一、本文介紹
?本文給大家帶來的改進機制是RCS-YOLO提出的RCS-OSA模塊,其全稱是"Reduced Channel Spatial Object Attention",意即"減少通道的空間對象注意力"。這個模塊的主要功能是通過減少特征圖的通道數量,同時關注空間維度上的重要特征,來提高模型的處理效率和檢測精度。親測在小目標檢測和大尺度目標檢測的數據集上都有大幅度的漲點效果(mAP直接漲了大概有0.6左右)。同時本文對RCS-OSA模塊的框架原理進行了詳細的分析,不光讓大家會添加到自己的模型在寫論文的時候也能夠有一定的參照,最后本文會手把手教你添加RCS-OSA模塊到網絡結構中。
推薦指數:?????
漲點效果:?????
專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備????
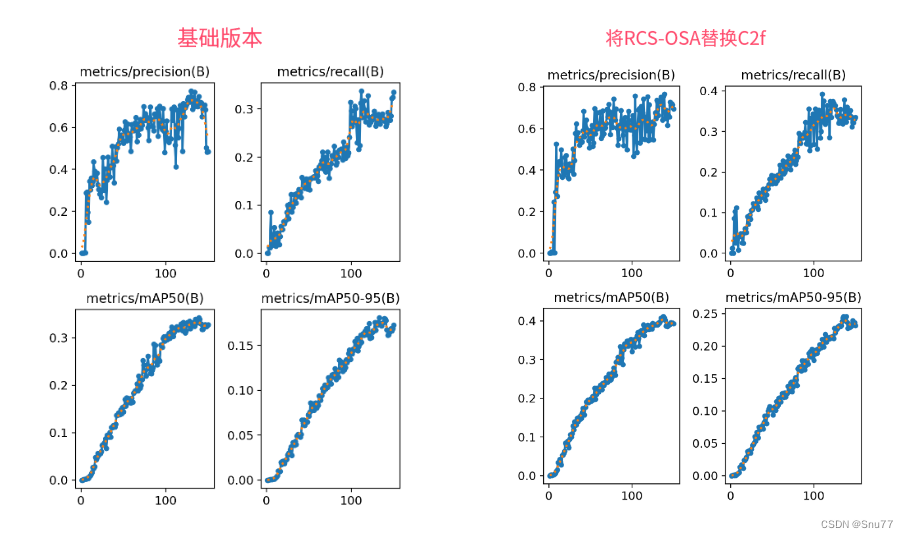
訓練結果對比圖->??
這次試驗我用的數據集大概有七八百張照片訓練了150個epochs,雖然沒有完全擬合但是效果有很高的漲點幅度,所以大家可以進行嘗試畢竟不同的數據集上效果也可能差很多,同時我在后面給了多種yaml文件大家可以分別進行實驗來檢驗效果。
可以看到這個漲點幅度mAP直接漲了大概有0.6左右,這個漲幅還是很好的,所以非常建議大家進行嘗試這個機制的改進。
目錄
一、本文介紹
二、RCS-OSA模塊原理
2.1 RCS-OSA的基本原理
2.2?RCS
2.3?RCS模塊
2.4?OSA
2.5?特征級聯
三、RCS-OSA核心代碼
四、手把手教你添加RCS-OSA模塊
4.1?RCS-OSA添加步驟
4.1.1 步驟一
4.1.2 步驟二
4.1.3 步驟三
4.2 RCS-OSA的yaml文件和訓練截圖
4.2.1 RCS-OSA的yaml版本一(推薦)
4.2.2 RCS-OSA的yaml版本二
4.2.2 RCS-OSA的訓練過程截圖?
五、本文總結
二、RCS-OSA模塊原理

論文地址:官方論文地址
代碼地址:官方代碼地址

2.1 RCS-OSA的基本原理
RCSOSA(RCS-One-Shot Aggregation)是RCS-YOLO中提出的一種結構,我們可以將主要原理概括如下:
1. RCS(Reparameterized Convolution based on channel Shuffle): 結合了通道混洗,通過重參數化卷積來增強網絡的特征提取能力。
2. RCS模塊: 在訓練階段,利用多分支結構學習豐富的特征表示;在推理階段,通過結構化重參數化簡化為單一分支,減少內存消耗。
3. OSA(One-Shot Aggregation): 一次性聚合多個特征級聯,減少網絡計算負擔,提高計算效率。
4. 特征級聯: RCS-OSA模塊通過堆疊RCS,確保特征的復用并加強不同層之間的信息流動。
2.2?RCS
RCS(基于通道Shuffle的重參數化卷積)是RCS-YOLO的核心組成部分,旨在訓練階段通過多分支結構學習豐富的特征信息,并在推理階段通過簡化為單分支結構來減少內存消耗,實現快速推理。此外,RCS利用通道分割和通道Shuffle操作來降低計算復雜性,同時保持通道間的信息交換,這樣在推理階段相比普通的3×3卷積可以減少一半的計算復雜度。通過結構重參數化,RCS能夠在訓練階段從輸入特征中學習深層表示,并在推理階段實現快速推理,同時減少內存消耗。
2.3?RCS模塊
RCS(基于通道Shuffle的重參數化卷積)模塊中,結構在訓練階段使用多個分支,包括1x1和3x3的卷積,以及一個直接的連接(Identity),用于學習豐富的特征表示。在推理階段,結構被重參數化成一個單一的3x3卷積,以減少計算復雜性和內存消耗,同時保持訓練階段學到的特征表達能力。這與RCS的設計理念緊密相連,即在不犧牲性能的情況下提高計算效率。
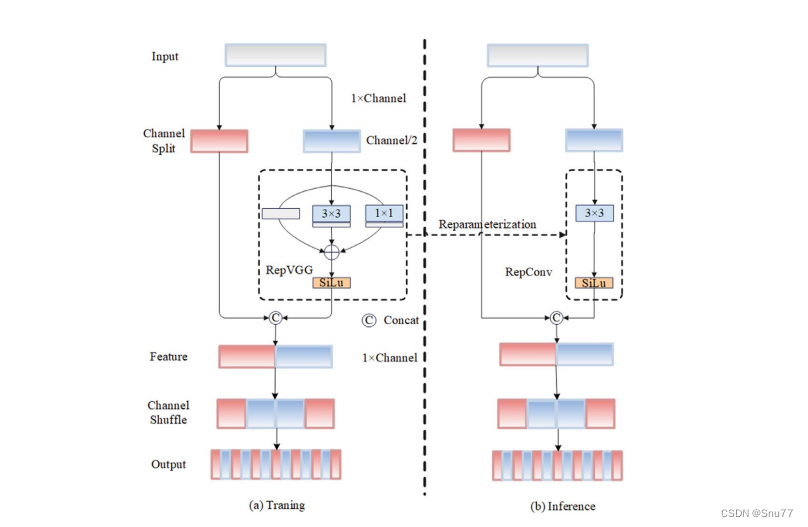
上圖為大家展示了RCS的結構,分為訓練階段(a部分)和推理階段(b部分)。在訓練階段,輸入通過通道分割,一部分輸入經過RepVGG塊,另一部分保持不變。然后通過1x1卷積和3x3卷積處理RepVGG塊的輸出,與另一部分輸入進行通道Shuffle和連接。在推理階段,原來的多分支結構被簡化為一個單一的3x3 RepConv塊。這種設計允許在訓練時學習復雜特征,在推理時減少計算復雜度。黑色邊框的矩形代表特定的模塊操作,漸變色的矩形代表張量的特定特征,矩形的寬度代表張量的通道數。?
2.4?OSA
OSA(One-Shot Aggregation)是一個關鍵的模塊,旨在提高網絡在處理密集連接時的效率。OSA模塊通過表示具有多個感受野的多樣化特征,并在最后的特征映射中僅聚合一次所有特征,從而克服了DenseNet中密集連接的低效率問題。
OSA模塊的使用有兩個主要目的:
1. 提高特征表示的多樣性:OSA通過聚合具有不同感受野的特征來增加網絡對于不同尺度的敏感性,這有助于提升模型對不同大小目標的檢測能力。
2. 提高效率:通過在網絡的最后一部分只進行一次特征聚合,OSA減少了重復的特征計算和存儲需求,從而提高了網絡的計算和能源效率。
在RCS-YOLO中,OSA模塊被進一步與RCS(基于通道Shuffle的重參數化卷積)相結合,形成RCS-OSA模塊。這種結合不僅保持了低成本的內存消耗,而且還實現了語義信息的有效提取,對于構建輕量級和大規模的對象檢測器尤為重要。
下面我將為大家展示RCS-OSA(One-Shot Aggregation of RCS)的結構。
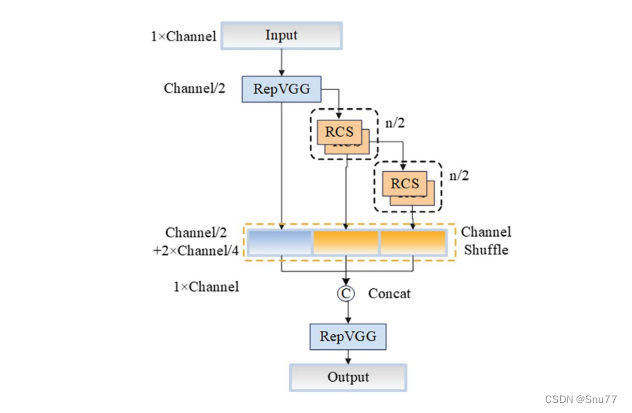
在RCS-OSA模塊中,輸入被分為兩部分,一部分直接通過,另一部分通過堆疊的RCS模塊進行處理。處理后的特征和直接通過的特征在通道混洗(Channel Shuffle)后合并。這種結構設計用于增強模型的特征提取和利用效率,是RCS-YOLO架構中的一個關鍵組成部分旨在通過一次性聚合來提高模型處理特征的能力,同時保持計算效率。
2.5?特征級聯
特征級聯(feature cascade)是一種技術,通過在網絡的一次性聚合(one-shot aggregate)路徑上維持有限數量的特征級聯來實現的。在RCS-YOLO中,特別是在RCS-OSA(RCS-Based One-Shot Aggregation)模塊中,只保留了三個特征級聯。
特征級聯的目的是為了減輕網絡計算負擔并降低內存占用。這種方法可以有效地聚合不同層次的特征,提高模型的語義信息提取能力,同時避免了過度復雜化網絡結構所帶來的低效率和高資源消耗。
下面為大家提供的圖像展示的是RCS-YOLO的整體架構,其中包括RCS-OSA模塊。RCS-OSA在模型中用于堆疊RCS模塊,以確保特征的復用并加強不同層之間的信息流動。圖中顯示的多層RCS-OSA模塊的排列和組合反映了它們如何一起工作以優化特征傳遞和提高檢測性能。

總結:RCS-YOLO主要由RCS-OSA(藍色模塊)和RepVGG(橙色模塊)構成。這里的n代表堆疊RCS模塊的數量。n_cls代表檢測到的對象中的類別數量。圖中的IDetect是從YOLOv7中借鑒過來的,表示使用二維卷積神經網絡的檢測層。這個架構通過堆疊的RCS模塊和RepVGG模塊,以及兩種類型的檢測層,實現了對象檢測的任務。?
三、RCS-OSA核心代碼
在這里說一下這個原文是RCS-YOLO我們只是用其中的RCS-OSA模塊來替換我們YOLOv8中的C2f模塊,但是在RCS-YOLO中還有一個RepVGG模塊(大家在下面的代碼中可以看到),這個模塊可以替換Conv,但是如果都替換的話我覺得那就是RCS-YOLO了沒啥區別了,所以我下面的改進和這篇文章只用了RCS-OSA模塊來替換C2f,如果你對RCS-YOLO感興趣的話,我后面也會提高RCS-YOLO的yaml文件供大家參考。
import torch.nn as nn
import torch
import torch.nn.functional as F
import numpy as np
import math# build RepVGG block
# -----------------------------
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):result = nn.Sequential()result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,bias=False))result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))return resultclass SEBlock(nn.Module):def __init__(self, input_channels):super(SEBlock, self).__init__()internal_neurons = input_channels // 8self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1,bias=True)self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1,bias=True)self.input_channels = input_channelsdef forward(self, inputs):x = F.avg_pool2d(inputs, kernel_size=inputs.size(3))x = self.down(x)x = F.relu(x)x = self.up(x)x = torch.sigmoid(x)x = x.view(-1, self.input_channels, 1, 1)return inputs * xclass RepVGG(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3,stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(RepVGG, self).__init__()self.deploy = deployself.groups = groupsself.in_channels = in_channelspadding_11 = padding - kernel_size // 2self.nonlinearity = nn.SiLU()# self.nonlinearity = nn.ReLU()if use_se:self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)else:self.se = nn.Identity()if deploy:self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True,padding_mode=padding_mode)else:self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else Noneself.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, groups=groups)self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,padding=padding_11, groups=groups)# print('RepVGG Block, identity = ', self.rbr_identity)def get_equivalent_kernel_bias(self):kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])def _fuse_bn_tensor(self, branch):if branch is None:return 0, 0if isinstance(branch, nn.Sequential):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselse:assert isinstance(branch, nn.BatchNorm2d)if not hasattr(self, 'id_tensor'):input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef forward(self, inputs):if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))def fusevggforward(self, x):return self.nonlinearity(self.rbr_dense(x))# RepVGG block end
# -----------------------------class SR(nn.Module):# Shuffle RepVGGdef __init__(self, c1, c2):super().__init__()c1_ = int(c1 // 2)c2_ = int(c2 // 2)self.repconv = RepVGG(c1_, c2_)def forward(self, x):x1, x2 = x.chunk(2, dim=1)out = torch.cat((x1, self.repconv(x2)), dim=1)out = self.channel_shuffle(out, 2)return outdef channel_shuffle(self, x, groups):batchsize, num_channels, height, width = x.data.size()channels_per_group = num_channels // groupsx = x.view(batchsize, groups, channels_per_group, height, width)x = torch.transpose(x, 1, 2).contiguous()x = x.view(batchsize, -1, height, width)return xdef make_divisible(x, divisor):# Returns nearest x divisible by divisorif isinstance(divisor, torch.Tensor):divisor = int(divisor.max()) # to intreturn math.ceil(x / divisor) * divisorclass RCSOSA(nn.Module):# VoVNet with Res Shuffle RepVGGdef __init__(self, c1, c2, n=1, se=False, e=0.5, stackrep=True):super().__init__()n_ = n // 2c_ = make_divisible(int(c1 * e), 8)# self.conv1 = Conv(c1, c_)self.conv1 = RepVGG(c1, c_)self.conv3 = RepVGG(int(c_ * 3), c2)self.sr1 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])self.sr2 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])self.se = Noneif se:self.se = SEBlock(c2)def forward(self, x):x1 = self.conv1(x)x2 = self.sr1(x1)x3 = self.sr2(x2)x = torch.cat((x1, x2, x3), 1)return self.conv3(x) if self.se is None else self.se(self.conv3(x))if __name__ == '__main__':m = RCSOSA(256, 256)im = torch.randn(2, 256, 13, 13)y = m(im)print(y.shape)四、手把手教你添加RCS-OSA模塊
4.1?RCS-OSA添加步驟
4.1.1 步驟一
首先我們找到如下的目錄'ultralytics/nn/modules',然后在這個目錄下創建一個py文件,名字為RCSOSA即可,然后將RCS-OSA的核心代碼復制進去。
4.1.2 步驟二
之后我們找到'ultralytics/nn/tasks.py'文件,在其中注冊我們的RCS-OSA模塊。
首先我們需要在文件的開頭導入我們的RCS-OSA模塊,如下圖所示->

4.1.3 步驟三
我們找到parse_model這個方法,可以用搜索也可以自己手動找,大概在六百多行吧。?我們找到如下的地方,然后將RCS-OSA添加進去即可

到此我們就注冊成功了,可以修改yaml文件中輸入RCSOSA使用這個模塊了。
4.2 RCS-OSA的yaml文件和訓練截圖
下面推薦幾個版本的yaml文件給大家,大家可以復制進行訓練,但是組合用很多具體那種最有效果都不一定,針對不同的數據集效果也不一樣,我不可每一種都做實驗,所以我下面推薦了幾種我自己認為可能有效果的配合方式,你也可以自己進行組合。
4.2.1 RCS-OSA的yaml版本一(推薦)
下面的配置文件為我修改的RCS-OSA的位置(我的對比實驗是用這個版本跑出來的)。
?此版本的GFLOPs大概漲到了24.4GFOPs,參數量為407120 parameters。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, RCSOSA, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, RCSOSA, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, RCSOSA, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, RCSOSA, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, RCSOSA, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, RCSOSA, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, RCSOSA, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, RCSOSA, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2.2 RCS-OSA的yaml版本二
添加的版本二具體那種適合你需要大家自己多做實驗來嘗試。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, RCSOSA, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, RCSOSA, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, RCSOSA, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, RCSOSA, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2.2 RCS-OSA的訓練過程截圖?
下面是添加了RCS-OSA的訓練截圖。
大家可以看下面的運行結果和添加的位置所以不存在我發的代碼不全或者運行不了的問題大家有問題也可以在評論區評論我看到都會為大家解答(我知道的)。

??????
五、本文總結
到此本文的正式分享內容就結束了,在這里給大家推薦我的YOLOv8改進有效漲點專欄,本專欄目前為新開的平均質量分98分,后期我會根據各種最新的前沿頂會進行論文復現,也會對一些老的改進機制進行補充,目前本專欄免費閱讀(暫時,大家盡早關注不迷路~),如果大家覺得本文幫助到你了,訂閱本專欄,關注后續更多的更新~
專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備
 ?
?





)




)

覆蓋優化 - 附代碼)






)