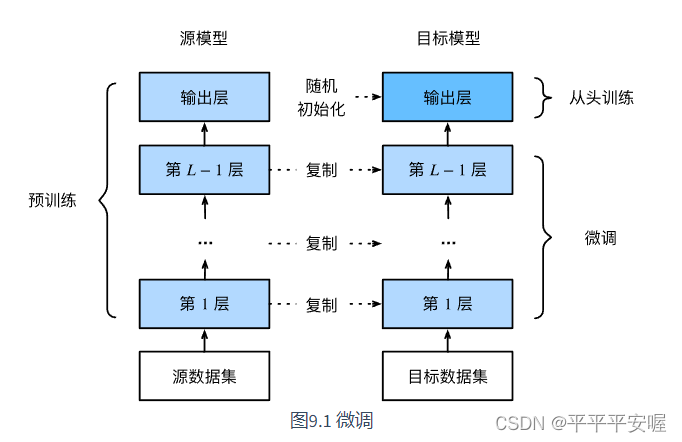
預訓練–微調
一個很簡單的道理,如果我們的模型是再ImageNet下訓練的,那么這個模型一定是會比較復雜的,意思就是這個模型可以識別到很多種類別的即泛化能力很強,但是如果要它精確的識別是否某種類別,它的表現可能就不佳了,因此,我們需要在原來的基礎上再對特定的我們需要識別的類別進行重新訓練,微調原來網絡結構中的參數,此時模型還是可以抽取較通用的圖像特征。
參考自https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter09_computer-vision/9.2_fine-tuning
當目標數據集遠小于源數據集時,微調有助于提升模型的泛化能力。
熱狗識別
源數據集是ImageNet,超過1000萬個圖像和1000類物體,熱狗數據集包含1400個正類圖像和其他多種負類圖像
最開始還是導入所需要的庫以及設置cuda
import torch
from torch import nn,optim
from torch.utils.data import Dataset, DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
import os
import d2lzh_pytorch as d2l
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
下載數據集https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/hotdog.zip
我直接放在了我的默認路徑下,讀數據如下
train_imgs = ImageFolder("hotdog/train")
test_imgs = ImageFolder("hotdog/test")
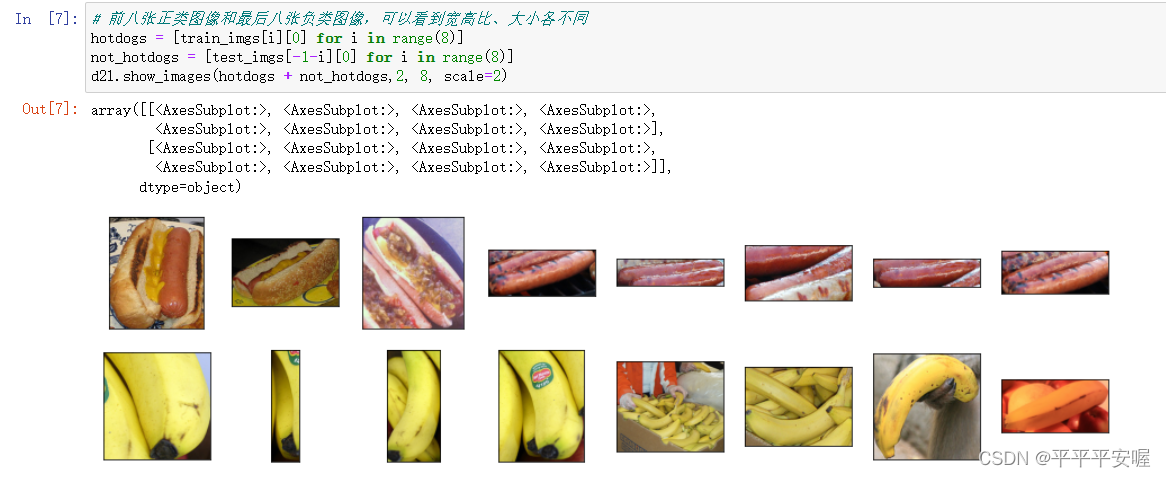
然后我們觀察一下數據集,可以看到大小,寬高比各不同
# 前八張正類圖像和最后八張負類圖像,可以看到寬高比、大小各不同
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [test_imgs[-1-i][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs,2, 8, scale=2)
接下來就是訓練時,我們先從圖像中隨機裁剪一塊區域,然后將該區域縮放成224*224的圖像進行輸入,測試時,我們將圖像的高和寬均縮放為256像素,然后從中裁剪出高、寬均為224的中心區域作為輸入,此外對RGB三通道作標準化,每個數值減去通道的平均值,再除以標準差需要注意的是,在使用預訓練模型時,一定要和預訓練時作同樣的預處理。 如果你使用的是torchvision的models,
那就要求: All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224. The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225].
如果你使用的是pretrained-models.pytorch倉庫,請務必閱讀其README,其中說明了如何預處理。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
train_augs = transforms.Compose([#transforms.Resize(size=256), # 是將最小邊調整到256#transforms.CenterCrop(size=224),transforms.RandomResizedCrop(size=224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize
])test_augs = transforms.Compose([transforms.Resize(size=256),transforms.CenterCrop(size=224),transforms.ToTensor(),normalize
])
需要注意的是,首先我有最開始有兩點疑惑
- 為什么不能需要從圖像中隨機裁剪一塊區域,然后將該區域縮放成224*224的圖像進行輸入。然后我測試了一下,如果不這樣做的話,那么泛化能力會比較差
- 如果非要這么做,那么可不可以直接transforms.Resize(size=224)?不可以的,transforms.Resize(size=224)是把最短的邊變為224,寬高比沒變,那么這樣就會導致圖像的尺寸不一樣,后面自然會報錯,所以需要先transforms.Resize(size=256),然后transforms.CenterCrop(size=224)
之后我們使用在ImageNet上預訓練的ResNet18,pretrained=True,自動下載預訓練參數
不管你是使用的torchvision的models還是pretrained-models.pytorch倉庫,默認都會將預訓練好的模型參數下載到你的home目錄下.torch文件夾。
你可以通過修改環境變量$TORCH_MODEL_ZOO來更改下載目錄
pretrained_net = models.resnet18(pretrained=True)
修改最后一層
pretrained_net.fc = nn.Linear(512, 2)
接下來設置訓練的參數,由于除了最后一層,之前的參數都經過預訓練,所以我們學習率調小一點,最后的fc層是初始化過的,于是我們學習率調大一點
output_params = list(map(id, pretrained_net.fc.parameters())) # fc層
feature_params = filter(lambda p: id(p) not in output_params, pretrained_net.parameters()) # 除了fc層
lr = 0.01 # 用來更新特征層
# fc層是lr * 10
optimizer = optim.SGD([{"params":feature_params},{"params":pretrained_net.fc.parameters(), "lr":lr*10}
] ,lr = lr, weight_decay=0.001)
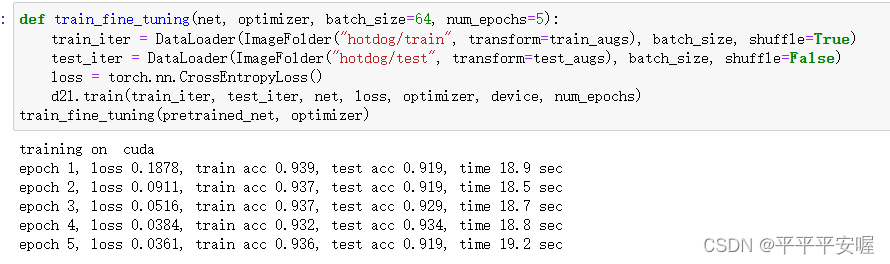
在之后就是訓練了
def train_fine_tuning(net, optimizer, batch_size=64, num_epochs=5):train_iter = DataLoader(ImageFolder("hotdog/train", transform=train_augs), batch_size, shuffle=True)test_iter = DataLoader(ImageFolder("hotdog/test", transform=test_augs), batch_size, shuffle=False)loss = torch.nn.CrossEntropyLoss()d2l.train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
train_fine_tuning(pretrained_net, optimizer)







)





真題解析)




-Part.17 安裝Spark2)
)