目錄
分塊
分塊算法步驟:
樹狀數組
樹狀數組步驟:
線段樹點更新
點更新步驟:
線段樹區間更新
區間更新步驟:
不同于倍增和前綴和與差分序列。
前綴和處理不更新的區間和
差分處理離線的區間更新問題
倍增處理離線的區間最值問題
分塊,樹狀數組,線段樹:
分塊處理求多次區間更新的區間和(在線算法)
樹狀數組求多次點更新的區間和 (在線算法)
線段樹求多次點更新或區間更新的區間最值 (在線算法)
????????
????????
分塊
分塊算法思想:基于優化后的暴力。
分塊的本質就是維護每個塊的suf數組(和lz),然后分整個塊處理和非整個塊暴力處理!
分塊操作是修改原數組及懶標,維護suf
????????
題目:(POJ 3648)?一個簡單的整數問題

????????
分塊算法步驟:
????????
1,預處理塊build:初始化每塊的左右下標L[],和R[],每個下標的所屬塊號be,每塊的和suf
????????
2,區間修改update:對于完整的塊僅修改懶標lz,不完整的就暴力修改a和suf
????????
3,區間查詢query :對于完整的塊直接利用懶標lz和suf,不完整的就暴力a和lz
(這里沒有什么懶標下放,這又不是求區間max)
#include <bits/stdc++.h>//POJ3648
using namespace std;
const int N=100010;
typedef long long ll;
ll suf[N],lz[N];//分塊的本質是維護每個塊的suf數組(和lz),然后分整個塊處理和非整個塊暴力處理(相當于優化后的暴力)
int a[N],L[N],R[N],be[N];
int n,m;
//分塊:我們處理下標都是從1開始
void build(){//L[]R[]每塊的左右下標,be[]每個下標的所屬塊號,suf[]每塊的和int t=sqrt(n);int num=n/t;if(n%t) num++;//t是塊長,num是塊數,for(int i=1;i<=num;i++){L[i]=(i-1)*t+1; R[i]=i*t;}R[num]=n;//更改最后一塊的右下標for(int i=1;i<=num;i++)for(int j=L[i];j<=R[i];j++){be[j]=i;suf[i]+=a[j];//初始化每點的be和每塊的suf}
}
//區間修改
void update (int l,int r,int d){//完整塊就修改懶標lz,不完整就修改a,sufint p=be[l],q=be[r];if(p==q){//如果在同一塊就暴力修改a和suffor(int i=l;i<=r;i++) a[i]+=d;suf[p]+=d*(r-l+1);}else{//否則:完整的塊修改懶標lz,不完整還是暴力a和suffor(int i=p+1;i<=q-1;i++) lz[i]+=d;for(int i=l;i<=R[p];i++) a[i]+=d;suf[p]+=d*(R[p]-l+1);for(int i=L[q];i<=r;i++) a[i]+=d;suf[q]+=d*(r-L[q]+1);}
}ll query(int l,int r){//完整塊suf和lz,不完整就a和lzint p=be[l],q=be[r];ll ans=0;if(p==q){//同一塊就看a和lzfor(int i=l;i<=r;i++) ans+=a[i];ans+=lz[p]*(r-l+1);}else{//否則:完整就suf+lz,不完整還是a和lzfor(int i=p+1;i<=q-1;i++) ans+=suf[i]+lz[i]*(R[i]-L[i]+1);for(int i=l;i<=R[p];i++) ans+=a[i];for(int i=L[q];i<=r;i++) ans+=a[i];ans+=lz[q]*(r-L[q]+1);}return ans;
}int main(){cin>>n>>m;int l,r,d;char op[3];//不要輸入字符,輸入字符串for(int i=1;i<=n;i++){scanf("%lld",&a[i]);}build();for(int i=1;i<=m;i++){scanf("%s %d %d",op,&l,&r);if(op[0]=='C'){scanf("%d",&d);update(l,r,d);}else{printf("%lld\n",query(l,r));}}
}
????????
????????
樹狀數組
樹狀數組思想:和原數組一一對應,且是通過“二進制 ”分解維護區間
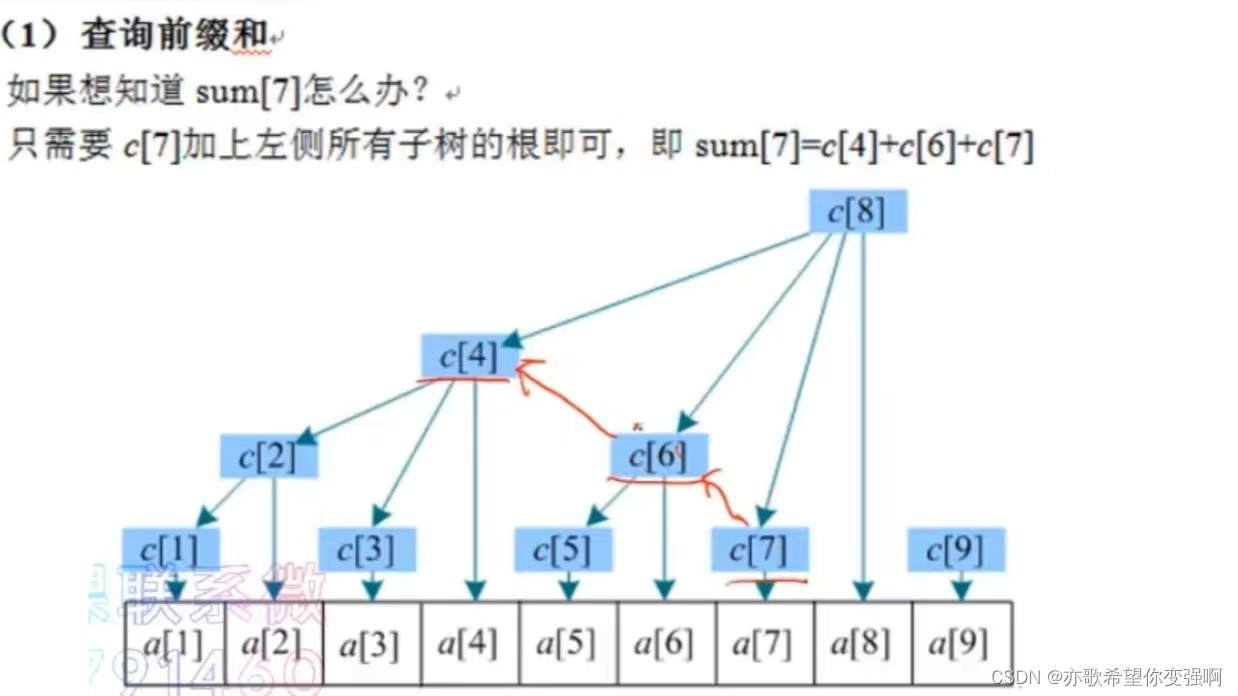
樹狀數組本質就是創建了一個離散的一維數組c,每個點維護不同區間的前綴和。更新和查詢都是離散的
樹狀數組操作是修改c數組的后繼,查詢c數組的前驅
????????????????
c[i]區間維護長度: i末尾有連續的k個0,則c[i]保存的區間長度為2^k,即從a[i]向前的2^k個元素
 ?????????
?????????
樹狀數組步驟:
????????
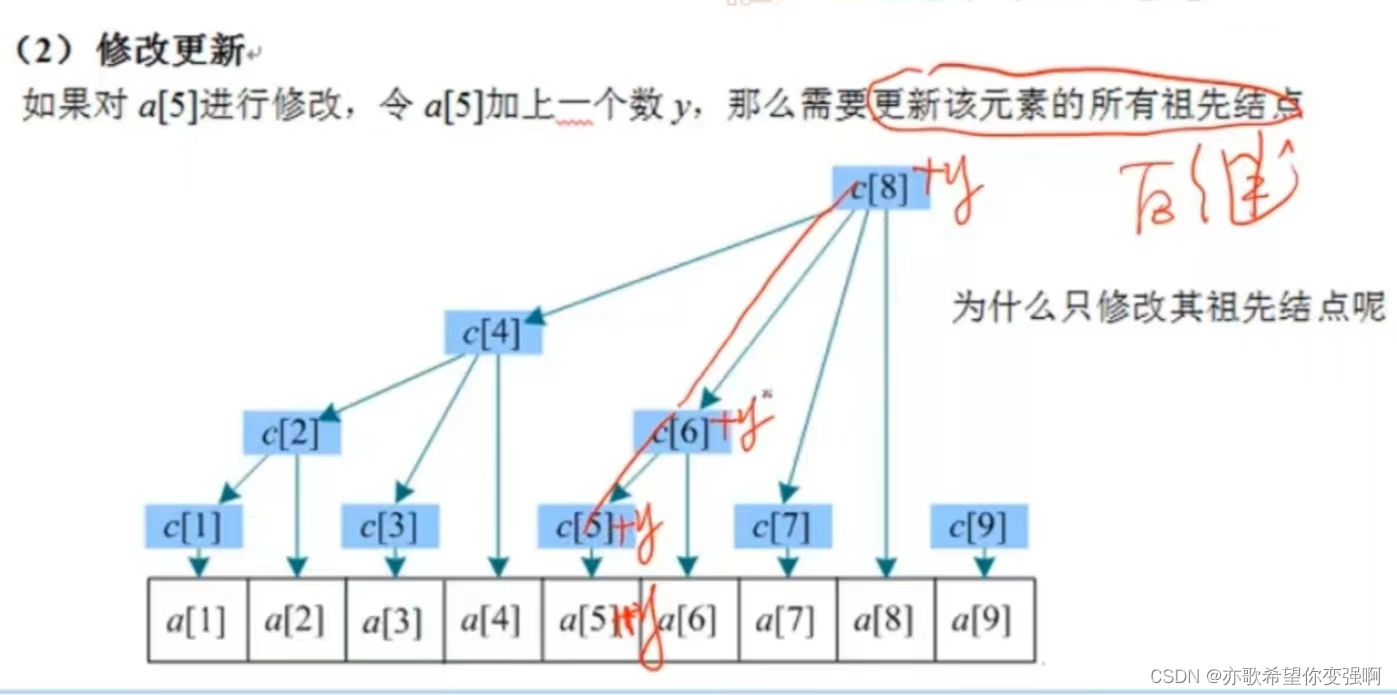
單點修改更新add:找后繼 ?更新該元素所有的祖先節點????????????????
查詢前綴和sum:找前驅 ? ?加上左側所有子樹的根(也就是自己的前兄弟,故稱為前驅)
????????
#include <bits/stdc++.h>//一維樹狀數組 性能是log(n)
using namespace std;
typedef long long ll;
const int maxn=10000;
ll c[maxn];//c[]為樹狀數組
int n,a[maxn];
int lowbit(int i){ return (-i)&i;}
//獲取c[i]區間的長度(計算機中的負數是以補碼來存的)
void add(int i,int z){ for(;i<=n;i+=lowbit(i)) c[i]+=z;}
//c[i]的后繼都加上z:直接后繼為[i+lowbit(i)]
ll sum(int i){//求前綴和a[1]~a[i],把i前面所有的根加上即可:直接前驅為[i-lowbit(i)]ll s=0;for(;i>0;i-=lowbit(i)) s+=c[i];return s;
}ll sum(int i,int j){ return sum(j)-sum(i-1);}//求區間和int main(){cin>>n;for(int i=1;i<=n;i++){//數組必須從1開始輸入cin>>a[i];add(i,a[i]);//點更新,更新樹狀數組} int x1,x2;cin>>x1;cout<<sum(x1)<<'\n';cin>>x1>>x2;cout<<sum(x1,x2);return 0;
}那么僅僅把sum改成從(1,1)到(x,y)求和即可變成二維的樹狀數組
#include <bits/stdc++.h>//二維樹狀數組
using namespace std;
typedef long long ll;
const int maxn=10000;
ll c[maxn][maxn];
int n,a[maxn][maxn];int lowbit(int i){ return (-i)&i;}void add(int x,int y,int z){for(int i=x;i<=n;i+=lowbit(i))for(int j=y;j<=n;j+=lowbit(j)){c[i][j]+=z;}
}ll sum(int x,int y){//求(1,1)到(x,y)和ll s=0;for(int i=x;i>0;i-=lowbit(i))for(int j=y;j>0;j-=lowbit(j)){s+=c[i][j];}return s;
}ll sum(int x1,int y1,int x2,int y2){return sum(x2,y2)-sum(x1-1,y2)-sum(x2,y1-1)+sum(x1-1,y1-1);
}int main(){cin>>n;for(int i=1;i<=n;i++)for(int j=1;j<=n;j++){cin>>a[i][j];add(i,j,a[i][j]);}int x1,y1,x2,y2;cin>>x1>>y1;cout<<sum(x1,y1)<<'\n';cin>>x1>>y1>>x2>>y2;cout<<sum(x1,y1,x2,y2);}????????
????????
線段樹點更新
線段樹思想:建立一顆二叉樹來用每個節點去維護對應區間的信息
線段樹的本質是在4maxn大小的一維樹形離散數組tree(節點)上存儲區間的信息。建立,更新和查詢也都是離散的
線段樹操作是找到并修改葉節點信息來維護整棵樹,查詢是找所有的對應節點
????????
要注意:
我們建立的二叉樹在非葉子層時都是滿二叉樹。所以k節點的左孩子一定是2k,右孩子一定是2k+1另外k(節點)的值和l,r的值沒有任何關系,只不過是l==r時候k是葉子節點
????????
下圖是初始化線段樹的節點號
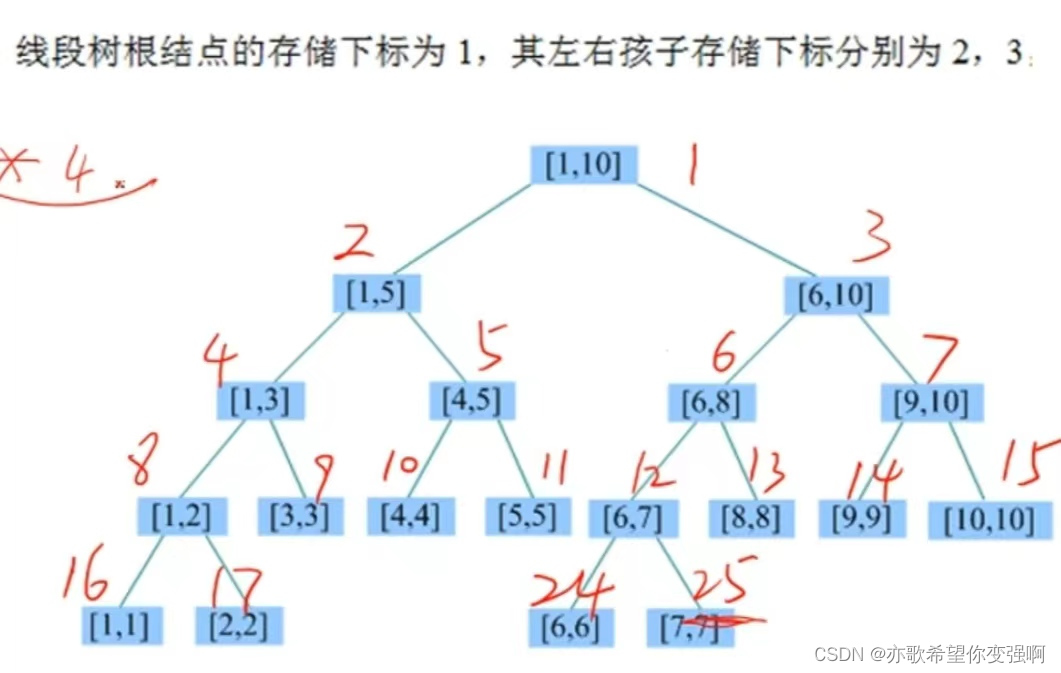
但是整棵樹一定是按照dfs序來更新的,也因此葉子節點也是dfs序更新的?
????????
點更新步驟:
????????
build:初始化節點信息:找到葉節點放置數組信息,然后上傳到所有節點更新信息
????????
update:找到對應的點將i下標的值更新為v
????????
query: 找到對正確的節點就返回,否則就繼續分叉找
????????
千萬別看代碼多長,基本就函數中最前面的幾句有用,剩余操作的都是在找孩子進行遞歸。
#include <bits/stdc++.h>
using namespace std;
const int maxn=100005,INF=0x3f3f3f3f;
int n,a[maxn];
struct node{ int l,r,mx;}tree[maxn*4];//存放左右端點l,r,mx為區間最值,tree存放樹節點號void build(int k,int l,int r){//創建線段樹:初始化每個節點tree[k].l=l;tree[k].r=r;if(l==r){tree[k].mx=a[l];return ;}int mid=(l+r)/2;build(k<<1,l,mid);//建樹時候范圍一定要變化build(k<<1|1,mid+1,r);tree[k].mx=max(tree[k<<1].mx,tree[k<<1|1].mx);//創建完成孩子后再更新最大值
}void update(int k,int i,int v){//單點修改:在k節點將i下標的值更新為vif(tree[k].l==tree[k].r&&tree[k].l==i){//找i下標的葉子更新tree[k].mx=v;return ;}int mid=(tree[k].l+tree[k].r)/2;if(i<=mid) update(k<<1,i,v);//否則就進入左子樹lc或右子樹更新rcelse update(k<<1|1,i,v);tree[k].mx=max(tree[k<<1].mx,tree[k<<1|1].mx);//孩子更新完后修改最大值
}int query(int k,int l,int r){//區間查詢:找到對正確的節點就返回,否則就繼續分叉找if(tree[k].l>=l&&tree[k].r<=r){return tree[k].mx;//找到了}int mid=(tree[k].l+tree[k].r)/2;int maxx=-INF;if(l<=mid){//否則就找左子樹或右子樹的最值maxx=max(maxx,query(k<<1,l,r));}if(r>mid){maxx=max(maxx,query(k<<1|1,l,r));}return maxx;
}void print(int k){if(tree[k].mx){cout<<k<<"\t"<<tree[k].l<<"\t"<<tree[k].r<<"\t"<<tree[k].mx<<"\t"<<'\n';print(k<<1);print((k<<1)+1);}
}int main(){int l,r,i,v;cin>>n;for(int i=1;i<=n;i++) cin>>a[i];build(1,1,n);//創建二叉線段樹,為啥傳入樹根呢?答:方便找左右孩子print(1);cin>>l>>r;cout<<query(1,l,r)<<'\n';//查詢區間最值cin>>i>>v;update(1,i,v);//點更新print(1);cin>>l>>r;cout<<query(1,l,r)<<'\n';
}輸入樣例后建立的二叉樹:?
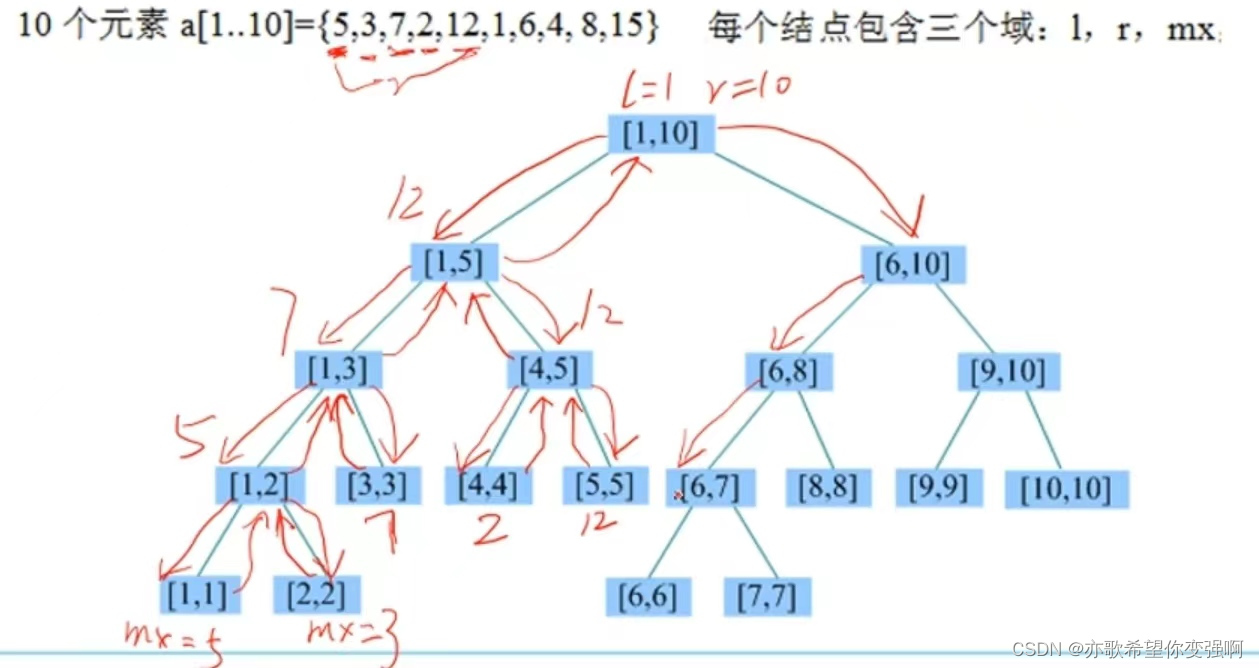
????????
?????????
線段樹區間更新
????????
區間更新步驟:
????????
創建線段樹:初始化節點信息:找到葉節點放置數組信息,然后上傳到所有節點更新信息
????????
區間修改:在k節點上修改[l,r]區間為v值,整體包含就做懶標,否則就繼續分叉(分叉前一定要懶標下移)
????????
區間查詢:找到對正確的節點就返回,否則就繼續分叉找(分叉前一定要懶標下移)
也就是相對點更新來講多了懶標的處理?
#include <bits/stdc++.h>
using namespace std;
const int maxn=100005,INF=0x3f3f3f3f;
int n,a[maxn];
struct node{ int l,r,mx,lz;}tree[maxn*4];//存放左右端點l,r,mx表示區間[l,r]最值,lz表示懶標 tree存放樹節點號
//二叉樹的本質是在4k的一維dfs序的樹形離散數組(節點)上存儲的信息。另外k(節點)的值和l,r的值沒有任何關系,只不過是l==r時候k是葉子節點
void lazy(int k,int v){tree[k].mx=tree[k].lz=v;}//給節點k打懶標void pushdown(int k){//從k節點下傳懶標(傳給子樹),只會傳一次,否則就退化成單點修改了lazy(k<<1,tree[k].lz);lazy(k<<1|1,tree[k].lz);//+的優先級太高了tree[k].lz=-1;//清除當前節點懶標
}void build(int k,int l,int r){//創建線段樹:創建二叉樹,然后在葉節點放置數組信息,然后上傳到所有節點更新信息tree[k].l=l;tree[k].r=r;tree[k].lz=-1;//初始化節點if(l==r){tree[k].mx=a[l];return ;//按dfs順序更新葉子}int mid=(l+r)/2;build(k<<1,l,mid);//建樹時候范圍一定要變化build(k<<1|1,mid+1,r);//左右孩子節點為2k和2k+1,分別維護[l,mid]和[mid+1,r]的區間信息tree[k].mx=max(tree[k<<1].mx,tree[k<<1|1].mx);//更新最大值
}void update(int k,int l,int r,int v){//區間修改:在k節點上修改[l,r]區間為v值,整體包含就做懶標,否則就繼續分叉if(tree[k].l>=l&&tree[k].r<=r){//恰好找到區間(覆蓋也行)return lazy(k,v);//直接做懶標記并結束本層,這個return不是返回值的}if(tree[k].lz!=-1) pushdown(k);//有懶標,先下移再進入子樹(這樣下個節點的lz和mx就更新了)int mid=(tree[k].l+tree[k].r)/2;if(l<=mid) update(k<<1,l,r,v);//傳節點即可,因為我們用的是節點的信息(build時是l到mid區間為左子樹,所以必須l<=mid)if(r>mid) update(k<<1|1,l,r,v);tree[k].mx=max(tree[k<<1].mx,tree[k<<1|1].mx);//更新最大值
}int query(int k,int l,int r){//區間查詢:找到對正確的節點就返回,否則就繼續分叉找if(tree[k].l>=l&&tree[k].r<=r){//找到就返回return tree[k].mx;}if(tree[k].lz!=-1) pushdown(k);//有懶標,先下移再進入子樹int mid =(tree[k].l+tree[k].r)/2;int maxx=-INF;if(l<=mid) maxx=max(maxx,query(k<<1,l,r));//否則就找左子樹或右子樹的最值if(r>mid) maxx=max(maxx,query(k<<1|1,l,r));return maxx;
}void print(int k){if(tree[k].mx){//從根開始dfs順序訪問每個節點(1,2,3 ……)cout<<k<<"\t"<<tree[k].l<<"\t"<<tree[k].r<<"\t"<<tree[k].mx<<"\t"<<'\n';print(k<<1);print(k<<1|1);}
}int main(){int l,r,v;cin>>n;for(int i=1;i<=n;i++) cin>>a[i];build(1,1,n);//創建線段樹 print(1);cin>>l>>r;cout<<query(1,l,r)<<'\n';//區間查詢cin>>l>>r>>v;update(1,l,r,v);//區間修改print(1);for(int i=1;i<=n;i++)cout<<a[i]<<' ';cout<<"\n";while(l){cin>>l>>r;cout<<query(1,l,r)<<'\n';}
}





![P1075 [NOIP2012 普及組] 質因數分解題解](http://pic.xiahunao.cn/P1075 [NOIP2012 普及組] 質因數分解題解)



)

的數據聚類可視化)


數據分析(二)——數據清洗、轉換)
如何訪問Github下載FFmpeg源碼)
)

