在這篇文章中,我們將和大家探討“深度學習中的網絡架構”這個主題,解釋相關背景知識,并就一些問題進行解答。
我選擇的問題反映的是常見用法,而不是學術用例。我將概括介紹該主題,然后探討以下四個問題:
1. 要進行圖像分類,我應該使用哪種架構?
2. 在時序應用中,我能否重用基于圖像數據訓練的架構?
3. 對于時序回歸,我該如何選擇合適的方法?
4. 對于小型數據集,我應該使用哪種網絡架構?
◆??◆??◆??◆
引言
網絡架構定義了深度學習模型的構建方式,更重要的是定義了它的功能。架構會決定:
-
模型準確度(網絡架構是影響準確度的眾多因素之一)
-
模型能預測什么
-
模型期望的輸入和輸出
-
層的組合以及數據如何流經這些層
大部分人會利用已有的成果,從現成的層組合入手開始訓練。畢竟初次嘗試某件事的話,借鑒前人的工作不失為一個好辦法。
相當一段時間以來,深度學習研究人員都在探索不同的網絡架構和層組合。得益于他們的工作,我們有了 GoogLeNet、ResNet、SqueezeNet 等各種網絡,這些架構都取得了很好的效果。
剛起步時,您可以選擇一個解決類似問題的已有架構,在它的基礎上進行構建,而無需從頭開始。
在選擇網絡架構之前,務必了解您的用例類型以及可用的常見網絡。
◆??◆??◆??◆
開始接觸深度學習時,您可能會遇到以下常見架構:
-
卷積神經網絡 (CNN):
CNN 通常用來處理圖像輸入數據,但也可以用于其他輸入數據,我將在問題 1 中詳細說明。
-
循環神經網絡 (RNN):
RNN 包含連接,可跟蹤先前信息以進行未來預測。CNN 假定每個輸入是獨立事件,而 RNN 則可以處理可能相互影響的數據序列。例如在自然語言處理中,前面的單詞會影響后續單詞出現的可能性。
-
長短期記憶 (LSTM) 網絡:
LSTM 網絡是針對序列和信號數據的常用 RNN。我將在問題 3 中進行詳細介紹。
-
生成式對抗網絡 (GAN):
盡管下面的問題不會涉及這類網絡,但是 GAN 最近越來越火了。GAN 可以基于現有數據生成新數據(想像一下并非現實真人的人像)。我覺得這挺有意思,而且有點未來感;
那么,接下來就開始回答問題!
◆??◆??◆??◆
Q1
我需要一個圖像分類模型。我應該使用哪種架構?
很好的問題。先說結論,您或許可以使用 CNN 進行圖像分類。
原因如下。
我們首先談談 CNN 和 LSTM 網絡分別是什么,以及它們的常見用途。
1) CNN
當談到卷積神經網絡時,有些人會說“ConvNet”,但我總覺得我自己這樣說會顯得有點裝。
CNN 由許多層組成,但形式上遵循一種“卷積 | ReLU | 池化”的模式,這會一再重復、反反復復。
這類網絡通常很適合處理圖像分類問題,因為它們非常擅長局部空間模式匹配,而且在圖像特征提取方面通常也優于其他方法。
別忘了,CNN 的核心是卷積。使用一系列過濾器對輸入圖像進行卷積可以突出圖像中的特征,而不會丟失相鄰像素之間的空間關系。
CNN 有很多變體,一些常見配置如下:
串聯網絡

Alexnet 示例。串聯層排列成一直線。
DAG 網絡
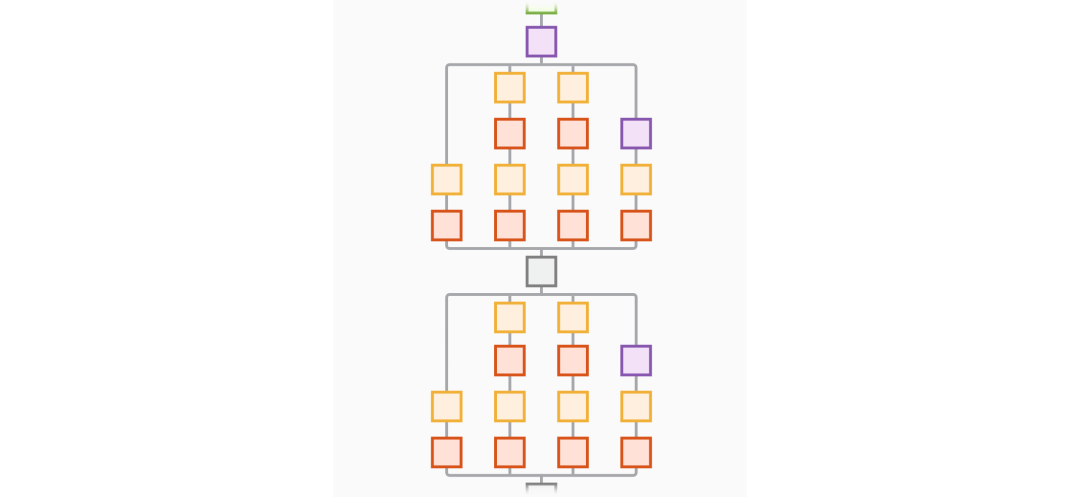
GoogLeNet 示例。多線多連接是 DAG 的典型特征。
2) LSTM
長短期記憶網絡主要用于時序和序列數據。LSTM 網絡會記住決策之前的部分數據,從而利用數據的上下文更好地作出關聯。
根據經驗,時序數據通常最適合用 LSTM 網絡處理,而圖像數據適合用 CNN。信號數據則是一個與經驗部分吻合的例外。CNN 和 LSTM 網絡都可以用來處理信號數據。我寫過一篇關于深度學習非圖像應用的文章,其中一個示例就是使用 CNN 進行語音識別。
下圖是一個用于分類的簡單 LSTM 網絡架構:
![]()
下圖是一個用于回歸的簡單 LSTM 網絡架構:
![]()
Q2
在時序應用中,我能否重用基于圖像數據訓練的架構?
可以!
您需要將輸出層從 classificationOutputLayer 更改為 regressionOutputLayer,可以跟隨這個簡單的文檔示例進行操作:將分類網絡轉換為回歸網絡
Q3
實現時序回歸的選擇太多!我該如何選擇合適的架構?
我的第一反應肯定是建議您采用 LSTM 網絡!
但是,其他方法的存在必然有其意義,事實上,某些方法在特定場景下表現會更好。
如果沒有更多背景信息,我就很難具體回答這個問題,因此讓我們逐一分析幾種可能的場景。
1) 時序回歸場景 #1:
我的輸入是低復雜度的時序數據。我想使用一系列數據點來預測未來的事件。
這種情況最好使用機器學習。
2) 時序回歸場景 #2:
我想使用來自多個傳感器的數據預測機器剩余使用壽命(即機器在不得不維修或更換之前可以使用的時間)。
這個問題來自我們在工業自動化領域的客戶,他們需要趕在問題變得危險或處理代價高昂之前先找出問題。
對于這個場景,最好選擇 LSTM 網絡而不是機器學習回歸。這種方法不要求手動識別特征,畢竟在多傳感器的情況下,手動識別特征會是相當艱巨的任務。
3) 時序回歸場景 #3:
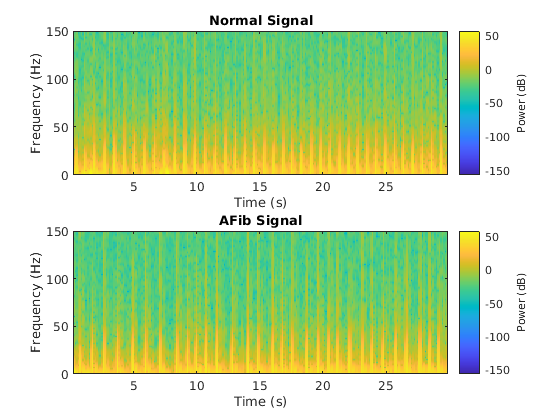
我想要對音頻數據進行去噪。
這里可以使用 CNN。這種方法的重點在于,在將信號傳送到網絡之前,先要將信號轉換成圖像。也就是說,您需要通過傅里葉變換或其他時頻操作,將信號轉換為圖像表示。
借助圖像,您可以看到原始信號中難以可視化的特征。這里可以使用為圖像任務設計的預訓練網絡,因為傅里葉變換本質上是圖像。
這個示例演示了如何使用 CNN 對語音進行去噪。對于場景 3,我還要補充一點:如果要從時序數據中提取信息并將其用作 CNN 輸入,小波也是一種比較主流的方法。

Q4
我想構建一個用來識別圖像的分類器,但是我的數據集有限。有沒有一種網絡架構可以更好地處理小型數據集?
網絡架構和預訓練網絡是密切相關的。預訓練模型是經過訓練的神經網絡。網絡的權重和偏置會根據輸入數據進行調整,因此面對新任務時,可以較快地重新訓練網絡。此過程稱為遷移學習,有時所需的圖像會比較少,適用于小型數據集。另一個可以考慮的方法是通過模擬或數據增強“創造”更多數據。
為幫助您進一步了解各種網絡架構的適用場景,我們匯總了一些提示和竅門,其中還包括有關預訓練網絡的信息。
對于這個問題,我認為無論數據集大小如何,您都可以使用任何您認為合適的網絡,但可以考慮使用預訓練網絡來減少所需的輸入數據量,或考慮采用一些方法來增強數據集。



)











:XPath 基礎知識)


— 緩存商品、購物車功能)
)