論文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun
鏈接:https://arxiv.org/abs/1312.6229
文章目錄
- 1、算法概述
- 2、OverFeat細節
- 2.1 分類
- 2.2 定位
- 3、創新點
1、算法概述
OverFeat算法同時實現圖像分類、定位及檢測任務,也證明了采用一個網絡同時做三種任務可以提高分類、定位、檢測的準確率。文章介紹了一種通過累積預測邊界框來定位和檢測的方法。通過結合許多定位預測,可以在沒有背景樣本訓練的情況下進行檢測任務,不進行背景訓練也可以讓網絡只關注正面類,以獲得更高的準確性。文中報道的結果是基于ILSVRC2013的,分類報道TOP5(分類概率前5個包含groundTruth就算正確);定位也是報道TOP5但是需加上TOP5各自對應目標的bounding box預測且bounding box與groundTruth矩形框標注的iou大于50%才能算bounding box預測正確;檢測任務就需要預測圖像中的每個目標了(類別加定位,包括背景類)并以mAP的指標報道結果。
2、OverFeat細節
2.1 分類
OverFeat仿照AlexNet設計,但是對網絡結構和推理步驟進行了改進;文中分類網絡分為兩種:速度和精度,結構如下:

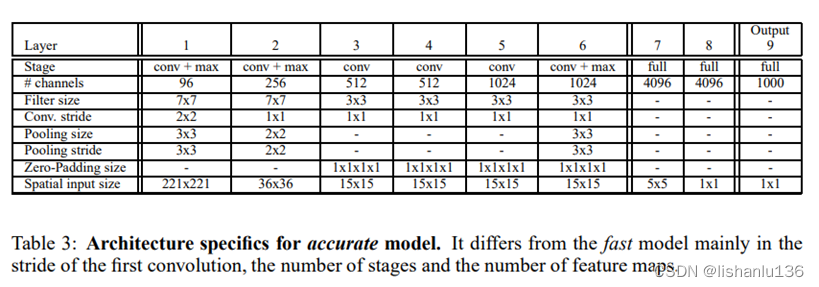
相對于AlexNet,它沒有采用對比度歸一化,沒有用帶重疊的池化層,網絡前兩層使用了小的stride從而保留了比較大的特征圖,因為大的stride雖然能快速減小特征圖從而對網絡推理提速但是對精度有損害。最終精度模型比速度模型的TOP5錯誤率少了2.21%(14.18%對16.39%)。
- 多尺度分類
AlexNet中,應用了多視角(multi-view)投票技術用來提升最后預測類別的精度,即通過4次corner_crop加一次center_crop,同時應用水平翻轉共計10次分類結果來投票出最終的類別;然而這種方式還是忽略了大量圖片區域,也在圖片重疊區域存在計算冗余,此外,這種方式也只是圖片的單一尺度,不一定是卷積神經網絡最合適的推理尺度。所以作者采用了6種不同尺度的測試圖像作為輸入(每個尺度圖像還增加了水平翻轉),而且作者認為在特征提取最后一層(conv 5)直接做 max pooling,將導致最終輸入圖像的檢測粒度不足,提出用偏移池化(offset pooling)操作實現讓分類器的視角窗口在特征圖上滑動,最終將偏移池化得到的特征圖組合在一起輸出結果。如下表、下圖所示:
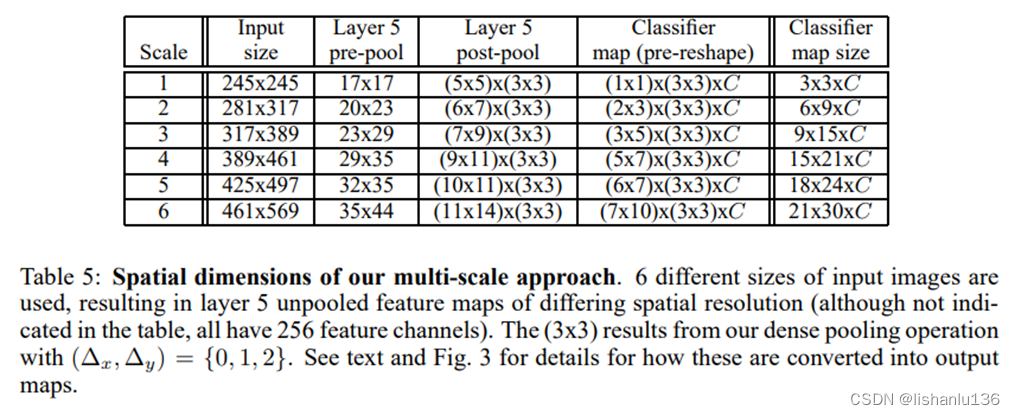
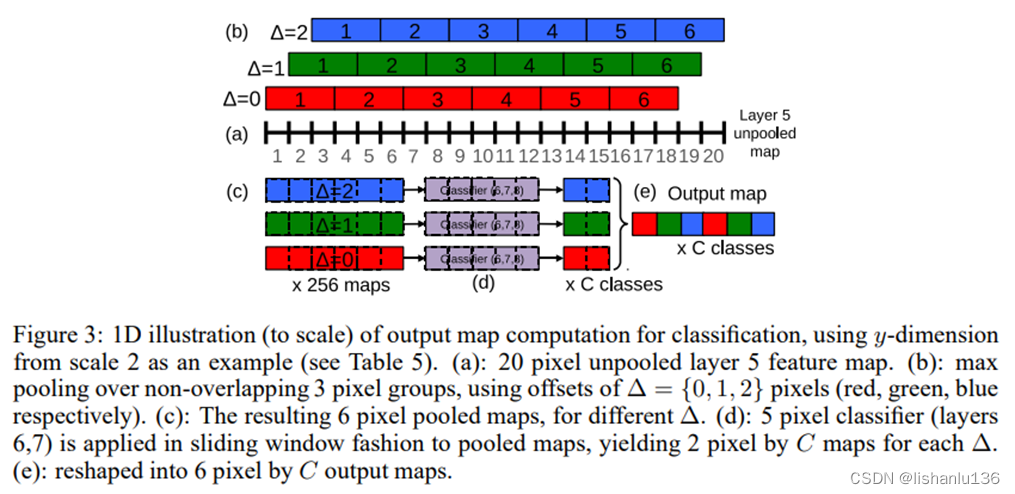
- 卷積和高效的滑窗
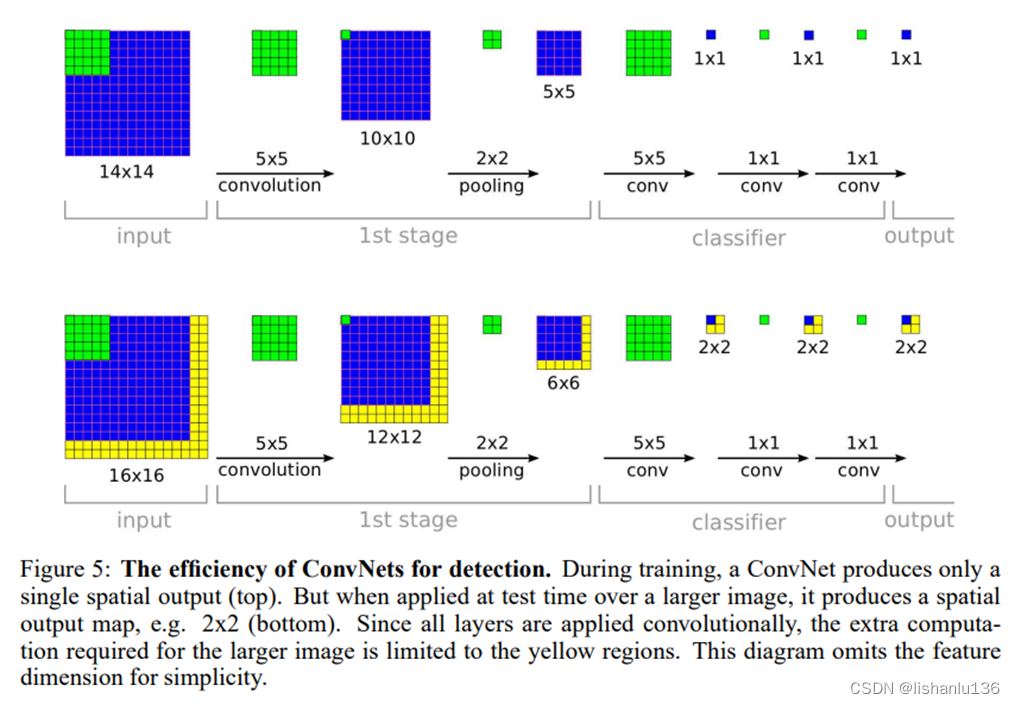
在此之前,很多滑動窗口技術都是為每個窗口重復進行所有的計算,這對計算資源的消耗是巨大的。而卷積天然就帶有滑窗的方式,如下圖所示,因為卷積操作是共享卷積核滑動操作,所以計算非常高效,作者最后在測試階段,將最后的全連接層替換成了1x1卷積層,這樣就能適應比訓練圖像大的圖片測試了。
2.2 定位
由分類到定位,基于之前的分類網絡,把網絡的分類器替換成回歸器,訓練這個網絡預測每個位置和尺度的物體邊界框,就可以實現定位任務。回歸器也取網絡的前5層的feature map輸出作為bounding box的輸入,該feature map也用作分類器訓練,所以分類器和回歸器共用前面的特征。回歸器的輸出是4個值,代表bounding box的坐標,每個類都有對應的bounding box預測。訓練回歸器時,前5層不參與訓練;如果樣本和真實標簽的重疊小于50%,則樣本不參與回歸器的訓練。(由于樣本預處理和增強的原因,可能導致樣本的范圍和真實標簽已經重疊較小)。下面看看定位/檢測具體的工作步驟:




3、創新點
采用multiscale、sliding window、offset pooling實現多尺度滑窗采樣,基于卷積高效實現滑窗思想,在同一網絡框架下實現分類、定位、檢測。


)





真題解析)




-Part.17 安裝Spark2)
)




