中草藥藥材圖像識別相關的實踐在前文中已有對應的實踐了,感興趣的話可以自行移步閱讀即可:
《python基于輕量級GhostNet模型開發構建23種常見中草藥圖像識別系統》
《基于輕量級MnasNet模型開發構建40種常見中草藥圖像識別系統》
在上一篇文章中,我們提到在自主開發構建大規模的中草藥數據集,本文就是建立在這樣的背景基礎上的,目前已經構建了包含908種中草藥數據的基礎數據集,整體如下:

首先看下整體效果:
類別實例如下:
車前草
金銀花
蒲公英
鴨跖草
垂盆草
酸漿
蒼耳
馬蘭頭
薺菜
小薊
水芹菜
天胡荽
酢漿草
婆婆指甲菜
漆姑草
通泉草
波斯婆婆納
澤漆
狗尾巴草
旋復花
黃花菜
小飛蓬
金線草
鴨舌草
蘭花參
柴胡
麥冬
蛇莓
玉竹
桑白皮
曼陀羅
鬼針草
苦菜
葵菜
蕁麻
龍葵
蒺藜
何首烏
野薄荷
棕櫚
夏枯草
絞股藍
紫云英
七星草
芍藥
貝母
當歸
丹皮
柴胡
車前草
紫蘇
益母草
枇杷葉
荷葉
大青葉
艾葉
野菊花
金銀花
月季花
旋覆花
蓮子
菟絲子
銀杏
茴香
天麻
葛根
桔梗
黃柏
杜仲
厚樸
全蝎
地龍
土鱉蟲
蟋蟀
貝殼
珍珠
磁石
麻黃
桂枝
生姜
香薷
紫蘇葉
藁本
辛夷
防風
白芷
荊芥
羌活
蒼耳子
薄荷
牛蒡子
蔓荊子
蟬蛻
桑葉
葛根
柴胡
升麻
淡豆豉
知母
梔子
夏枯草
蘆根
天花粉
淡竹葉
黃芩
黃連
黃柏
龍膽
苦參
犀角
生地黃
玄參
牡丹皮
赤芍
金銀花
連翹
魚腥草
熟地黃
黨參
桂枝
山藥
枸杞子
車前草
紫蘇
大青葉
荷葉
青皮薄荷
柴胡
香附
當歸
黃芪
西洋參
茯苓
蒼術
艾葉
老姜
當歸
香附
益母草
玫瑰花
桑枝
薄荷
木瓜
雞血藤
女貞子
蓮子
薏米
百合
人參
太子參
鹿茸
龜板
鱉甲
杏仁
桔梗
陳皮
丹參
川芎
旱蓮草
車前子
大黃
夏枯草
連翹
金銀花
桂枝
柴胡
香附
薄荷
青皮
香櫞
佛手
熟地
當歸
川芎
白芍
阿膠
丹參
三七
桃仁
紅花
元胡
生地
石斛
沙參
麥冬
巴戟天
鎖陽
火炭母
地膽草
崩大碗
絞股藍
布荊
八角楓
八角茴香
八角金盤
八角蓮
八角蓮葉
目前數據總類別共有908種,來自我們不同成員的匯總,后續有新的類目可以持續進行擴充累積。
考慮到如此大類目的圖像識別,本文選擇的是經典的ResNet模型,殘差網絡(ResNet)是一種深度學習架構,用于解決深度神經網絡中的梯度消失和梯度爆炸問題。它引入了殘差塊(residual block)的概念,使網絡能夠更輕松地學習恒等映射,從而提高網絡的訓練效果。
ResNet的構建原理如下:
-
基礎模塊:ResNet的基礎模塊是殘差塊。每個殘差塊由兩個卷積層組成,每個卷積層后面跟著一個批量歸一化層(batch normalization)和一個激活函數(通常是ReLU)。這兩個卷積層的輸出通過跳躍連接(skip connection)相加,然后再通過激活函數。這個跳躍連接允許信息直接流過殘差塊,從而避免了信息在網絡中丟失或衰減。
-
堆疊殘差塊:ResNet通過堆疊多個殘差塊來構建更深的網絡。這些殘差塊可以有不同的層數和濾波器數量,以適應不同的任務和網絡深度需求。
-
池化層和全連接層:在堆疊殘差塊之后,可以添加池化層來減小特征圖的尺寸,并通過全連接層對最終的特征進行分類或回歸。
ResNet的優點:
-
解決梯度消失和梯度爆炸問題:由于殘差塊中的跳躍連接,ResNet可以更輕松地訓練深層網絡,避免了梯度在反向傳播過程中的消失或爆炸。
-
提高網絡的訓練效果:殘差塊允許網絡學習恒等映射,即將輸入直接傳遞到輸出。這使得網絡可以更容易地學習殘差部分,從而提高了網絡的訓練效果。
-
可以構建非常深的網絡:由于殘差連接的存在,ResNet可以堆疊更多的殘差塊,構建非常深的網絡。這有助于提取更復雜的特征,從而提高模型的表達能力。
ResNet的缺點:
-
參數較多:由于ResNet的深度,網絡中存在大量的參數,這會增加模型的復雜度和訓練時間。
-
訓練困難:盡管ResNet可以解決梯度消失和梯度爆炸問題,但在訓練較深的ResNet時,仍然可能出現其他訓練困難,如梯度退化問題和過擬合。
ResNet通過引入殘差塊和跳躍連接的方式,解決了深度神經網絡中的梯度消失和梯度爆炸問題,并提高了網絡的訓練效果。
這里給出對應的代碼實現:
# coding=utf-8
from keras.models import Model
from keras.layers import (Input,Dense,BatchNormalization,Conv2D,MaxPooling2D,AveragePooling2D,ZeroPadding2D,
)
from keras.layers import add, Flatten
from keras.optimizers import SGD
import numpy as npseed = 7
np.random.seed(seed)def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding="same", name=None):if name is not None:bn_name = name + "_bn"conv_name = name + "_conv"else:bn_name = Noneconv_name = Nonex = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation="relu",name=conv_name,)(x)x = BatchNormalization(axis=3, name=bn_name)(x)return xdef Conv_Block(inpt, nb_filter, kernel_size, strides=(1, 1), with_conv_shortcut=False):x = Conv2d_BN(inpt,nb_filter=nb_filter[0],kernel_size=(1, 1),strides=strides,padding="same",)x = Conv2d_BN(x, nb_filter=nb_filter[1], kernel_size=(3, 3), padding="same")x = Conv2d_BN(x, nb_filter=nb_filter[2], kernel_size=(1, 1), padding="same")if with_conv_shortcut:shortcut = Conv2d_BN(inpt, nb_filter=nb_filter[2], strides=strides, kernel_size=kernel_size)x = add([x, shortcut])return xelse:x = add([x, inpt])return xdef ResNet():inpt = Input(shape=(224, 224, 3))x = ZeroPadding2D((3, 3))(inpt)x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding="valid")x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding="same")(x)x = Conv_Block(x,nb_filter=[64, 64, 256],kernel_size=(3, 3),strides=(1, 1),with_conv_shortcut=True,)x = Conv_Block(x, nb_filter=[64, 64, 256], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[64, 64, 256], kernel_size=(3, 3))x = Conv_Block(x,nb_filter=[128, 128, 512],kernel_size=(3, 3),strides=(2, 2),with_conv_shortcut=True,)x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))x = Conv_Block(x,nb_filter=[256, 256, 1024],kernel_size=(3, 3),strides=(2, 2),with_conv_shortcut=True,)x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))x = Conv_Block(x,nb_filter=[512, 512, 2048],kernel_size=(3, 3),strides=(2, 2),with_conv_shortcut=True,)x = Conv_Block(x, nb_filter=[512, 512, 2048], kernel_size=(3, 3))x = Conv_Block(x, nb_filter=[512, 512, 2048], kernel_size=(3, 3))x = AveragePooling2D(pool_size=(7, 7))(x)x = Flatten()(x)x = Dense(908, activation="softmax")(x)model = Model(inputs=inpt, outputs=x)sgd = SGD(decay=0.0001, momentum=0.9)model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=["accuracy"])model.summary()
上面是基于Keras框架實現的,當然了也可以基于PyTorch框架實現,如下所示:
import torch
from torch import Tensor
import torch.nn as nn
import numpy as np
from torchvision._internally_replaced_utils import load_state_dict_from_url
from typing import Type, Any, Callable, Union, List, Optionaldef conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1
) -> nn.Conv2d:return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=dilation,groups=groups,bias=False,dilation=dilation,)def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class BasicBlock(nn.Module):expansion: int = 1def __init__(self,inplanes: int,planes: int,stride: int = 1,downsample: Optional[nn.Module] = None,groups: int = 1,base_width: int = 64,dilation: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,) -> None:super(BasicBlock, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dif groups != 1 or base_width != 64:raise ValueError("BasicBlock only supports groups=1 and base_width=64")if dilation > 1:raise NotImplementedError("Dilation > 1 not supported in BasicBlock")self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = norm_layer(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = norm_layer(planes)self.downsample = downsampleself.stride = stridedef forward(self, x: Tensor) -> Tensor:identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass Bottleneck(nn.Module):expansion: int = 4def __init__(self,inplanes: int,planes: int,stride: int = 1,downsample: Optional[nn.Module] = None,groups: int = 1,base_width: int = 64,dilation: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,) -> None:super(Bottleneck, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dwidth = int(planes * (base_width / 64.0)) * groups# Both self.conv2 and self.downsample layers downsample the input when stride != 1self.conv1 = conv1x1(inplanes, width)self.bn1 = norm_layer(width)self.conv2 = conv3x3(width, width, stride, groups, dilation)self.bn2 = norm_layer(width)self.conv3 = conv1x1(width, planes * self.expansion)self.bn3 = norm_layer(planes * self.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x: Tensor) -> Tensor:identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self,block: Type[Union[BasicBlock, Bottleneck]],layers: List[int],num_classes: int = 1000,zero_init_residual: bool = False,groups: int = 1,width_per_group: int = 64,replace_stride_with_dilation: Optional[List[bool]] = None,norm_layer: Optional[Callable[..., nn.Module]] = None,) -> None:super(ResNet, self).__init__()if norm_layer is None:norm_layer = nn.BatchNorm2dself._norm_layer = norm_layerself.inplanes = 64self.dilation = 1if replace_stride_with_dilation is None:replace_stride_with_dilation = [False, False, False]if len(replace_stride_with_dilation) != 3:raise ValueError("replace_stride_with_dilation should be None ""or a 3-element tuple, got {}".format(replace_stride_with_dilation))self.groups = groupsself.base_width = width_per_groupself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = norm_layer(self.inplanes)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)if zero_init_residual:for m in self.modules():if isinstance(m, Bottleneck):nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]elif isinstance(m, BasicBlock):nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]def _make_layer(self,block: Type[Union[BasicBlock, Bottleneck]],planes: int,blocks: int,stride: int = 1,dilate: bool = False,) -> nn.Sequential:norm_layer = self._norm_layerdownsample = Noneprevious_dilation = self.dilationif dilate:self.dilation *= stridestride = 1if stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(conv1x1(self.inplanes, planes * block.expansion, stride),norm_layer(planes * block.expansion),)layers = []layers.append(block(self.inplanes,planes,stride,downsample,self.groups,self.base_width,previous_dilation,norm_layer,))self.inplanes = planes * block.expansionfor _ in range(1, blocks):layers.append(block(self.inplanes,planes,groups=self.groups,base_width=self.base_width,dilation=self.dilation,norm_layer=norm_layer,))return nn.Sequential(*layers)def _forward_impl(self, x: Tensor, need_fea=False) -> Tensor:if need_fea:features, features_fc = self.forward_features(x, need_fea)x = self.fc(features_fc)return features, features_fc, xelse:x = self.forward_features(x)x = self.fc(x)return xdef forward(self, x: Tensor, need_fea=False) -> Tensor:return self._forward_impl(x, need_fea)def forward_features(self, x, need_fea=False):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)if need_fea:x1 = self.layer1(x)x2 = self.layer2(x1)x3 = self.layer3(x2)x4 = self.layer4(x3)x = self.avgpool(x4)x = torch.flatten(x, 1)return [x1, x2, x3, x4], xelse:x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)return xdef cam_layer(self):return self.layer4def _resnet(block: Type[Union[BasicBlock, Bottleneck]],layers: List[int],pretrained: bool,progress: bool,**kwargs: Any
) -> ResNet:model = ResNet(block, layers, **kwargs)if pretrained:state_dict = load_state_dict_from_url("https://download.pytorch.org/models/resnet50-0676ba61.pth",progress=progress,)model_dict = model.state_dict()weight_dict = {}for k, v in state_dict.items():if k in model_dict:if np.shape(model_dict[k]) == np.shape(v):weight_dict[k] = vpretrained_dict = weight_dictmodel_dict.update(pretrained_dict)model.load_state_dict(model_dict)return modeldef resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:return _resnet(Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
可以根據自己的喜好,直接集成到自己的項目中進行使用都是可以的。
整體訓練loss曲線如下所示:
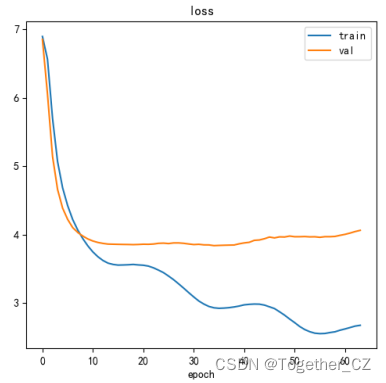
準確率曲線如下所示:

目前僅僅從零開始訓練了60多個epoch,效果不是很理想,后續計劃基于預訓練的模型權重來進行微調訓練提升當前的精度。
)


與Android系統 各自特點 架構對比 各自優勢)



)



報錯:unknown error: unsupported protocol)


單目初始化)

-window、distinct、join等)


