文章目錄
- 一、論文信息
- 二、論文概要
- 三、實驗動機
- 四、創新之處
- 五、實驗分析
- 六、核心代碼
- 注釋版本
- 七、實驗總結
一、論文信息
- 論文題目:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
- 中文題目:奔跑而非行走:追求更高FLOPS以實現更快神經網絡
- 論文鏈接:點擊跳轉
- 代碼鏈接:點擊跳轉
- 作者:Jierun Chen (中文名:陳潔潤),香港科技大學(HKUST)、Shiu-hong Kao (高詩鴻),香港科技大學(HKUST)、Hao He (何豪),香港科技大學(HKUST)、Weipeng Zhuo (卓偉鵬),香港科技大學(HKUST)\Song Wen (溫松),羅格斯大學(Rutgers University)、Chul-Ho Lee (李哲昊),德州州立大學(Texas State University)、S.-H. Gary Chan (陳紹豪),香港科技大學(HKUST)
- 單位: 香港科技大學(HKUST)、羅格斯大學、德克薩斯州立大學
- 核心速覽:提出一種新型部分卷積(PConv)和FasterNet架構,在減少FLOPs的同時提升FLOPS,實現更快的推理速度。
二、論文概要
本文指出當前輕量級神經網絡雖然FLOPs低,但由于內存訪問頻繁導致FLOPS(每秒浮點運算次數)不高,實際延遲并未顯著降低。作者提出部分卷積(PConv),僅對部分通道進行卷積,減少計算和內存訪問,并基于此構建FasterNet,在多個視覺任務上實現速度與精度的最優平衡。
三、實驗動機
-
現有輕量網絡(如MobileNet、ShuffleNet)雖FLOPs低,但FLOPS也低,導致實際延遲高。
-
深度可分離卷積(DWConv)等操作內存訪問頻繁,成為速度瓶頸。
-
目標:在減少FLOPs的同時保持高FLOPS,實現真正的高速度。
兩個概念:FLOPS和FLOPs(s一個大寫一個小寫)
FLOPS: FLoating point Operations Per Second的縮寫,即每秒浮點運算次數,或表示為計算速度。是一個衡量硬件性能的指標。
FLOPs: FLoating point OPerationS 即 浮點計算次數,包含乘法和加法,只和模型有關,可以用來衡量其復雜度。
總結起來,S大寫的是計算速度,小寫的是計算量。計算量 / 計算速度 = 計算時間Latency
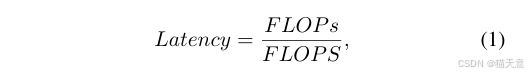
四、創新之處
-
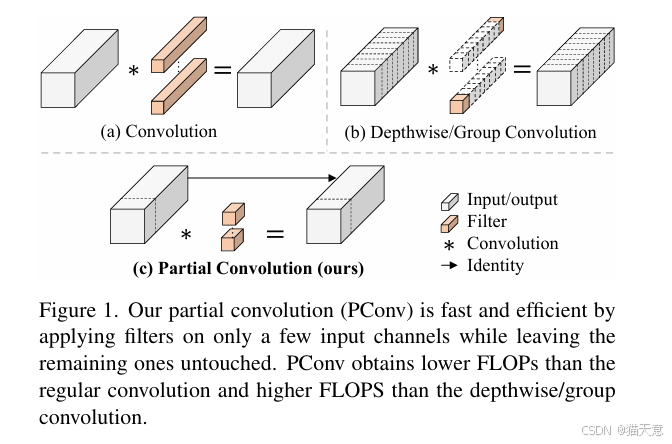
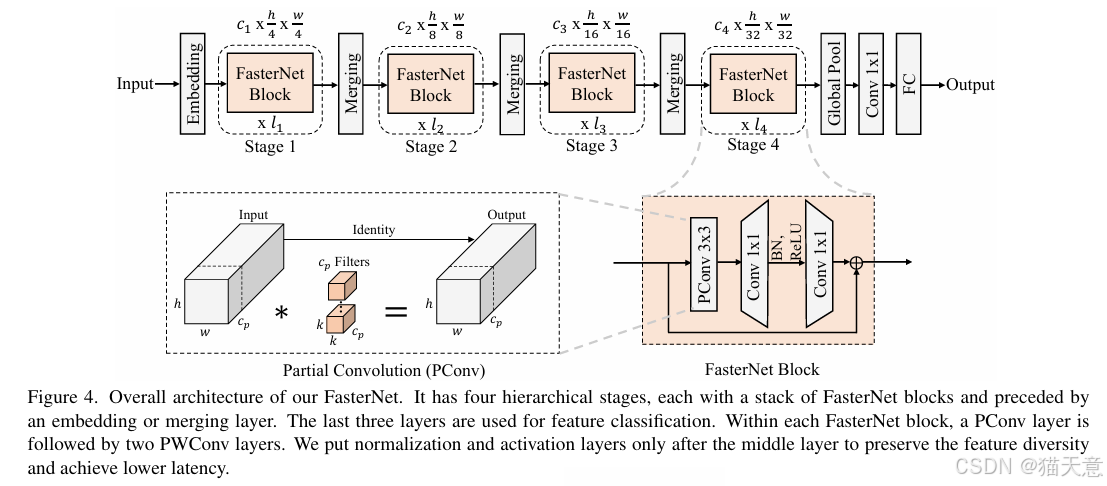
提出PConv:僅對連續的一部分通道進行卷積,其余通道保留,大幅減少計算和內存訪問。
-
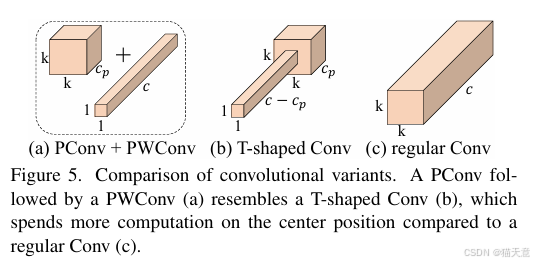
T型感受野:PConv + PWConv 組合形成T型卷積,更關注中心位置,與常規卷積近似。
-
FasterNet架構:基于PConv構建,結構簡潔,硬件友好,在多個設備上(GPU/CPU/ARM)均表現優異。

五、實驗分析
-
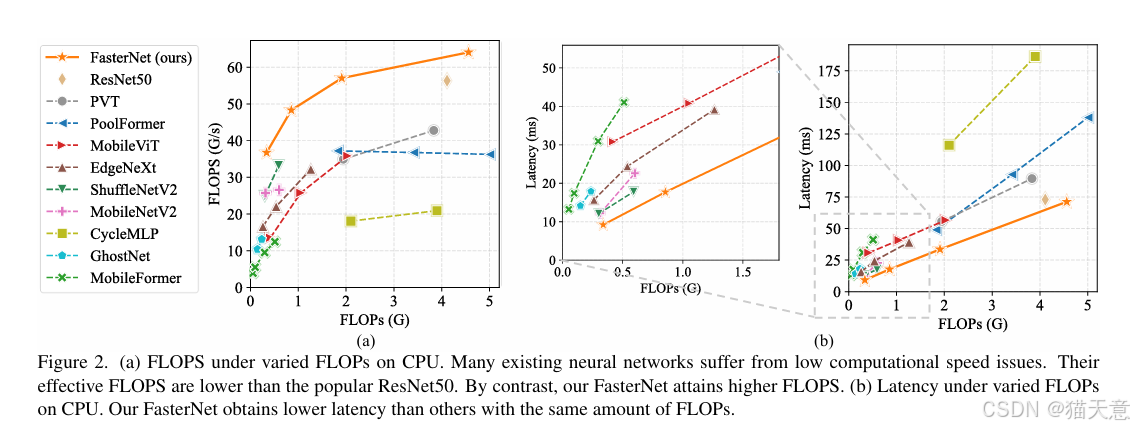
PConv速度對比:在相同FLOPs下,PConv的FLOPS顯著高于DWConv和GConv。
-
ImageNet分類:FasterNet在相同精度下延遲更低,吞吐量更高。
-
下游任務(檢測/分割):在COCO數據集上,FasterNet作為Backbone顯著提升檢測與分割性能。
-
消融實驗:驗證了部分比例 r=1/4 最優,BN比LN更高效,不同規模模型適用不同激活函數。
六、核心代碼
class Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x: Tensor) -> Tensor:# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x
注釋版本
class Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_div # 計算要進行3x3卷積的通道數self.dim_untouched = dim - self.dim_conv3 # 計算保持不變的通道數self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False) # 定義3x3卷積# 根據forward參數選擇前向傳播的實現方式 兩個函數實質上是等價的操作,只是實現方式不同而已。if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:# 僅用于推理的切片方法x = x.clone() # 克隆輸入以保持原始輸入不變(為了后續殘差連接)# 只對前dim_conv3個通道進行卷積操作x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x: Tensor) -> Tensor:# 用于訓練/推理的分割-連接方法# 將輸入分割為兩部分:要進行卷積的部分和保持不變的部分x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1) # 對第一部分進行卷積x = torch.cat((x1, x2), 1) # 將兩部分重新連接return x
七、實驗總結
-
PConv 在減少FLOPs的同時顯著提升FLOPS,是替代DWConv的高效選擇。
-
FasterNet 在ImageNet、COCO等任務上實現SOTA速度-精度權衡。
-
方法簡潔、通用性強,適用于多種硬件平臺。
--- 類加載子系統)



)




)









