嶺回歸是失損函數通過添加所有權重的平方和的乘積(L2)來懲罰模型的復雜度。
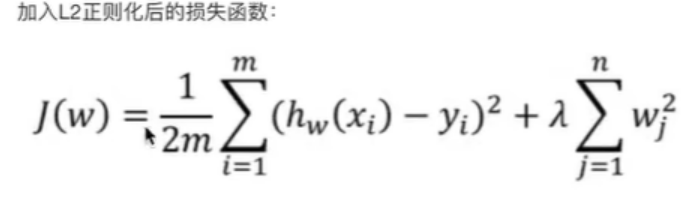
均方差除以2是因為方便求導,w_j指所有的權重系數, λ指懲罰型系數,又叫正則項力度
特點:
嶺回歸不會將權重壓縮到零,這意味著所有特征都會保留在模型中,但它們的權重會被縮小。
適用于特征間存在多重共線性的情況。
嶺回歸產生的模型通常更為平滑,因為它對所有特征都有影響。
from sklearn.linear_model import Ridge from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_california_housing from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_squared_errorx,y = fetch_california_housing(return_X_y=True,data_home = "./src")x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2,random_state = 42) scaler = StandardScaler() x_train = scaler.fit_transform(x_train) x_train = scaler.fit_transform(x_train)model = Ridge(alpha = 1,max_iter = 100,fit_intercept=True)#調節這里的alpha可以改變w model.fit(x_train,y_train)y_hat = model.predict(x_test) print("loss:",mean_squared_error(y_test,y_hat)) print("w:",model.coef_) print("b:",model.intercept_)具有L2正則化的線性回歸-嶺回歸。
sklearn.linear_model.Ridge()
1 參數:
(1)alpha, default=1.0,正則項力度
(2)fit_intercept, 是否計算偏置, default=True
(3)solver, {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
當值為auto,并且數據量、特征都比較大時,內部會隨機梯度下降法。
(4)normalize:,default=True, 數據進行標準化,如果特征工程中已經做過標準化,這里就該設置為False
(5)max_iterint, default=None,梯度解算器的最大迭代次數,默認為150002 屬性
coef_ 回歸后的權重系數
intercept_ 偏置
說明:SGDRegressor也可以做嶺回歸的事情,比如SGDRegressor(penalty='l2',loss="squared_loss"),但是其中梯度下降法有些不同。所以推薦使用Ridge實現嶺回歸





之使用教程(4)工具)
:)








)
---在獨立的應用工程里使用MPU6050)

 Tokenizer)
