文章目錄
- 一、視圖(View)
- 1、概念
- 2、基本操作
- 1)創建視圖
- 2)修改視圖
- 3)刪除視圖
- 4)使用視圖
- 3、使用場景
- 4、實踐
- 二、函數(Function)
- 1、概念
- 2、基本操作
- 1)創建函數
- 2)使用函數
- 3、使用場景
- 4、實踐
- 三、存儲過程(Stored Procedure)
- 1、概念
- 2、基本操作
- 1)創建存儲過程
- 2)使用存儲過程
- 3、使用場景
- 4、實踐
- 四、觸發器(Trigger)
- 1、概念
- 2、基本操作
- 1) 創建觸發器
- 2) 使用觸發器
- 3、使用場景
- 4、實踐
- 五、物化視圖(Materialized View)
- 1、概念
- 2、使用場景
- 3、實踐
- 六、總結
一、視圖(View)
1、概念
視圖是數據庫中的一個虛擬表,它是基于一個或多個表的查詢結果構建的。視圖可以被視為存儲在數據庫中的預定義查詢。通過創建視圖,您可以簡化復雜的查詢,隱藏底層表的細節,并提供更簡潔和易于理解的數據訪問方式。視圖可以像表一樣使用,可以查詢、插入、更新和刪除視圖中的數據,但實際上它們并不存儲任何數據。
2、基本操作
1)創建視圖
語法如下:
CREATE[OR REPLACE][ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}][DEFINER = user][SQL SECURITY { DEFINER | INVOKER }]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]
參數說明:
- CREATE: 這是創建視圖的關鍵字。
- OR REPLACE: 這是一個可選的選項,表示如果已經存在同名的視圖,則替換它。
- ALGORITHM: 這也是一個可選的選項,用于指定用于視圖的算法。它可以取UNDEFINED、MERGE或TEMPTABLE這三種值。UNDEFINED表示由數據庫選擇算法,這是默認值。MERGE表示將使用與普通查詢相同的算法。TEMPTABLE表示將創建一個臨時表,并將查詢結果存儲在該臨時表中。
- DEFINER: 這是可選的選項,用于指定定義視圖的用戶。通常,這個值應該是創建視圖的用戶的用戶名。
- SQL SECURITY: 這也是可選的選項,用于指定視圖的安全性選項。它可以是DEFINER或INVOKER,表示視圖的定義者和調用者的安全級別。
- VIEW: 這是創建視圖的關鍵詞。view_name: 這是要創建的視圖的名稱。column_list: 可選的參數,用于指定視圖的列名。如果省略,則視圖的列名將與查詢語句的輸出列名相同。
- AS select_statement: 這是指定視圖內容的語句。視圖的內容是通過一個或多個SELECT語句定義的。
- WITH [CASCADED | LOCAL] CHECK OPTION: 可選的選項,用于指定對視圖進行插入、更新和刪除操作的約束。如果選擇CASCADED,則將對視圖的所有后續查詢都強制執行該約束。如果選擇LOCAL,則只對直接查詢該視圖的用戶強制執行該約束。如果省略,則默認為CASCADED。
2)修改視圖
語法如下:
ALTER[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}][DEFINER = user][SQL SECURITY { DEFINER | INVOKER }]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]
參數和創建視圖差不多,只不過創建是關鍵字CREATE,修改是ALTER
3)刪除視圖
語法如下:
DROP VIEW [IF EXISTS]view_name [, view_name] ...[RESTRICT | CASCADE]
參數說明:
- DROP VIEW: 這是刪除視圖的關鍵字。
- IF EXISTS: 這是一個可選的參數,用于指定在嘗試刪除視圖之前是否檢查視圖是否存在。如果存在,則執行刪除操作,否則忽略該操作。
- view_name: 這是要刪除的視圖的名稱。您可以指定一個或多個視圖名稱,用逗號分隔。
- RESTRICT: 這是一個可選的參數,用于指定如果存在依賴于該視圖的任何對象(例如其他視圖或存儲過程),則不允許刪除該視圖。如果未指定該參數,并且存在依賴于該視圖的對象,則刪除操作將被禁止。
- CASCADE: 這是一個可選的參數,用于指定刪除視圖以及所有依賴于該視圖的對象。如果未指定該參數,并且存在依賴于該視圖的對象,則刪除操作將被禁止。
例子:DROP VIEW IF EXISTS view1, view2 CASCADE;
這個示例將嘗試刪除名為view1和view2的兩個視圖。如果這兩個視圖存在,則它們將被刪除,并且所有依賴于它們的對象也將被刪除(因為指定了CASCADE參數)。如果這兩個視圖不存在,則該命令將被忽略(因為指定了IF EXISTS參數)。
4)使用視圖
使用視圖時,可以像使用表一樣進行查詢操作,例如:SELECT * FROM my_view;
3、使用場景
-
簡化復雜查詢:視圖可以封裝復雜的查詢邏輯,簡化應用程序中的查詢操作,提高查詢的可讀性和復用性。
-
數據安全性和權限控制:通過視圖可以隱藏底層表的結構和數據,只向用戶暴露必要的信息,從而提高數據安全性和權限控制。
-
簡化應用程序邏輯:視圖可以在數據庫層面實現一些通用的邏輯,簡化應用程序中的代碼,提高代碼復用性。
-
數據報表和分析:視圖可以用于創建數據報表和分析視圖,方便用戶進行數據分析和報表生成。
-
數據結構的抽象:視圖可以將多個表的數據結構抽象為一個虛擬的表,簡化數據訪問和操作。
總的來說,MySQL視圖適合于需要簡化復雜查詢、提高數據安全性、簡化應用程序邏輯和進行數據報表分析的場景。
4、實踐
這里我們將下面這個復雜查詢寫到視圖里面

首先創建視圖
CREATE VIEW vw_forlan_student AS SELECTA.`name`,A.age,B.class_name
FROMforlan_student A INNER JOIN forlan_class B ON A.class_id = B.id;
然后,直接查詢即可,可以看到效果,和前面的復雜查詢得到了一模一樣的內容
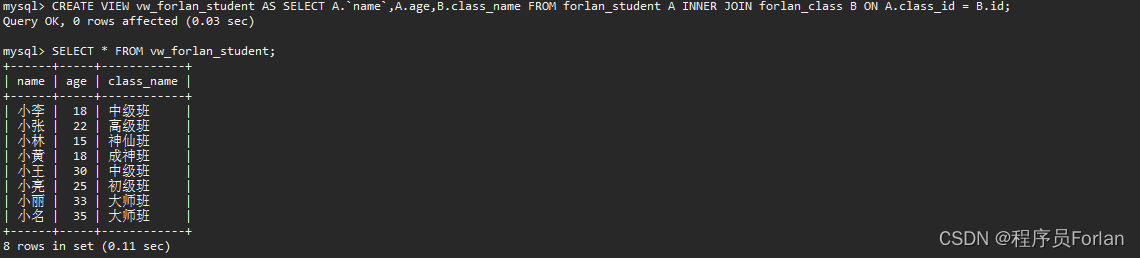
那么,我們直接查和通過視圖查,有啥區別,我們先來看看執行計劃,發現沒啥不同?
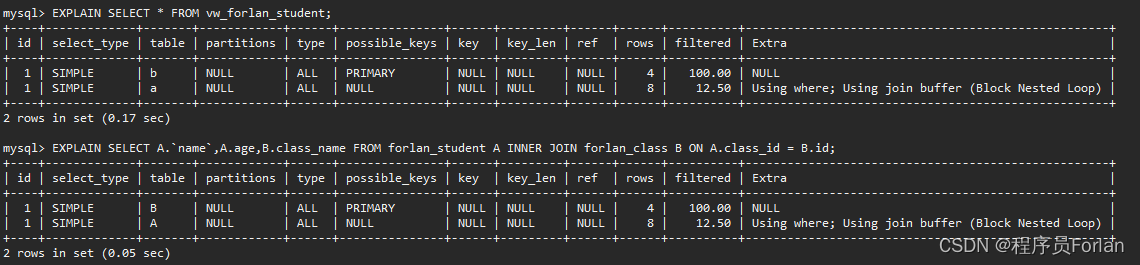
但總的來說,官方是給出了以下區別:
- 可讀性:將復雜SQL定義在視圖中可以提高查詢語句的可讀性。通過將復雜的邏輯封裝在視圖中,可以使查詢語句更簡潔、易于理解和維護。
- 重用性:定義視圖后,可以在多個查詢中重復使用該視圖,而不需要重復編寫復雜的SQL語句。這樣可以提高代碼的重用性和減少代碼冗余。
- 安全性:通過將復雜SQL定義在視圖中,可以限制用戶對底層數據的直接訪問。只有授予對視圖的訪問權限的用戶才能查詢視圖中的數據,而無法直接訪問底層表。
- 性能:在某些情況下,將復雜SQL定義在視圖中可能會提高查詢性能。視圖可以使用索引和其他優化技術來加速查詢,而直接查詢復雜SQL可能需要更多的計算資源和時間。
需要注意的是,將復雜SQL定義在視圖中也可能帶來一些額外的開銷,例如視圖的創建和維護成本。因此,在選擇使用哪種方式時,需要綜合考慮查詢的復雜性、可讀性、重用性和性能等因素。
二、函數(Function)
1、概念
函數是一段可重復使用的代碼,用于執行特定的操作或計算,并返回結果。函數可以接受參數,并根據這些參數執行一系列的操作,最后返回一個結果。
MySQL提供了許多內置函數,用于執行各種操作,例如數學計算、字符串處理、日期和時間操作等。除了內置函數,MySQL還支持自定義函數,以滿足特定的需求。
以下是一些常見的MySQL內置函數的示例:
數學函數:例如SUM、AVG、MAX、MIN等用于執行數值計算的函數。
字符串函數:例如CONCAT、SUBSTRING、LENGTH等用于處理字符串的函數。
日期和時間函數:例如NOW、DATE_FORMAT、DATE_ADD等用于處理日期和時間的函數。
2、基本操作
1)創建函數
CREATE FUNCTION function_name ([parameter1 data_type [, parameter2 data_type, ...]])RETURNS return_data_type[DETERMINISTIC][COMMENT 'string']BEGIN-- 函數體,包含具體的操作和邏輯-- 使用RETURN語句返回結果END;
參數說明:
- CREATE FUNCTION:指示創建一個函數。
- function_name:自定義函數的名稱。
- parameter1, parameter2, …:函數的參數列表,每個參數由參數名稱和數據類型組成。
- return_data_type:函數的返回值數據類型。可以選擇函數返回一個字符串(STRING)、整數(INTEGER)、實數(REAL)或十進制數(DECIMAL)。
- DETERMINISTIC:可選項,指示函數是否是確定性的(即,對于給定的輸入,是否總是返回相同的結果)。
- COMMENT ‘string’:可選項,用于為函數添加注釋。
- BEGIN和END:用于定義函數體的開始和結束。
拓展- 加載函數
CREATE [AGGREGATE] FUNCTION function_nameRETURNS {STRING|INTEGER|REAL|DECIMAL}SONAME shared_library_name
參數說明:
- CREATE FUNCTION是用于定義一個新函數的語句。當你在這里使用AGGREGATE FUNCTION時,你正在創建一個聚合函數,它會對一組值執行特定的操作。
- SONAME shared_library_name: 這是指定函數所在的共享庫的部分。shared_library_name是你要引用的共享庫的名稱。共享庫是一種存儲預先編譯的函數代碼的方式,這樣在調用函數時可以更快地執行。
2)使用函數
函數可以在SQL查詢中使用,也可以在存儲過程和觸發器中使用。一般在SELECT語句中使用函數來計算和轉換數據,或者在WHERE子句中使用函數來過濾數據。
例如:SELECT function_name(arguments) FROM table_name;
3、使用場景
-
數據處理和計算:函數可以用于執行特定的數據處理、計算和轉換,例如日期處理、字符串操作、數學運算等。
-
查詢優化:通過函數可以封裝復雜的查詢邏輯,提高查詢的可讀性和復用性,同時也有助于優化查詢性能。
-
業務規則和驗證:函數可以用于實現特定的業務規則和驗證邏輯,例如數據有效性檢查、權限控制等。
-
簡化應用程序邏輯:函數可以在數據庫層面實現一些通用的邏輯,簡化應用程序中的代碼,提高代碼復用性。
-
自定義聚合函數:通過自定義聚合函數,可以實現特定的數據聚合邏輯,滿足特定的業務需求。
總的來說,MySQL函數適合于需要在數據庫層面執行特定的數據處理、計算和驗證邏輯,以及優化查詢性能、簡化應用程序邏輯的場景。
4、實踐
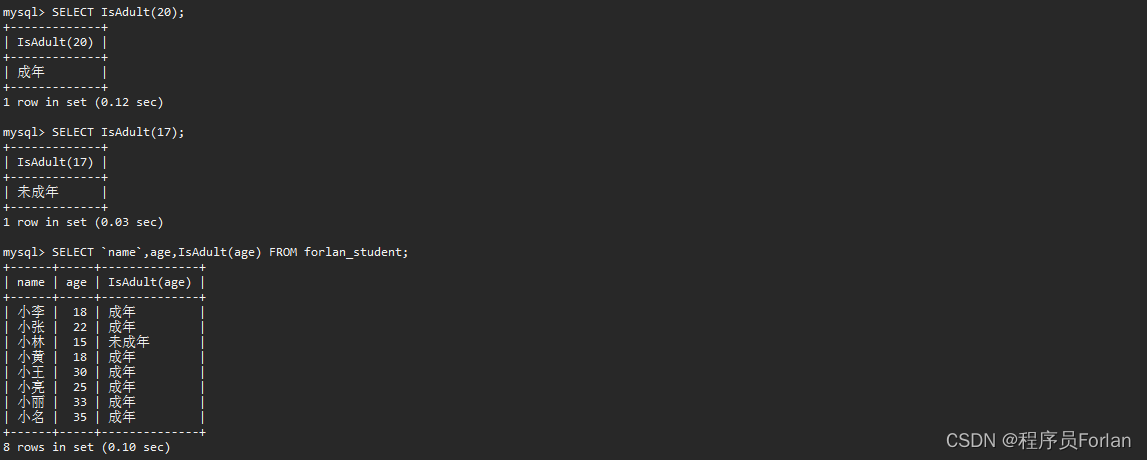
創建一個函數,判斷年齡是否成年,代碼如下:
CREATE FUNCTION IsAdult(age INT)
RETURNS VARCHAR(10)
BEGINDECLARE result VARCHAR(10);IF age >= 18 THENSET result = '成年';ELSESET result = '未成年';END IF;RETURN result;
END;
測試效果如下:
三、存儲過程(Stored Procedure)
1、概念
存儲過程是一組預定義的SQL語句集合,可以在數據庫中進行重復使用。存儲過程類似于函數,但不返回結果。它可以接受參數,并且可以包含條件邏輯、循環、異常處理等。
存儲過程由以下組成:
- 存儲過程名稱:用于唯一標識存儲過程的名稱。
- 參數列表:可選項,用于傳遞給存儲過程的輸入參數。
- 存儲過程體:包含一系列SQL語句和控制結構,用于實現特定的功能。
- 存儲過程結束標記:表示存儲過程的結束。
2、基本操作
1)創建存儲過程
CREATE PROCEDURE procedure_name[ (IN parameter1 datatype1 [, OUT|INOUT parameter2 datatype2 [, ...]] ) ]
BEGIN-- 存儲過程的邏輯代碼
END;
參數說明:
- CREATE PROCEDURE:指示創建一個存儲過程。
- procedure_name:存儲過程的名稱。
- parameter1, parameter2, …:存儲過程的參數列表,每個參數由參數名稱和數據類型組成。
- IN參數:用于將值傳遞給存儲過程。在存儲過程內部,IN參數的值是只讀的,不能在存儲過程中修改。
- OUT參數:用于從存儲過程中返回值。在存儲過程內部,OUT參數的值可以被修改,并在存儲過程執行完畢后返回給調用者。
- INOUT參數:既可以傳遞值給存儲過程,也可以從存儲過程中返回值。在存儲過程內部,INOUT參數的值可以被修改,并在存儲過程執行完畢后返回給調用者。
- BEGIN和END:用于定義存儲過程體的開始和結束。
2)使用存儲過程
使用CALL語句來調用存儲過程。在調用存儲過程時,您可以傳遞參數值,根據需要指定參數的模式(IN、OUT或INOUT)。
3、使用場景
-
數據處理和業務邏輯:存儲過程可以封裝復雜的數據處理邏輯,例如數據清洗、轉換、計算等,以及實現特定的業務規則和流程。
-
數據安全性和權限控制:通過存儲過程,可以對數據庫操作進行封裝和控制,限制用戶對數據的訪問和操作,提高數據安全性。
-
提高性能:存儲過程可以減少網絡通信開銷,提高數據庫操作的性能,尤其是在需要頻繁執行相同邏輯的情況下。
-
代碼復用和維護:存儲過程可以被多個應用程序共享和調用,提高代碼的復用性,同時也方便對邏輯進行統一管理和維護。
-
批量操作和事務管理:存儲過程可以實現批量數據操作,同時也可以管理事務,確保一系列操作的原子性和一致性。
總的來說,存儲過程適合于需要在數據庫層面實現復雜邏輯、提高性能、增強安全性和方便維護的場景。
4、實踐
使用存儲過程插入新班級新學生數據
1)創建一個存儲過程,用于插入班級信息并返回班級ID
CREATE PROCEDURE insert_class(IN class_name VARCHAR(255), OUT class_id INT)
BEGININSERT INTO forlan_class (class_name) VALUES (class_name);SET class_id = LAST_INSERT_ID();
END;
2)創建另一個存儲過程,用于插入學生信息并使用上一步中返回的班級ID:
CREATE PROCEDURE insert_student(IN name VARCHAR(255), IN age INT, IN class_id INT)
BEGININSERT INTO forlan_student (name, age, class_id) VALUES (name, age, class_id);
END;
3)調用存儲過程
CALL insert_class('存儲過程學習班', @class_id);
CALL insert_student('forlan', 20, @class_id);
4)通過查看視圖驗證,可以查到我們剛剛插入的,如下:

四、觸發器(Trigger)
1、概念
觸發器是一種數據庫對象,它在指定的表上自動執行特定的操作。當滿足特定的事件(如插入、更新或刪除數據)時,觸發器會觸發并執行預定義的操作。這些操作可以是SQL語句、存儲過程或其他自定義邏輯。觸發器通常用于實現數據完整性約束、審計跟蹤和自動化業務邏輯等功能
2、基本操作
1) 創建觸發器
CREATE[DEFINER = user]TRIGGER trigger_name{ BEFORE | AFTER } { INSERT | UPDATE | DELETE }ON tbl_name FOR EACH ROW[{ FOLLOWS | PRECEDES } other_trigger_name]trigger_body
參數說明:
- DEFINER = user: 這部分指定了觸發器的定義者
- TRIGGER trigger_name:指定觸發器的名稱,用于標識觸發器對象。
- BEFORE或AFTER:指定觸發器在事件之前或之后執行。BEFORE表示在事件執行之前觸發,AFTER表示在事件執行之后觸發。
- INSERT、UPDATE或DELETE:指定觸發器要響應的事件類型。INSERT表示在插入數據之前或之后觸發,UPDATE表示在更新數據之前或之后觸發,DELETE表示在刪除數據之前或之后觸發。
- ON table_name:指定觸發器所屬的表名,即觸發器要監視的表。
- trigger_order:指定觸發器的執行順序。
- FOR EACH ROW:表示觸發器將為每一行數據執行操作。這意味著觸發器的操作邏輯將在每次插入、更新或刪除數據時執行。
- { FOLLOWS | PRECEDES } other_trigger_name 表示該觸發器與其他觸發器之間的執行順序關系
2) 使用觸發器
一旦創建觸發器,它將自動與指定的表關聯。當觸發器所監視的事件發生時,觸發器的操作邏輯將被執行。
3、使用場景
-
數據完整性和約束:觸發器可以用于實現數據完整性和約束,例如在插入、更新、刪除數據時進行驗證和限制。
-
數據審計和日志記錄:觸發器可以用于記錄數據變更的日志,包括誰在什么時間做了什么操作。
-
數據復制和同步:觸發器可以用于在數據變更時觸發數據復制和同步操作,確保數據的一致性。
-
自動化任務和業務邏輯:觸發器可以用于執行特定的業務邏輯和自動化任務,例如在特定條件下觸發某些操作。
-
數據轉換和處理:觸發器可以用于在數據變更時進行特定的數據轉換和處理,例如數據格式轉換、計算字段值等。
總的來說,MySQL觸發器適合于需要在特定的數據變更時執行特定的邏輯、記錄數據變更日志、實現數據復制和同步、以及執行特定的自動化任務和業務邏輯的場景。
4、實踐
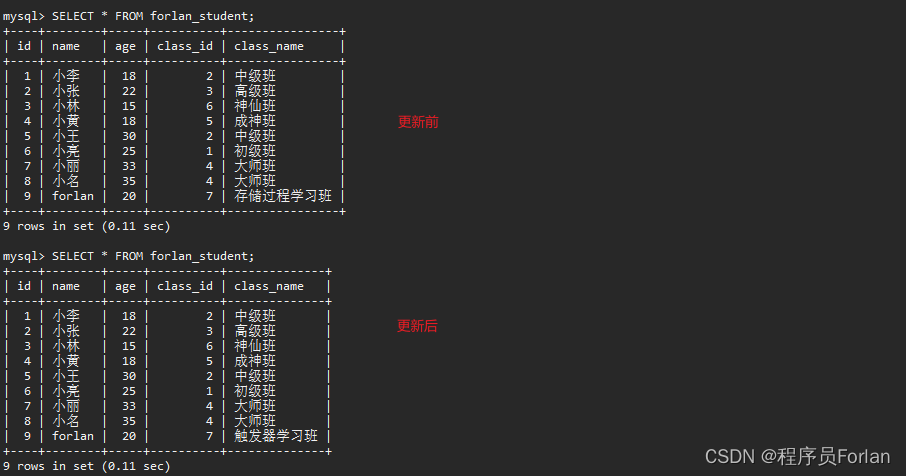
我們寫一個觸發器,來實現當班級信息發生變化時,觸發更新學生信息
1)創建觸發器
CREATE TRIGGER update_forlan_student
AFTER UPDATE ON forlan_class
FOR EACH ROW
BEGIN-- 更新學生表中對應班級的信息UPDATE forlan_studentSET class_name = NEW.class_nameWHERE class_id = NEW.id;
END;
注:NEW關鍵字表示觸發器所監視的事件中的新數據
2)修改班級信息
UPDATE `forlan_class` SET `class_name` = '觸發器學習班' WHERE `id` = 7
3)查看觸發器監情況,效果如下:
五、物化視圖(Materialized View)
1、概念
在MySQL中,物化視圖(Materialized View)是一種預先計算和存儲的查詢結果集。與普通視圖不同,物化視圖在創建時會將查詢結果保存在磁盤上,而不是在每次查詢時動態計算。這樣可以顯著提高查詢性能,并減少對原始表的查詢次數。
總的來說,通常用于存儲預先計算的結果,以提高查詢性能。然而,MySQL本身并不直接支持物化視圖,但可以通過函數、存儲過程、觸發器、視圖來實現類型的功能
2、使用場景
- 復雜查詢優化:當數據庫中存在復雜的查詢,需要多個表的聯接和聚合操作時,可以使用物化視圖來預先計算并存儲查詢結果,以提高查詢性能。
- 數據匯總和報表生成:物化視圖可以用于匯總和聚合大量數據,以生成報表和分析結果。通過預先計算和存儲匯總數據,可以加快報表生成的速度。
- 數據倉庫和決策支持系統:在數據倉庫和決策支持系統中,物化視圖可以用于存儲預先計算的指標和維度數據,以支持復雜的分析和決策過程。
- 實時數據更新:物化視圖可以定期或實時地更新,以保持與源數據的同步。這對于需要實時或近實時數據的應用程序非常有用。
需要注意的是,物化視圖的創建和維護可能會增加數據庫的存儲空間和更新成本。因此,在選擇使用物化視圖時,需要權衡查詢性能的提升和資源消耗之間的平衡。
3、實踐
學生表如下:
CREATE TABLE `forlan_student` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主鍵ID',`name` varchar(200) DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年齡',`class_id` bigint(20) DEFAULT NULL COMMENT '所屬班級',`class_name` varchar(255) DEFAULT NULL COMMENT '所屬班級名稱',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='學生信息表';
假設我們需要在頁面查看是否成年,這時候會有多種實現方案,我們來分析下:
- 方案一:代碼里面寫if…else…判斷,但這樣每次查詢都要計算一遍
- 方案二:在學生表新增一個字段,但這不符合數據庫第三范式了,因為是否成年”可以由“年齡”推出,具體數據庫范式可以去看數據庫基礎概念與范式反范式總結
- 方案三:新增一張表,但是需要改代碼,增刪改,都要重新計算去維護多一張表信息,挺麻煩的,這里就可以通過物化視圖來弄,自動觸發維護即可
1)創建學生年齡表
CREATE TABLE `materialized_student_adult_status` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主鍵ID',`student_id` bigint(20) DEFAULT NULL COMMENT '學生id',`is_adult` varchar(255) DEFAULT NULL COMMENT '是否成年',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='學生年齡表';
2)創建一個存儲過程,用于更新物化視圖的數據:
CREATE PROCEDURE update_student_adult_status()
BEGINDELETE FROM materialized_student_adult_status;INSERT INTO materialized_student_adult_status (student_id, is_adult)SELECT id, isAdult(age) FROM forlan_student;
END;
注:isAdult是我們前面自定義的函數
3)創建一個觸發器,當學生表中的年齡字段發生變化時,自動觸發更新物化視圖的存儲過程:
CREATE TRIGGER student_age_update_trigger
AFTER UPDATE ON forlan_student
FOR EACH ROW
BEGINIF NEW.age <> OLD.age THENCALL update_student_adult_status();END IF;
END;
4)創建一個普通視圖,用于展示我們需要的信息
CREATE VIEW vw_student_adult_status AS
SELECT A.*,B.is_adult
FROM forlan_student A JOIN materialized_student_adult_status B ON A.id = B.student_id;
5)查看效果,是否返回了學生表的信息,還返回了對應的是否成年字段,而且我們修改了年齡后,自動維護了is_adult字段
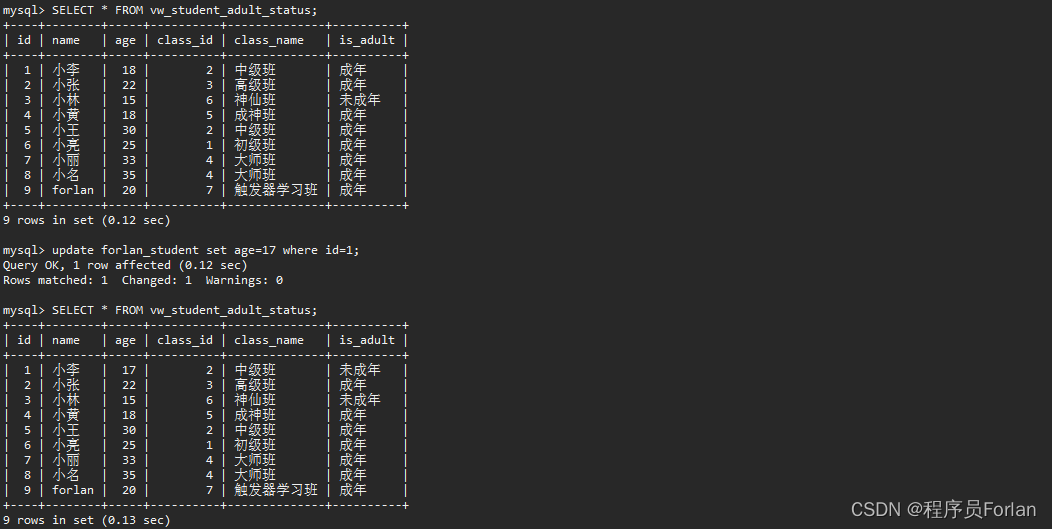
六、總結
從上面的理論與實現相結合,我們大概知道了視圖、函數、存儲過程、觸發器和物化視圖是干嘛的,總結如下:
- 視圖:一般用于預定義一些復雜查詢操作,隱藏底表實現細節,本身不存儲實際數據;
- 函數:把重復代碼抽取為一個公共方法,方便SQL語句、視圖、存儲過程、觸發器等調用;
- 存儲過程:一般用于實現復雜業務邏輯和數據處理,需要顯示使用CALL語句調用;
- 觸發器:類似于監聽器,監聽表的某些行為,觸發相應的動作;
- 物化視圖:類似于視圖,只不過它本身存儲數據,會把計算結果落庫,而不是每次查詢動態計算;



![【算法每日一練]-結構優化(保姆級教程 篇4 樹狀數組,線段樹,分塊模板篇)](http://pic.xiahunao.cn/【算法每日一練]-結構優化(保姆級教程 篇4 樹狀數組,線段樹,分塊模板篇))






![P1075 [NOIP2012 普及組] 質因數分解題解](http://pic.xiahunao.cn/P1075 [NOIP2012 普及組] 質因數分解題解)



)

的數據聚類可視化)


數據分析(二)——數據清洗、轉換)