目錄
介紹
準備
目標
規定
思路
補充知識
解法參考
介紹
Markdown 因為其簡潔的語法大受歡迎,已經成為大家寫博客或文檔時必備的技能點,眾多博客平臺都提倡用戶使用 Markdown 語法進行文章書寫,然后再發布后,實時的將其轉化為常規的 HTML 頁面渲染。
本題需要在已提供的基礎項目中,使用 Nodejs 實現簡易的 Markdown 文檔解析器。
準備
開始答題前,需要先打開本題的項目代碼文件夾,目錄結構如下:
├── docs.md
├── images
│ └── md.jpg
├── index.html
└── js├── index.js└── parse.js其中:
index.html?是主頁面。images?是圖片文件夾。docs.md?是需要解析的 Markdown 文件。js/index.js?是提供的工具腳本,用于快速驗證代碼結果。js/parse.js?是需要補充的腳本文件。
注意:打開環境后發現缺少項目代碼,請手動鍵入下述命令進行下載:
cd /home/project
wget https://labfile.oss.aliyuncs.com/courses/18213/07.zip && unzip 07.zip && rm 07.zip目標
在?js/parse.js?中實現幾種特定的 Markdown 語法解析,目前初始文件中已實現標題解析(即從?#?前綴轉換為?<hn>?標簽),請你繼續完善該文件 TODO 部分,完成剩余語法解析操作,具體需求如下:
1.對分隔符進行解析,Markdown 中使用?---?(三條及以上的短橫線) 作為分隔符,將其解析成為?<hr>?標簽:
<!-- Markdown -->
----<!-- 對應 HTML -->
<hr>2.對引用區塊進行解析,Markdown 中使用?>?作為前綴,將其解析成為?<blockquote>?標簽:
<!-- Markdown -->
> 引用區塊1> 多級引用區塊2
> 多級引用區塊2<!-- 對應 HTML -->
<blockquote><p>引用區塊1</p>
</blockquote><blockquote><p>多級引用區塊2</p><p>多級引用區塊2</p>
</blockquote>3.對無序列表進行解析,Markdown 中使用?*?或者?-?作為前綴,將其解析成為?<ul>?標簽:
<!-- Markdown -->
* 無序列表
* 無序列表
* 無序列表或者:
- 無序列表
- 無序列表
- 無序列表<!-- 對應 HTML -->
<ul><li>無序列表</li><li>無序列表</li><li>無序列表</li>
</ul>4.對圖片進行解析,Markdown 中使用??表示,將其解析成為?<img>?標簽:
<!-- Markdown -->
<!-- 對應 HTML -->
<img src="./images/md.jpg" alt="圖片">5.對文字效果進行解析,比如粗體效果,和行內代碼塊,將其分別解析成?<b>?和?code?標簽:
<!-- Markdown -->
這是**粗體**的效果文字,這是內嵌的`代碼行`<!-- 對應 HTML -->
這是<b>粗體</b>的效果文字,這是內嵌的<code>代碼行</code>在驗證代碼效果時,你可以在終端運行:
node ./js/index.js程序會將解析的結果輸出到?index.html?文件中,然后通過瀏覽器查看輸出的?index.html?是否符合解析要求(注意:程序不會實時的將結果更新到?index.html?文件中,在你的代碼變更后,請重新執行上述命令)。
在題目所提供的數據的情況下,完成后的效果如下:
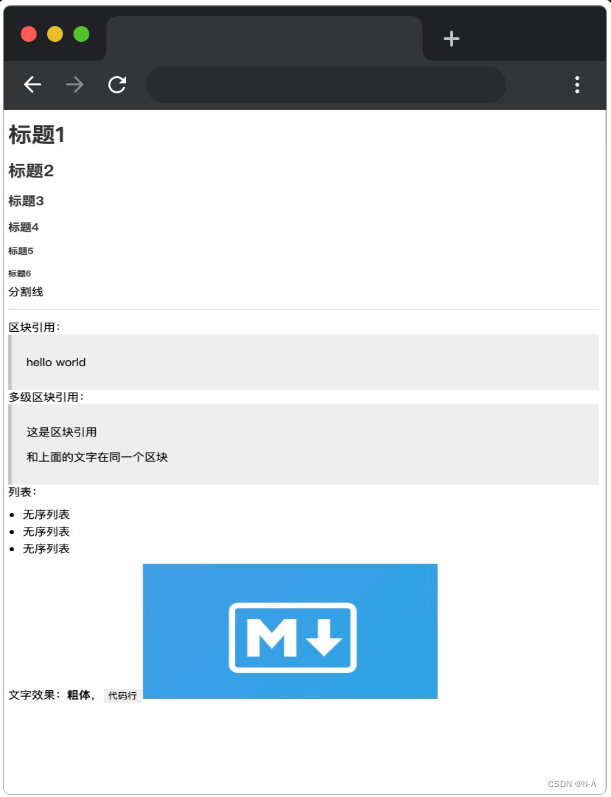
規定
- 請勿修改?
js/parse.js?文件外的任何內容。 - 請嚴格按照考試步驟操作,切勿修改考試默認提供項目中的文件名稱、文件夾路徑、class 名、id 名、圖片名等,以免造成無法判題通過。自己先做以下把,傳送門
思路
本道題在14屆省賽中是倒數第二道題目,還是有一定的難度的。本文的題目表示考查的點是Node.js。但是在做這道題目我們壓根就不需要使用到Node.js的知識點,因此這部分的功能題目源碼都已經幫我們寫好了。它主要是使用到了Node.js中的fs模塊來讀取md文件,后續對其進行讀取到的文本內容通過解析之后渲染到了html文檔中。如果對Node.js感興趣的小伙伴可以看我之前發布的文章。一共6篇,還有一篇案例。
這道題主要是給我們一些規則,讓我們通過對應的規則去將代碼進行轉換。做這道題目首先自己需要對正則有一點的了解。然后需要對字符串或者數組的一些方法熟悉,才能方便處理。同時還需要你會觀察上下文的代碼,通過它已經提供的代碼來對其進行理解,然后編寫出自己的代碼。
補充知識
JavaScript中的正則表達式(正則規則)是用于匹配字符串模式的工具。它們提供了強大的方式來搜索、替換或提取字符串中的特定部分。以下是一些常見的JS正則表達式規則:
1.字面量表示法:使用斜杠(/)來包裹正則表達式模式,例如:/pattern/flags。pattern 是你要匹配的模式,flags 是標志,可以是 i(忽略大小寫)、g(全局匹配)、m(多行匹配)等。
2.元字符:元字符是在正則表達式中具有特殊含義的字符,如 ^(匹配開頭)、$(匹配結尾)、.(匹配除換行符外的任何字符)、*(匹配前一個元素零次或多次)等。
3.字符類:使用方括號 [ ] 來定義一個字符類,代表匹配其中任何一個字符。比如 [abc] 表示匹配字符 a、b 或 c。
4.量詞:量詞用于指定匹配元素的數量。常見的量詞包括 *(零次或多次匹配)、+(一次或多次匹配)、?(零次或一次匹配)、{n}(匹配 n 次)、{n,}(至少匹配 n 次)、{n,m}(匹配 n 到 m 次)等。
5.捕獲組:使用括號 () 可以創建一個捕獲組,用于匹配子表達式,并可以在后續操作中引用它。
6.特殊字符轉義:在正則表達式中,有些字符具有特殊含義,如果想要匹配這些字符本身,需要使用反斜杠 \ 進行轉義,比如 \. 可以匹配 . 字符。
7.預定義模式:如 \d(匹配數字字符)、\w(匹配字母、數字或下劃線)、\s(匹配空白字符)等,它們表示常見的字符集合。
8.修飾符:修飾符用于指定匹配規則的標志,比如 i(不區分大小寫)、g(全局匹配)、m(多行匹配)等。
匹配數字
const pattern = /\d+/;
console.log(pattern.test("Hello 123")); // 輸出 true,匹配到數字
console.log(pattern.test("Hello World")); // 輸出 false,未匹配到數字
匹配郵箱:
const emailPattern = /^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$/;
console.log(emailPattern.test("example@mail.com")); // 輸出 true,匹配郵箱格式
console.log(emailPattern.test("invalid_email.com")); // 輸出 false,不匹配郵箱格式
提取字符串中的數字:
const str = "Age: 25, Height: 180cm";
const numberPattern = /\d+/g;
const numbers = str.match(numberPattern);
console.log(numbers); // 輸出 ["25", "180"]
替換字符串中的特定內容:
const sentence = "Learn JavaScript, it's JavaScript";
const replacePattern = /JavaScript/g;
const replaced = sentence.replace(replacePattern, "JS");
console.log(replaced); // 輸出 "Learn JS, it's JS"
檢查字符串是否以特定模式開頭:
const startsWithPattern = /^Start/;
console.log(startsWithPattern.test("Starts with Start")); // 輸出 true
console.log(startsWithPattern.test("Does not start")); // 輸出 false
解法參考
首先我們需要對分隔符來進行解析。我們先寫出其對應的正則表達式,Markdown 中使用?---?(三條及以上的短橫線) 作為分隔符。使用正則表示為:this.hr = /-{3,}/。接著我們判斷是否符合分隔符,并且對其進行轉化函數的編寫。
//是否符合分隔符規范isHr(){return this.hr.test(this.lineText);}//解析分隔符parseHr(){return `<hr>`;}然后在渲染類的?runParser()中編寫對應的渲染處理。這部分我們跟上面提供的代碼的標題函數一樣即可。
// 分割線渲染if (this.parser.isHr()) {hasParsed.push(this.parser.parseHr());currentLine++;continue;}接著我們對引用區塊進行解析,同樣對其進行判斷以及解析。這部分的解析我們分為三個方法,開始標簽,中間p標簽以及結束標簽的解析。
// 解析blockQuote開始標簽parseStartBlockQuote(){return `<blockquote>`;}// 解析blockQuote結束標簽parseEndBlockQuote(){return `</blockquote>`;}接著我們解析中間的文字,我們使用到了split方法來進行獲取到的那一行文字通過>符號來進行分割成字符串數組,如下。接著我們獲取下標為1的元素,并使用trim()用于去除字符串中的空格。最后將這部分獲取到的文字包裹來一個p標簽中。
[ '', ' hello world' ]
[ '', ' 這是區塊引用' ]
[ '', ' 和上面的文字在同一個區塊' ] // 生成blockQuote中的p標簽parseBlockQuoteP(){//split將一個字符串分割成字符串數組const temp = this.lineText.split(">");//trim()用于去除字符串中的空格console.log(temp)const content = temp[1].trim();// console.log(content)return `<p>${content}</p>`;}接下來我們對引用區塊進行渲染,首先若匹配到 < 標簽我們就先為其加上一個塊級的開始標簽,同時也加上中間文字的解析,然后我們通過循環,來對現在的currentLine不斷往下,然后獲取對應的行文本內容,判斷若匹配不到 < 標簽,我們就為其添加一個塊級的結束標簽。
// 塊作用區渲染if (this.parser.isBlockQuote()){hasParsed.push(this.parser.parseStartBlockQuote())while(true){ hasParsed.push(this.parser.parseBlockQuoteP())currentLine++;this.parser.parseLineText(this.getLineText(currentLine));if(!this.parser.isBlockQuote()){hasParsed.push(this.parser.parseEndBlockQuote())break}}continue;}接下來的無序列表進行解析為塊級作用域的解析思路是一樣的。這里就不做過多的解釋。
//是否為無序列表isUnorderedList(){return this.unorderedList.test(this.lineText);}// // 解析unorderedList開始標簽parseStartUnorderedList(){return `<ul>`;}// 解析unorderedList結束標簽parseEndUnorderedList(){return `</ul>`;}// 生成unorderedList中的li標簽parseUnorderedListLi(){//split將一個字符串分割成字符串數組const temp = this.lineText.split(" ");//trim()用于去除字符串中的空格const content = temp[1].trim();// console.log(content)return `<li>${content}</li>`;} //無序列表渲染if (this.parser.isUnorderedList()){hasParsed.push(this.parser.parseStartUnorderedList())while(true){ hasParsed.push(this.parser.parseUnorderedListLi())currentLine++;this.parser.parseLineText(this.getLineText(currentLine));if(!this.parser.isUnorderedList()){hasParsed.push(this.parser.parseEndUnorderedList())break}}continue;}接著我們對圖片進行解析,Markdown 中使用??表示,將其解析成為?<img>?標簽。這部分也比較簡單使用到了slice方法來進行截取對應的圖片的路徑已經alt屬性的值。slice方法我們在第一篇真題講解中有介紹了,可以去看看。
//是否為圖片isImage(){return this.image.test(this.lineText);}// 解析image標簽parseImage(){const src=this.lineText.slice(6,-1);const alt=this.lineText.slice(2,4);return `<img src="${src}" alt="${alt}">`;} //圖片渲染if(this.parser.isImage()){hasParsed.push(this.parser.parseImage());currentLine++;continue;}最后,我們需要對文字效果進行解析,比如粗體效果,和行內代碼塊,將其分別解析成<b>和code標簽。this.strongText 是一個匹配粗體文本的正則表達式。replace 方法會將匹配到的粗體文本替換成函數中返回的內容。參數 match 包含了整個匹配的字符串,而 p1 則是捕獲組中捕獲到的內容,也就是粗體文本的實際內容。若遇到粗體以及代碼塊的標識則解析成對應的格式,否則對正常文字進行正常解析。
//解析文本parseText(){let temp=this.lineText;//若有粗體則對其進行添加標簽temp=temp.replace(this.strongText,(match,p1)=>{return `<b>${p1}</b>`;})//若遇到代碼塊則對其進行添加標簽temp=temp.replace(this.codeLine,(match,p1)=>{return `<code>${p1}</code>`;})return temp;}; //渲染文本hasParsed.push(this.parser.parseText());currentLine++;continue;
好啦!本文就到這里結束了~~~



















