概念
過擬合:根本原因是特征維度過多,模型假設過于復雜,參數過多,訓練數據過少,噪聲過多,導致擬合的函數完美的預測訓練集,但對新數據的測試集預測結果差。 過度的擬合了訓練數據,而沒有考慮到泛化能力。
代碼
model.py
import torch.nn as nn
import torchclass AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6])self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)if init_weights:self._initialize_weights()def forward(self, x):x = self.features(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
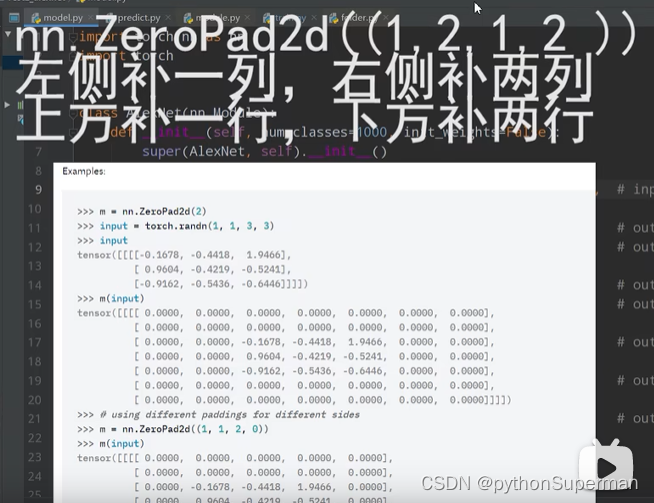
padding:
只能傳入兩種形式的變量,int整形,tuple類型。
比如int整形傳入1,就會在圖像的左上右下分別添上一層0。
比如tuple(1,2):1代表上下方各補一行零,2代表左右兩側各補兩列零。
或者:
?nn.ReLU(inplace=True):inplace=True增加計算量,減少內存使用
Dropout:失活。Dropout 是為了讓全連接層部分失活,所以需要dropout的全連接層前配置Dropout()
激活:每一層都要激活。激活屬于非線性操作,如果不激活,每層就是純線性變換,連續的多層和只有一層是等效的,沒有任何區別。
train.py
transform
data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224), # 隨機裁剪成224×224的大小transforms.RandomHorizontalFlip(), # 在水平方向隨機水平翻轉transforms.ToTensor(), # 標準化處理transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)), ?# cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}?json類別文件
用flower_list來保存類別索引,在這個數據集下,圖片所在的文件夾名稱即為他們的索引。
然后通過dict方法聯合類別和序號值
再寫入json文件。
? ? # {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idx?cla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)損失函數
loss_function = nn.CrossEntropyLoss()nn.CrossEntropyLoss():針對多類別的損失函數
優化器
optimizer = optim.Adam(net.parameters(), lr=0.0002)優化器是Adam優化器,優化對象是網絡中所有的可訓練的參數,學習率設置的為0.0002
?net.train()
使用Dropout的方式再網絡正向傳播過程中隨機失活一部分神經元。這是再訓練過程中需要的,所以會調用net.train(),再測試過程中不需要隨機失活,所以會調用net.eval()關閉dropout()方法.








)

 —— 概念、SpringBoot + MyBatis(controller+service+mapper)開發流程與過程梳理)




)
)

)
