
一、說明
????????降維在數據分析和機器學習中發揮著關鍵作用,為高維數據集帶來的挑戰提供了戰略解決方案。隨著數據集規模和復雜性的增長,特征或維度的數量通常變得難以處理,導致計算需求增加、潛在的過度擬合和模型可解釋性降低。降維技術通過捕獲數據中的基本信息同時丟棄冗余或信息量較少的特征來提供補救措施。這一過程不僅簡化了計算任務,還有助于可視化數據趨勢,減輕維數災難的風險,并提高機器學習模型的泛化性能。降維在從圖像和語音處理到金融和生物信息學等各個領域都有應用,其中從大量數據集中提取有意義的模式對于做出明智的決策和構建有效的預測模型至關重要。
????????在本博客中,我們將深入研究三種強大的降維技術——主成分分析(PCA)、線性判別分析(LDA)和奇異值分解(SVD)。我們的探索不僅會闡明這些方法的底層算法,還會提供它們各自的優缺點。我們將結合理論討論和 Python 的實際實現,提供將 PCA、LDA 和 SVD 應用到現實世界數據集的實踐指導。無論您是尋求降維介紹的新手,還是希望增強理解的經驗豐富的從業者,這個博客都是為了滿足各個級別的專業知識而精心設計的。
二、主成分分析(PCA)
主成分分析(PCA)是一種廣泛應用于數據分析和機器學習的降維技術。其主要目標是將高維數據轉換為低維表示,捕獲最重要的信息。
2.1 以下是 PCA 的動機:
由于我們的目標是識別數據集中的模式,因此希望數據分布在每個維度上,并且我們尋求這些維度之間的獨立性。讓我們回顧一下一些基本概念。方差作為變異性的度量,本質上是量化數據集分散的程度。用數學術語來說,它表示與平均分數的平均平方偏差。用于計算方差的公式表示為 var(x),表達如下。

協方差量化兩組有序數據中對應元素表現出相似方向運動的程度。該公式表示為 cov(x, y),捕獲變量 x 和 y 之間的協方差。在這種情況下,xi 表示第 i 維中 x 的值,而 x 條和 y 條表示它們各自的平均值。現在,讓我們以矩陣形式探討這個概念。如果我們有一個維度為 m*n 的矩陣 X,其中包含 n 個數據點,每個數據點的維度為 m,則協方差矩陣可以計算如下:

請注意,協方差矩陣包含 -
1. 作為主對角元素的維度方差
2. 作為非對角元素的維度協方差
如前所述,我們的目標是確保數據廣泛分散,表明其維度上的高方差。此外,我們的目標是消除相關維度,這意味著維度之間的協方差應該為零,表示它們的線性獨立性。因此,目的是進行數據變換,使其協方差矩陣表現出以下特征:
1. 有效值作為主對角線元素。
2. 零值作為非對角元素。
因此,必須對原始數據點進行變換以獲得類似于對角矩陣的協方差矩陣。將矩陣轉換為對角矩陣的過程稱為對角化,它構成了主成分分析 (PCA) 的主要動機。
PCA 的工作原理如下:
1. 標準化
當以不同單位測量特征時,對數據進行標準化。這需要減去每個特征的平均值并除以標準差。未能對具有不同尺度特征的數據進行標準化可能會導致誤導性組件。
2. 計算協方差矩陣
如前所述計算協方差矩陣
3.計算特征向量和特征值
確定協方差矩陣的特征向量和特征值。
![]()
特征向量表示方向(主成分),特征值表示這些方向上的方差大小。要了解什么是特征向量和特征值,您可以觀看此視頻:
4. 對特征值進行排序
按降序對特征值進行排序。與最高特征值對應的特征向量是捕獲數據中最大方差的主成分。要了解原因,請參閱此博客。
5. 選擇主成分
根據所需解釋的方差選擇前 k 個特征向量(主成分)。通常,您的目標是保留總方差的很大一部分,例如 85%。可以在此處找到如何計算解釋方差。
6. 轉換數據
現在,我們可以使用特征向量轉換原始數據:
因此,如果我們有 m 維原始 n 個數據點,則
X : m*n
P : k*m
Y = PX : (k*m)(m*n) = (k*n)
因此,我們新的變換矩陣有 n具有 k 維的數據點。
2.2 優點:
1.降維:
PCA有效地減少了特征數量,這對于遭受維數災難的模型是有利的。
2. 特征獨立性:
主成分是正交的(不相關的),這意味著它們捕獲獨立的信息,簡化了對簡化特征的解釋。
3. 降噪:
PCA 可以通過關注解釋數據中最顯著方差的成分來幫助降低噪聲。
4. 可視化:
降維數據可以可視化,有助于理解底層結構和模式。
2.3 缺點:
1. 可解釋性的損失:
原始特征的可解釋性可能會在變換后的空間中丟失,因為主成分是原始特征的線性組合。
2. 線性假設:
PCA 假設變量之間的關系是線性的,但并非在所有情況下都是如此。
3.對尺度敏感:
PCA對特征的尺度敏感,因此通常需要標準化。
4. 異常值影響結果:
異常值可以顯著影響 PCA 的結果,因為它側重于捕獲最大方差,這可能會受到極值的影響。
2.4 何時使用:
1. 高維數據:
PCA 在處理具有大量特征的數據集以減輕維數災難時特別有用。
2.共線特征:
當特征高度相關時,PCA可以有效地捕獲共享信息并用更少的組件來表示它。
3. 可視化:
當高維數據可視化具有挑戰性時,PCA 很有用。它將數據投影到可以輕松可視化的低維空間中。
5.線性關系:
當變量之間的關系大部分是線性時,PCA是一種合適的技術。
2.5 Python實現
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris# Load iris dataset as an example
iris = load_iris()
X = iris.data
y = iris.target# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Standardize the data (important for PCA)
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)# Apply PCA
pca = PCA()
X_train_pca = pca.fit_transform(X_train_std)# Calculate the cumulative explained variance
cumulative_variance_ratio = np.cumsum(pca.explained_variance_ratio_)# Determine the number of components to keep for 85% variance explained
n_components = np.argmax(cumulative_variance_ratio >= 0.85) + 1# Apply PCA with the selected number of components
pca = PCA(n_components=n_components)
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.transform(X_test_std)# Display the results
print("Original Training Data Shape:", X_train.shape)
print("Reduced Training Data Shape (PCA):", X_train_pca.shape)
print("Number of Components Selected:", n_components)在此示例中,PCA()最初應用時未指定組件數量,這意味著它將保留所有組件。然后,使用 計算累積解釋方差np.cumsum(pca.explained_variance_ratio_)。最后,確定解釋至少 85% 方差所需的成分數量,并使用選定的成分數量再次應用 PCA。請注意,PCA 僅適用于訓練數據,然后用于轉換測試數據。
三、線性判別分析 (LDA)
????????線性判別分析 (LDA) 是一種降維和分類技術,旨在優化數據集中不同類別之間的區別。LDA 在數據點類別預先確定的監督學習場景中尤其普遍。PCA 被認為是一種“無監督”算法,它忽略類標簽,專注于尋找主成分以最大化數據集方差,而 LDA 則采用“監督”方法。LDA 計算“線性判別式”,確定作為軸的方向,以最大化多個類之間的分離。為了深入研究 LDA 的工作原理,讓我們使用UCI 機器學習存儲庫中著名的“Iris”數據集的示例來了解如何計算 LDA 。它包含來自三個不同品種的 150 朵鳶尾花的測量值。
Iris 數據集中共有三個類:
- 山鳶尾 (n=50)
- 雜色鳶尾 (n=50)
- 弗吉尼亞鳶尾 (n=50)
Iris 數據集中有四個特征:
- 萼片長度(厘米)
- 萼片寬度(厘米)
- 花瓣長度(厘米)
- 花瓣寬度(厘米)
3.1 LDA的步驟:
- 我們將從計算 3 個不同花類的平均向量 mi (i=1,2,3) 開始:
Mean Vector class 1: [ 5.006 3.418 1.464 0.244]Mean Vector class 2: [ 5.936 2.77 4.26 1.326]Mean Vector class 3: [ 6.588 2.974 5.552 2.026]每個向量包含數據集中特定類的 4 個特征的平均值。
2. 計算類內散布矩陣 (Sw),它表示每個類內數據的分布:

在我們的示例中,它將如下所示:
within-class Scatter Matrix:[[ 38.9562 13.683 24.614 5.6556][ 13.683 17.035 8.12 4.9132][ 24.614 8.12 27.22 6.2536][ 5.6556 4.9132 6.2536 6.1756]]3. 使用以下公式計算類間散布矩陣 (Sb),它表示不同類之間的分布:

在我們的示例中,它將如下所示:
between-class Scatter Matrix:[[ 63.2121 -19.534 165.1647 71.3631][ -19.534 10.9776 -56.0552 -22.4924][ 165.1647 -56.0552 436.6437 186.9081][ 71.3631 -22.4924 186.9081 80.6041]]4. 計算 Sw-1Sb 的特征值和特征向量(類似于 PCA)。在我們的例子中,我們有 4 個特征值和特征向量:
Eigenvector 1:
[[-0.2049][-0.3871][ 0.5465][ 0.7138]]
Eigenvalue 1: 3.23e+01Eigenvector 2:
[[-0.009 ][-0.589 ][ 0.2543][-0.767 ]]
Eigenvalue 2: 2.78e-01Eigenvector 3:
[[ 0.179 ][-0.3178][-0.3658][ 0.6011]]
Eigenvalue 3: -4.02e-17Eigenvector 4:
[[ 0.179 ][-0.3178][-0.3658][ 0.6011]]
Eigenvalue 4: -4.02e-175. 按特征值遞減對特征向量進行排序,并選取前 k 個。通過減少特征值對特征對進行排序后,現在是時候根據 2 個信息最豐富的特征對構建我們的 d×k 維特征向量矩陣(我們稱之為 W)。我們在示例中得到以下矩陣:
Matrix W:[[-0.2049 -0.009 ][-0.3871 -0.589 ][ 0.5465 0.2543][ 0.7138 -0.767 ]]6. 使用矩陣 W(4 X 2 矩陣)通過以下方程將樣本轉換到新的子空間:Y = X*W,其中 X 是矩陣格式的原始數據幀(在我們的例子中為 150 X 4 矩陣)并且Y 是轉換后的數據集(150 X 2 矩陣)。請參閱此博客了解更多詳細信息。
3.2 優點:
1.最大化類分離:
LDA旨在最大化不同類之間的分離,使其對分類任務有效。
2.降維:
與PCA一樣,LDA可以用于降維,但具有考慮類信息的優點。
3.3 缺點:
1.對異常值的敏感性:
LDA對異常值敏感,異常值的存在會影響方法的性能。
2. 正態性假設:
LDA 假設每個類內的特征呈正態分布,如果違反此假設,LDA 可能表現不佳。
3. 需要足夠的樣本:當
每類樣本數量較少時,LDA 可能表現不佳。擁有更多樣本可以改善類參數的估計。
3.4 何時使用:
1. 分類任務
當目標是將數據分類到預定義的類別時,LDA 很有用。
2. 保留類別信息:
當目標是降低維度同時保留與區分類別相關的信息時。
3. 正態性假設成立:
當每個類內正態分布的假設有效時,LDA 表現良好。
4.有監督降維:
當任務需要在類標簽的指導下進行降維時,LDA是一個合適的選擇。
3.5 Python實現
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler# Generate a sample dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Standardize the features (important for LDA)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# Initialize LDA and fit on the training data
lda = LinearDiscriminantAnalysis()
X_train_lda = lda.fit_transform(X_train, y_train)# Calculate explained variance ratio for each component
explained_variance_ratio = lda.explained_variance_ratio_# Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio)# Find the number of components that explain at least 75% of the variance
n_components = np.argmax(cumulative_explained_variance >= 0.75) + 1# Transform both the training and test data to the selected number of components
X_train_lda_selected = lda.transform(X_train)[:, :n_components]
X_test_lda_selected = lda.transform(X_test)[:, :n_components]# Print the number of components selected
print(f"Number of components selected: {n_components}")# Now, X_train_lda_selected and X_test_lda_selected can be used for further analysis or modeling此示例使用make_classificationscikit-learn 中的函數生成合成數據集,然后將數據拆分為訓練集和測試集。它標準化特征,初始化LDA模型,并將其擬合到訓練數據中。最后,它根據解釋的所需方差選擇組件數量,并相應地轉換訓練和測試數據。
四、奇異值分解 (SVD)
奇異值分解是一種矩陣分解技術,廣泛應用于各種應用,包括線性代數、信號處理和機器學習。它將一個矩陣分解為另外三個矩陣,允許以簡化形式表示原始矩陣。這里解釋了分解技術和證明。
4.1 SVD 的步驟:
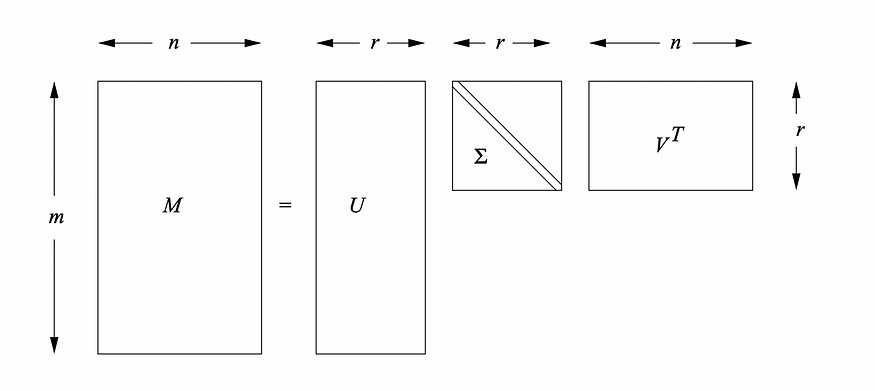
1. 矩陣的分解
給定一個大小為 mxn 的矩陣 M(或 m 行 n 列的數據框),SVD 將其分解為三個矩陣:
M = U *Σ *V?,
其中 U 是 mxm 正交矩陣,Σ 是mxr 對角矩陣,V 是 rxn 正交矩陣。r是矩陣M的秩。Σ的
對角線元素是原始矩陣M的奇異值,并且它們按降序排列。U 的列是 M 的左奇異向量。這些向量形成 M 的列空間的正交基。V 的列是 M 的右奇異向量。這些向量形成 M 的行空間的正交基。請閱讀本文以深入了解其背后的數學原理。
2. 簡化形式(截斷SVD)
對于降維,通常使用截斷版本的SVD。選擇 Σ 中前 k 個最大奇異值。這些列可以從 Σ 中選擇,行可以從 V? 中選擇。可以使用以下公式從原始矩陣 M 重建新矩陣 B:
B = U * Σ
B = V? * A,其中 Σ 僅包含原始 Σ 中基于奇異值的前 k 列,V? 包含原始 V? 中與奇異值對應的前 k 行。欲了解更多詳情,您可以參考這里。
4.2 優點:
1. 降維
SVD 允許通過僅保留最重要的奇異值和向量來降維。
2.數據壓縮
SVD用于數據壓縮任務,減少矩陣的存儲要求。
3. 降噪
通過僅使用最重要的奇異值,SVD 可以幫助減少數據中噪聲的影響。
4. 數值穩定性
SVD 具有數值穩定性,非常適合求解病態系統中的線性方程。
5.正交性
SVD分解中的矩陣U和V是正交的,保留了原始矩陣的行和列之間的關系。
6.在推薦系統中的應用
SVD廣泛應用于推薦系統的協同過濾中。
4.3 缺點:
1. 計算復雜性:
計算大型矩陣的完整 SVD 的計算成本可能很高。
2. 內存要求:
存儲完整的矩陣 U、Σ 和 V 可能會占用大量內存,尤其是對于大型矩陣。
3. 對缺失值的敏感性:
SVD 對數據中的缺失值很敏感,處理缺失值需要專門的技術。
4.4 何時使用 SVD:
1. 降維:
當目標是降低數據的維度同時保留其基本結構時。
2. 推薦系統:
在基于協同過濾的推薦系統中,SVD 用于識別捕獲用戶-項目交互的潛在因素。
3.數據壓縮:
在需要對大數據集進行壓縮或近似的場景中。
4. 數值穩定性:
在求解病態系統中的線性方程時,SVD 提供數值穩定性。
5.信號處理:
在信號處理中,SVD用于降噪和特征提取。
6. 主題建模:
SVD 用于主題建模技術,例如潛在語義分析(LSA)。
4.5 Python實現
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.decomposition import TruncatedSVD
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler# Generate a sample dataset
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Standardize the features (important for SVD)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# Initialize SVD and fit on the training data
svd = TruncatedSVD(n_components=X_train.shape[1] - 1) # Use one less component than the feature count
X_train_svd = svd.fit_transform(X_train)# Calculate explained variance ratio for each component
explained_variance_ratio = svd.explained_variance_ratio_# Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio)# Find the number of components that explain at least 75% of the variance
n_components = np.argmax(cumulative_explained_variance >= 0.75) + 1# Transform both the training and test data to the selected number of components
X_train_svd_selected = svd.transform(X_train)[:, :n_components]
X_test_svd_selected = svd.transform(X_test)[:, :n_components]# Print the number of components selected
print(f"Number of components selected: {n_components}")# Now, X_train_svd_selected and X_test_svd_selected can be used for further analysis or modeling此示例使用該make_classification函數生成合成數據集,將數據拆分為訓練集和測試集,并對特征進行標準化。然后,它初始化TruncatedSVD模型,將其擬合到訓練數據上,并根據所解釋的所需方差選擇組件的數量。最后,它相應地轉換訓練和測試數據。
五、結論
主成分分析 (PCA)、線性判別分析 (LDA) 和奇異值分解 (SVD) 之間的選擇取決于數據的具體目標和特征。以下是有關何時使用每種技術的一般準則:
1. PCA(主成分分析)
用例:
1. 當目標是降低數據集的維度時。
2. 在捕獲數據中的全局模式和關系至關重要的場景中。
3. 用于探索性數據分析和可視化。
2. LDA(線性判別分析)
用例:
1. 在分類問題中,增強類之間的分離很重要。
2. 當存在標記數據集時,目標是找到最大化類別區分度的投影。
3. 當類正態分布和協方差矩陣相等的假設成立時,LDA 特別有效。
3. SVD(奇異值分解)
用例:
1. 處理稀疏數據或缺失值時。
2. 在推薦系統的協同過濾中。
3. SVD也適用于數據壓縮和去噪。
我們應該考慮以下因素:
無監督與監督學習:PCA 是無監督的,而 LDA 是有監督的。根據標記數據的可用性進行選擇。
類可分離性:如果目標是提高類可分離性,則首選 LDA。PCA 和 SVD 關注整體方差。
數據特征:數據的特征(例如線性、類別分布和異常值的存在)會影響選擇。
應用程序特定要求:考慮應用程序的特定要求,例如可解釋性、計算效率或丟失數據的處理。
總之,PCA 適用于無監督降維,LDA 對于關注類可分離性的監督問題有效,而 SVD 用途廣泛,適合各種應用,包括協同過濾和矩陣分解。選擇取決于數據的性質和分析的目標。
您對此博客有任何疑問或建議嗎?請隨時留言。











:進制轉換,原碼,反碼,補碼)





手動編譯開發庫(win10+vs2019))

