這篇是我對嗶哩嗶哩up主 @霹靂吧啦Wz 的視頻的文字版學習筆記 感謝他對知識的分享
只要大家一提到深度學習
缺乏一定的解釋性
比如說在我們之前講的分類網絡當中
網絡它為什么要這么預測
它針對每個類別所關注的點在哪里呢


在great?cam這篇論文當中呢
就完美的解決了在cam這篇論文當中存在一些問題
在great?cam當中
我們既不需要修改網絡的結構
也不需要對網絡做進一步的訓練

舉個非常有意思的一個例子
這里呢我們也來簡單的聊一聊
那么首先呢作者訓練了一個二分類網絡
也就是針對護士以及醫生這兩個類別的
那對于這個帶有偏見的模型呢
首先對于護士這個類別
你會發現他預測的是正確的
然后通過我們繪制熱力圖呢
你會發現其實它主要關注的區域是在人臉的這個區域
大家想想你通過人臉就能分辨出他是醫生還是護士嗎
其實我個人覺得僅僅通過人臉是很難區分出來的
然后接下來我們再看下面這個圖
也就是它的正確標簽應該是醫生
但是我們這個帶有偏見的模型呢
它預測的結果是護士?預測錯誤
這個不帶偏見的模型
它是根據不同職業所使用的器械或者說工具
以及它的穿著來得出最終預測結果的
那么很明顯
這相比于我們僅僅通過人臉來判斷他的職業要更加的科學一些
那么再看一下這個圖
這個帶偏見的模型呢
它學到特征其實是有問題的
那么作者呢有進一步分析這個帶偏見模型它所對應的訓練的數據集
然后作者發現在這個數據集當中
護士這個類別絕大多數都是女性
所以這就導致了訓練得到這個模型
它是帶有偏見的
那么為了解決這個問題呢
作者就調整了一下訓練數據當中不同職業男女之間的一個比例
那么調整均衡之后再去訓練網絡
就得到了這個不帶偏見的模型
那么它的測試集的準確率由原來的%多
提升到了%多的明顯效果是變好了的
所以我覺得作者舉這個例子呢是值得我們大家去思考以及借鑒

cam的適用性非常強的
然后我們來看一下我剛剛提供的關于這個pytorch實現cam這個倉庫
那么在這個倉庫下呢
還提供了比如說像目標檢測以及語義分割的一些使用方法
其實作者有給出對應的一個使用教程啊
那么這里我給出針對目標檢測的語義分割的
還有針對使用像transformer模型
它的一個使用的案例
那么大家有興趣的話可以自己去看一下
那接著我們再回到我們的ppt當中
我們現在就以圖像分類這個任務為例啊
那么黑色這個箭頭呢代表的是我們正向傳播的一個過程

藍色這個箭頭呢代表的是梯度反傳的一個過程
那比如說針對我們圖像分類這個任務
假設我想看一下對于tiger?cat這個類別
我們網絡究竟關注的區域在哪
那么他就根據網絡預測的tiger?cat這個類別的數據進行一個反向傳播

這里的數據是沒有通過softmax激活的
我們就能得到針對這個特征層A的一個反向傳播的梯度信息
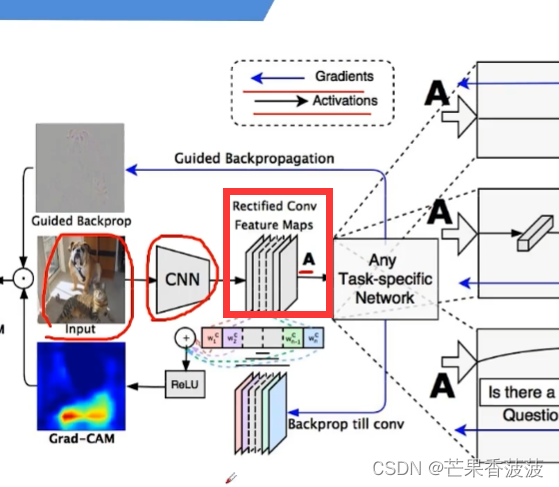
比如說我把它標記為A'

然后呢作者對這里的a撇在它的每一個通道位置上去求一個均值
那么就得到我們這里的每一個w
那這里的w呢就是針對我們這個特征層a每一個通道的一個權重
然后接下來做的再進行一個加權求和
通過relu函數得到我們最終的great?cam【還要通過relu?】
那這里呢我簡單的講一下我個人的一個看法
首先是關于得到這個特征層A是網絡對原圖進行特征提取得到的結果
那一般呢越往后的特征層它的抽象程度越高
語義信息呢也是越來越豐富
并且利用cnn過去得到這個特征層
它是能夠保留空間信息的
那么在我們得到的最終的這個特征層A上呢
它對應的激活區域差不多也是在這個位置
所以說我們聲音網絡它是能夠保留空間信息的
其實不光是cnn
包括我們最近常用的transformer模型也是一樣的
那么在原論文的圖當中呢
我們一般所說的這個特征成層A都是指的卷一層當中最后一個卷積層
它所輸出的特征層
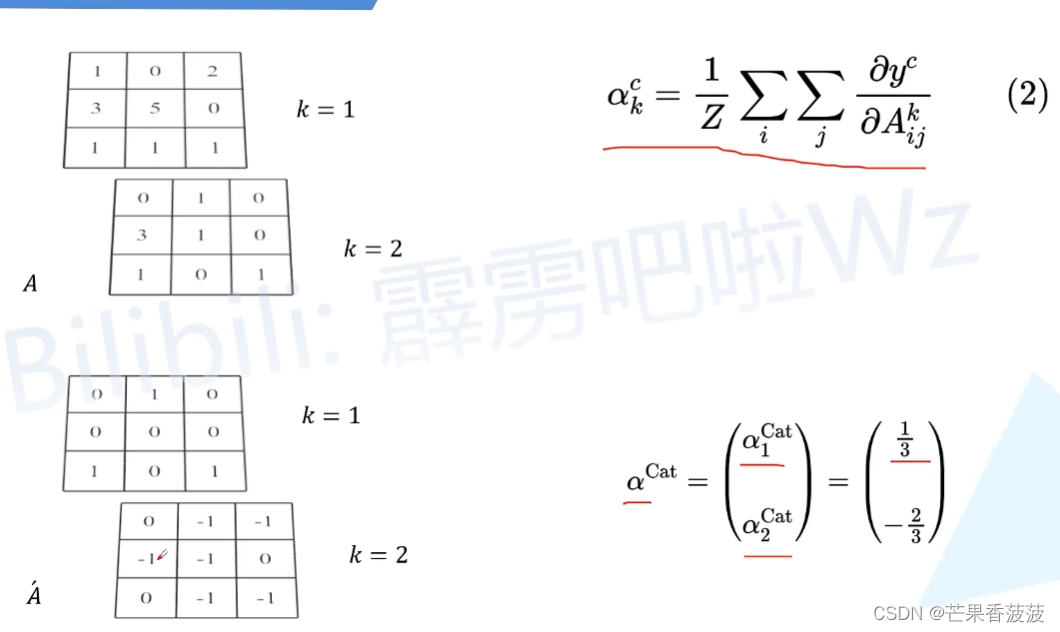
然后這里的A'是y(c)對A求得這個偏導
![]()
那么換句話說就是A'
它代表的是A中每個元素對我們最終這個y(c)結果一個貢獻值
那么貢獻越大就代表網絡認為它有越重要
所以呢接下來我們對A'在每個通道上去取均值
就能得到針對特征層A每個通道的重要程度
然后我們再進行一個加權求和
以及通過relu函數就能得到我們這里的一個cam
那么這里呢我們用公式來進行表示的話


那么接下來我們來舉個例子
方便大家理解
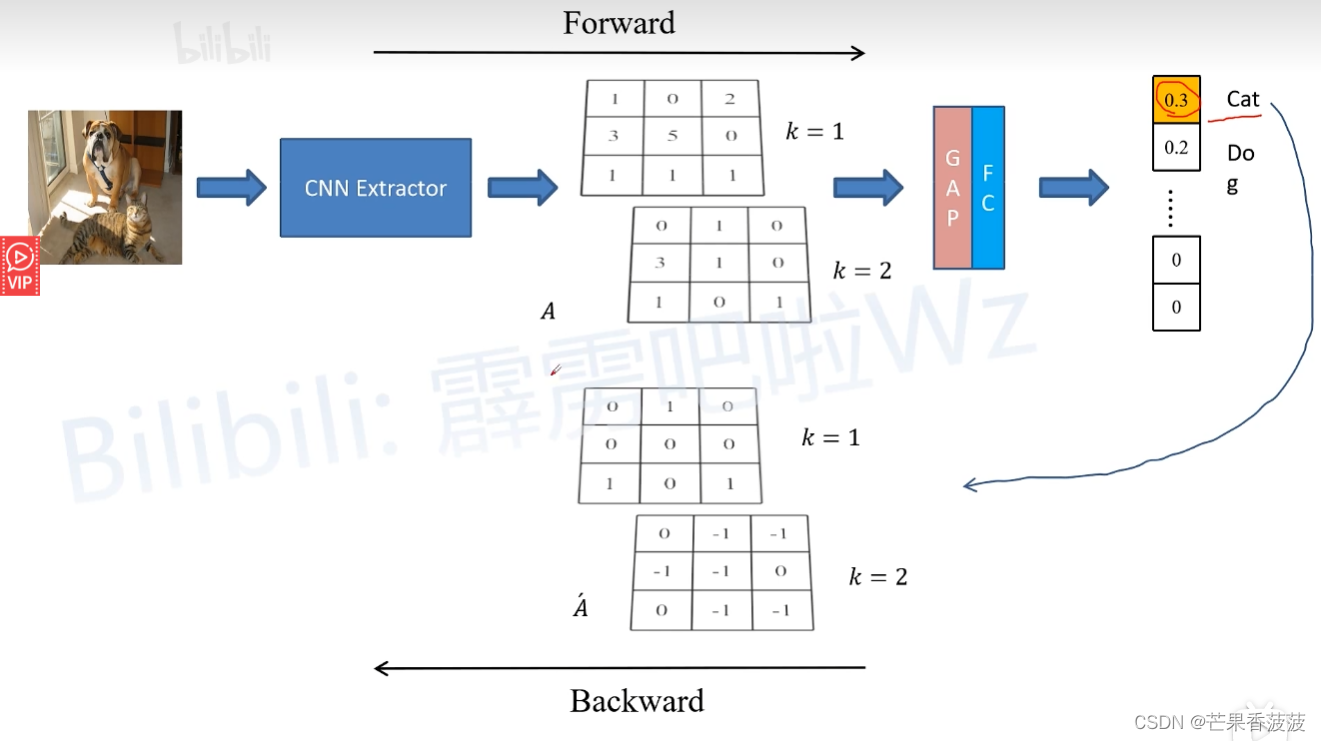
對cat類別進行反向傳播

然后我們通過relu之后呢
就將那些小于零的數據全部給設置成零
就得到我們最終的great?cam有輸出了
那么講呢肯定有人對這里的A'求解是抱有疑惑的
那如果你想了解這個A'怎么求解的話
你可以去看一下我寫這個博文
(51條消息)?Grad-CAM簡介_gradcam_太陽花的小綠豆的博客-CSDN博客
當然在我們去實現的過程當中
其實我們不需要自己去計算
因為現有的新中學框架它都會自動幫我去計算
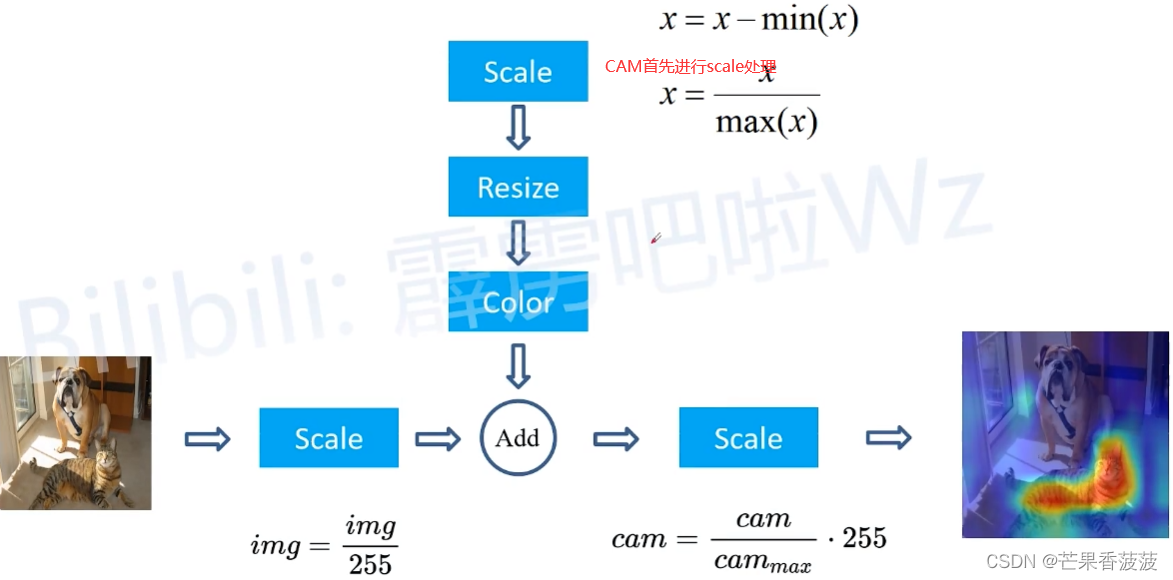
再對CAM進行resize變成原圖大小
之后再將CAM轉化成彩色形式(原CAM是單通道的非彩色)
然后將原圖scale處理
將scale后的原圖add已處理完的cam
將add后的結果再進行scale
即可得到覆蓋了cam的輸出圖片
)




函數)

)

)
UI交互邏輯的設計)








