文章目錄
- 前言
- 8.1 內核融合和拆分
- 8.2 編譯選項
- 8.3 Conformant(規范) vs. fast vs. native math functions
- 8.4 Loop unrolling
- 8.5 避免分支發散
- 8.6 Handle image boundaries
- 8.7 Avoid the use of size_t
- 8.8 通用 vs. 具名內存地址空間
- 8.9 Subgroup
- 8.10 Use of union
- 8.11 Use of struct
- 8.12 綜合
前言
這一章節提供了有關內核優化的更多細節,這些內容可能與第6章的頂級優化提示和第7章的內存優化有一些重疊。
8.1 內核融合和拆分
一個復雜的應用可能包含許多階段。對于進行 OpenCL 移植和優化的情況,人們可能會問應該使用多少個內核。這個問題很難回答,因為涉及到許多因素。以下是一些建議:
- 在內存和計算之間取得良好的平衡。
- 有足夠的波(waves)來隱藏延遲。
- 避免寄存器溢出。
開發人員可以嘗試以下操作:
- 將一個大內核拆分成多個小內核可能會更好地實現數據并行化。
- 將多個內核融合成一個內核(內核融合),如果可以通過良好的并行化來減少數據流量(工作組大小相當大)。
8.2 編譯選項
APIs clCompileProgram 和 clBuildProgram 提供了許多編譯器構建選項,用于性能優化。借助這些選項,開發人員可以根據其目的啟用一些功能。例如,使用 -cl-fast-relaxed-math 將使用快速數學運算編譯內核,而不是按照 OpenCL 規范提供的更高精度的數學運算:
clBuildProgram( myProgram, numDevices, pDevices, "-cl-fast-relaxed-math ",NULL, NULL );
Adreno GPU 還可以支持一些特定于 Adreno 的選項,以啟用特定功能,詳見第 9 章的討論。
8.3 Conformant(規范) vs. fast vs. native math functions
《OpenCL》標準在OpenCL C語言中定義了許多數學函數。默認情況下,所有的數學函數都必須符合IEEE 754單精度浮點數數學要求,這是OpenCL規范要求的。Adreno GPU具有一個內置的硬件模塊,即基本函數單元(EFU),用于加速一些原始數學函數。EFU直接不支持的許多數學函數已經通過結合EFU和ALU操作進行了優化,或者通過編譯器使用復雜算法進行了模擬。以下表格顯示了基于相對性能對OpenCL-GPU數學函數進行分類的列表。使用高性能函數(例如,類別A中的函數)是一個良好的做法。
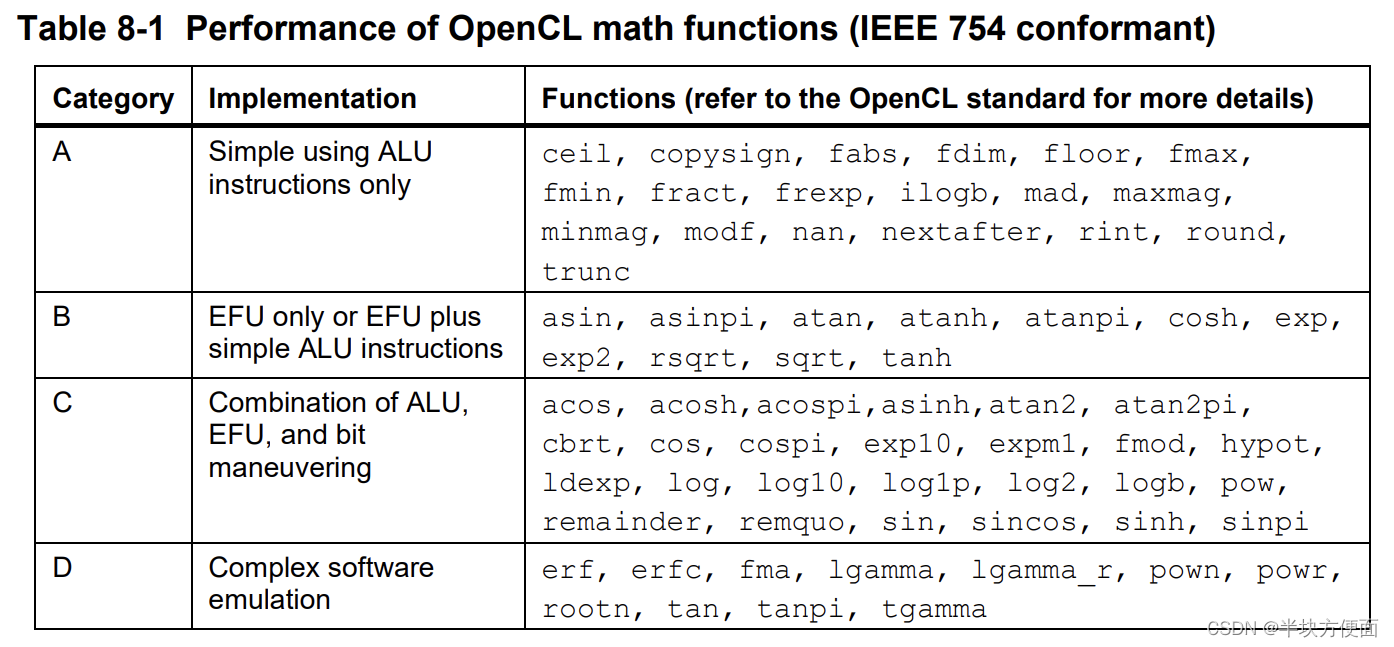
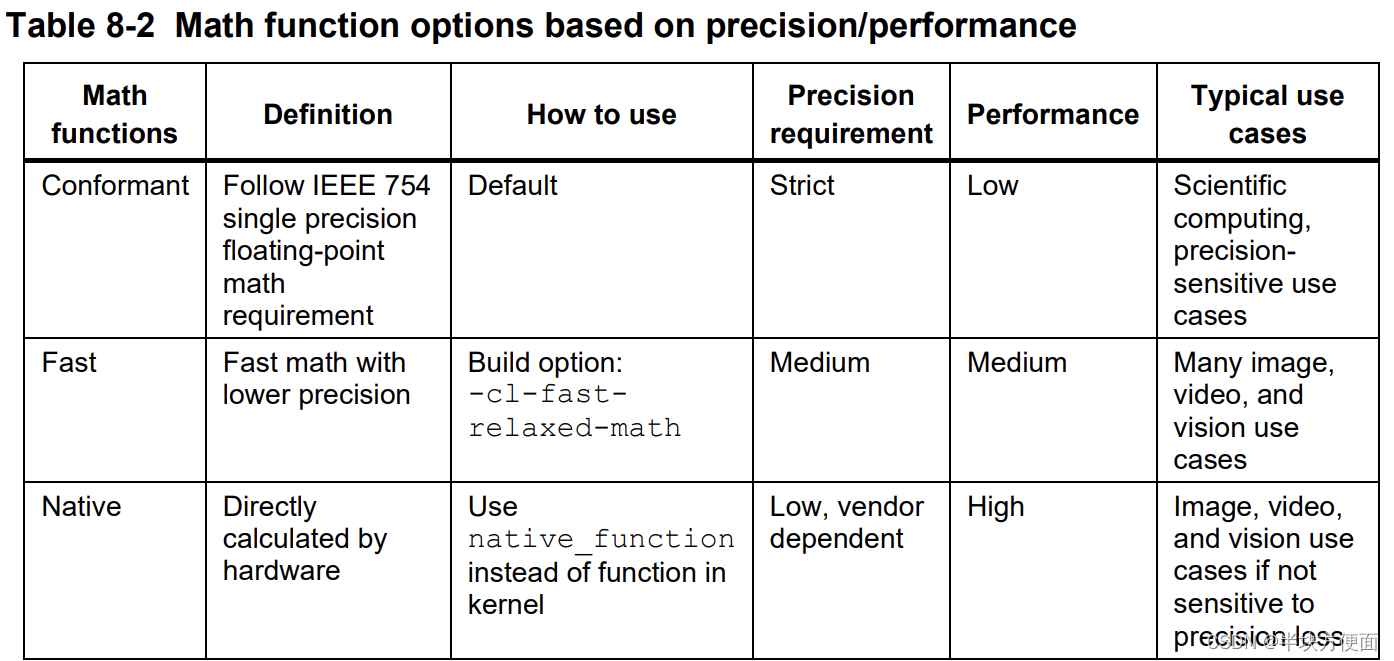
或者,如果應用程序對精度不敏感,開發人員可以使用本地或快速數學而不是符合規范的數學函數。表8-2總結了使用數學函數的這三個選項:
本地數學函數(native math function),由底層硬件(如GPU)本地支持的數學函數
- 對于快速數學,在clBuildProgram調用中啟用-cl-fast-relaxed-math。
- 使用本地數學函數:
- 具有本地實現的數學函數有 native_cos、native_exp、native_exp2、native_log、native_log2、native_log10、native_powr、native_recip、native_rsqrt、native_sin、native_sqrt、native_tan、native_divide;
- 以下是使用本地數學的示例:
- 原始:int c = a / b; // a和b都是整數
- 使用本地指令:int c = (int)native_divide((float)(a), (float)(b));
8.4 Loop unrolling
循環展開通常是一個良好的實踐,因為它可以減少指令執行成本并提高性能。Adreno編譯器通常可以根據一些啟發式方法自動展開循環。然而,也有可能編譯器選擇不完全展開循環,這取決于諸如寄存器分配預算之類的因素,或者編譯器由于缺乏知識而無法展開。在這些情況下,開發人員可以通過以下方式向編譯器提供提示或手動強制展開循環:
- 一個內核可以通過使用 attribute((opencl_unroll_hint)) 或 attribute((opencl_unroll_hint(n))) 來提供提示。
- 或者,一個內核可以使用指令 #pragma unroll 來展開循環。
- 最后的選擇是手動展開循環。
8.5 避免分支發散
通常情況下,當同一組(wave)中的工作項(work items)按照不同的執行路徑時,GPU的效率并不高。一些工作項可能需要被屏蔽(masked)以適應不同的分支,導致GPU的占用率降低,如下圖所示。此外,條件檢查的代碼,比如if-else,通常會觸發控制流硬件邏輯,這是比較昂貴的操作。
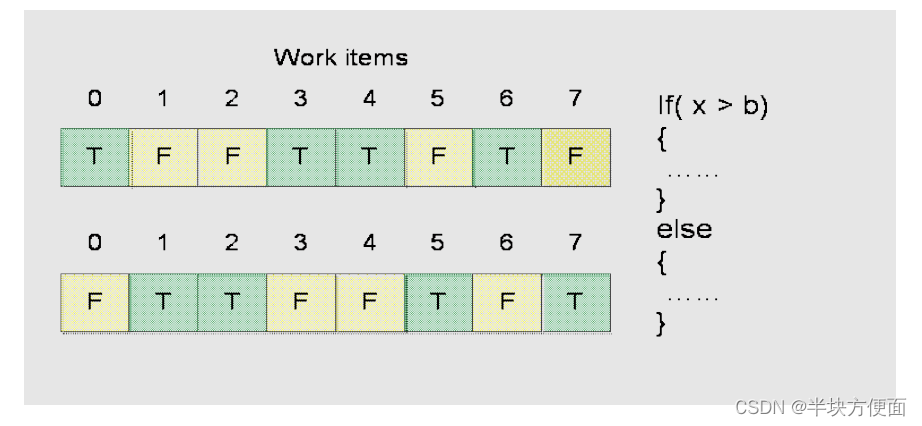
有一些方法可以避免或減少分歧和條件檢查。在算法層面上,可以將進入同一分支的工作項分組為一個非分歧的波(wave)。開發者可以將一些簡單的分歧或條件檢查操作轉換為快速的ALU操作。:
- 第10.3.6節中的一個示例展示了如何將由昂貴的控制流邏輯執行的三元操作轉換為快速的ALU操作。
- 另一種方法是使用像select這樣的函數,它可能使用快速的ALU操作而不是控制流邏輯。
8.6 Handle image boundaries
許多操作可能訪問圖像邊界之外的像素。為了更好地處理邊界,應考慮以下選項:
- 如果可能的話,提前對圖像進行填充。
- 使用具有良好取樣器的圖像對象(紋理引擎會自動處理)。
- 編寫單獨的內核來處理邊界,或者讓CPU處理邊界像素。
8.7 Avoid the use of size_t
在許多情況下,64位內存地址對于OpenCL內核編譯可能會帶來復雜性,開發者必須謹慎。開發者應避免在內核中將變量定義為size_t類型。對于64位操作系統,內核中定義為size_t的變量可能必須被處理為64位長整型。Adreno GPU必須使用兩個32位寄存器來模擬64位。因此,具有size_t變量需要更多的寄存器資源,這通常會導致性能下降,因為激活的波浪較少,工作組大小較小。因此,開發者應該使用32位或更短的數據類型,而不是size_t。
對于在OpenCL中返回size_t的內置函數,編譯器可能會嘗試根據其知識推導并限制其范圍。例如,get_local_id返回結果為size_t,盡管local_id永遠不會超過32位。在這種情況下,編譯器使用了一個較短的數據類型。然而,通常最好為編譯器提供最佳的數據類型,以獲得更好的寄存器使用和代碼質量。
8.8 通用 vs. 具名內存地址空間
自OpenCL 2.0以來引入了一種稱為通用內存地址空間的特性。在OpenCL 2.0之前,指針必須指定其內存地址空間,比如local、private或global。通用內存允許在內核中不設置指針的地址空間,GPU會在內核執行期間確定實際的地址空間。這一特性使開發人員能夠重用和減少代碼基礎,尤其適用于庫開發等任務。
使用通用內存地址空間可能會帶來性能損失,因為與識別內存空間相關的硬件成本。以下是一些建議關于內存地址空間的使用:
- 如果事先知道,開發人員應明確指定內存地址空間。這將減少編譯器的歧義,避免GPU硬件識別實際內存空間的成本。
- 盡量避免工作項使用不同的內存地址空間。對于統一(固定)的情況,編譯器可能能夠提取內存空間并避免硬件識別其內存空間。
- 準備不同內存地址空間的不同版本代碼。
8.9 Subgroup
OpenCL 2.0引入的新子組函數提供了比工作組更精細的對工作項的控制。一個工作組包含一個或多個子組,而在Adreno GPU中,子組與波(wave)概念對應。與1D/2D/3D工作組相比,子組只有一個維度。與工作組類似,一組函數允許工作項在子組內查詢其本地ID和其他參數。
子組的強大之處在于OpenCL引入了一套豐富的函數,允許子組中的工作項共享數據并在子組內進行各種操作。沒有這個特性,工作項之間的數據共享可能不得不依賴于本地或全局內存,而這通常是昂貴的。
如何實現子組功能取決于硬件供應商。它可以通過硬件加速或通過軟件仿真來實現。在Adreno GPU中,許多子組功能都是通過硬件加速的。
除了核心OpenCL中的子組功能之外,OpenCL 3.0還有關于子組的KHR擴展。在使用這些擴展之前,檢查擴展的可用性是非常重要的。
子組功能大致可以分為兩種類型:規約和洗牌。
- 規約:Adreno具有硬件支持的規約功能,比通過本地內存進行規約要快得多。
- 洗牌:洗牌允許數據從一個工作項傳遞到另一個工作項。通常支持shuffle-up, shuffle-down, and generic shuffle.
除了對標準子組函數的支持,Adreno GPU 還通過供應商擴展支持子組規約和洗牌功能。
8.10 Use of union
雖然聯合(union)是 OpenCL 內核語言中的一個標準特性,但在 Adreno GPU 上它是低效的。編譯器需要分配額外的寄存器來處理不同大小的成員,因此性能通常較不使用聯合的常規內核更差。開發者在 Adreno GPU 上應避免使用聯合。
8.11 Use of struct
結構體(struct)可以使代碼更易于理解和組織,是將一組相關變量組織到一個地方的絕佳方式。盡管有這些優點,但在 Adreno GPU 上使用結構體可能會引起一些效率問題,因此不總是建議使用。以下是一些建議:
- 盡量避免在結構體內部使用指針。
- 明確分配單個成員,而不是將整個結構體變量分配給另一個變量。
- SoA(struct of array,結構體,元素是數組) 或 AoS(array of struct,數組,元素是結構體):
- 一個關鍵考慮因素是選擇是否能夠緩解內核的瓶頸。
- 例如,如果數組可以安排得使得從內存加載數據具有更好的合并性,那么結構體數組是一個更好的選擇。
- 如果結構體中的成員導致良好的緩存局部性,那么數組結構體可能是一個更好的選擇。
8.12 綜合
許多其他看似細微的優化技巧都可能提高內核性能。以下是開發人員可以嘗試的一些事項:
- 預先計算在內核中不會改變的值。
- 使用內核計算可以預先計算的值是不劃算的。
- 可以通過內核參數或 #define 將預先計算的值傳遞給內核。
- 使用快速整數內建函數。對于 24 位整數乘法,使用 mul24,對于 24 位整數乘法和累加,使用 mad24。
Adreno GPU 在硬件上原生支持 mul24,而 32 位整數乘法則需要多于一條指令。- 如果整數在 24 位范圍內,使用 mul24 比直接的 32 位乘法更快。
- 減少 EFU(elementary function unit) 函數的使用。
- 例如,以下是一段代碼:
其中 a、b 和 T 是 float 變量,c 和 d 是常量,可以重寫為:r = a / select(c, d, b<T)
這樣避免了 reciprocal(倒數) EFU 函數,因為 1/c 和 1/d 可以在編譯時由編譯器推導出。r = a * select(1/c, 1/d, b<T)
- 例如,以下是一段代碼:
- 避免除法運算,尤其是整數除法。
- 在 Adreno GPU 中,整數除法非常昂貴。
- 不要使用除法,而是使用 native_recip 進行倒數運算,如第 8.3 節所述。
- 避免使用整數模運算 (mod,取余),這對 Adreno GPU 來說是昂貴的。
對于常量數組,如查找表、濾波器系數等,將它們聲明在內核范圍之外。- 在 OpenCL 內核中使用 mem_fence 函數來分隔或組織代碼段。
- 編譯器具有從全局優化角度生成最佳代碼的復雜算法。
- mem_fence 可能會
阻止編譯器在前后混合代碼之前進行重排。 - mem_fence 允許開發人員操作一些代碼以進行性能分析和調試。
- 使用16位ALU計算而不是8位。由于
Adreno GPU不支持通用的8位ALU操作,8位可能需要轉換為16位或32位ALU操作。 - 如果可能的話,使用位移操作而不是乘法。
)

)
覆蓋優化 - 附代碼)






![[文檔級關系抽取|ACL論文]文檔級關系抽取中語言理解的基礎模型](http://pic.xiahunao.cn/[文檔級關系抽取|ACL論文]文檔級關系抽取中語言理解的基礎模型)








