在本專欄中,我們將討論預訓練模型。有很多模型可供選擇,因此也有很多考慮事項。
這次的專欄與以往稍有不同。我要回答的問題全部源于 MathWorks 社區論壇(ww2.mathworks.cn/matlabcentral/)的問題。我會首先總結 MATLAB Answers 上的回答,然后基于問題提出問題:大家為什么會問這些問題?
因此,本專欄將介紹如何選擇預訓練模型、如何確定是否作出了正確的選擇,并回答關于預訓練模型的三個問題:
1. 訓練網絡時,應操作數據大小還是模型輸入大小?
2. 為什么要在 MATLAB 中導入經過預訓練的 YOLO 模型?
3. 為什么要凍結預訓練模型的權重?
選擇預訓練模型
可供選擇的模型非常多,而且只會越來越多。這當然帶來很多便利,但也有些令人望而生畏:我們該如何挑選,又如何確定是否作出了正確的選擇?
與其把所有預訓練模型放在一起考慮,我們不妨將它們分成幾類。
基本模型
這些模型架構簡單,可以輕松上手。這些模型通常層數較少,支持預處理和訓練選項的快速迭代。一旦掌握了訓練模型的方法,就可以開始嘗試改善結果。
嘗試這些模型:GoogLeNet、VGG-16、VGG-19 和 AlexNet
高準確度模型
這些模型適用于基于圖像的工作流,如圖像分類、目標檢測和語義分割。大多數網絡,包括上述基本模型,都屬于此類別。與基本模型的區別在于,高準確度模型可能需要更多訓練時間,網絡結構更復雜。
嘗試這些模型:ResNet-50、Inception-v3、Densenet-201
目標檢測工作流:一般推薦基于 DarkNet-19 和 DarkNet-53 創建檢測和 YOLO 類型工作流。我也見過 ResNet-50 加 Faster R-CNN 的組合,因此多少有一些選擇余地。我們將在之后的問題中進一步討論目標檢測。
語義分割:您可以選擇一個網絡并將其轉換為語義分割網絡。也有一些專門的 Segnet 結構,如 segnetLayers 和 unetLayers。
適合邊緣部署的模型
當部署到硬件時,模型大小變得尤為重要。此類模型內存占用量較小,適合 Raspberry Pi? 等嵌入式設備。
嘗試這些模型:SqueezeNet、MobileNet-v2、ShuffLeNet、NASNetMobile
以上只是一些常規原則,為模型選擇提供基本思路。我將從第一類模型入手,之后如果需要,再選擇更復雜的模型。我個人覺得 AlexNet 是一個不錯的起點。它的架構非常容易理解,性能表現通常也不錯,當然也取決于具體問題。
選擇模型時,如何確定是否作出了正確的選擇?
對于您的任務來說,合適的模型可能不止一個。
只要模型的準確度能滿足給定任務的需求,就是一個可接受的模型。至于多高的準確度意味著“可接受”,則可能視應用不同而差異極大。
例如,購物時某寶推薦商品出錯不是什么大事,但暴風雪漏報后果就很嚴重。
針對您的應用嘗試各種預訓練網絡,方能確保獲得最準確和最穩健的模型。
當然,要實現一個成功的應用,網絡架構只是眾多因素之一。
|
|

Q1
問題 1:訓練網絡時,應操作數據大小還是模型輸入大小?
此問題來自論壇提問“如何在預訓練模型中使用灰度圖像”和“如何更改預訓練模型的輸入大小”。
-
如何在預訓練模型中使用灰度圖:?
https://ww2.mathworks.cn/matlabcentral/answers/448360-how-we-do-transfer-learning-using-pretrained-models-with-grey-scale-images-as-input
-
如何更改預訓練模型的輸入大小:?
https://ww2.mathworks.cn/matlabcentral/answers/458610-change-input-size-of-a-pre-trained-network
首先快速回顧一下模型數據輸入的相關知識。
所有預訓練模型都有一個預期,即需要什么樣的輸入數據結構,才能重新訓練網絡或基于新數據進行預測。
如果數據與模型預期不符,您就可能提出這些問題。
這就帶來了一個有趣的問題:是要操作數據,還是操作模型?
最簡單的方法是更改數據。
這很簡單:只需調整數據的大小,就可以操作數據輸入的大小。在 MATLAB? 中,使用?imresize?命令就能做到。灰度問題也變得很簡單。
彩色圖像通常采用 RGB 形式,包含三個層,分別表示紅、綠、藍三個顏色平面。灰度圖像則只包含一個層而不是三個層。只需重復灰度圖像的單個層,就可以創建網絡所期望的輸入結構,原理如下圖所示。
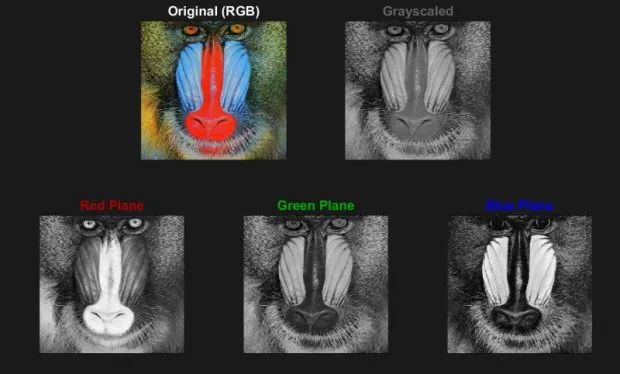
山魈照片的原始彩色圖像,經灰度處理的圖像,以及單獨顯示紅、綠、藍平面的圖像。
這是一張色彩非常豐富的圖像,可以看到,三個 RGB 平面看起來就像三張灰度圖像,它們組合在一起形成一張彩色圖像。
稍微復雜一點的方法是更改模型。為什么要大費周章地操作模型而不是數據?
因為現有的輸入數據決定了只能這樣做。
假設您的圖像是 1000×1000 像素,您的模型接受 10×10 像素大小的圖像。如果您將圖像調整到 10×10 像素,就只能得到一張充滿噪聲的輸入圖像。
在這種情況下,您需要更改模型的輸入層,而不是輸入。
圖像大小:1000×1000 像素:

圖像大小:10×10 像素

我原以為對模型輸入層進行操作會非常復雜,但在 MATLAB 里試了試,其實還好。相信我,真的不復雜。您只需完成以下操作:
1. 打開深度網絡設計器 Deep Network Designer。
2. 選擇一個預訓練模型。
3. 刪除當前輸入層,并替換為新層。這樣您就可以更改輸入大小。
4. 導出模型,直接就能在遷移學習應用中使用。我推薦按照基本遷移學習示例進行操作:
https://ww2.mathworks.cn/help/deeplearning/ug/train-deep-learning-network-to-classify-new-images.html
整個過程非常輕松,您不必手動編碼即可更改預訓練模型的輸入大小。
Q2
問題 2:為什么要在 MATLAB 中導入經過預訓練的 YOLO 模型?
此問題源于基于 COCO 數據集訓練 YOLO v3,答案很明確。背景并不復雜。
-
基于 COCO 數據集訓練 YOLO v3
https://ww2.mathworks.cn/matlabcentral/answers/553528-yolo-v3-training-on-coco-data-set
此示例介紹如何使用 ResNet-50 訓練 YOLO v2 網絡以在 MATLAB 中使用:
https://ww2.mathworks.cn/help/deeplearning/ug/object-detection-using-yolo-v2.html
YOLO 是“you only look once”的縮寫。
該算法有多個版本,相對于 v2,v3 改進了定位較小對象的功能。YOLO 從一個特征提取網絡(使用預訓練模型,如 ResNet-50 或 DarkNet-19)開始,然后進行定位。
YOLO v3: https://ww2.mathworks.cn/help/vision/ug/object-detection-using-yolo-v3-deep-learning.html
那么,為什么要在 MATLAB 中導入經過預訓練的 YOLO 模型?
YOLO 是最流行的目標檢測算法之一。與簡單的目標識別問題相比,目標檢測更具挑戰性。
對于目標檢測,面臨的挑戰不僅僅是識別目標,還要確定其位置。
有兩類目標檢測器:
單級檢測器,如 YOLO;兩級檢測器,如 Faster R-CNN。
-
單級檢測器可以實現快速檢測。這篇文檔詳細介紹了 YOLO v2 算法。
https://ww2.mathworks.cn/help/vision/ug/getting-started-with-yolo-v2.html
-
兩級檢測器:定位和目標識別準確度高這篇文檔介紹了 R-CNN 算法的基礎知識。
https://ww2.mathworks.cn/help/vision/ug/getting-started-with-r-cnn-fast-r-cnn-and-faster-r-cnn.html

值得探索的目標檢測應用有很多,不過我強烈建議從簡單的目標檢測示例開始,以此為基礎逐步推進。
Q3
問題 3:為什么要凍結預訓練模型的權重?
此問題源自如何凍結神經網絡模型的特定權重?要回答此問題,我們先看一小段代碼。
導入預訓練網絡后,您可以選擇通過以下方式凍結權重:
凍結所有初始層:
layers(1:10) = freezeWeights(layers(1:10));
凍結單個層:
layer.WeightLearnRateFactor = 0;
凍結所有允許凍結的層:
function layers = freezeWeights(layers)for ii = 1:size(layers,1)props = properties(layers(ii));for p = 1:numel(props)propName = props{p};if ~isempty(regexp(propName, 'LearnRateFactor$', 'once'))layers(ii).(propName) = 0;endend
endend
如果該層有 LearnRateFactor,則將其設置為零。其他層保持不變。
凍結權重有兩個好處,即您可以:
-
加快訓練速度。由于不需要計算已凍結層的梯度,因此凍結多個初始層的權重可以顯著加快網絡訓練速度。
-
防止過擬合。如果新數據集很小,凍結較淺的網絡層可以防止這些層對新數據集過擬合。
實際上,您也可以將一個預訓練模型的權重應用于您的模型,這樣不經訓練也能創建一個“經過訓練的”網絡。查看 MATLAB 中?assembleNetwork?的說明,了解如何不經訓練直接基于層創建深度學習網絡。
https://ww2.mathworks.cn/help/deeplearning/ref/assemblenetwork.html
最后,說到權重,對于類分布不平衡的分類問題,可以使用加權分類輸出層。請參考關于使用自定義加權分類層的示例。

)

















