目錄
???????概述
概念:
單列索引
普通索引
創建索引
查看索引
刪除索引
唯一索引
創建唯一索引
刪除唯一索引
主鍵索引
組合索引
創建索引
全文索引
概述
使用全文索引
空間索引
內部原理
相關算法:
hash算法
二叉樹算法
平衡二叉樹
?Btree樹算法
MylSAM引擎使用B+Tree
InnoDB引擎使用B+Tree
特點總結
優點
缺點
使用原則
概述
概念:
- 索引是通過某種算法,構建出一個數據模型,用于快速找出在某個列中有一特定值的行,不使用索引,MySQL必須從第一條記錄開始讀完整個表,直到找出相關的行,表越大,查詢數據所花費的時間就越多,如果表中查詢的列有一個索引,MySQL能夠快速到達一個位置去搜索數據文件,而不必查看所有數據,那么將會節省很大一部分時間。
- 索引類似一本書的目錄,比如要查找'student'這個單詞,可以先找到s開頭的頁然后向后查找,這個就類似索引。
? - 按照實現方式可以分為hash索引、B+tree索引
單列索引
單列索引:一個索引只包含單個列,但一個表中可以有多個單列索引;
?
普通索引
普通索引:MySQL中基本索引類型,沒有什么限制,允許在定義索引的列中插入重復值和空值,純粹為了查詢數據更快一點。
創建索引
-- 方式1 創建表的時候直接指定
create table student(sid int primary key,card_id varchar(20),name varchar (20),gender varchar (20),age int,birth date,phone_num varchar(20),score double,index index_name(name) -- 給name列創建索引
)-- 方式2 直接創建
create index index_gender on student(gender);-- 方式3 修改表結構(添加索引)
alter table student add index index_age(age);查看索引



-- 1、查看數據庫所有索引
-- select * from mysql.innodb_index_stats a where a.database_name = '數據庫名'
select * from mysql.innodb_index_stats a where a.database_name = 'mydb2';-- 2、查看表中所有索引
-- select * from mysql.innodb_index_stats a where a.database_name = '數據庫名' and a.table_name like '%表名%';
select * from mysql.innodb_index_stats a where a.database_name = 'mydb2' and a.table_name like '%student%';-- 3、查看表中所有索引
-- show index from 表名
show index from student;刪除索引

-- 刪除索引
drop index index_name on student;alter table student drop index index_gender; 唯一索引
- 唯一索引與前面的普通索引類似,不同的就是:
- 索引列的值必須唯一,但允許有空值。如果是組合索引,則列值的組合必須唯一。它有以下幾種創建方式:
創建唯一索引

刪除唯一索引

主鍵索引
- 每張表一般都會有自己的主鍵,當我們在創建表時,MySQL會自動在主鍵列上建立一個索引,這就是主鍵索引。主鍵是具有唯一性并且不允許為NULL,所以他是一種特殊的唯一索引。
組合索引
- 組合索引也叫復合索引,指的是我們在建立索引的時候使用多個字段,例如同時使用身份證和手機號建立索引,同樣的可以建立為普通索引或者是唯一索引。
- 復合索引的使用復合最左原則。
創建索引

-- 組合索引
create index index_phone_name on student(phone_num,name);-- 刪除索引
drop index index_phone_name on student;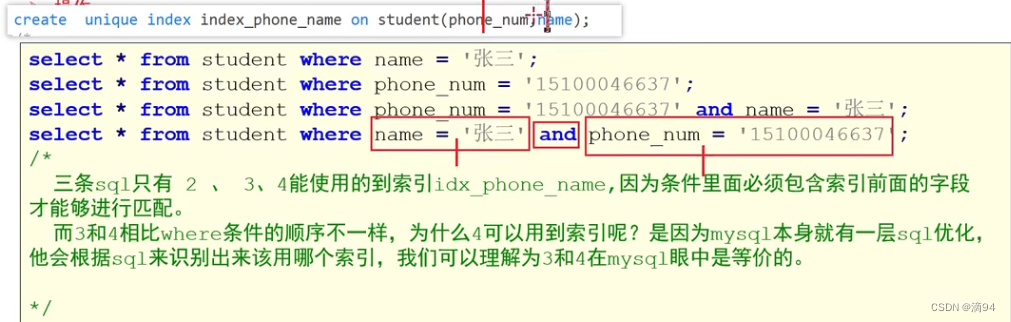
全文索引
概述
- 全文索引的關鍵字是fulltext
- 全文索引主要用來查找文本中的關鍵字,而不是直接與索引中的值相比較,它更像是一個搜索引擎,基于相似度的查詢,而不是簡單的where語句的參數匹配。
- 用like +%就可以實現模糊匹配了,為什么還要全文索引? like +%在文本比較少時是合適的,但是對于大量的文本數據檢索,是不可想象的。全文索引在大量的數據面前,能比 like +%快N倍,速度不是一個數量級,但是全文索引可能存在精度問題。
- 只有字段的數據類型為char、varchar、text及其系列才可以建全文索引;
- 在數據量較大時候,現將數據放入一個沒有全局索引的表中,然后再用create index創建fultext索引,要比先為一張表建立fulltext然后再將數據寫入的速度快很多
- 測試或使用全文索引時,要先看一下自己的MysQL版本、存儲引擎和數據類型是否支持全文索引。
- MySQL中的全文索引,有兩個變量,最小搜索長度和最大搜索長度,對于長度小于最小搜索長度和大于最大搜索長度的詞語,都不會被索引。通俗點就是說,想對一個詞語使用全文索引搜索,那么這個詞語的長度必須在以上兩個變量的區間內。這兩個的默認值可以使用以下命令查看:?show variables like '%ft%'
使用全文索引

create table t_article(id int primary key auto_increment,title varchar(255),content varchar(1000),writing_data date-- fulltext(content) 可以在這里創建全文索引,但是效率比較低
)insert into t_article values(null, "Yesterday Once NMore","when 1 was young 1 listen to the radi " , '2021-10-01');
insert into t_article values(null, "Right Here waiting" ,'oceans apart,day after day,and I slowly go insane',' 2021-10-02' );
insert into t_article values(null, "ly Heart will Go on", " every night in my dreams,i see you, i feel you",' 2021-10-03');
insert into t_article values(null, 'Everything I Do',' eLook into my eyes , vou will see what you mean to me' , '2021-10-04')
insert into t_article values(null, "called To Say I Love you","say love you no new yean 's day,to celebrate" ,'2021-10-05');
insert into t_article values(null, "Nothing s Gonna Change Ny Love For You","if i had to live my life without you nearme"," 2021-10-06");
insert into t_article values(null, "Everybody", "we 're gonna bring the flavor show U how." , '221-10-07');-- 修改表結構
alter table t_article add fulltext index_content(content);-- 添加全文索引
create fulltext index index_content on t_article(content);-- 使用全文索引
select * from t_article where match(content) against('you') -- 有結果select * from t_article where match(content) against('yo') -- 沒結果select * from t_article where content like '%you%';空間索引
- MySQL在5.7之后的版本支持了空間索引,而且支持OpenGIs幾何數據模型
- 空間索引是對空間數據類型的字段建立的索引,MYSQL中的空間數據類型有4種,分別是GEOMETRY、POINT、LINESTRING、POLYGON。
- MYSQL使用SPATIAL關鍵字進行擴展,使得能夠用于創建正規索引類型的語法創建空間索引。創建空間索引的列,必須將其聲明為NOT NULL。
- 空間索引一般是用的比較少,了解即可。
?


內部原理
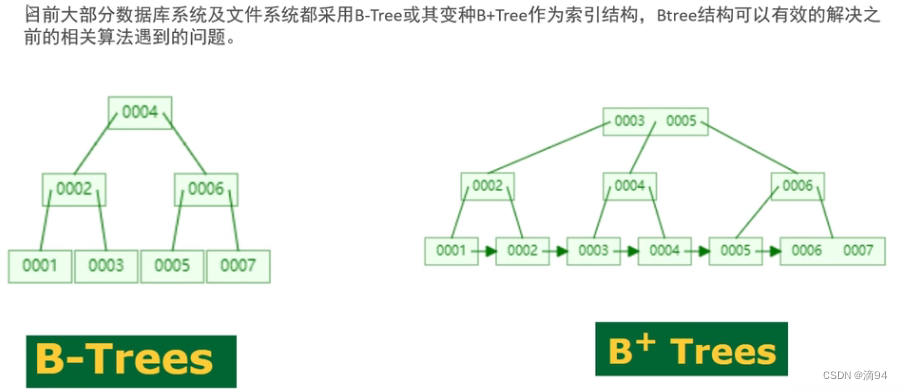
- 一般來說,索引本身也很大,不可能全部存儲在內存中,因此索引往往以索引文件的形式存儲的磁盤上這樣的話,索引查找過程中就要產生磁盤I/O消耗,相對于內存存取,I/O存取的消耗要高幾個數量級,所以評價一個數據結構作為索引的優劣最重要的指標就是在查找過程中磁盤I/O操作次數的漸進復雜度。
- 換句話說,索引的結構組織要盡量減少查找過程中磁盤I/O的存取次數。
相關算法:
hash算法

二叉樹算法

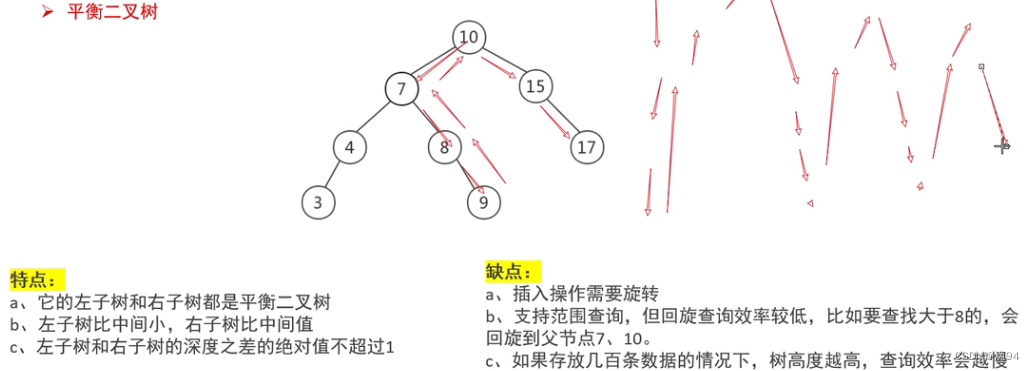
平衡二叉樹
?Btree樹算法
MylSAM引擎使用B+Tree

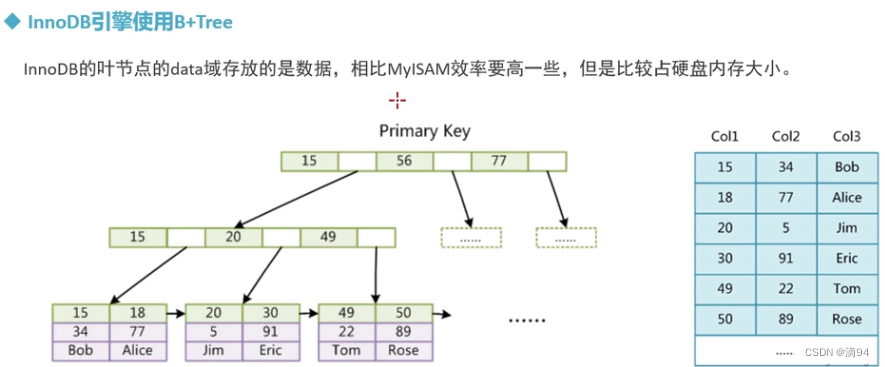
InnoDB引擎使用B+Tree
特點總結
優點
- ·大大加快數據的查詢速度
- ·使用分組和排序進行數據查詢時,可以顯著減少查詢時分組和排序的時間·創建唯一索引,能夠保證數據庫表中每一行數據的唯一性
- ·在實現數據的參考完整性方面,可以加速表和表之間的連接
缺點
- ·創建索引和維護索引需要消耗時間,并且隨著數據量的增加,時間也會增加
- ·索引需要占據磁盤空間
- ·對數據表中的數據進行增加,修改,刪除時,索引也要動態的維護,降低了維護的速度
使用原則
- 更新頻繁的列不應設置索引
- 數據量小的表不要使用索引(畢竟總共2頁的文檔,還要目錄嗎? )
- 重復數據多的字段不應設為索引(比如性別.只右里和女,一般來說:重復的數據超過百分之15就不該建索引)
- 首先應該考慮對 where 和 order by 涉及的列上建立索引

,PDE,RLE代碼)

 事務,視圖,觸發器,存儲過程)
)





【KMP】)






)

