本文以yolo系列代碼為基礎,在其中查找用到的numpy函數,包含近50個函數,本文花費多天,三萬多字,通過豐富的函數原理和示例對這些函數進行詳解。以幫助大家理解和使用。
目錄
- np.array()
- 運行示例
- np.asarray()
- 函數解析
- 運行示例
- 列表轉換為 NumPy 數組
- 元組轉換為 NumPy 數組
- np.random.uniform()
- 函數解析
- 運行示例
- np.arange()
- 函數解析
- 運行示例
- np.clip()
- 函數解析
- 運行示例
- np.append()
- 函數解析
- 運行示例
- 不使用 axis 參數:
- 使用 axis =0:
- 使用 axis =1
- np.mod()
- 函數解析
- 運行示例
- np.eye()
- 函數解析
- 運行示例
- 創建2*2矩陣
- 創建4*5矩陣
- np.zeros()
- 函數解析
- 運行示例
- np.ones()
- 函數解析
- 運行示例
- np.concatenate()
- 函數解析
- 運行示例
- np.random.beta()
- 函數解析
- 運行示例
- np.maximum()
- 函數解析
- 運行示例
- np.maximum.accumulate()
- 函數解析
- 運行示例
- 例子1
- 例子2
- np.minimum()
- 函數解析
- 運行示例
- np.full()
- 函數解析
- 運行示例
- np.ascontiguousarray()
- 函數解析
- 運行示例
- np.random.seed()
- 函數解析
- 運行示例
- np.stack()
- 函數解析
- 運行示例
- np.unique
- 函數解析
- 運行示例
- np.zeros_like
- 函數解析
- 運行示例
- np.save ()
- 函數解析
- 運行示例
- np.load ()
- 函數解析
- 運行示例
- np.floor()
- 函數解析
- 運行示例
- np.ceil()
- 函數解析
- 運行示例
- np.flipud()
- 函數解析
- 運行示例
- np.fliplr()
- 函數解析
- 運行示例
- np.hstack()
- 函數解析
- 運行示例
- 一維數組
- 二維數組
- np.vstack()
- 函數解析
- 運行示例
- np.bincount()
- 函數解析
- 運行示例
- np.argmax()
- 函數解析
- 運行示例
- 一維數組
- 二維數組(默認行為)
- 二維數組(指定軸)
- np.argmin()
- 函數解析
- 運行示例
- 一維數組
- 二維數組(默認行為)
- 二維數組(指定軸)
- np.argsort()
- 函數解析
- 運行示例
- 一維數組排序索引
- 二維數組排序索引
- 使用排序索引重新構造數組
- np.set_printoptions()
- 函數解析
- 運行示例
- 設置浮點數的精度
- 設置數組元素的閾值
- 設置每行的最大字符數
- np.loadtxt()
- 函數解析
- 運行示例
- 用`.`號分隔數據的文本文件
- 加載包含注釋的文本文件,并跳過前三行
- np.linspace()
- 函數解析
- 運行示例
- np.copy()
- 函數解析
- 運行示例
- np.interp()
- 函數解析
- 運行示例
- np.ndarray()
- 函數解析
- 運行示例
- np.fromfile()
- 函數解析
- 運行示例
- np.convolve()
- 函數解析
- 運行示例
- 卷積運算
- np.trapz()
- 函數解析
- 運行示例
- np.where()
- 函數解析
- 運行示例
- 單條件
- 多條件
- np.sum()
- 函數解析
- 運行示例
- np.nan()
- 函數解析
- 運行示例
- np.log()
- 函數解析
- 運行示例
- np.linalg.lstsq()
- 函數解析
- 運行示例
- np.empty()
- 函數解析
- 運行示例
- 結束語
np.array()
np.array()函數是NumPy庫中創建數組的主要方法,它接受一組參數,每個參數都可以是數組,公開數組接口的任何對象,或者任何(嵌套)序列。
np.array()函數的作用是將輸入的對象(或對象序列)轉換為一個新的NumPy數組。
函數原型:
numpy.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)參數詳解:object:可以是一個列表、元組、字典或者另一個 NumPy 數組。也可以是公開數組接口的任何對象,或者任何(嵌套)序列。
dtype:可選參數,用來指定數組元素的類型。例如,np.array([1, 2, 3]) 默認情況下元素的類型是 int,但如果你指定了 dtype=np.float32,那么元素類型就會變成 float32。
copy:可選參數,默認為 True。如果為 True,那么會創建一個新的數組,復制輸入的對象。如果為 False,那么可能會共享數據,即改變原數據也會影響返回的數組。
order:可選參數,默認為 'K'。這決定了數據的存儲順序。'K' 代表 Fortran 的存儲順序(行優先),'C' 代表 C 的存儲順序(列優先)。
subok:可選參數,默認為 False。如果為 True,那么返回的數組將是輸入對象的子類。如果為 False,那么返回的數組將是基類數組。
ndmin:可選參數,默認為 0。這決定了返回的數組的最小維度數。例如,如果你指定了 ndmin=2,那么即使輸入的是一個標量,也會返回一個一維數組。
運行示例
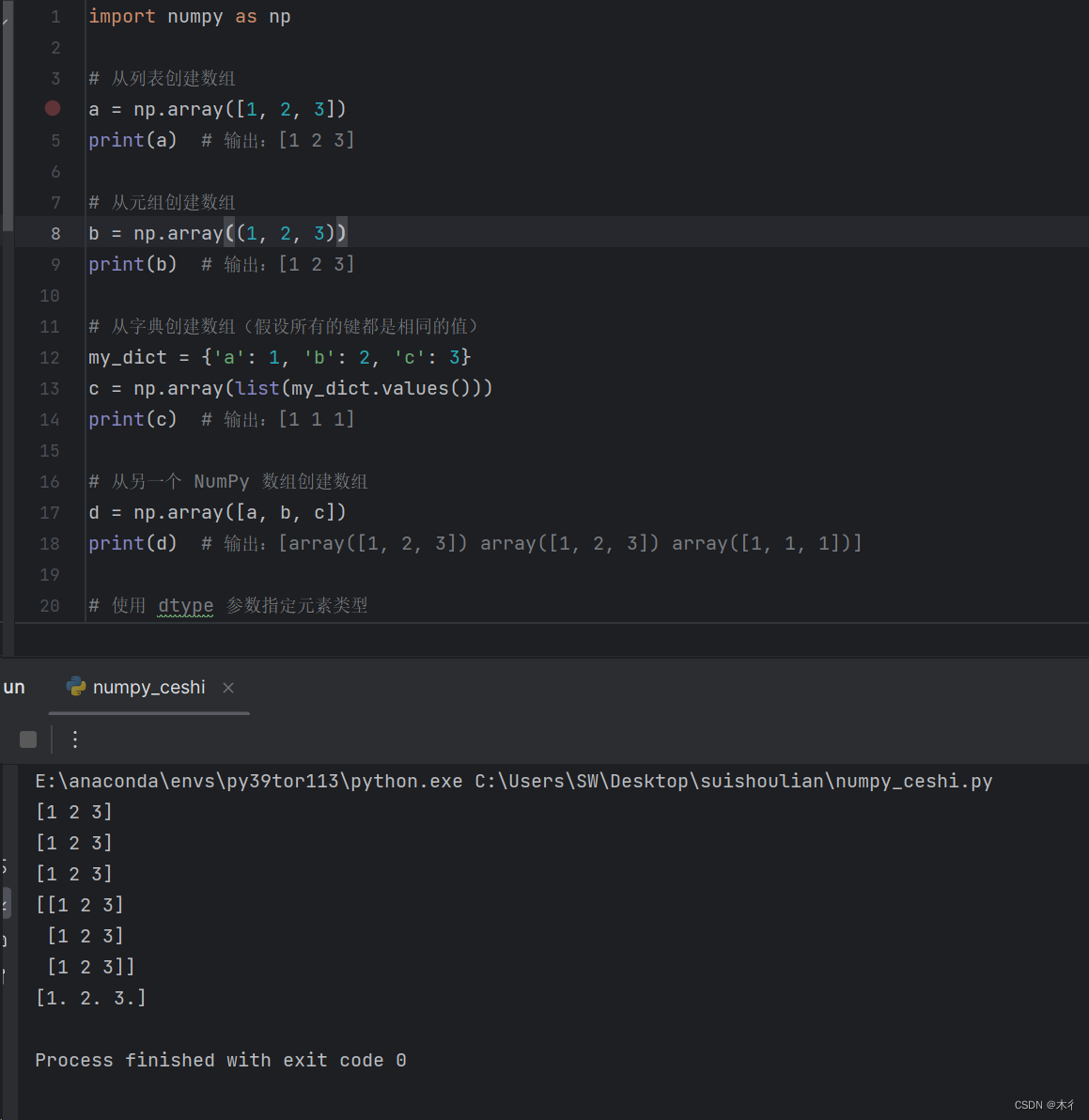
import numpy as np# 從列表創建數組
a = np.array([1, 2, 3])
print(a) # 輸出:[1 2 3]# 從元組創建數組
b = np.array((1, 2, 3))
print(b) # 輸出:[1 2 3]# 從字典創建數組(假設所有的鍵都是相同的值)
my_dict = {'a': 1, 'b': 2, 'c': 3}
c = np.array(list(my_dict.values()))
print(c) # 輸出:[1 1 1]# 從另一個 NumPy 數組創建數組
d = np.array([a, b, c])
print(d) # 輸出:[array([1, 2, 3]) array([1, 2, 3]) array([1, 1, 1])]# 使用 dtype 參數指定元素類型
e = np.array([1, 2, 3], dtype=np.float32)
print(e) # 輸出:[1. 2. 3.]
np.asarray()
np.asarray 是 NumPy 庫中的一個函數,用于將一個具有不同類型的數據集合(例如 Python 列表、元組或 NumPy 數組)轉換為一個 NumPy 數組。
函數解析
函數原型:
numpy.asarray(a)參數:
a:一個可迭代對象(例如 Python 列表、元組或其他 NumPy 數組)。返回值:
返回一個新的 NumPy 數組,其中包含 a 中的數據,但以 NumPy 數組的形式表示。注意事項:
如果 a 已經是一個 NumPy 數組,那么 np.asarray 不會進行任何轉換,直接返回該數組。
如果 a 是一個 Python 列表或其他不可直接轉換為 NumPy 數組的對象,np.asarray 會嘗試將其轉換為 NumPy 數組。
如果 a 是一個可迭代對象,但其中的元素不是同一種類型,那么 np.asarray 將返回一個 object 類型的數組,其中包含原始對象的引用。
運行示例
列表轉換為 NumPy 數組
import numpy as np
list1 = [1, 2, 3, 4, 5]
arr1 = np.asarray(list1)
print(arr1)
輸出:
[1 2 3 4 5]
元組轉換為 NumPy 數組
import numpy as nptuple1 = (1, 2, 3, 4, 5)
arr2 = np.asarray(tuple1)
print(arr2)
輸出:
[1 2 3 4 5]
np.random.uniform()
np.random.uniform() 是 NumPy 庫中的一個函數,用于生成一個指定形狀的數組,數組元素的值均勻分布在指定的范圍內。
函數解析
函數原型:
np.random.uniform(low, high, size)參數詳解:
low:生成隨機數的最小值(含)。默認為0。
high:生成隨機數的最大值(不含)。不能小于 low。默認為1。
size:生成的隨機數數組的形狀。可以是正整數、負整數或零,分別代表的形狀為(n,),(n,n),(n,n,n)等。默認為None,代表生成的隨機數數組形狀為一個。
返回值:生成的隨機數數組。
運行示例
(1)生成一個元素范圍在0到1之間的隨機數數組,形狀為(3,):
import numpy as np
print(np.random.uniform(0, 1, 3))
輸出的一種:
[0.59394381 0.64440999 0.91008711]
(2)生成一個元素范圍在1到10之間的隨機數數組,形狀為(2,2):
import numpy as np
print(np.random.uniform(1, 10, (2, 2)))
輸出的一種:
[[7.2666767 6.93297231][9.65006062 8.67068568]]
np.arange()
np.arange() 是 NumPy 庫中的一個函數,用于生成一個包含一定范圍內整數的數組。這個函數在 Python 的內置 range() 函數的基礎上提供了更多的靈活性和功能。
函數解析
函數原型為:
np.arange([start,] stop[, step,], dtype=None)參數詳解:start:起始值。默認為0。
stop:結束值。生成的數組將包含到此值之前的所有整數。請注意,數組的最后一個元素將是 stop-1。
step:步長。默認為1。生成的數組的每個元素之間的差值就是這個步長。
dtype:可選參數,生成的數組的數據類型。如果未指定,則默認為當前 NumPy 數據類型。返回值:一個包含一定范圍內整數的 NumPy 數組。
運行示例
(1)生成從0到9(包含0,不包含10)的整數數組,步長為2:
import numpy as np
print(np.arange(0, 10, 2))
輸出:
[0 2 4 6 8]
(2)生成一個長度為10的數組,元素從1開始,到100結束(不包含100),步長為10:
import numpy as np
print(np.arange(1, 100, 10))
輸出:
[ 1 11 21 31 41 51 61 71 81 91]
np.clip()
np.clip()是NumPy庫中的一個函數,它用于將數組中的元素限制在指定的范圍內。這個函數接受兩個參數,即最小值和最大值,所有超過這個范圍的元素都會被限制在這個范圍內。
函數解析
函數原型為:
np.clip(a, a_min, a_max)參數詳解:a:輸入數組。
a_min:限制下限。所有小于a_min的a中的元素將被替換為a_min。
a_max:限制上限。所有大于a_max的a中的元素將被替換為a_max。
返回值:一個新的數組,其中的元素被限制在a_min和a_max之間。
運行示例
import numpy as np# 創建一個隨機數組
arr = np.random.rand(5) * 100
print("Original array:", arr)# 使用np.clip()將數組中的元素限制在0到10之間
clipped_arr = np.clip(arr, 0, 10)
print("Clipped array:", clipped_arr)
輸出:
Original array: [89.01030861 7.78381296 52.43930124 70.35602011 62.99517335]
Clipped array: [10. 7.78381296 10. 10. 10. ]
在這個示例中,原始數組中的元素被限制在0到10之間。所有超過這個范圍的元素都被替換為對應的邊界值(小于0的元素被替換為0,大于10的元素被替換為10)。
np.append()
np.append() 是 NumPy 庫中的一個函數,它用于將一個或多個數組添加到另一個數組的末尾。這個函數不會改變原始數組,而是返回一個新的數組。
函數解析
函數原型為:
np.append(arr, values[, axis])參數詳解:
arr:要添加其他數組的數組。
values:要添加到 arr 的數組或列表。這可以是多個數組或列表。
axis:可選參數,定義了 values 中的數組沿著哪個軸添加到 arr 中。默認值為 None,這意味著 values 中的數組將被展平并添加到 arr 的末尾。如果指定了 axis,則 values 中的數組將被添加到 arr 的指定軸上。
運行示例
不使用 axis 參數:
import numpy as nparr = np.array([1, 2, 3])
values = np.array([4, 5, 6])appended_arr = np.append(arr, values)
print(appended_arr)
輸出:
[1 2 3 4 5 6]
使用 axis =0:
import numpy as nparr = np.array([[1, 2], [3, 4]])
values = np.array([5, 6])# 將 values 轉換為二維數組
values_2d = np.reshape(values, (1, -1))appended_arr = np.append(arr, values_2d, axis=0)
print(appended_arr)
輸出:
[[1 2][3 4][5 6]]
使用 axis =1
import numpy as nparr = np.array([[1, 2], [3, 4]])
values = np.array([5, 6])# 將 values 轉換為二維數組
values_2d = np.reshape(values, (-1, 1))appended_arr = np.append(arr, values_2d, axis=1)
print(appended_arr)
輸出:
[[1 2 5][3 4 6]]
注意:按照行或列拼接時注意要相同的維度,0是行拼接,1是列。
np.mod()
np.mod() 是 NumPy 庫中的一個函數,它用于計算兩個數的模(余數)。該函數的語法為 np.mod(x, y),其中 x 和 y 是要計算模的兩個數。
函數解析
函數的工作方式與 Python 內置的 % 運算符類似,但有一個重要的區別:np.mod() 函數可以處理浮點數和非整數,而 Python 的 % 運算符只能處理整數。
運行示例
import numpy as npx1 = np.array([10, 10.5])
x2 = np.array([3, 3.2])result = np.mod(x1, x2)
print(result)
輸出:
[1. 0.9]
在上面的示例中,我們使用 np.mod() 函數計算了 x1 對 x2 的模,并將結果存儲在 result 數組中。
np.eye()
函數解析
函數原型:
np.eye(n, m=None, k=0, dtype=<class 'NoneType'>)參數:n:整數,表示要生成的單位矩陣的行數或列數,取決于是否指定了m參數。如果m未指定,則n既是行數也是列數。
m:整數,表示要生成的單位矩陣的列數或行數,取決于是否指定了n參數。如果n未指定,則m既是列數也是行數。
k:整數,表示對角線偏離中心的偏移量。默認值為0,表示對角線居中。
dtype:數據類型,默認為None。如果指定了數據類型,則生成矩陣的數據類型將被指定為該類型。
該函數返回一個單位矩陣,其中對角線上的元素為1,其他位置的元素為0。通過調用 np.eye(),我們可以創建不同大小和維度的單位矩陣。
運行示例
創建2*2矩陣
mport numpy as npidentity_matrix = np.eye(2)
print(identity_matrix)
輸出:
[[1. 0.][0. 1.]]
創建4*5矩陣
import numpy as npidentity_matrix = np.eye(4, 5,dtype=np.float32)
print(identity_matrix)
輸出:
[[1. 0. 0. 0. 0.][0. 1. 0. 0. 0.][0. 0. 1. 0. 0.][0. 0. 0. 1. 0.]]
np.zeros()
np.zeros() 是 NumPy 庫中的一個函數,用于創建一個形狀和大小都為零的數組。該函數的主要參數是形狀,可以接受的形式有:一個整數,一個元組,或者一個表示形狀的數組。
函數解析
函數的詳細解釋如下:np.zeros(shape)
shape:一個整數或一個元組,指定要創建的數組的形狀。例如,np.zeros(3) 會創建一個長度為3的零向量,np.zeros((2,3)) 會創建一個2行3列的全零矩陣。
函數返回的是一個填充了0的數組。
運行示例
import numpy as np# 創建一個長度為10的零向量
v = np.zeros(10)
print(v)
# 結果:[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]# 創建一個3行2列的全零矩陣
m = np.zeros((3,2))
print(m)
# 結果:[[0. 0.] [0. 0.] [0. 0.]]# 創建一個復雜的多維數組
n = np.zeros((2,3,4))
print(n)
# 結果:[[[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]]
輸出:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0. 0.][0. 0.][0. 0.]]
[[[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.]][[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.]]]
np.ones()
np.ones() 是 NumPy 庫中的一個函數,用于創建一個全為1的數組。該函數的主要參數是形狀,可以接受的形式有:一個整數,一個元組,或者一個表示形狀的數組。
函數解析
與np.zeros()函數類似
np.ones(shape)shape:一個整數或一個元組,指定要創建的數組的形狀。例如,np.ones(3) 會創建一個長度為3的全1向量,np.ones((2,3)) 會創建一個2行3列的全1矩陣。
函數返回的是一個填充了1的數組。
運行示例
import numpy as np# 創建一個長度為10的全1向量
v = np.ones(10)
print(v)
# 結果:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]# 創建一個3行2列的全1矩陣
m = np.ones((3,2))
print(m)
# 結果:[[1. 1.] [1. 1.] [1. 1.]]# 創建一個復雜的多維數組
n = np.ones((2,3,4))
print(n)
# 結果:[[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] [[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]]]
輸出:
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[[1. 1.][1. 1.][1. 1.]]
[[[1. 1. 1. 1.][1. 1. 1. 1.][1. 1. 1. 1.]][[1. 1. 1. 1.][1. 1. 1. 1.][1. 1. 1. 1.]]]
np.concatenate()
np.concatenate() 是 NumPy 庫中的一個函數,用于將兩個或更多的數組連接在一起。這個函數接受一個元組作為輸入,該元組中的每個元素都是一個要連接的數組。
函數解析
np.concatenate((a1, a2, ...), axis=0)a1, a2, ...:一個或多個要連接的數組。
axis:連接操作沿著哪個軸進行。如果 axis=0,那么數組將會在第一個軸上進行連接,這是默認值。如果 axis=1,那么數組將會在第二個軸上進行連接,以此類推。注意,axis 參數必須是整數。函數返回一個新的數組,該數組包含所有輸入數組在指定軸上的連接。
運行示例
import numpy as np# 創建兩個一維數組
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
#按行拼接
# 在第一個軸(默認)上連接這兩個數組
c = np.concatenate((a, b))
print(c)print("*************")
#按列拼接
# 創建兩個二維數組
a2 = np.array([[1, 2], [3, 4]])
b2 = np.array([[5, 6], [7, 8]])
# 按列拼接這兩個數組
c2 = np.concatenate((a2, b2), axis=1)
print(c2)
輸出:
[1 2 3 4 5 6]
*************
[[1 2 5 6][3 4 7 8]]
np.random.beta()
np.random.beta() 是 NumPy 庫中的一個函數,用于生成服從 Beta 分布的隨機數。Beta 分布是一種連續概率分布,通常用于描述在一定范圍內介于兩個值之間的隨機變量。
函數解析
函數:np.random.beta(a, b)a:代表 Alpha 分布的參數,也稱作形狀參數1。
b:代表 Beta 分布的參數,也稱作形狀參數2。返回值:
從 Beta 分布中抽取的隨機樣本。
運行示例
import numpy as np
import matplotlib.pyplot as plt# 設置隨機種子以確保結果可復現
np.random.seed(0)# 設置參數 a 和 b
a = 2.0
b = 5.0# 生成服從 Beta 分布的隨機數
samples = np.random.beta(a, b, 1000)# 使用 matplotlib 繪制 Beta 分布圖
plt.hist(samples, bins=30, density=True, alpha=0.6, color='g')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.title('Beta Distribution')
plt.show()

在上面的示例中,我們設置了 a=2.0 和 b=5.0 作為 Beta 分布的參數,生成了 1000 個服從該分布的隨機數,并使用 Matplotlib 繪制了它們的直方圖。
np.maximum()
np.maximum() 是 NumPy 庫中的一個函數,用于比較兩個或更多個數組元素,并返回每個元素的最大值。
函數解析
函數原型:
np.maximum(x1, x2, *args)參數:
x1, x2, *args:要進行比較的數值或數組。可以輸入任意數量的參數。返回值:
返回一個相同的形狀和類型與輸入參數的數組,其中每個元素都是輸入參數在該位置上的最大值。
運行示例
import numpy as np# 對于兩個數值
print(np.maximum(3, 4)) # 對于numpy數組
arr1 = np.array([1, 2, 3])
arr2 = np.array([3, 2, 1])print(np.maximum(arr1, arr2))
輸出:
4
[3 2 3]
在上面的示例中,我們看到 np.maximum() 函數可以用于兩個數值或兩個numpy數組。對于兩個數值,它返回較大的那個數值。對于numpy數組,它在每個位置上比較兩個數組的元素,并返回一個新數組,其中每個元素都是輸入數組在該位置上的最大值。
np.maximum.accumulate()
np.maximum.accumulate 是 NumPy 庫中的一個函數,它用于計算輸入數組中元素的累積最大值。這個函數接受一個輸入數組,然后返回一個累積最大值數組。
函數解析
函數原型為:numpy.maximum.accumulate(array)
其中 array 是輸入的數組。
運行示例
例子1
import numpy as nparr = np.array([1, 2, 3, 4, 5])
result = np.maximum.accumulate(arr)
print(result)
輸出結果:
[1 2 3 4 5]
這個例子中,輸入數組 [1, 2, 3, 4, 5] 的累積最大值數組仍然是 [1, 2, 3, 4, 5],因為每個元素本身都是它之前的最大值。
例子2
import numpy as nparr = np.array([5, 3, 8, 9, 6])
result = np.maximum.accumulate(arr)
print(result)
輸出:
[5 5 8 9 9]
np.minimum()
該函數與np.maximum()原理類似,是 NumPy 庫中的一個函數,用于比較兩個或更多個數組元素,并返回每個元素的最小值。
函數解析
函數原型:
np.minimum(x1, x2, *args)參數:
x1, x2, *args:要進行比較的數值或數組。可以輸入任意數量的參數。返回值:
返回一個相同的形狀和類型與輸入參數的數組,其中每個元素都是輸入參數在該位置上的最小值。
運行示例
import numpy as np# 對于兩個數值
print(np.minimum(3, 4)) # 對于numpy數組
arr1 = np.array([1, 2, 3])
arr2 = np.array([3, 2, 1])
print(np.minimum(arr1, arr2))
輸出:
3
[1 2 1]
在上面的示例中,我們看到 np.minimum() 函數可以用于兩個數值或兩個numpy數組。對于兩個數值,它返回較小的那個數值。對于numpy數組,它在每個位置上比較兩個數組的元素,并返回一個新數組,其中每個元素都是輸入數組在該位置上的最小值。
np.full()
np.full() 是 NumPy 庫中的一個函數,用于創建一個具有指定形狀和填充值的數組。
函數解析
函數原型:
np.full(shape, fill_value, dtype=None)參數:
shape:一個表示數組形狀的元組或整數。例如,(3, 4) 表示一個 3 行 4 列的二維數組。
fill_value:要填充在數組中的值。可以是任何 NumPy 數據類型。
dtype:可選參數,表示數組的數據類型。如果未指定,則默認為 None,即根據 fill_value 的類型進行推斷。返回值:
返回一個具有指定形狀和填充值的 NumPy 數組。
運行示例
import numpy as np# 創建一個形狀為 (3, 4) 的二維數組,填充值為 0
arr = np.full((3, 4), 0)
print(arr)# 創建一個形狀為 (2, 3) 的二維數組,填充值為 1.5,數據類型為 float
arr = np.full((2, 3), 1.5, dtype=float)
print(arr)輸出:
[[0 0 0 0][0 0 0 0][0 0 0 0]]
[[1.5 1.5 1.5][1.5 1.5 1.5]]
在上面的示例中,我們看到 np.full() 函數可以用于創建一個具有指定形狀和填充值的數組。第一個示例中,我們創建了一個形狀為 (3, 4) 的二維數組,并將所有元素填充為 0。第二個示例中,我們創建了一個形狀為 (2, 3) 的二維數組,并將所有元素填充為 1.5,并指定了數據類型為 float。
np.ascontiguousarray()
np.ascontiguousarray() 是 NumPy 庫中的一個函數,用于將輸入的數組重新構造為連續的內存塊。這個函數在處理需要連續內存的函數(如 np.dot() 或 np.fft.fft2())時非常有用。
函數解析
函數原型:
np.ascontiguousarray(a, dtype=None)參數:
a:輸入數組。可以是任何形狀和類型的數組。
dtype:可選參數,表示返回數組的數據類型。如果未指定,則默認為 None,即使用與輸入數組相同的類型。返回值:
返回一個連續的內存塊表示的數組,與輸入數組 a 具有相同的形狀和值。
運行示例
import numpy as np# 創建一個形狀為 (3, 4) 的二維數組,填充值為 0
arr = np.zeros((3, 4))
print("Original array:")
print(arr)# 使用 np.ascontiguousarray() 重構數組
arr_contiguous = np.ascontiguousarray(arr)
print("Reconstructed array:")
print(arr_contiguous)輸出:
Original array:
[[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.]]
Reconstructed array:
[[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.]]
在上面的示例中,我們首先創建了一個形狀為 (3, 4) 的二維數組,并將所有元素填充為 0。然后,我們使用 np.ascontiguousarray() 函數將該數組重構為連續的內存塊表示。可以看到,返回的數組與原始數組具有相同的形狀和值。
np.random.seed()
np.random.seed() 是 NumPy 庫中的一個函數,用于設置隨機數生成器的種子。種子是一個整數或一個整數序列,用于控制隨機數生成器的行為,以確保生成的隨機數序列是可重復的。
函數解析
函數原型:
np.random.seed(seed)參數:
seed:可選參數,用于設置隨機數生成器的種子。可以是整數或一個整數序列。如果未指定,則默認為 None,此時隨機數生成器會生成一個隨機種子。返回值:
該函數沒有返回值。
運行示例
import numpy as np# 設置隨機數生成器的種子為 100
np.random.seed(100)# 生成一個隨機數
random_number = np.random.rand()
print("Random number:", random_number)# 設置隨機數生成器的種子為 None(默認)
np.random.seed()# 再次生成一個隨機數
random_number = np.random.rand()
print("Random number:", random_number)
輸出:
Random number: 0.5434049417909654
Random number: 0.7352229465659721
在上面的示例中,我們首先使用 np.random.seed(100) 設置隨機數生成器的種子為 100,并生成一個隨機數。然后,我們使用 np.random.seed() 將種子重置為默認值(None),并再次生成一個隨機數。可以看到,由于種子不同,生成的隨機數也不同。因此,通過設置種子,我們可以確保在多次運行程序時得到相同的隨機數序列。
np.stack()
np.stack() 是 NumPy 庫中的一個函數,用于將一個或多個數組沿著新的維度堆疊在一起。這個函數返回一個新數組,其中包含原始數組中的所有元素,但它們沿著新的維度排列。
函數解析
函數原型:
np.stack(arrays, axis=0)參數:
arrays:一個或多個數組,這些數組將被堆疊在一起。
axis:可選參數,表示沿著哪個維度進行堆疊。默認為 0,表示在第一個維度(行)上進行堆疊。返回值:
返回一個新的 NumPy 數組,其中包含原始數組中的所有元素,但它們沿著新的維度排列。
運行示例
import numpy as np# 創建兩個一維數組
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])# 使用 np.stack() 將它們堆疊在一起,得到一個二維數組
c = np.stack((a, b))
print("Stacked array:")
print(c)#按列堆疊
c1 = np.stack((a, b),axis=1)
print("Stacked array1:")
print(c1)
輸出:
Stacked array:
[[1 2 3][4 5 6]]
Stacked array1:
[[1 4][2 5][3 6]]
在上面的示例中,我們創建了兩個一維數組 a 和 b,然后使用 np.stack() 將它們堆疊在一起,得到一個二維數組 c。可以看到,c 是一個二維數組,其中包含了 a 和 b 中的所有元素,但它們沿著新的維度排列。
np.unique
np.unique 是 NumPy 庫中的一個函數,用于從數組中返回唯一值,并按升序排序。它返回一個包含唯一值的數組,以及一個包含這些唯一值在原數組中首次出現的索引的數組。
函數解析
函數原型:
np.unique(arr, return_index=False, return_inverse=False)參數:
arr:輸入數組,可以是多維數組。
return_index:可選參數,如果為 True,則除了返回唯一值之外,還返回這些唯一值在原數組中首次出現的索引。默認為 False。
return_inverse:可選參數,如果為 True,則除了返回唯一值之外,還返回一個索引數組,該數組可用于將唯一值數組重新構造為原始數組。默認為 False。返回值:
返回一個包含唯一值的數組,以及可選的索引數組或索引數組的組合(根據參數 return_index 和 return_inverse 的設置)。
運行示例
import numpy as np# 創建一個一維數組
arr = np.array([2, 5, 1, 2, 4, 3, 5])# 使用 np.unique() 找到唯一值并按升序排序
unique_values = np.unique(arr)
print("Unique values:", unique_values)# 使用 np.unique() 找到唯一值并按升序排序,并返回首次出現的索引
unique_values, indices = np.unique(arr, return_index=True)
print("Unique values:", unique_values)
print("Indices:", indices)# 使用 np.unique() 找到唯一值并按升序排序,并返回一個索引數組,用于重新構造原始數組
unique_values, inverse = np.unique(arr, return_inverse=True)
print("Unique values:", unique_values)
print("Inverse:", inverse)
輸出:
Unique values: [1 2 3 4 5]
Unique values: [1 2 3 4 5]
Indices: [2 0 5 4 1]
Unique values: [1 2 3 4 5]
Inverse: [1 4 0 1 3 2 4]
在上面的示例中,我們首先創建了一個包含重復值的一維數組 arr。然后使用 np.unique() 找到 arr 中的唯一值并按升序排序,將結果存儲在變量 unique_values 中。接下來,我們使用 return_index=True 和 return_inverse=True 參數來獲取更多信息。當 return_index=True 時,函數返回一個包含唯一值及其在原數組中首次出現的索引的元組。當 return_inverse=True 時,函數返回一個索引數組,該數組可用于將唯一值數組重新構造為原始數組(根據原數組中的值在排序中的位置,如原數組中第一個值2,在排序中是在第二個位置,則最后生成的索引則為1,即得到的新數組第一個值為1)。
np.zeros_like
np.zeros_like 是一個 NumPy 函數,它創建一個與給定數組形狀相同、元素值全為零的新數組。這個函數對于快速復制形狀并填充零非常有用。
函數解析
函數原型:
np.zeros_like(a, dtype=None, order='K', subok=False)參數解釋:
a: 輸入數組。函數將創建與這個數組形狀相同的新數組。
dtype: 數據類型,可選參數。如果未指定,則默認為 None,這意味著新數組的數據類型將與輸入數組相同。
order: 排序方式,可選參數。如果為 'K',則按照輸入數組的內存順序創建新數組。如果為 'C',則使用行優先方式創建數組。默認值為 'K'。
subok: 如果為 True,則允許創建子類的實例。默認值為 False。返回值:
返回一個新數組,其形狀與輸入數組相同,所有元素值都為零。
運行示例
import numpy as np# 創建一個形狀為 (3, 3) 的隨機數組
a = np.random.rand(3, 3)
print("Original array:", a)# 創建一個與 a 形狀相同、元素值全為零的新數組
b = np.zeros_like(a)
print("Zero array:", b)
輸出:
Original array:[[0.03055982 0.10393955 0.52521327][0.24149545 0.23694233 0.41798272][0.72414372 0.26958905 0.2894202 ]]
Zero array:[[0. 0. 0.][0. 0. 0.][0. 0. 0.]]
這段代碼將首先創建一個形狀為 (3, 3) 的隨機數組 a,然后使用 np.zeros_like 函數創建一個與 a 形狀相同、元素值全為零的新數組 b。
np.save ()
np.save() 是 NumPy 庫中的一個函數,用于將數組保存到 .npy 文件中。這種文件格式可以用于在之后重新加載數組。
函數解析
函數原型:
numpy.save(file, arr, allow_pickle=True, fix_imports=True, do_compression=False)參數:
file:要保存到的 .npy 文件的路徑。
arr:要保存的數組。
allow_pickle:布爾值,決定是否允許 pickling 數據。默認為 True。
fix_imports:布爾值,決定是否應該嘗試修復不兼容的導入。默認為 True。
do_compression:布爾值,決定是否應該對文件進行壓縮。默認為 False。
運行示例
import numpy as np# 創建一個數組
arr = np.array([[1, 2], [3, 4]])# 將數組保存到 .npy 文件
np.save('my_array.npy', arr)
同級別文件夾中生成了一個“my_array.npy”文件,內容為:
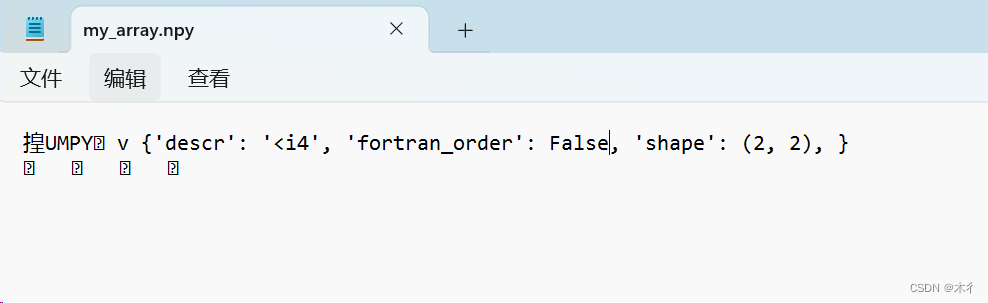
用記事本打開有些亂碼。
np.load ()
np.load 是 NumPy 庫中的一個函數,用于從 .npy 文件中加載數組。這種文件是由 np.save 函數創建的。np.load 函數非常適合用于恢復之前保存的數組,以便可以在之后的代碼中使用。
函數解析
函數原型:
numpy.load(file, mmap_mode=None, allow_pickle=True, fix_imports=True, encoding='ASCII')參數:
file:要加載的 .npy 文件的路徑。
mmap_mode:可選參數,用于指定內存映射模式的文件加載。默認值是 None。
allow_pickle:布爾值,決定是否允許加載 pickle 數據。默認為 True。
fix_imports:布爾值,決定是否應該嘗試修復不兼容的導入。默認為 True。
encoding:字符串,用于指定編碼方式。默認為 'ASCII'。
運行示例
import numpy as np# 創建一個數組
arr = np.array([[1, 2], [3, 4]])# 將數組保存到 .npy 文件
np.save('my_array.npy', arr)
# 加載 .npy 文件
loaded_arr = np.load('my_array.npy')# 打印加載的數組
print(loaded_arr)
輸出:
[[1 2][3 4]]
np.floor()
np.floor() 是 NumPy 庫中的一個函數,用于對輸入的數字或數組進行向下取整。具體來說,np.floor(x) 會返回不大于 x 的最大整數。如果 x 是一個數組,那么 np.floor(x) 會返回一個新的數組,其中每個元素都是 x 中相應元素的最大整數。
函數解析
函數原型為:
numpy.floor(x)
其中 x 是輸入的數字或數組。
運行示例
import numpy as np# 對單個數字進行向下取整
print(np.floor(3.14))
print("**********")
print(np.floor(3))
print("**********")# 對數組進行向下取整
print(np.floor([3.14, 2.71, 1.41]))
print("**********")
print(np.floor([[3.14, 2.71], [1.41, 1.69]]))
輸出:
3.0
**********
3.0
**********
[3. 2. 1.]
**********
[[3. 2.][1. 1.]]
np.ceil()
np.ceil() 是 NumPy 庫中的一個函數,用于對輸入的數字或數組進行向上取整。具體來說,np.ceil(x) 會返回大于等于 x 的最小整數。如果 x 是一個數組,那么 np.ceil(x) 會返回一個新的數組,其中每個元素都是 x 中相應元素的最小整數。
函數解析
函數原型為:
numpy.ceil(x)
其中 x 是輸入的數字或數組。
運行示例
import numpy as np
# 對單個數字進行向上取整
print(np.ceil(3.14))
print("**********")
print(np.ceil(3))
print("**********")# 對數組進行向上取整
print(np.ceil([3.14, 2.71, 1.41]))
print("**********")
print(np.ceil([[3.14, 2.71], [1.41, 1.69]]))
輸出:
4.0
**********
3.0
**********
[4. 3. 2.]
**********
[[4. 3.][2. 2.]]
np.flipud()
np.flipud() 是 NumPy 庫中的一個函數,用于沿著垂直軸翻轉數組。具體來說,np.flipud(a) 會返回一個新數組,其中原數組 a 的每一行都被翻轉。
函數解析
函數原型為:
numpy.flipud(a)
其中 a 是輸入的數組。
運行示例
import numpy as np# 創建一個 3x3 的二維數組
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("Original array:")
print(a)# 使用 np.flipud() 翻轉數組
b = np.flipud(a)
print("Flipped array:")
print(b)
輸出:
Original array:
[[1 2 3][4 5 6][7 8 9]]
Flipped array:
[[7 8 9][4 5 6][1 2 3]]
np.fliplr()
np.fliplr() 是 NumPy 庫中的一個函數,用于沿著水平軸翻轉數組。具體來說,np.fliplr(a) 會返回一個新數組,其中原數組 a 的每一列都被翻轉。
函數解析
函數原型為:
numpy.fliplr(a)
其中 a 是輸入的數組。
運行示例
import numpy as np# 創建一個 3x3 的二維數組
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("Original array:")
print(a)# 使用 np.fliplr() 翻轉數組
b = np.fliplr(a)
print("Flipped array:")
print(b)
輸出結果:
Original array:
[[1 2 3][4 5 6][7 8 9]]
Flipped array:
[[3 2 1][6 5 4][9 8 7]]
np.hstack()
np.hstack() 是 NumPy 庫中的一個函數,用于將兩個或更多的數組沿著水平軸(即列)連接起來。這個函數會沿著水平軸(即列)將輸入的數組堆疊起來。這意味著輸出的數組的列數將是輸入數組的列數之和,而行數將是輸入數組中最大行數的值。
函數解析
函數原型為:
numpy.hstack(tup)
其中 tup 是一個元組,包含了你想要堆疊的數組。
運行示例
一維數組
import numpy as np# 創建兩個一維數組
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])# 使用 np.hstack() 將它們堆疊起來
c = np.hstack((a, b))
print(c)
輸出:
[1 2 3 4 5 6]
二維數組
import numpy as np# 創建兩個二維數組
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])# 使用 np.hstack() 將它們堆疊起來
c = np.hstack((a, b))print(c)
輸出:
[[1 2 5 6][3 4 7 8]]
np.vstack()
在NumPy中,用于按行堆疊(即在水平方向上堆疊)的函數是np.vstack()。這個函數將兩個或更多的數組沿著垂直軸(即行)堆疊起來。
函數解析
數原型為:
numpy.vstack(tup)
其中tup是一個元組,包含了你想要堆疊的數組。
運行示例
import numpy as np# 創建兩個二維數組
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
# 使用 np.vstack() 將它們堆疊起來
c = np.vstack((a, b))
print("按行堆疊:")
print(c)
輸出:
按行堆疊:
[[1 2][3 4][5 6][7 8]]
np.bincount()
np.bincount()函數是NumPy庫中的一個函數,用于統計數組中每個元素出現的次數。
函數解析
函數原型為:
numpy.bincount(x[, minlength])
參數:
x:一個數組,其中包含要統計的元素。
minlength:可選參數,指定返回結果的長度。如果指定了此參數,那么當x的長度小于minlength時,將會用0補充結果。返回值:
這個函數會返回一個長度與x中不同元素個數相同的數組,其中每個元素表示相應元素在x中出現的次數。
運行示例
import numpy as np# 創建一個一維數組
arr = np.array([0, 1, 1, 2, 3, 3, 3, 2])# 使用 np.bincount() 統計每個元素出現的次數
counts = np.bincount(arr)print("元素出現的次數:")
print(counts)
輸出:
元素出現的次數:
[1 2 2 3]
np.argmax()
np.argmax() 是 NumPy 庫中的一個函數,它返回輸入數組中最大值的索引。這是一個非常實用的函數,特別是在處理多維數組時。
函數解析
函數原型為:
numpy.argmax(a, axis=None)參數:
a:輸入的數組。
axis:可選參數,表示沿著哪個軸進行操作。如果 axis 為 None,則函數會返回輸入數組中最大值的索引。如果指定了 axis,則函數會返回該軸上最大值的索引。例如,如果 axis 等于 1,函數會返回每一行中最大值的索引。
運行示例
一維數組
import numpy as np# 創建一個一維數組
arr = np.array([1, 3, 5, 2, 4])
# 使用 np.argmax() 找到最大值的索引
max_index = np.argmax(arr)print("最大值的索引:", max_index)
輸出:
最大值的索引: 2
二維數組(默認行為)
import numpy as np# 創建一個二維數組
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 使用 np.argmax() 找到最大值的索引(默認行為是沿著最后一維)
max_index = np.argmax(arr)print("最大值的索引:", max_index)
輸出:
最大值的索引: 8
二維數組(指定軸)
0是列,1是行
import numpy as np# 創建一個二維數組
arr = np.array([[1, 2, 3], [4, 5, 6], [2, 8, 9]])# 使用 np.argmax() 沿著第一維找到最大值的索引(axis=0)
max_index_axis0 = np.argmax(arr, axis=0)
print("沿著第一維最大值的索引:", max_index_axis0)# 使用 np.argmax() 沿著第二維找到最大值的索引(axis=1)
max_index_axis1 = np.argmax(arr, axis=1)
print("沿著第二維最大值的索引:", max_index_axis1)
輸出:
沿著第一維最大值的索引: [1 2 2]
沿著第二維最大值的索引: [2 2 2]
np.argmin()
np.argmin() 是 NumPy 庫中的一個函數,它返回輸入數組中最小元素的索引。該函數的行為會根據輸入數組的維度而變化。
函數解析
運行示例
一維數組
import numpy as np# 創建一個一維數組
arr = np.array([1, 3, 5, 2, 4])
# 使用 np.argmin() 找到最小值的索引
min_index = np.argmin(arr1)print("最大值的索引:", max_index)
輸出:
最小值的索引: 0
二維數組(默認行為)
import numpy as np
# 創建一個二維數組
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 使用 np.argmin() 找到最小值的索引(默認行為是沿著最后一維)
min_index = np.argmin(arr)print("最小值的索引:", min_index)
輸出:
最大值的索引: 0
二維數組(指定軸)
0是列,1是行
import numpy as np# 創建一個二維數組
arr2 = np.array([[3, 2, 1], [1, 5, 6], [7, 8, 9]])# 使用 np.argmin() 沿著第一維找到最小值的索引(axis=0)
min_index_axis0 = np.argmin(arr2, axis=0)
print("沿著第一維最小值的索引:", min_index_axis0)# 使用 np.argmin() 沿著第二維找到最小值的索引(axis=1)
min_index_axis1 = np.argmin(arr2, axis=1)
print("沿著第二維最小值的索引:", min_index_axis1)
輸出:
沿著第一維最小值的索引: [1 0 0]
沿著第二維最小值的索引: [2 0 0]
np.argsort()
np.argsort() 是 NumPy 庫中的一個函數,它返回輸入數組中元素的排序索引。這個函數非常有用,特別是在需要排序數組并獲取排序索引時。
函數解析
函數原型為:
numpy.argsort(a, kind='quicksort', axis=-1, order=None)參數:
a:輸入的數組。
kind:排序算法的類型。可以是 'quicksort'、'heapsort'、'stable' 等。默認是 'quicksort'。
axis:沿著哪個軸進行排序。默認是 -1,表示在最后一個軸上排序。
order:排序的順序。可以是 'ascending'(升序)或 'descending'(降序)。
這個函數返回一個整數數組,表示輸入數組中每個元素在排序后數組中的索引位置。這個數組可以用于重新構造排序后的數組,或者用于其他需要排序索引的操作。默認是升序
運行示例
一維數組排序索引
import numpy as np# 創建一個一維數組
arr = np.array([3, 1, 2])# 使用 np.argsort() 獲取排序索引
sort_index = np.argsort(arr)print("排序索引:", sort_index)
輸出:
排序索引: [1 2 0]
二維數組排序索引
import numpy as np# 創建一個二維數組
arr = np.array([[3, 1, 2], [5, 4, 7], [6, 8, 9]])# 使用 np.argsort() 沿著最后一維獲取排序索引
sort_index = np.argsort(arr, axis=-1)print("排序索引:", sort_index)
輸出:
排序索引: [[1 2 0][1 0 2][0 1 2]]
使用排序索引重新構造數組
import numpy as np# 創建一個二維數組
arr = np.array([[3, 1, 2], [5, 4, 7], [6, 8, 9]])# 使用 np.argsort() 沿著最后一維獲取排序索引
sort_index = np.argsort(arr, axis=-1)
print("重新構造的數組:", sort_index )# 使用排序索引重新構造數組
sorted_arr = arr[np.argsort(sort_index)]print("重新構造的數組:", sorted_arr)
輸出:
重新構造的數組: [[1 2 0][1 0 2][0 1 2]]
重新構造的數組: [[[6 8 9][3 1 2][5 4 7]][[5 4 7][3 1 2][6 8 9]][[3 1 2][5 4 7][6 8 9]]]
np.set_printoptions()
np.set_printoptions 是 NumPy 庫中的一個函數,它用于設置打印數組時的默認選項。這可以幫助你控制 NumPy 打印輸出的格式和精度。
函數解析
函數原型:
numpy.set_printoptions(precision, threshold, edgeitems, linewidth, max_line_width)參數:
precision:控制浮點數的精度,即小數點后的位數。默認值是 None,表示使用默認精度。
threshold:控制數組元素的總數,當元素數量大于該閾值時,會使用省略號表示。默認值是 None,表示不使用省略號。
edgeitems:控制數組邊緣的元素數量,當數組邊緣的元素數量小于該值時,會在邊緣添加省略號。默認值是 3。
linewidth:控制每行的最大字符數,超過該值的元素會被分割到下一行。默認值是 75。
max_line_width:控制每行的最大行數,超過該值的元素會被分割到多行。默認值是 None,表示不進行分割。返回值:
該函數沒有返回值。
運行示例
設置浮點數的精度
import numpy as npnp.set_printoptions(precision=4)
print(np.array([1.23456789]))
輸出:
[1.2346]
設置數組元素的閾值
當元素個數大于10時,使用省略號。
import numpy as np
#控制元素個數
np.set_printoptions(threshold=10)
print(np.arange(20))
[ 0 1 2 ... 17 18 19]
設置每行的最大字符數
最大字符數設置為10
import numpy as npnp.set_printoptions(linewidth=10)
print(np.array([1, 2, 3, 4, 5]))
輸出:
[1 2 3 45]
np.loadtxt()
np.loadtxt 是 NumPy 庫中的一個函數,用于從文本文件中加載數據并返回一個 NumPy 數組。
函數解析
函數原型:
numpy.loadtxt(filename, dtype=float, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)參數:
filename:要加載數據的文件名,可以是字符串類型。
dtype:返回的數組的數據類型,默認為浮點型(float)。也可以傳入其他 NumPy 數據類型,如 int、str 等。
delimiter:指定分隔符,用于將文本文件中的數據拆分為不同列。默認為 None,表示根據輸入文件的數據類型進行自動推斷。常見的分隔符包括逗號(',')、制表符('\t')等。
converters:一個字典,用于指定某些列數據的轉換函數。字典的鍵為列索引,值為轉換函數。例如,設置 converters={0: lambda x: int(x)} 將第一列數據轉換為整數類型。
skiprows:要跳過的行數,用于忽略文件開頭的注釋或無關數據。默認為 0,表示不跳過任何行。
usecols:一個切片對象,用于指定要加載的列范圍。例如,設置 usecols=(0, 2, 4) 將只加載第一、第三和第五列數據。
unpack:布爾值,用于指示是否將返回的數組解包為單獨的變量。默認為 False,表示不解包。
ndmin:指定返回的數組的維度最小值。默認為 0,表示根據數據自動推斷數組維度。
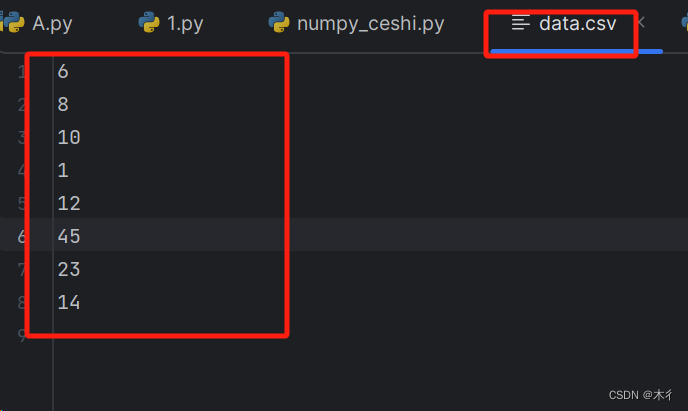
data.csv文件內容為:
運行示例
用.號分隔數據的文本文件
import numpy as np
data = np.loadtxt('data.csv', delimiter='.')
print(data)
輸出:
[ 6. 8. 10. 1. 12. 45. 23. 14.]
加載包含注釋的文本文件,并跳過前三行
import numpy as npdata = np.loadtxt('data.csv', skiprows=3)
print(data)
輸出:
[ 1. 12. 45. 23. 14.]
np.linspace()
np.linspace 是 NumPy 庫中的一個函數,用于在指定的間隔內生成等間距的數值序列。它返回一個 NumPy 數組,其中包含指定數量的數字,這些數字沿著標準數軸均勻分布。
函數解析
函數原型:
np.linspace(start, stop, num, endpoint=True, retstep=False, dtype=None)參數說明:
start:序列的起始值。默認值為 0。
stop:序列的終止值。這是唯一必需的參數。
num:生成的數字序列中元素的數量。默認值為 50。
endpoint:如果為 True,stop 值將被包含在結果中。默認值為 True。
retstep:如果為 True,返回 (num, start, stop, endpoint) 的元組。默認值為 False。
運行示例
import numpy as nparr = np.linspace(0, 1, 10)
print(arr)arr1 = np.linspace(0, 1, 10, endpoint=True)
print(arr1) arr2 = np.linspace(2, 10, num=5, endpoint=True)
print(arr2)
輸出:
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.555555560.66666667 0.77777778 0.88888889 1. ]
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.555555560.66666667 0.77777778 0.88888889 1. ]
[ 2. 4. 6. 8. 10.]
np.copy()
np.copy 是 NumPy 庫中的一個函數,用于創建指定數組的副本。這個函數返回的是輸入數組的一個拷貝,而不是對原始數組的引用。這意味著對返回的拷貝進行的任何更改不會影響到原始數組。
函數解析
函數原型:
numpy.copy(arr)參數:
arr:要復制的數組。返回值:
返回輸入數組的副本。返回的數組是原始數組的一個全新副本,對它的更改不會影響原始數組。
運行示例
import numpy as np# 創建一個數組
arr = np.array([1, 2, 3, 4, 5])
print("原始數組:")
print(arr)# 使用 np.copy 復制數組
arr_copy = np.copy(arr)
print("復制的數組:")
print(arr_copy)# 修改復制的數組
arr_copy[0] = 100
print("修改后的復制數組:")
print(arr_copy)# 原始數組未受影響
print("原始數組:")
print(arr)
輸出:
原始數組:
[1 2 3 4 5]
復制的數組:
[1 2 3 4 5]
修改后的復制數組:
[100 2 3 4 5]
原始數組:
[1 2 3 4 5]
np.interp()
np.interp 是 NumPy 庫中的一個函數,用于執行一維線性插值。它可以在已知的數據點之間進行插值,生成新的數據點。
函數解析
函數原型:
numpy.interp(x, xp, fp)參數:
x:要進行插值的數據點,可以是一個一維數組或一個單獨的數值。
xp:已知的數據點,是一個一維數組,表示 x 的值。
fp:已知的數據點的函數值,是一個一維數組,與 xp 具有相同的長度,表示對應于每個 x 的函數值。返回值:
返回插值后得到的新數據點的函數值。
np.interp通過獲取xp與fp之間的對應線性函數關系,估計x處的對應值來進行線性插值。
運行示例
import numpy as np# 已知數據點
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 5, 7, 11])# 進行插值,得到新的數據點對應的函數值
x_new = np.array([1.5, 2.5, 3.5])
y_new = np.interp(x_new, x, y)print(y_new) # 輸出 [2.5 4. 6. ]
輸出:
[2.5 4. 6. ]
np.ndarray()
np.ndarray 是 NumPy 庫中的一個類,用于創建和操作多維數組對象。np.ndarray 可以包含不同類型的數據,例如整數、浮點數、字符串等。
函數解析
class numpy.ndarray:def __init__(self, shape, dtype=float, buffer=None, offset=0, strides=None, order=None):# 構造函數,用于創建 ndarray 對象self.shape = shape # 數組的形狀self.dtype = dtype # 數組的數據類型self.buffer = buffer # 數組數據的內存塊self.offset = offset # 數組數據在內存塊中的偏移量self.strides = strides # 數組每個維度在內存中的跨度self.order = order # 數組數據的存儲方式(默認值:None)
常用參數:
shape:返回數組的形狀。例如:arr.shape = (3,4) 表示數組是一個 3 行 4 列的二維數組。
dtype:返回數組的數據類型。例如:arr.dtype = int 表示數組中的元素都是整數類型。運行示例
import numpy as np# 創建一個 2x3x4 的三維數組
data = np.ndarray((2, 3, 4), dtype=int)# 為數組元素賦值
for i in range(data.shape[0]):for j in range(data.shape[1]):for k in range(data.shape[2]):data[i, j, k] = i + j + kprint("三維數組:")
print(data)
輸出:
[[[0 1 2 3][1 2 3 4][2 3 4 5]][[1 2 3 4][2 3 4 5][3 4 5 6]]]
np.fromfile()
np.fromfile() 是 NumPy 庫中的一個函數,它從一個二進制文件中讀取數據并返回一個數組。這個函數特別適合處理大型數據集,因為它可以直接從文件中讀取數據,而不需要將整個文件加載到內存中。
函數解析
函數原型:
函數原型:
numpy.fromfile(file, dtype=float, count=-1, sep='')參數解釋:
file:需要讀取的二進制文件。
dtype:期望的數據類型。例如,np.int32、np.float64 等。默認值是 float。
count:要讀取的元素數量。如果設置為 -1,將讀取所有剩余的元素。默認值是 -1。
sep:元素之間的分隔符。在 NumPy 中,默認分隔符是 None,表示根據數據類型確定分隔符。
運行示例
import numpy as np# 創建一個包含數據的二進制文件
data = np.array([1, 2, 3, 4, 5], dtype=np.int32).tofile('data.bin')# 從文件中讀取數據并存儲為 NumPy 數組
arr = np.fromfile('data.bin', dtype=np.int32)
print(arr) arr1 = np.fromfile('data.bin', dtype=np.int32, count=3)
print(arr1)
輸出:
[1 2 3 4 5]
[1 2 3]
np.convolve()
np.convolve 是 NumPy 庫中的一個函數,用于執行卷積運算。卷積是一種在信號處理、圖像處理和機器學習等領域廣泛應用的運算。
函數解析
函數原型:
numpy.convolve(in1, in2, mode='full', axis=-1)參數:
in1:第一個輸入數組。
in2:第二個輸入數組。
mode:卷積的模式,有四種模式可選:'full'、'valid'、'same'、'linear'。默認為 'full'。
'full':輸出是完整的重疊區域。
'valid':輸出僅包含完全重疊的點。
'same':輸出是輸入的長度相同的中央部分。
'linear':使用線性濾波器,輸出是輸入的長度相同的中央部分,但邊緣效應被線性濾波器處理。
axis:進行卷積操作的軸。默認為 -1,表示在最后一個軸上操作。
運行示例
卷積運算
import numpy as npvector1 = np.array([1, 2, 3])
vector2 = np.array([4, 5, 6])
convolution = np.convolve(vector1, vector2, mode='full')
print(convolution)
輸出:
[ 4 13 28 27 18]
np.trapz()
np.trapz 是 NumPy 庫中的一個函數,用于計算梯形積分。這個函數在數值積分中非常有用,特別是在那些不能輕易找到解析解的問題中。
梯形法是一種數值積分方法,其基本思想是在被積函數曲線的下方“畫梯形”,然后用梯形的面積近似代替所求的積分。
函數解析
可以這樣形象地理解 np.trapz:想象你在平面上鋪設了多個“梯形”小塊(由函數在特定點的取值決定),這些梯形的寬度都是 dx ,高度就是函數的取值。然后,把這些梯形的面積加起來,就得到了這個函數在該區間上的積分值。
函數原型:
numpy.trapz(x, y=None, dx=1.0)參數說明:
x:一維的數組或者列表,作為積分的下限。
y:一維的數組或者列表,作為積分的上限。如果未提供,默認為 None,此時函數會返回從 x[0] 到 x[-1] 的積分。
dx:間距的長度,如果 x 是等間隔的,那么 dx 應該被設定為 1.0。默認值為 1.0。返回值:
返回一個浮點數,表示所求的梯形積分值。
運行示例
import numpy as np
x = np.linspace(0, 3, 100) # 創建一個等間隔的數組,作為積分的下限和上限
y = x**2 # 定義函數 f(x) = x^2 在每個點的取值integral = np.trapz(y, x) # 計算積分
print(f"The integral of f(x) = x^2 from 0 to 3 is: {integral}") # 輸出積分的結果
輸出:
The integral of f(x) = x^2 from 0 to 3 is: 9.000459136822775
上述示例中,我們使用了 np.linspace(0, 3, 100) 來生成等間隔的數組 x,這只是為了方便我們手動構造一個具體的函數。在實際應用中,你可能會直接使用函數在其他點的取值作為 y。
np.where()
np.where() 是一個非常有用的函數,它返回輸入數組中滿足給定條件的元素的索引。這個函數在很多情況下都非常有用,比如在數據分析和處理中進行條件判斷。
函數解析
函數原型:
numpy.where(condition[, x, y])參數說明:
condition:當只使用一個條件時,它是一個用于測試每個元素的布爾(真/假)數組。當使用兩個條件時,它是一個(n,2)數組,每行包含一個布爾測試。
x, y:當只使用一個條件時,x 和 y 是用于替換滿足和不滿足條件的元素的數組。當使用兩個條件時,x 和 y 是用于替換每行的元素的數組。返回值:
當只使用一個條件時,返回一個包含滿足條件的元素的數組。當使用兩個條件時,返回一個包含替換每行元素的數組。
運行示例
單條件
import numpy as np# 創建一個隨機數組
arr = np.random.randint(0, 10, size=(5,))
print("Original array:", arr)# 使用np.where()找出所有大于5的元素,并用9替換它們
new_arr = np.where(arr > 5, 9, arr)
print("New array with replaced values:", new_arr)
輸出:
Original array: [2 2 6 1 9]
New array with replaced values: [2 2 9 1 9]
多條件
import numpy as np# 創建一個隨機數組
arr = np.random.randint(0, 10, size=(5,2))
print("Original array:", arr)# 使用np.where()找出第一列大于5的元素,并用9替換它們;同時找出第二列小于6的元素,并用11替換它們
new_arr = np.where(np.c_[arr[:,0] > 5, arr[:,1] < 6], [9, 11], arr)
print("New array with replaced values:", new_arr)
輸出:
Original array: [[8 3][3 6][3 1][5 0][2 3]]
New array with replaced values: [[ 9 11][ 3 6][ 3 11][ 5 11][ 2 11]]
np.sum()
np.sum() 是 NumPy 庫中的一個函數,用于計算數組中元素的總和。它接受一個或多個數組作為輸入,并返回這些數組元素的和。
函數解析
函數原型:
numpy.sum(array, axis=None, dtype=None, out=None, keepdims=False, initial=0, where=True)參數說明:
array:輸入的數組。可以是標量(在調用 np.sum() 時將計算其和),也可以是 NumPy 數組。
axis:可選參數,表示沿哪個軸進行求和。默認值是 None,表示對整個數組進行求和。如果輸入的是一個標量,則該參數無效。
dtype:可選參數,表示返回的數組的數據類型。默認值是 None,表示使用與輸入數組相同的數據類型。
out:可選參數,表示輸出的數組。如果提供了一個 out 參數,則求和操作將在這個數組中進行,而不是創建一個新的數組。
keepdims:可選參數,表示是否保持被求和的維度。如果為 True,則返回的數組將保留被求和的維度,這些維度的長度為 1。
initial:可選參數,表示在求和操作中添加到每個元素之前的初始值。默認值是 0。
where:可選參數,表示一個布爾掩碼,決定哪些元素應該被包括在求和操作中。默認值是 True,表示對所有元素進行求和。返回值:
返回一個 NumPy 數組,其中包含輸入數組的元素的和。如果 axis 參數為 None,則返回一個標量。
運行示例
import numpy as np#對一個 NumPy 數組進行求和:
arr = np.array([1, 2, 3, 4, 5])
result = np.sum(arr)
print(result) #對多個 NumPy 數組進行求和:
import numpy as nparr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
result1 = np.sum([arr1, arr2])
print(result1) #沿著某個軸進行求和:
import numpy as nparr3 = np.array([[1, 2], [3, 4]])
result3 = np.sum(arr3, axis=0)
print(result3)
輸出:
15
21
[4 6]
np.nan()
函數解析
np.nan 是 NumPy 庫中的一個特殊值,表示“非數字”(Not a Number)。它是 NaN 的縮寫,是一個IEEE標準,用于表示結果無法定義或無法表示的數學運算。
使用方法:
創建 NaN 值的常用方法就是調用 np.nan 函數。
運行示例
import numpy as np# 使用 np.nan 創建 NaN 數組
nan_array = np.array([1, 2, np.nan, 4])
print(nan_array)
輸出:
[ 1. 2. nan 4.]
np.log()
np.log() 是 NumPy 庫中的一個函數,用于計算自然對數(以 e 為底)。
函數解析
函數原型:
numpy.log(x)參數說明:
x:一個數值或 NumPy 數組,表示要計算其自然對數的值。返回值:
返回輸入值的自然對數。
運行示例
import numpy as np# 計算數字 10 的自然對數
result = np.log(10)
print(result) array = np.array([-1, 10, 100, 1000])
# 計算這個數組中每個數字的自然對數
result1 = np.log(array)print(result1)
輸出:
2.302585092994046
[ nan 2.30258509 4.60517019 6.90775528]
C:\Users\SW\Desktop\suishoulian\csdn\numpy_ceshi.py:776: RuntimeWarning: invalid value encountered in logresult1 = np.log(array)在這個示例中,如果輸入數組中的值是負數或零,那么返回的將是 NaN(因為負數和零的自然對數是未定義的)。
np.linalg.lstsq()
np.linalg.lstsq() 是 NumPy 庫中的一個函數,用于執行最小二乘法擬合線性方程組。它可以找到一個向量 b,使得對于給定的矩陣 A,np.dot(A, b) 盡可能接近 y。
函數解析
函數原型:
numpy.linalg.lstsq(A, y, rcond=None, overwrite_A=False, overwrite_b=False, check_finite=True, det_A=None, normed=True)參數說明:
A:一個 n×m 的矩陣,其中 n 是線性方程組的未知數的數量,m 是方程的數量。
y:一個 n×1 的向量,表示等式右邊的值。
rcond:一個可選參數,用于指定奇異值閾值。如果指定了該參數,那么當使用奇異值分解時,奇異值小于 rcond * sigma_max 的值將被截斷為零,其中 sigma_max 是最大的奇異值。
overwrite_A:一個布爾值,表示是否覆蓋輸入的矩陣 A。
overwrite_b:一個布爾值,表示是否覆蓋輸入的向量 y。
check_finite:一個布爾值,表示是否檢查矩陣 A 和向量 y 中的元素是否為有限值。
det_A:一個可選參數,表示矩陣 A 的行列式值的估計。
normed:一個布爾值,表示是否對解向量 b 進行歸一化。返回值:
返回一個元組 (x, residuals, rank, s = singular_values, rcond),其中:
x:一個 m×1 的向量,表示最小二乘解。
residuals:一個 1-D 數組,表示殘差平方和。
rank:矩陣 A 的秩。
s:一個 1-D 數組,表示 A 的奇異值。
rcond:如果指定了該參數,那么就是使用的奇異值的倒數閾值;否則為 None。
運行示例
import numpy as np# 定義一個矩陣 A 和一個向量 y
A = np.array([[3, 2], [1, 7]])
y = np.array([9, 1])# 使用 np.linalg.lstsq() 求解最小二乘解
x, residuals, rank, s = np.linalg.lstsq(A, y)# 輸出結果
print("最小二乘解:", x)
輸出:
最小二乘解: [ 3.21052632 -0.31578947]
這個示例中,我們有一個 2×2 的矩陣 A 和一個 2×1 的向量 y。我們使用 np.linalg.lstsq() 函數來找到一個向量 x,使得 np.dot(A, x) 最接近 y。輸出結果將顯示找到的最小二乘解
np.empty()
np.empty() 是 NumPy 庫中的一個函數,用于創建一個指定形狀和數據類型的空數組。這個函數不初始化數組元素,因此返回的數組中元素的值是不確定的。
函數解析
函數原型:
numpy.empty(shape, dtype=float, order='C')參數說明:
shape:一個表示數組形狀的元組。例如,(3, 4) 表示一個 3 行 4 列的二維數組。
dtype:一個可選參數,表示創建的數組的數據類型。默認值是 float。其他常用的數據類型包括 int、str 等。
order:一個可選參數,表示數組在內存中的存儲方式。默認值是 'C',表示按行優先存儲(類似于 C 語言中的數組)。如果指定為 'F',則表示按列優先存儲(類似于 Fortran 語言中的數組)。返回值:
np.empty() 返回一個新的數組對象,該對象是一個指定形狀和數據類型的空數組。返回的數組中的元素值不確定,因此需要在使用之前進行初始化。
運行示例
import numpy as np# 創建一個形狀為 (3, 4) 的空數組,數據類型為 float
empty_array = np.empty((3, 4), dtype=float)
print(empty_array)
輸出:
[[6.23042070e-307 7.56587584e-307 1.37961302e-306 6.23053614e-307][1.69121639e-306 1.05701279e-307 1.60220393e-306 6.23037996e-307][6.23053954e-307 9.34603679e-307 2.22522596e-306 2.56765117e-312]]
結束語
因搜集來源有限,寫的可能不全,歡迎大家評論補充,后期不定時更新。
)

)




![[原創]C++98升級到C++20的復習旅途-個人感覺std::string_literals這個東西實現的不太人性化.](http://pic.xiahunao.cn/[原創]C++98升級到C++20的復習旅途-個人感覺std::string_literals這個東西實現的不太人性化.)








)


