上的常量內存。此功能僅支持16位和32位的數組,即不支持8位數組。此外,如果緩沖區太大而無法適應常量內存,則它將存儲在片外系統內存中。
對于動態索引且由工作項發散訪問的數組,常量內存可能不是最優選擇。例如,如果一個工作項獲取索引0,而下一個工作項獲取索引20,那么常量內存效率較低。在這種情況下,使用圖像對象可能是一個更好的選擇。
7.1.4 Private Memory
在OpenCL中,私有內存是每個工作項私有的,其他工作項無法訪問。從物理上來說,私有內存可以存在于芯片內寄存器或片外系統內存中。確切的位置取決于多個因素,以下是一些典型的情況:
- 標量變量存儲在寄存器中,這比其他內存更快。
- 如果寄存器不足,私有變量可能存儲在系統內存中。
- 私有數組可能存儲在:
- 本地內存中,盡管不能保證。
- 如果超過本地內存容量,可能存儲在片外系統內存中。
將私有內存存儲到片外系統內存是非常不可取的,原因有兩點:
- 系統內存的延遲遠高于寄存器
- 私有內存訪問模式不友好于緩存,尤其是如果每個工作項的私有內存量很大
建議:
- 避免在內核中定義任何私有數組。盡量使用矢量。
- 替換私有數組,使用全局或本地數組,并設計其布局,以便在多個相鄰的工作項之間合并對數組元素的訪問。這樣可以改善緩存性能。
- 使用矢量化的私有內存加載/存儲,即盡量每次加載/存儲高達128位的數據,使用vload4/vstore4每次加載/存儲四個32位元素。
7.1.5 Global Memory
OpenCL支持使用系統RAM的緩沖區(buffer)和圖像對象。與緩沖區對象相比,它是在系統RAM中存儲的簡單一維數據數組,圖像對象是一種不透明的內存對象,開發人員無法看到底層數據的存儲方式。當創建圖像對象時,軟件以特定方式安排數據,以便GPU能夠高效訪問。它們的最佳使用方式是不同的,并在接下來的部分中進行討論。
7.1.5.1 Buffer Object
緩沖區對象存儲一維元素集合:標量數據類型、矢量數據類型或用戶定義的結構體。緩沖區對象的內容通過Adreno GPU中的L2緩存由內核加載或寫入。可以使用以下API函數創建緩沖區對象:
cl_mem clCreateBuffer(cl_context contextcl_mem_flags flags,size_t size,void *host_ptr,cl_int *errcode_ret)
在這個函數中,cl_mem_flags 是一個關鍵的標志,開發人員必須小心使用,因為它可能會顯著影響性能。OpenCL允許在這個函數中使用許多不同的標志,對于Adreno GPU,以下是一些關鍵點:
- 一些標志可能會導致額外的內存復制。盡量使用第7.4節中描述的零拷貝標志。
- 一些標志適用于具有專用GPU內存的臺式機/獨立GPU。
使用最準確的標志:
- 總體思路是,標志越嚴格,OpenCL軟件越有可能找到對象的最佳配置。
- 例如,OpenCL軟件可以應用最適合內存對象的緩存刷新策略(write-through、write-back等),以在緩存刷新時產生最小的開銷。
- 第7.4.2節詳細介紹了緩存策略及其對性能的影響。以下是一些示例:
- 如果內存只能由主機進行讀取,則使用 CL_MEM_HOST_READ_ONLY。
- 如果內存對主機沒有訪問權限,則使用 CL_MEM_HOST_NO_ACCESS。
- 如果內存僅用于主機寫入,則使用 CL_MEM_HOST_WRITE_ONLY
7.1.5.2 Image Object
圖像對象存儲1D、2D或3D紋理、frame buffer 或圖像數據,圖像對象內部的數據布局是不透明的。在實際應用中,對象中的內容不一定與實際圖像數據相關聯。任何數據都可以存儲為圖像對象以利用Adreno中的硬件紋理引擎及其L1緩存。使用以下API可以創建圖像對象:
cl_mem clCreateImage(cl_context context,cl_mem_flags flags,const cl_image_format *image_format,const cl_image_desc *image_desc,void *host_ptr,cl_int *errcode_ret)
請注意,圖像的 cl_mem_flags 具有與前一節討論的緩沖區對象類似的經驗法則。
Adreno GPU支持許多圖像格式和數據類型。隨著版本迭代,又增加了更多的圖像格式和數據類型。開發人員可以使用函數 clGetSupportedImageFormats 獲取設備上可用的完整圖像格式/數據類型列表。為了充分利用內存帶寬,開發人員應該使用長度為128位的配對,例如 CL_RGBA/CL_FLOAT、CL_RGBA/CL_SIGNED_INT32 等。
Adreno GPU還通過供應商擴展支持OpenCL標準中沒有的格式,比如YUV和壓縮格式。除了新格式外,許多新函數也對圖像對象進行了硬件加速,例如 box filtering、SAD和SSD。更多詳情,請參考第9章
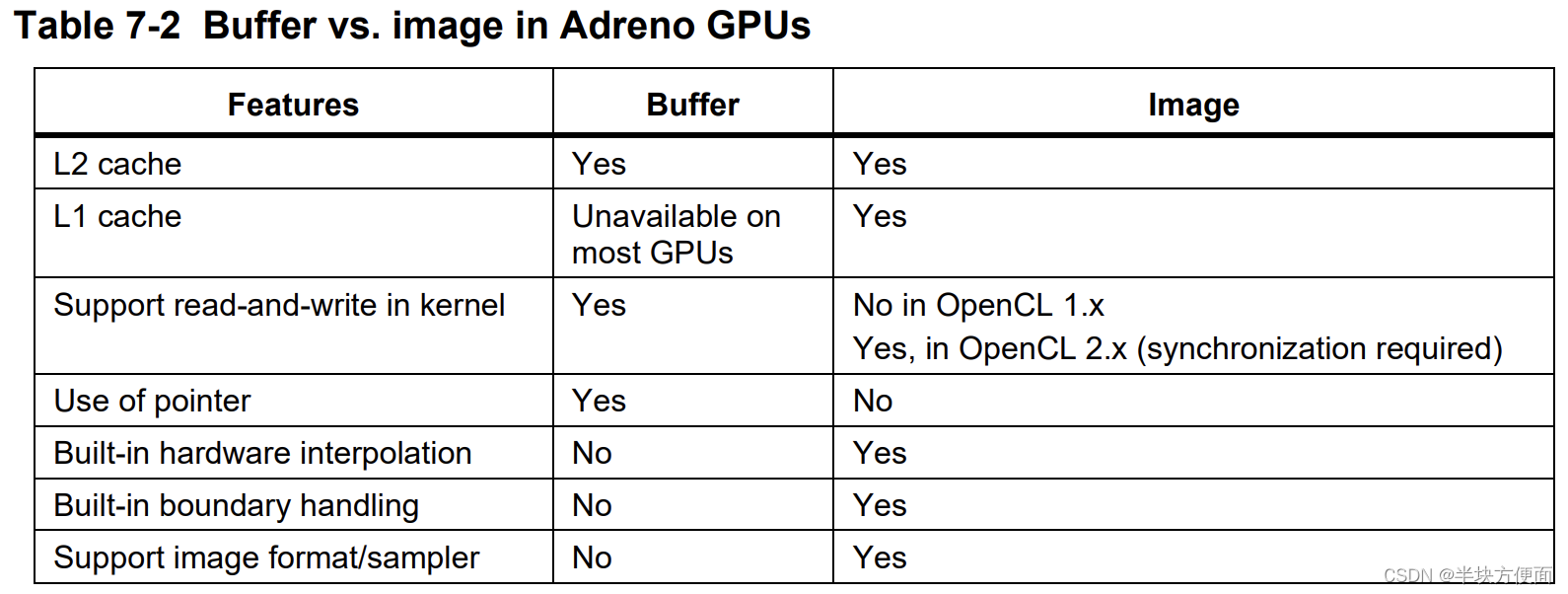
7.1.5.3 Image object vs. buffer object
如第6.2節所述,由于具有強大的紋理引擎、專用L1緩存和自動處理越界訪問(這有時候并不是一件好事)等多種優勢,Adreno GPU在處理圖像對象時比緩沖對象表現更好。Adreno GPU支持許多圖像格式和數據類型的組合,并且能夠進行自動格式轉換。
OpenCL支持兩種采樣器濾波器,即CLK_FILTER_NEAREST和CLK_FILTER_LINEAR。對于CLK_FILTER_LINEAR,適當的圖像類型組合允許GPU使用其內置的紋理引擎進行自動雙線性/三線性插值。例如,假設一個圖像是CLK_NORMALIZED_COORDS_TRUE和CL_UNORM_INT16,即圖像數據為2字節無符號短整型。要執行read_imagef,Adreno GPU執行以下操作:
- 圖像對象通過L1緩存讀取像素。
- 執行所有所需像素的插值。
- 將其轉換并標準化到[0, 1]的范圍內。
這對于雙線性/三線性插值操作非常方便。Adreno GPU還通過供應商擴展支持雙三次插值。有關更多詳細信息,請參考第9.3.4節。然而,有時緩沖對象可能是更好的選擇:
-
緩沖對象允許更靈活的數據訪問:
- 圖像對象只允許在像素大小的粒度進行訪問,例如,128位的 32-bit/channel 的 RGBA 圖像。
- Adreno支持對緩沖對象進行靈活訪問,其中指針提供了在數據訪問方面極大的靈活性。
-
L1 緩存成為瓶頸
- 例如,嚴重的 L1 緩存抖動, 使得 L1 緩存訪問變得低效
-
緩沖對象允許在內核中進行讀寫操作。在內核中支持帶有__read_write限定符的讀寫圖像(即圖像對象)。由于同步要求,一些舊一代的Adreno GPU上,讀寫圖像的性能可能不如緩沖區好。
7.1.5.4 Use of both Image and buffer objects
充分利用 L2 cache<=>SP 和 L2 cache<=>TPL1<=>SP 兩種方法是更好的方法,由于TPL1具有L1緩存,將最常用但相對較小的數據存儲在L1緩存中是一個良好的做法。
7.1.5.5 Global memory vs. local memory
一種典型的本地內存使用情況是首先將數據加載到本地內存中,同步以確保數據準備就緒,然后工作組中的工作項可以使用它進行處理。然而,使用全局內存可能比使用本地內存更好,原因如下:
- 它可能具有更好的L2緩存命中率和更好的性能。
- 代碼比使用本地內存更簡單,并且具有更大的工作組大小(local memory 只對應于一個 workgroup)。
7.2 優化內存 load/store
在前面的部分中,我們討論了如何使用不同類型的內存的一般指導原則。在本節中,我們將回顧一些關于內存加載/存儲對性能至關重要的關鍵要點。
7.2.1 Coalesced memory load/store
合并加載/存儲指的是從多個相鄰的工作項中合并加載/存儲請求的能力,如第3.2.4節中所述,用于本地內存訪問。合并訪問對于全局內存的加載/存儲同樣至關重要。
合并存儲的工作方式類似于讀取,只是加載是一個雙向過程(請求和響應),而存儲是一個單向過程,通常不會阻塞內核執行。對于大多數用例來說,數據加載遠遠大于數據存儲。因此,合并加載通常比存儲更為關鍵。
Adreno GPU支持對全局內存和本地內存進行合并訪問,但不支持對私有內存進行合并訪問。
7.2.2 Vectorized load/store
矢量化加載/存儲指的是為單個工作項進行的多個數據加載/存儲矢量化操作。這與合并訪問不同,合并訪問是為了各種工作項。以下是使用矢量化加載/存儲的一些關鍵要點:
- 每個工作項應以多個字節的塊加載數據,例如,64/128位。這樣可以更好地利用帶寬。
- 例如,多個8位數據可以手動打包成一個元素(例如,64位/128位),然后使用vloadn加載,再使用as_typeN函數(例如,as_char16)進行解包。
- 請參見第10.3.3節中的矢量化操作示例。
- 為了優化 SP 對L2緩存的帶寬利用率,加載/存儲的內存地址應該是32位對齊的。
- 有兩種方法進行矢量化加載/存儲:
- 使用 built-in function (例如vload/vstoren)。
- 或者,可以使用指針轉換來進行矢量化加載/存儲,如下所示:
char *p1; char4 vec;
vec = *(char4 *)(p1 + offset)
- 使用最多四個分量的矢量化加載/存儲指令。具有超過四個分量的矢量化數據類型加載將被分成多個加載/存儲指令,每個指令最多處理四個分量。
- 避免一個工作項加載過多的數據
- 加載過多的數據可能導致更高的寄存器占用,從而導致較小的工作組大小,并影響性能。
- 在最壞的情況下,這可能導致寄存器溢出,即編譯器必須使用系統RAM來存儲變量。
矢量化ALU(算術邏輯單元)計算也可以提高性能,盡管通常不如矢量化內存加載/存儲的提升明顯。
7.2.3 Optimal data type
數據類型至關重要,它不僅影響內存流量,還影響ALU操作。以下是一些數據類型的規則:
- 在應用程序流水線的每個階段檢查數據類型,并確保在整個流水線中使用的數據類型是一致的。
- 如果可能的話,使用較短的數據類型,以減少內存獲取(帶寬),并增加可用于執行的ALU數量。
7.2.4 16-bit vs. 32-bit data type
在Adreno GPU上強烈推薦使用16位數據類型而不是32位數據類型,原因如下:
- 16位ALU操作的計算能力(以gflops為單位)是32位操作的兩倍,這要歸功于Adreno對于16位ALU計算的專用硬件加速邏輯。
- 與32位數據的加載/存儲相比,16位數據的加載/存儲可以節省一半的帶寬。
特別是對于一些機器學習和圖像處理用例,16位浮點數,也稱為半浮點(FP16),是非常理想的。請注意,與32位浮點數據(FP32)相比,16位半浮點的數據范圍和精度更為受限。例如,它只能準確地表示整數值范圍在[0, 2048]內。開發人員必須意識到精度損失的問題。
另一種使用16位的方式是將數據加載/存儲為16位,而計算部分可以使用32位,如果精度損失是不可接受的。與使用32位數據相比,這將節省一半的內存流量這是相當不錯的提議。
7.3 Atomic functions in OpenCL 1.x
OpenCL 1.x支持本地和全局原子函數,包括atomic_add、atomic_inc、atomic_min、atomic_max等。請注意,此處討論的原子函數與第7.5節中的共享虛擬內存(SVM)中的原子函數不同。Adreno GPU在硬件上支持所有這些函數。在使用原子函數時,請注意以下一些規則:
- 避免讓多個工作項頻繁地對單個全局/本地內存地址執行原子操作。
- 原子操作是串行且不可分割的操作,可能需要在內存地址上進行鎖定和解鎖。
- 因此,不建議讓多個工作項對單個地址進行原子操作。
- 盡量首先進行歸約操作,例如,首先使用本地原子操作,然后以原子方式對全局內存進行單一更新。
- 在Adreno GPU中,每個SP都有自己的本地內存原子引擎。如果使用全局內存原子操作且它們的地址相同,首先執行本地原子操作有助于減少訪問沖突。
7.4 Zero copy
Adreno OpenCL提供了一些機制,以避免在主機端可能發生的昂貴內存復制。根據內存對象的創建方式,存在一些選項來防止過多的復制。本節描述了實現零拷貝的一些基本方法,第7.5節介紹了一種更高級的使用共享虛擬內存(SVM)的技術。
7.4.1 使用內存映射而不是 COPY
假設OpenCL應用程序完全控制數據流,即 target 和 source 內存對象的創建都由OpenCL應用程序管理。對于這種簡單情況,可以通過以下步驟避免內存復制:
- 在創建 buffer / image 對象時,使用標志 CL_MEM_ALLOC_HOST_PTR,并按照以下步驟進行:
-
首先,在調用 clCreateBuffer 時設置 cl_mem_flags 輸入:
cl_mem Buffer = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR,sizeof(cl_ushort) * size,NULL,&status); -
然后使用 map 函數返回指向主機的指針:
cl_uchar *hostPtr = (cl_uchar *)clEnqueueMapBuffer( commandQueue,Buffer,CL_TRUE,CL_MAP_WRITE,0,sizeof(cl_uchar) * size,0, NULL, NULL, &status); -
主機使用指針 hostPtr 更新緩沖區。
- 例如,主機可以將相機數據填充到緩沖區中,或從磁盤中讀取數據到緩沖區
-
取消映射
status = clEnqueueUnmapMemObject(commandQueue, Buffer, (void *) hostPtr,0, NULL, NULL); -
OpenCL內核可以使用這個對象。
-
在這種情況下,CL_MEM_ALLOC_HOST_PTR 是避免復制數據的唯一方法。對于其他標志,如 CL_MEM_USE_HOST_PTR 或 CL_MEM_COPY_HOST_PTR,驅動程序將不得不執行額外的內存復制以便GPU訪問
7.4.2 避免為非由OpenCL分配的對象進行內存復制
7.4.2.1 ION/dmabuf memory extensions
假設一個內存對象最初是在OpenCL API的范圍之外創建的,并且是使用 ION/DMA-BUF 進行分配的。在這種情況下,開發人員可以使用 cl_qcom_ion_host_ptr 或 cl_qcom_dmabuf_host_ptr 擴展來創建 buffer / image 對象,這些對象映射到 GPU 可訪問的內存,而不需要額外的復制。
ION(Input/Output Memory Management Unit)是Android系統中用于管理內存的一種機制。DMA-BUF(Direct Memory Access Buffer)是Linux內核中的一種機制,用于在不同設備之間共享內存區域,而無需通過CPU的中介。
7.4.2.2 QTI Android native buffer (ANB) extension
在許多相機和視頻處理用例中,由gralloc分配的ANB(Android Native Buffer)必須在多個設備之間共享。由于這些緩沖區基于ION,因此共享是可能的。然而,開發人員需要從這些緩沖區中提取內部句柄以使用ION路徑,這需要訪問QTI(Qualcomm Technologies, Inc.)的內部頭文件。cl_qcom_android_native_buffer_host_ptr 擴展提供了一種更直接的方式,在無需訪問 QTI 頭文件的情況下與 OpenCL 共享 ANB。這使得獨立軟件供應商(ISVs)和其他第三方開發人員能夠實現對 ANB 進行零拷貝的技術。
7.4.2.3 Android Hardware Buffer (AHB) extension
類似于上面描述的ANB擴展,cl_qcom_android_ahardwarebuffer_host_ptr 擴展提供了一種簡單的方法,可以在無需提取內部ION句柄的情況下與OpenCL共享AHB(Android Hardware Buffer),從而實現零拷貝的AHB應用程序。
7.4.2.4 Using standard EGL extensions
cl_khr_egl_image 擴展允許從EGL圖像創建OpenCL圖像。這帶來的主要好處有:
- 這是一個標準化的方法;使用這種技術編寫的代碼很可能在支持的其他GPU上也能正常工作。
- 與此擴展一起使用的EGL/CL擴展(如 cl_khr_egl_event 和 EGL_KHR_cl_event)使更有效的同步變得可能。
- 使用 EGL_IMG_image_plane_attribs 擴展,對YUV(色度亮度分量)的處理變得更加容易。
7.5 Shared virtual memory (SVM)
作為引入到OpenCL 2.0標準的一個重要和高級功能,SVM(Shared Virtual Memory)允許主機和設備共享和訪問相同的內存空間,避免過多的數據復制,例如,現在可以在OpenCL設備上訪問主機指針。
SVM有幾種類型,GPU可以選擇支持。從Adreno A5x GPU開始,支持粗粒度的SVM和更高級的帶有原子操作的細粒度緩沖區SVM。
- 對于粗粒度SVM,內存一致性僅在使用映射/解映射函數(即 clEnqueueSVMMap 和 clEnqueueSVMUnMap)的同步點上得到保證。
-
因此,粗粒度SVM類似于第7.4.1節中描述的零拷貝技術,因為它們都需要映射和解映射操作。
-
盡管如此,粗粒度SVM允許應用程序在主機和設備之間使用和共享基于指針的數據結構。
-
- 細粒度緩沖區SVM消除了粗粒度SVM中映射/解映射同步的要求。
- 細粒度緩沖區SVM是一種“無映射”SVM,即主機和設備可以同時修改相同的內存區域。
- 盡管如此,它仍然需要一定程度的同步。
- 取決于主機和設備之間的數據訪問模式,可能需要不同類型的同步。
- 如果在主機和設備之間對相同數據沒有讀寫依賴關系,例如,主機和設備正在處理SVM內存對象的不同部分,那么就不需要原子操作/柵欄。
- 在這種情況下,內存一致性在OpenCL同步點得到保證,例如,在調用 clFinish 后,所有數據將是最新的。
- 如果存在對內存訪問順序的依賴或要求,例如主機修改了某個數據,設備需要使用新數據,則需要使用原子操作或柵欄。
- 在創建時,SVM緩沖區必須具有標志 CL_MEM_SVM_ATOMICS。
- 在內核內部,必須使用 memory_scope_all_svm_devices。
- 必須使用一組類似于C11的原子函數,并使用適當的內存作用域、順序和原子標志。
- 如果在主機和設備之間對相同數據沒有讀寫依賴關系,例如,主機和設備正在處理SVM內存對象的不同部分,那么就不需要原子操作/柵欄。
- 細粒度緩沖區SVM是一種“無映射”SVM,即主機和設備可以同時修改相同的內存區域。
開發人員需要仔細權衡SVM的利與弊。作為一項高級功能,為GPU實現SVM通常需要精密的硬件設計。實施所有這些高級數據共享和同步可能存在潛在的成本,這些成本開發人員可能未察覺到。在復雜的實際用例中,使用 SVM 的門檻相對較高。開發人員在使用SVM時應謹慎,尤其是在主機和設備之間存在大量數據依賴關系的情況下。在這種類型的用例中,同步成本可能會削弱共享虛擬內存空間的優勢。
7.6 Improve the GPU’s L1/L2 cache usage
為了實現良好的緩存利用,開發人員應該遵循以下規則:
- 了解數據加載/存儲的影響:
- 許多內核從全局內存加載的數據比要存儲的數據多得多。因此,通過執行合并加載、矢量化加載、使用圖像等方式,提高數據局部性并減少對緩存行的需求是至關重要的。
- 然而,數據存儲也可能對性能產生重大影響。
- 對于數據存儲,必須首先從系統內存加載緩存行,進行修改,然后寫回。
- 如果數據存儲的局部性較差,例如,數據寫入了太多的緩存行,內存系統必須加載多個緩存行進行更新。
- 合并寫對性能至關重要,因為它可以提高局部性并減少內存系統對緩存行的需求。
- 檢查并避免緩存抖動,以提高緩存使用效率。
- 緩存抖動指的是在緩存行完全被使用之前被驅逐,然后必須重新獲取。這可能導致嚴重的性能懲罰。
- Snapdragon Profiler可以提供有關緩存訪問的信息,例如加載/存儲的字節數和緩存命中/失效比率。
- 如果加載到L2緩存的字節數遠高于內核的預期,可能存在緩存抖動。
- L1/L2命中/失效比率等指標可以告訴緩存的使用情況有多好。
- 避免抖動的方法包括:
-
調整工作組的大小和形狀。
-
更改訪問模式,例如,更改內核的維度。
-
如果在使用循環時存在緩存抖動,可以通過在循環中添加原子操作或屏障來減少緩存抖動的機會。
// 在循環中使用原子操作或柵欄同步對共享內存的讀寫,防止緩存行被切出 for (int i = 0; i < size; ++i) {barrier(CLK_GLOBAL_MEM_FENCE);atomic_operation(&shared_memory[i]);barrier(CLK_GLOBAL_MEM_FENCE); }
-
性能分析工具依賴于硬件性能計數器來生成有關緩存使用情況的指標。由于性能計數器旨在傳達有關硬件的信息,因此派生的指標,如L1/L2緩存命中率,可能會產生非直觀的結果。例如,可能會看到% L2命中率是大幅的負值,表明加載到緩存中的數據量超過了請求的量。在這類情況下,程序員應該關注性能指標值在優化之間的相對變化,而不是指標的絕對值。
7.7 CPU cache operations
現代SOC(系統芯片)具有多級緩存,驍龍SOC也不例外。對于開發人員來說,了解SOC中GPU/CPU緩存操作的基礎知識是有幫助的。
OpenCL驅動程序必須在適當的時候刷新或使CPU緩存無效,以確保對于可緩存的內存對象,當CPU和GPU嘗試訪問數據時,它們都看到最新的數據副本。例如,當將內核的輸出緩沖區映射到由主機CPU進行讀取時,必須使CPU緩存無效。
OpenCL軟件具有復雜的CPU緩存管理策略,該策略試圖通過在每個內存對象的基礎上跟蹤數據可見性并盡可能推遲操作來最小化緩存操作的數量。例如,在啟動內核之前,可能會對輸入緩沖區進行CPU緩存刷新。
CPU緩存操作的成本是可以明確測量的,通常可通過觀察clEnqueueNDRangeKernel的CL_PROFILING_COMMAND_QUEUED和CL_PROFILING_COMMAND_SUBMIT之間的時間差來體現,如圖4-1所示。在某些情況下,clEnqueueMapBuffer/Image和clEnqueueUnmapBuffer/Image的執行時間可能會增加。總的來說,CPU緩存操作的成本通常隨著內存對象的大小呈線性增長。
以下是減小CPU緩存操作成本的一些建議:
- 應該設計應用程序的結構,以便不頻繁地在CPU和GPU之間移動處理。
- 此外,應用程序應該分配內存對象,以便需要在CPU和GPU之間進行交替訪問的數據與僅有一個訪問轉換的數據位于不同的內存對象中。
- 內存對象應該使用適用于其預期使用方式的適當CPU緩存策略創建:
- 在為緩沖區或圖像對象分配內存時,驅動程序將選擇CPU緩存策略。默認的CPU緩存策略是寫回(write-back)。
- 但是,如果在標志中指定了CL_MEM_HOST_WRITE_ONLY或CL_MEM_READ_ONLY中的任何一個,驅動程序將假定應用程序不打算使用主機CPU讀取數據。在這種情況下,CPU緩存策略被設置為寫合并(write-combine)。
- 對于外部分配的內存對象,如ION和ANB機制(參見第7.4.2節),應用程序對CPU緩存策略具有更多、更直接的控制。
- 當將這些對象導入到OpenCL時,應用程序必須正確設置CPU緩存策略標志。
7.8 減少能耗
電源和能耗是移動應用的重要因素。在性能最佳的應用可能不具備最佳的功耗/能效性能,反之亦然。因此,了解功耗/能耗和性能需求至關重要。以下是幾個減少OpenCL功耗和能耗的建議:
- 盡量避免
內存復制,例如,使用ION內存實現零復制,并在使用clCreateBuffer創建緩沖區時使用CL_MEM_ALLOC_HOST_PTR。此外,避免使用進行數據復制的OpenCL API。 - 最小化主機和設備之間的內存交互,例如,
在常量或本地內存中存儲數據,使用較短的數據類型,降低數據精度,消除私有內存使用等。 優化內核并提高其性能。通常,內核運行得越快,消耗的能量或功率就越少。- 減少軟件開銷。例如,
事件驅動的流水線降低了主機和設備通信的開銷。避免創建過多的OpenCL對象,并避免在內核執行之間創建或釋放OpenCL對象。
clEnqueueNDRangeKernel
參數解析
總結
內存使用事項,有點長,但建議看一下,關于 clEnqueueNDRangeKernel 的信息在兩個鏈接中查看,也比較簡單。






)



)


批量將橫向文本改豎向)





