1.MySQL中,如何定位慢查詢?
①介紹一下當時產生問題的場景(我們當時的一個接口測試的時候非常的慢,壓測的結果大概5秒鐘)
②我們系統中當時采用了運維工具( Skywalking ),可以監測出哪個接口,最終因為是sql的問題
③在mysql中開啟了慢日志查詢,我們設置的值就是2秒,一旦sql執行超過2秒就會記錄到日志中(調試階段)
面試回答:
我們當時做壓測的時候有的接口非常的慢,接口的響應時間超過了2秒以上,因為我們當時的系統部署了運維的監控系統Skywalking ,在展示的報表中可以看到是哪一個接口比較慢,并且可以分析這個接口哪部分比較慢,這里可以看到SQL的具體的執行時間,所以可以定位是哪個sql出了問題。
如果,項目中沒有這種運維的監控系統,其實在MySQL中也提供了慢日志查詢的功能,可以在MySQL的系統配置文件中開啟這個慢日志的功能,并且也可以設置SQL執行超過多少時間來記錄到一個日志文件中,我記得上一個項目配置的是2秒,只要SQL執行的時間超過了2秒就會記錄到日志文件中,我們就可以在日志文件找到執行比較慢的SQL了。
擴展:
方案一:開源工具
調試工具:Arthas
運維工具:Prometheus 、Skywalking
以Skywalking為例:

方案二:MySQL自帶慢日志
慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句的日志 如果要開啟慢查詢日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
SHOW VARIABLES LIKE 'slow_query_log';我的之前配置過,所以顯示的是ON(off為關,on為開):?

SHOW VARIABLES LIKE 'long_query_time';# 設置慢日志的時間為2秒,SQL語句執行時間超過2秒,就會視為慢查詢,記錄慢查詢日志
long_query_time=2

配置完畢之后,通過以下指令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息 /var/lib/mysql/localhost-slow.log。

2.那這個SQL語句執行很慢, 如何分析呢?
面試回答:
如果一條sql執行很慢的話,我們通常會使用mysql自動的執行計劃explain來去查看這條sql的執行情況。
①可以通過key和key_len檢查是否命中了索引,如果本身已經添加了索引,也可以判斷索引是否有失效的情況
②可以通過type字段查看sql是否有進一步的優化空間,是否存在全索引掃描或全盤掃描
③可以通過extra建議來判斷,是否出現了回表的情況,如果出現了,可以嘗試添加索引或修改返回字段來修復
擴展:
-- 直接在select語句之前加上關鍵字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 條件 ; ?
?
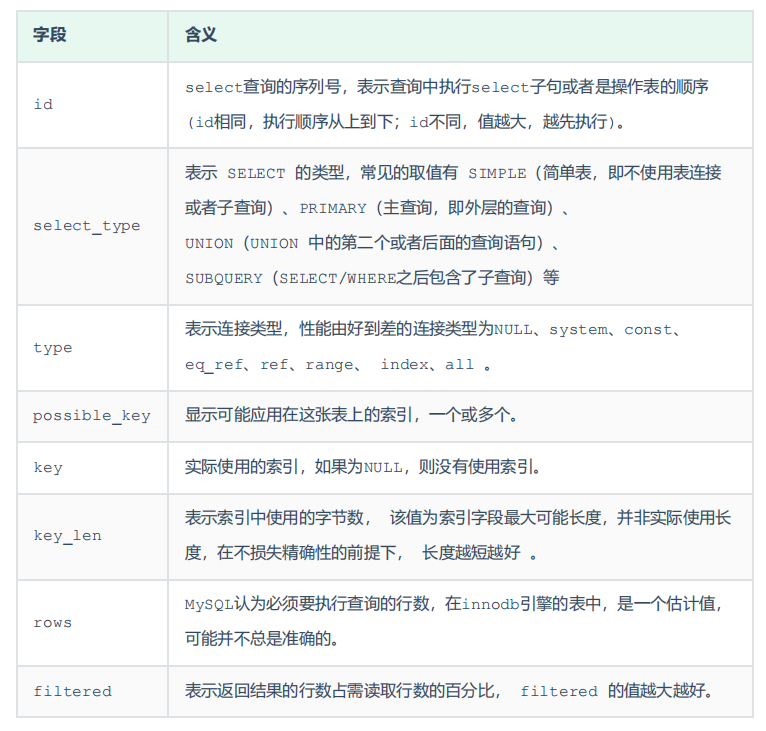
Explain?執行計劃中各個字段的含義:

3.了解過索引嗎?(什么是索引)
面試回答:
索引在項目中還是比較常見的,它是幫助MySQL高效獲取數據的數據結構,主要是用來提高數據檢索的效率,降低數據庫的IO成本,同時通過索引列對數據進行排序,降低數據排序的成本,也能降低了CPU的消耗。
擴展:
【MySQL進階】索引的結構及分類_mysql索引數據結構有哪些-CSDN博客
?
4.索引的底層數據結構了解過嘛?
面試回答:
MySQL的默認的存儲引擎InnoDB采用的B+樹的數據結構來存儲索引,選擇B+樹的主要的原因是:
①階數更多,路徑更短
②磁盤讀寫代價B+樹更低,非葉子節點只存儲指針,葉子階段存儲數據
③B+樹便于掃庫和區間查詢,葉子節點是一個雙向鏈表
?擴展:
【MySQL進階】索引的結構及分類_mysql索引數據結構有哪些-CSDN博客
5.B樹和B+樹的區別是什么呢?
面試回答:
第一:在B樹中,非葉子節點和葉子節點都會存放數據,而B+樹的所有的數據都會出現在葉子節點,在查詢的時候,B+樹查找效率更加穩定
第二:在進行范圍查詢的時候,B+樹效率更高,因為B+樹都在葉子節點存儲,并且葉子節點是一個雙向鏈表
?擴展:
【MySQL進階】索引的結構及分類_mysql索引數據結構有哪些-CSDN博客
6.InnoDB為什么使用B+樹實現索引?
面試回答:
首先看看B+樹有哪些特點:
- B+樹是一棵平衡樹,每個葉子節點到根節點的路徑長度相同,查找效率較高;
- B+樹的所有關鍵字都在葉子節點上,因此范圍查詢時只需要遍歷一遍葉子節點即可;
- B+樹的葉子節點都按照關鍵字大小順序存放,因此可以快速地支持按照關鍵字大小進行排序;
- B+樹的非葉子節點不存儲實際數據,因此可以存儲更多的索引數據;
- B+樹的非葉子節點使用指針連接子節點,因此可以快速地支持范圍查詢和倒序查詢。
- B+樹的葉子節點之間通過雙向鏈表鏈接,方便進行范圍查詢。
?
那么,使用B+樹實現索引,就有以下幾個優點:
- 支持范圍查詢,B+樹在進行范圍查找時,只需要從根節點一直遍歷到葉子節點,因為數據都存儲在葉子節點上,而且葉子節點之間有指針連接,可以很方便地進行范圍查找。
- 支持排序,B+樹的葉子節點按照關鍵字順序存儲,可以快速支持排序操作,提高排序效率;
- 存儲更多的索引數據,因為它的非葉子節點只存儲索引關鍵字,不存儲實際數據,因此可以存儲更多的索引數據;
- 在節點分裂和合并時,IO操作少。B+樹的葉子節點的大小是固定的,而且節點的大小一般都會設置為一頁的大小,這就使得節點分裂和合并時,IO操作很少,只需讀取和寫入一頁。
- 有利于磁盤預讀。由于B+樹的節點大小是固定的,因此可以很好地利用磁盤預讀特性,一次性讀取多個節點到內存中,這樣可以減少IO操作次數,提高查詢效率。
- 有利于緩存。B+樹的非葉子節點只存儲指向子節點的指針,而不存儲數據,這樣可以使得緩存能夠容納更多的索引數據,從而提高緩存的命中率,加快查詢速度。
?
7.什么是聚簇索引什么是非聚簇索引 ?
面試回答:
聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)是數據庫中的兩種索引類型,它們在組織和存儲數據時有不同的方式。
聚簇索引,簡單點理解就是將數據與索引放到了一起,找到索引也就找到了數據。也就是說,對于聚簇索引來說,他的非葉子節點上存儲的是索引字段的值,而他的葉子節點上存儲的是這條記錄的整行數據。
非聚簇索引,就是將數據與索引分開存儲,葉子節點包含索引字段值及指向數據頁數據行的邏輯指針。
- 對于聚簇索引來說,他的非葉子節點上存儲的是索引值,而它的葉子節點上存儲的是整行記錄。
- 對于非聚簇索引來說,他的非葉子節點上存儲的都是索引值,而它的葉子節點上存儲的是主鍵的值。
所以,通過非聚簇索引的查詢,需要進行一次回表,就是先查到主鍵ID,在通過ID查詢所需字段。
?擴展:

聚集索引選取規則:
如果存在主鍵,主鍵索引就是聚集索引。
如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引。
如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索引。
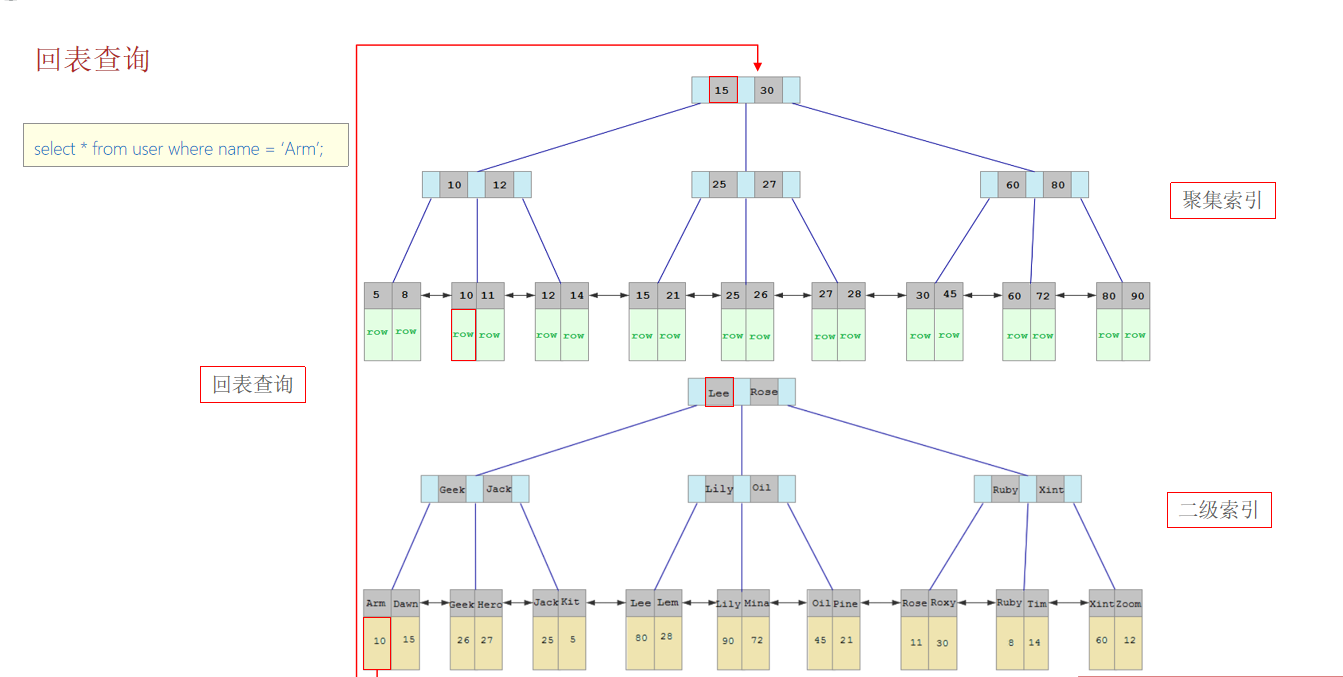
8.知道什么是回表查詢嗎?
在 InnoDB 里,索引B+ Tree的葉子節點存儲了整行數據的是主鍵索引,也被稱之為聚簇索引。而索引B+ Tree的葉子節點存儲了主鍵的值的是非主鍵索引,也被稱之為非聚簇索引。
在存儲的數據方面,主鍵(聚簇)索引的B+樹的葉子節點直接就是我們要查詢的整行數據了。而非主鍵(非聚簇)索引的葉子節點是主鍵的值。
那么,當我們根據非聚簇索引查詢的時候,會先通過非聚簇索引查到主鍵的值,之后,還需要再通過主鍵的值再進行一次查詢才能得到我們要查詢的數據。而這個過程就叫做回表。
所以,在InnoDB 中,使用主鍵查詢的時候,是效率更高的, 因為這個過程不需要回表。另外,依賴覆蓋索引、索引下推等技術,我們也可以通過優化索引結構以及SQL語句減少回表的次數。
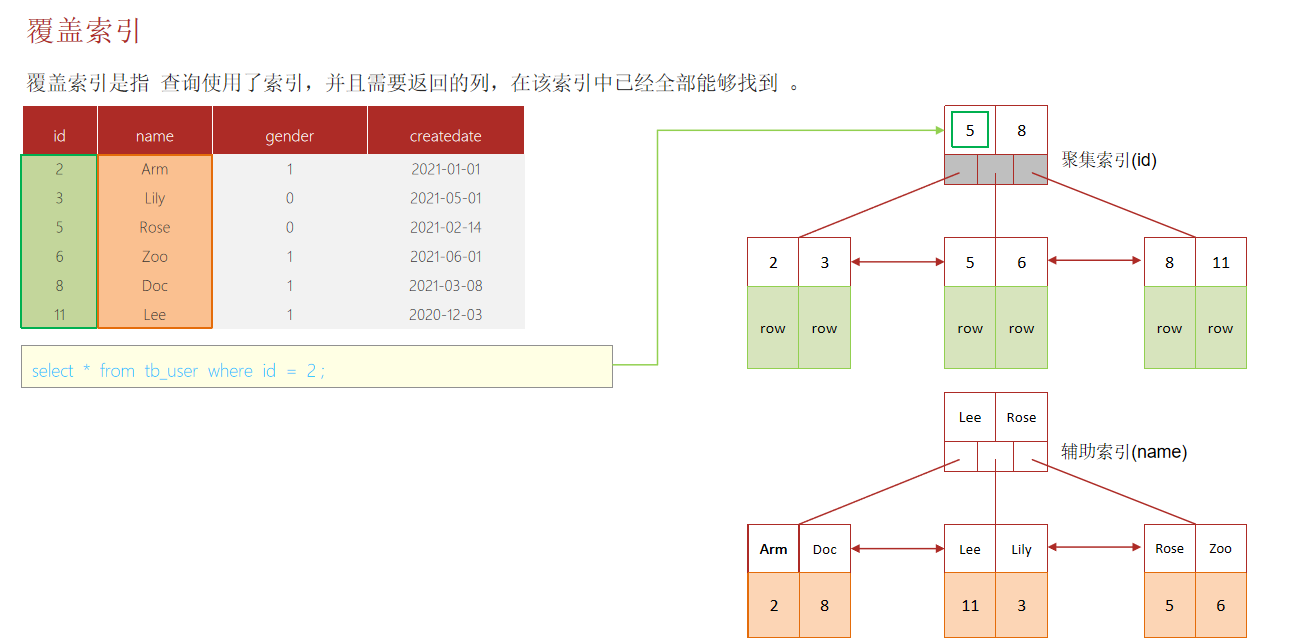
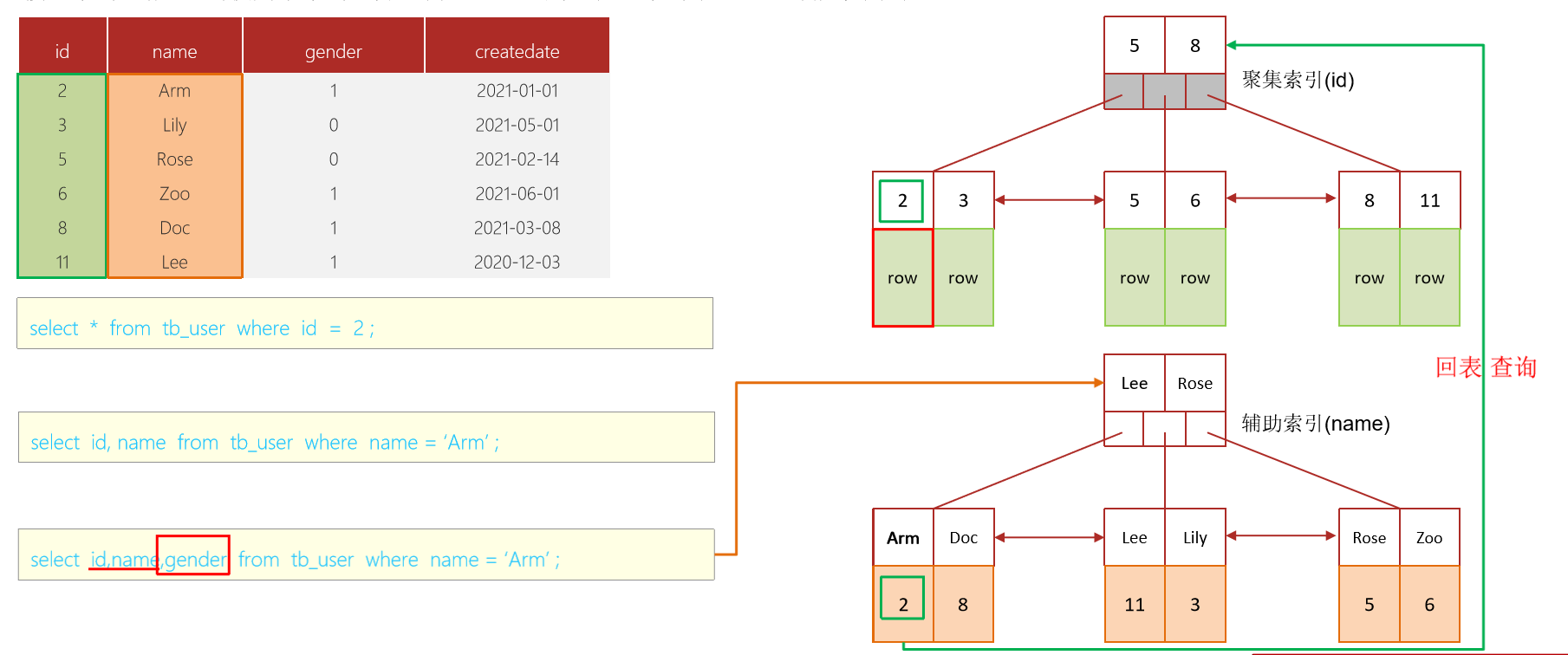
9.知道什么叫覆蓋索引嘛 ?
覆蓋索引是指select查詢語句使用了索引,在返回的列,必須在索引中全部能夠找到,如果我們使用id查詢,它會直接走聚集索引查詢,一次索引掃描,直接返回數據,性能高。
如果按照二級索引查詢數據的時候,返回的列中沒有創建索引,有可能會觸發回表查詢,盡量避免使用select *,盡量在返回的列中都包含添加索引的字段
當一條查詢語句符合覆蓋索引條件時,MySQL只需要通過索引就可以返回查詢所需要的數據,這樣避免了查到索引后再返回表操作,減少I/O提高效率。


10.MySQL超大分頁怎么處理 ?
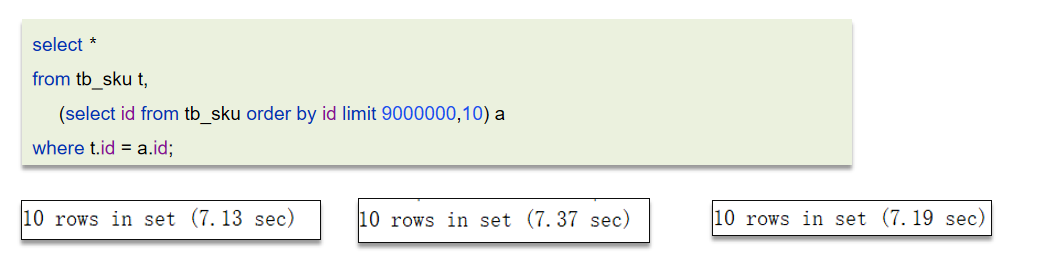
超大分頁一般都是在數據量比較大時,我們使用了limit分頁查詢,并且需要對數據進行排序,這個時候效率就很低,我們可以采用覆蓋索引和子查詢來解決
先分頁查詢數據的id字段,確定了id之后,再用子查詢來過濾,只查詢這個id列表中的數據就可以了
因為查詢id的時候,走的覆蓋索引,所以效率可以提升很多
?擴展:
我們一起來看看執行limit分頁查詢耗時對比:

因為,當在進行分頁查詢時,如果執行 limit 9000000,10 ,此時需要MySQL排序前9000010 記錄,僅僅返回 9000000 - 9000010 的記錄,其他記錄丟棄,查詢排序的代價非常大 。
優化思路: 一般分頁查詢時,通過創建 覆蓋索引 能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優化


:進制轉換,原碼,反碼,補碼)





手動編譯開發庫(win10+vs2019))








:Java的特性與優點及其發展史)

