文章目錄
- 0 前言
- 1\. 目標檢測概況
- 1.1 什么是目標檢測?
- 1.2 發展階段
- 2\. 行人檢測
- 2.1 行人檢測簡介
- 2.2 行人檢測技術難點
- 2.3 行人檢測實現效果
- 2.4 關鍵代碼-訓練過程
- 最后
0 前言
🔥 優質競賽項目系列,今天要分享的是
🚩 畢業設計 交通目標檢測-行人車輛檢測流量計數
該項目較為新穎,適合作為競賽課題方向,學長非常推薦!
🥇學長這里給一個題目綜合評分(每項滿分5分)
- 難度系數:3分
- 工作量:3分
- 創新點:4分
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1. 目標檢測概況
1.1 什么是目標檢測?
目標檢測,粗略來說就是:輸入圖片/視頻,經過處理,得到:目標的位置信息(比如左上角和右下角的坐標)、目標的預測類別、目標的預測置信度(confidence)。
1.2 發展階段
-
手工特征提取算法,如VJ、HOG、DPM
-
R-CNN算法(2014),最早的基于深度學習的目標檢測器之一,其結構是兩級網絡:
- 1)首先需要諸如選擇性搜索之類的算法來提出可能包含對象的候選邊界框;
- 2)然后將這些區域傳遞到CNN算法進行分類;
-
R-CNN算法存在的問題是其仿真很慢,并且不是完整的端到端的目標檢測器。
-
Fast R-CNN算法(2014末),對原始R-CNN進行了相當大的改進:提高準確度,并減少執行正向傳遞所花費的時間。
是,該模型仍然依賴于外部區域搜索算法。 -
faster R-CNN算法(2015),真正的端到端深度學習目標檢測器。刪除了選擇性搜索的要求,而是依賴于
- (1)完全卷積的區域提議網絡(RPN, Region Purpose Network),可以預測對象邊界框和“對象”分數(量化它是一個區域的可能性的分數)。
- (2)然后將RPN的輸出傳遞到R-CNN組件以進行最終分類和標記。
-
R-CNN系列算法,都采取了two-stage策略。特點是:雖然檢測結果一般都非常準確,但仿真速度非常慢,即使是在GPU上也僅獲得5 FPS。
-
one-stage方法有:yolo(2015)、SSD(2015末),以及在這兩個算法基礎上改進的各論文提出的算法。這些算法的基本思路是:均勻地在圖片的不同位置進行密集抽樣,抽樣時可以采用不同尺度和長寬比,然后利用CNN提取特征后直接進行分類與回歸。
整個過程只需要一步,所以其優勢是速度快,但是訓練比較困難。 -
yolov3(2018)是yolo作者提出的第三個版本(之前還提過yolov2和它們的tinny版本,tinny版本經過壓縮更快但是也降低了準確率)。
2. 行人檢測
這里學長以行人檢測作為例子來講解目標檢測。
2.1 行人檢測簡介
行人檢測( Pedestrian
Detection)一直是計算機視覺研究中的熱點和難點。行人檢測要解決的問題是:找出圖像或視頻幀中所有的行人,包括位置和大小,一般用矩形框表示,和人臉檢測類似,這也是典型的目標檢測問題。
行人檢測技術有很強的使用價值,它可以與行人跟蹤,行人重識別等技術結合,應用于汽車無人駕駛系統(ADAS),智能機器人,智能視頻監控,人體行為分析,客流統計系統,智能交通等領域。
2.2 行人檢測技術難點
由于人體具有相當的柔性,因此會有各種姿態和形狀,其外觀受穿著,姿態,視角等影響非常大,另外還面臨著遮擋
、光照等因素的影響,這使得行人檢測成為計算機視覺領域中一個極具挑戰性的課題。行人檢測要解決的主要難題是:
-
外觀差異大:包括視角,姿態,服飾和附著物,光照,成像距離等。從不同的角度看過去,行人的外觀是很不一樣的。處于不同姿態的行人,外觀差異也很大。由于人穿的衣服不同,以及打傘、戴帽子、戴圍巾、提行李等附著物的影響,外觀差異也非常大。光照的差異也導致了一些困難。遠距離的人體和近距離的人體,在外觀上差別也非常大。
-
遮擋問題: 在很多應用場景中,行人非常密集,存在嚴重的遮擋,我們只能看到人體的一部分,這對檢測算法帶來了嚴重的挑戰。
-
背景復雜:無論是室內還是室外,行人檢測一般面臨的背景都非常復雜,有些物體的外觀和形狀、顏色、紋理很像人體,導致算法無法準確的區分。
-
檢測速度:行人檢測一般采用了復雜的模型,運算量相當大,要達到實時非常困難,一般需要大量的優化。
2.3 行人檢測實現效果
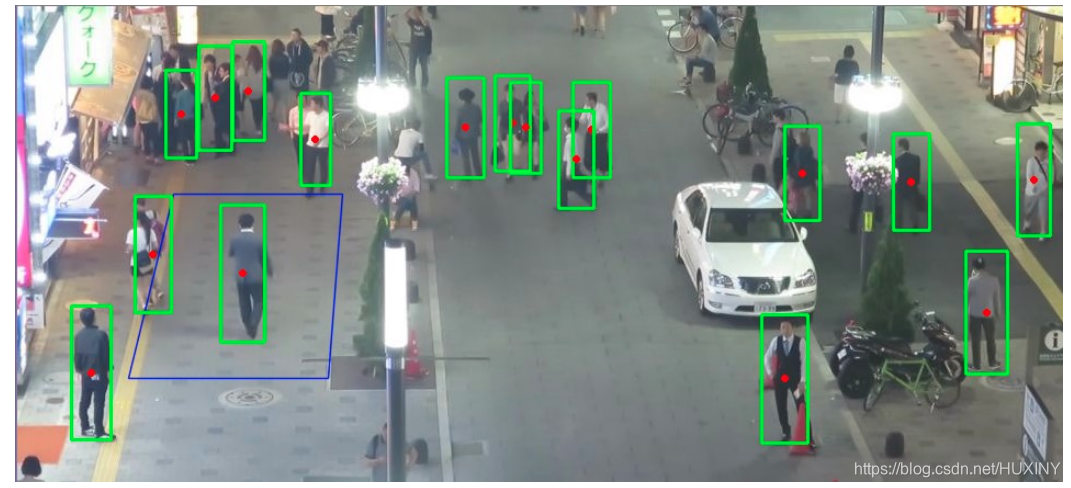
檢測到行人后還可以做流量分析:
2.4 關鍵代碼-訓練過程
?
import cv2import numpy as npimport randomdef load_images(dirname, amout = 9999):img_list = []file = open(dirname)img_name = file.readline()while img_name != '': # 文件尾img_name = dirname.rsplit(r'/', 1)[0] + r'/' + img_name.split('/', 1)[1].strip('\n')img_list.append(cv2.imread(img_name))img_name = file.readline()amout -= 1if amout <= 0: # 控制讀取圖片的數量breakreturn img_list# 從每一張沒有人的原始圖片中隨機裁出10張64*128的圖片作為負樣本def sample_neg(full_neg_lst, neg_list, size):random.seed(1)width, height = size[1], size[0]for i in range(len(full_neg_lst)):for j in range(10):y = int(random.random() * (len(full_neg_lst[i]) - height))x = int(random.random() * (len(full_neg_lst[i][0]) - width))neg_list.append(full_neg_lst[i][y:y + height, x:x + width])return neg_list# wsize: 處理圖片大小,通常64*128; 輸入圖片尺寸>= wsizedef computeHOGs(img_lst, gradient_lst, wsize=(128, 64)):hog = cv2.HOGDescriptor()# hog.winSize = wsizefor i in range(len(img_lst)):if img_lst[i].shape[1] >= wsize[1] and img_lst[i].shape[0] >= wsize[0]:roi = img_lst[i][(img_lst[i].shape[0] - wsize[0]) // 2: (img_lst[i].shape[0] - wsize[0]) // 2 + wsize[0], \(img_lst[i].shape[1] - wsize[1]) // 2: (img_lst[i].shape[1] - wsize[1]) // 2 + wsize[1]]gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)gradient_lst.append(hog.compute(gray))# return gradient_lstdef get_svm_detector(svm):sv = svm.getSupportVectors()rho, _, _ = svm.getDecisionFunction(0)sv = np.transpose(sv)return np.append(sv, [[-rho]], 0)# 主程序# 第一步:計算HOG特征neg_list = []pos_list = []gradient_lst = []labels = []hard_neg_list = []svm = cv2.ml.SVM_create()pos_list = load_images(r'G:/python_project/INRIAPerson/96X160H96/Train/pos.lst')full_neg_lst = load_images(r'G:/python_project/INRIAPerson/train_64x128_H96/neg.lst')sample_neg(full_neg_lst, neg_list, [128, 64])print(len(neg_list))computeHOGs(pos_list, gradient_lst)[labels.append(+1) for _ in range(len(pos_list))]computeHOGs(neg_list, gradient_lst)[labels.append(-1) for _ in range(len(neg_list))]# 第二步:訓練SVMsvm.setCoef0(0)svm.setCoef0(0.0)svm.setDegree(3)criteria = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 1000, 1e-3)svm.setTermCriteria(criteria)svm.setGamma(0)svm.setKernel(cv2.ml.SVM_LINEAR)svm.setNu(0.5)svm.setP(0.1) # for EPSILON_SVR, epsilon in loss function?svm.setC(0.01) # From paper, soft classifiersvm.setType(cv2.ml.SVM_EPS_SVR) # C_SVC # EPSILON_SVR # may be also NU_SVR # do regression tasksvm.train(np.array(gradient_lst), cv2.ml.ROW_SAMPLE, np.array(labels))# 第三步:加入識別錯誤的樣本,進行第二輪訓練# 參考 http://masikkk.com/article/SVM-HOG-HardExample/hog = cv2.HOGDescriptor()hard_neg_list.clear()hog.setSVMDetector(get_svm_detector(svm))for i in range(len(full_neg_lst)):rects, wei = hog.detectMultiScale(full_neg_lst[i], winStride=(4, 4),padding=(8, 8), scale=1.05)for (x,y,w,h) in rects:hardExample = full_neg_lst[i][y:y+h, x:x+w]hard_neg_list.append(cv2.resize(hardExample,(64,128)))computeHOGs(hard_neg_list, gradient_lst)[labels.append(-1) for _ in range(len(hard_neg_list))]svm.train(np.array(gradient_lst), cv2.ml.ROW_SAMPLE, np.array(labels))# 第四步:保存訓練結果hog.setSVMDetector(get_svm_detector(svm))hog.save('myHogDector.bin')最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate

報錯:unknown error: unsupported protocol)


單目初始化)

-window、distinct、join等)







技術參數分享)
![二叉樹的層序遍歷[中等]](http://pic.xiahunao.cn/二叉樹的層序遍歷[中等])



