本文整理了10個常用于可解釋AI的Python庫,方便我們更好的理解AI模型的決策。
什么是XAI?
XAI(Explainable AI)的目標是為模型的行為和決策提供合理的解釋,這有助于增加信任、提供問責制和模型決策的透明度。XAI 不僅限于解釋,還以一種使推理更容易為用戶提取和解釋的方式進行 ML 實驗。
在實踐中,XAI 可以通過多種方法實現,例如使用特征重要性度量、可視化技術,或者通過構建本質上可解釋的模型,例如決策樹或線性回歸模型。方法的選擇取決于所解決問題的類型和所需的可解釋性水平。
AI 系統被用于越來越多的應用程序,包括醫療保健、金融和刑事司法,在這些應用程序中,AI 對人們生活的潛在影響很大,并且了解做出了決定特定原因至關重要。因為這些領域的錯誤決策成本很高(風險很高),所以XAI 變得越來越重要,因為即使是 AI 做出的決定也需要仔細檢查其有效性和可解釋性。
可解釋性實踐的步驟
數據準備: 這個階段包括數據的收集和處理。數據應該是高質量的、平衡的并且代表正在解決的現實問題。擁有平衡的、有代表性的、干凈的數據可以減少未來為保持 AI 的可解釋性而付出的努力。
模型訓練: 模型在準備好的數據上進行訓練,傳統的機器學習模型或深度學習神經網絡都可以。模型的選擇取決于要解決的問題和所需的可解釋性水平。模型越簡單就越容易解釋結果,但是簡單模型的性能并不會很高。
模型評估: 選擇適當的評估方法和性能指標對于保持模型的可解釋性是必要的。在此階段評估模型的可解釋性也很重要,這樣確保它能夠為其預測提供有意義的解釋。
解釋生成: 這可以使用各種技術來完成,例如特征重要性度量、可視化技術,或通過構建固有的可解釋模型。
解釋驗證: 驗證模型生成的解釋的準確性和完整性。這有助于確保解釋是可信的。
部署和監控: XAI 的工作不會在模型創建和驗證時結束。它需要在部署后進行持續的可解釋性工作。在真實環境中進行監控,定期評估系統的性能和可解釋性非常重要。
技術交流
技術要學會交流、分享,不建議閉門造車。一個人可以走的很快、一堆人可以走的更遠。
好的文章離不開粉絲的分享、推薦,資料干貨、資料分享、數據、技術交流提升,均可加交流群獲取,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友。
方式①、添加微信號:dkl88194,備注:來自CSDN + 數據分析
方式②、微信搜索公眾號:Python學習與數據挖掘,后臺回復:數據分析
資料1

資料2
我們打造了《100個超強算法模型》,特點:從0到1輕松學習,原理、代碼、案例應有盡有,所有的算法模型都是按照這樣的節奏進行表述,所以是一套完完整整的案例庫。
很多初學者是有這么一個痛點,就是案例,案例的完整性直接影響同學的興致。因此,我整理了 100個最常見的算法模型,在你的學習路上助推一把!

1、SHAP (SHapley Additive exPlanations)
SHAP是一種博弈論方法,可用于解釋任何機器學習模型的輸出。它使用博弈論中的經典Shapley值及其相關擴展將最佳信用分配與本地解釋聯系起來。

2、LIME(Local Interpretable Model-agnostic Explanations)
LIME 是一種與模型無關的方法,它通過圍繞特定預測在局部近似模型的行為來工作。LIME 試圖解釋機器學習模型在做什么。LIME 支持解釋文本分類器、表格類數據或圖像的分類器的個別預測。

3、Eli5
ELI5是一個Python包,它可以幫助調試機器學習分類器并解釋它們的預測。它提供了以下機器學習框架和包的支持:
-
scikit-learn:ELI5可以解釋scikit-learn線性分類器和回歸器的權重和預測,可以將決策樹打印為文本或SVG,顯示特征的重要性,并解釋決策樹和基于樹集成的預測。ELI5還可以理解scikit-learn中的文本處理程序,并相應地突出顯示文本數據。
-
Keras -通過Grad-CAM可視化解釋圖像分類器的預測。
-
XGBoost -顯示特征的重要性,解釋XGBClassifier, XGBRegressor和XGBoost . booster的預測。
-
LightGBM -顯示特征的重要性,解釋LGBMClassifier和LGBMRegressor的預測。
-
CatBoost:顯示CatBoostClassifier和CatBoostRegressor的特征重要性。
-
lightning -解釋lightning 分類器和回歸器的權重和預測。
-
sklearn-crfsuite。ELI5允許檢查sklearn_crfsuite.CRF模型的權重。
基本用法:
Show_weights() 顯示模型的所有權重,Show_prediction() 可用于檢查模型的個體預測

ELI5還實現了一些檢查黑盒模型的算法:
TextExplainer使用LIME算法解釋任何文本分類器的預測。排列重要性法可用于計算黑盒估計器的特征重要性。

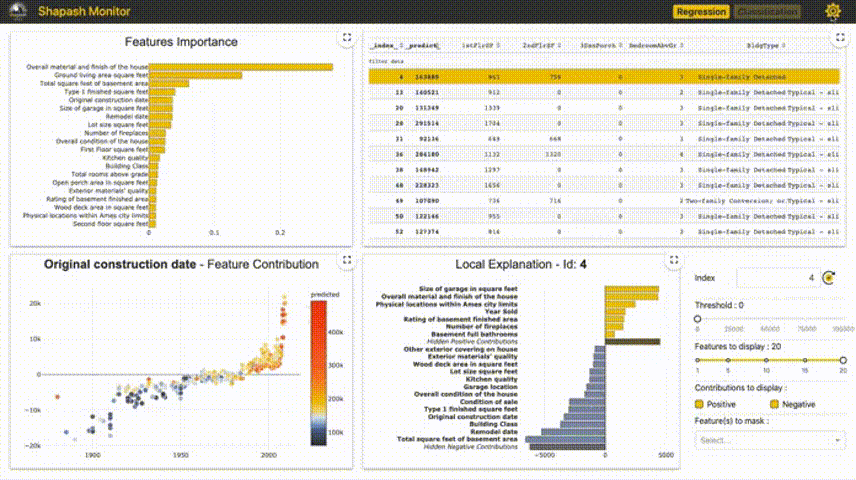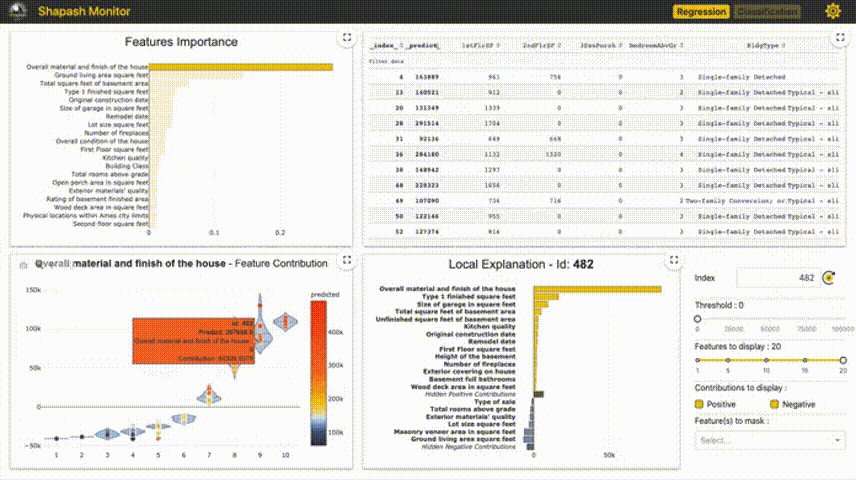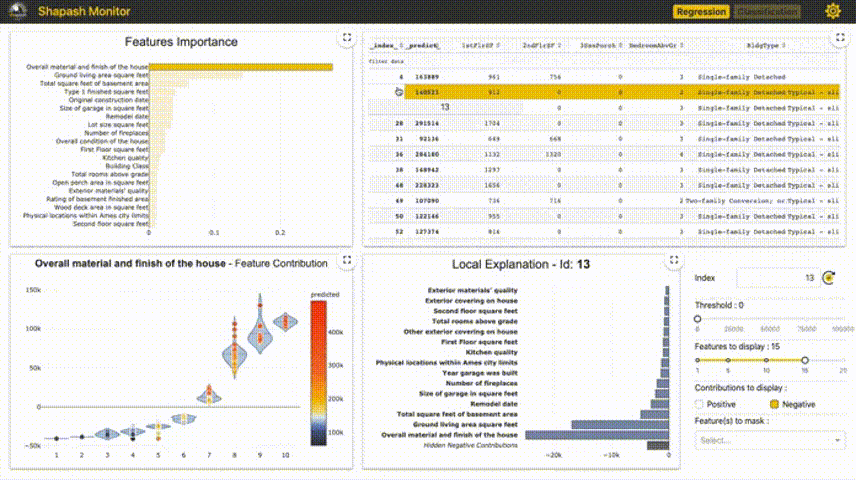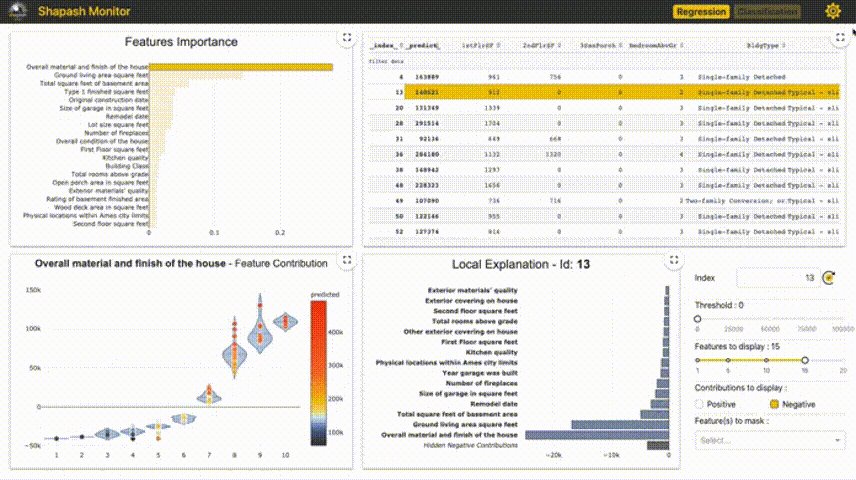
4、Shapash
Shapash提供了幾種類型的可視化,可以更容易地理解模型。通過摘要來理解模型提出的決策。該項目由MAIF數據科學家開發。Shapash主要通過一組出色的可視化來解釋模型。
Shapash通過web應用程序機制工作,與Jupyter/ipython可以完美的結合。
from shapash import SmartExplainerxpl = SmartExplainer(model=regressor,preprocessing=encoder, # Optional: compile step can use inverse_transform methodfeatures_dict=house_dict # Optional parameter, dict specifies label for features name)xpl.compile(x=Xtest,y_pred=y_pred,y_target=ytest, # Optional: allows to display True Values vs Predicted Values)xpl.plot.contribution_plot("OverallQual")
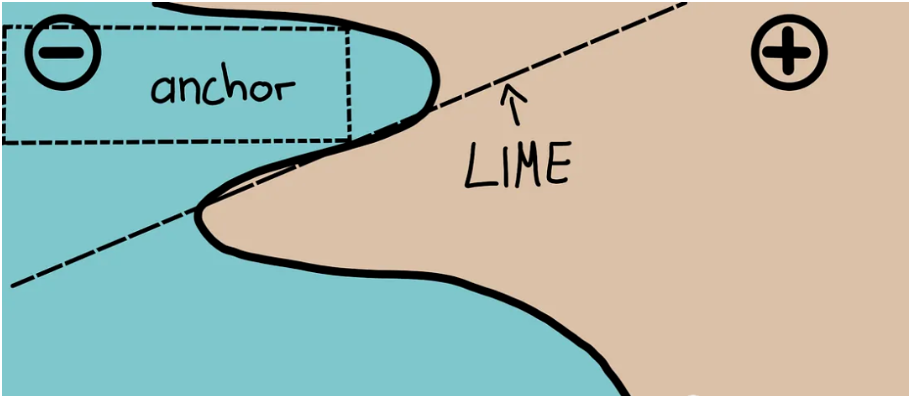
5、Anchors
Anchors使用稱為錨點的高精度規則解釋復雜模型的行為,代表局部的“充分”預測條件。該算法可以有效地計算任何具有高概率保證的黑盒模型的解釋。
Anchors可以被看作為LIME v2,其中LIME的一些限制(例如不能為數據的不可見實例擬合模型)已經得到糾正。Anchors使用局部區域,而不是每個單獨的觀察點。它在計算上比SHAP輕量,因此可以用于高維或大數據集。但是有些限制是標簽只能是整數。
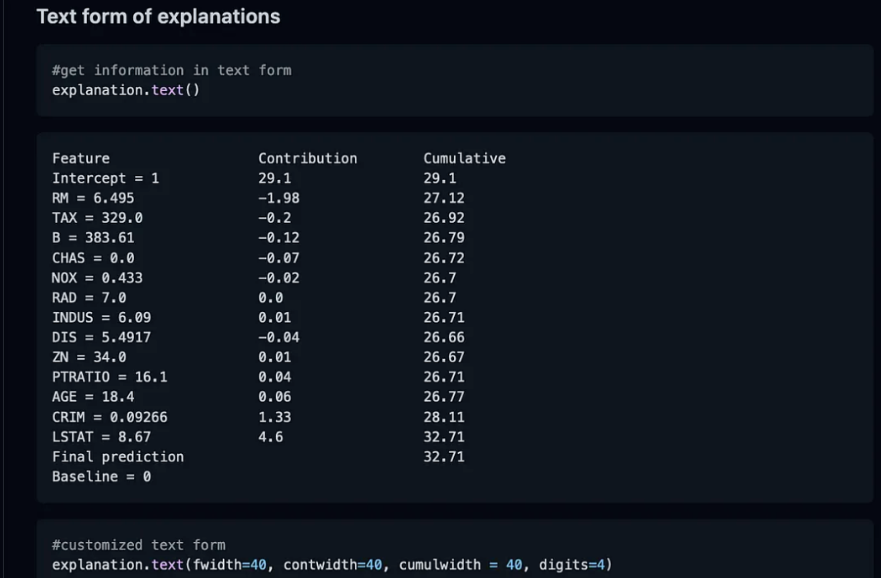
6、BreakDown
BreakDown是一種可以用來解釋線性模型預測的工具。它的工作原理是將模型的輸出分解為每個輸入特征的貢獻。這個包中有兩個主要方法。Explainer()和Explanation()
model = tree.DecisionTreeRegressor()model = model.fit(train_data,y=train_labels)#necessary importsfrom pyBreakDown.explainer import Explainerfrom pyBreakDown.explanation import Explanation#make explainer objectexp = Explainer(clf=model, data=train_data, colnames=feature_names)#What do you want to be explained from the data (select an observation)explanation = exp.explain(observation=data[302,:],direction="up")
7、Interpret-Text
Interpret-Text 結合了社區為 NLP 模型開發的可解釋性技術和用于查看結果的可視化面板。可以在多個最先進的解釋器上運行實驗,并對它們進行比較分析。這個工具包可以在每個標簽上全局或在每個文檔本地解釋機器學習模型。
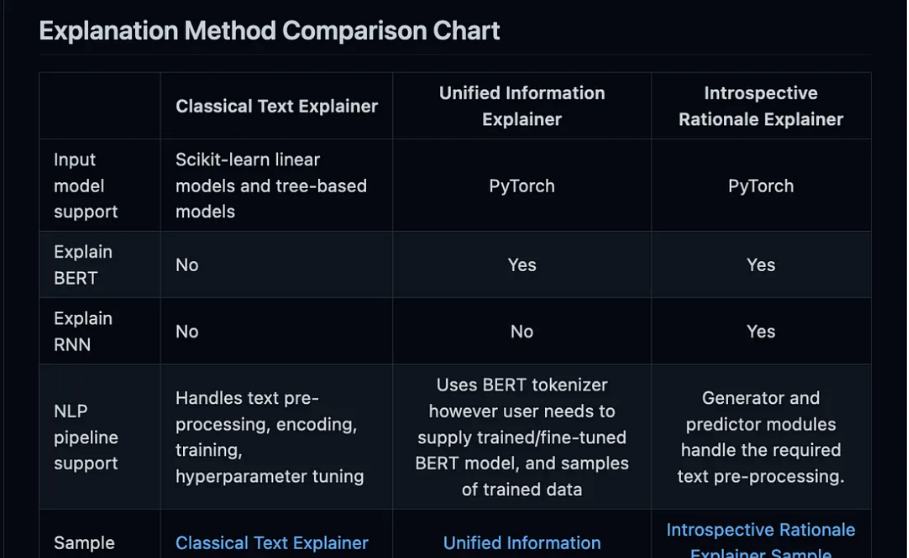
以下是此包中可用的解釋器列表:
-
Classical Text Explainer——(默認:邏輯回歸的詞袋)
-
Unified Information Explainer
-
Introspective Rationale Explainer
它的好處是支持CUDA,RNN和BERT等模型。并且可以為文檔中特性的重要性生成一個面板。
from interpret_text.widget import ExplanationDashboardfrom interpret_text.explanation.explanation import _create_local_explanation# create local explanationlocal_explanantion = _create_local_explanation(classification=True,text_explanation=True,local_importance_values=feature_importance_values,method=name_of_model,model_task="classification",features=parsed_sentence_list,classes=list_of_classes,)# Dash itExplanationDashboard(local_explanantion)

8、aix360 (AI Explainability 360)
AI Explainbability 360工具包是一個開源庫,這個包是由IBM開發的,在他們的平臺上廣泛使用。AI Explainability 360包含一套全面的算法,涵蓋了不同維度的解釋以及代理解釋性指標。

工具包結合了以下論文中的算法和指標:
-
Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref
-
Boolean Decision Rules via Column Generation, 2018. ref
-
Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref
-
Improving Simple Models with Confidence Profiles, , 2018. ref
-
Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref
-
TED: Teaching AI to Explain Its Decisions, 2019. ref
-
Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref
-
Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref
-
Generalized Linear Rule Models, 2019. ref
9、OmniXAI
OmniXAI (Omni explable AI的縮寫),解決了在實踐中解釋機器學習模型產生的判斷的幾個問題。
它是一個用于可解釋AI (XAI)的Python機器學習庫,提供全方位的可解釋AI和可解釋機器學習功能,并能夠解決實踐中解釋機器學習模型所做決策的許多痛點。OmniXAI旨在成為一站式綜合庫,為數據科學家、ML研究人員和從業者提供可解釋的AI。
from omnixai.visualization.dashboard import Dashboard# Launch a dashboard for visualizationdashboard = Dashboard(instances=test_instances, # The instances to explainlocal_explanations=local_explanations, # Set the local explanationsglobal_explanations=global_explanations, # Set the global explanationsprediction_explanations=prediction_explanations, # Set the prediction metricsclass_names=class_names, # Set class namesexplainer=explainer # The created TabularExplainer for what if analysis)dashboard.show()

10、XAI (eXplainable AI)
XAI 庫由 The Institute for Ethical AI & ML 維護,它是根據 Responsible Machine Learning 的 8 條原則開發的。它仍處于 alpha 階段因此請不要將其用于生產工作流程。









:XPath 基礎知識)


— 緩存商品、購物車功能)
)

)



