這篇是我對嗶哩嗶哩up主 @霹靂吧啦Wz 的視頻的文字版學習筆記 感謝他對知識的分享
本節課我們來講一下如何在pytouch當中去使用我們的tensorboard
對我們的訓練過程進行一個可視化
左邊有一個visualizing?models?data?and?training?with?tensorboard
主要是這么一個教程
那么這里我想問一下大家
平時你們在使用tensorboard的時候
主要會去使用它的哪些功能
反正在我個人使用當中呢
我主要會使用其中的四個功能
第一個就是去保存一下網絡的一個結構圖

比如說在我們tensorboard的graphs當中
會有我們模型的一個結構圖
然后這個圖當中呢其實就能夠比較清晰地看到我們整個模型
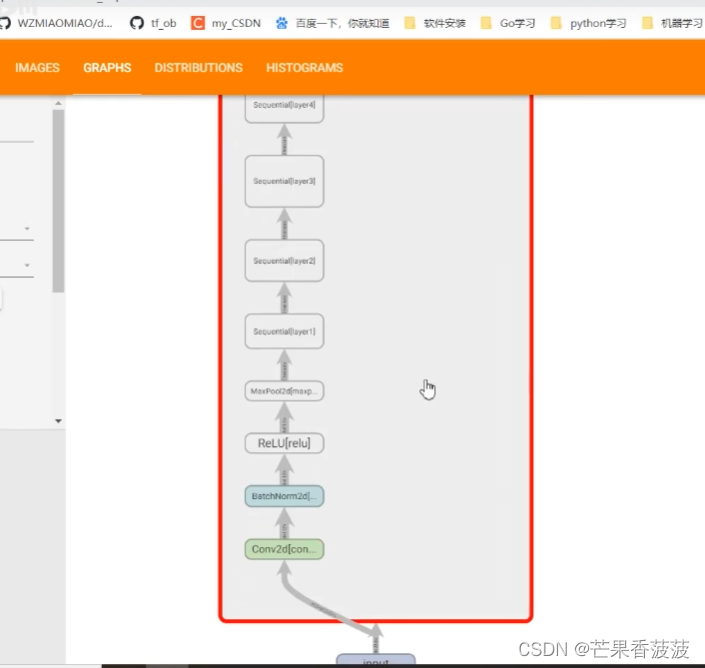
它的搭建的每一個模塊
第二個呢就是保存我們在訓練過程當中
訓練集它的一個損失loss?還有驗證集的accuracy?還有我們的學習率變化等等
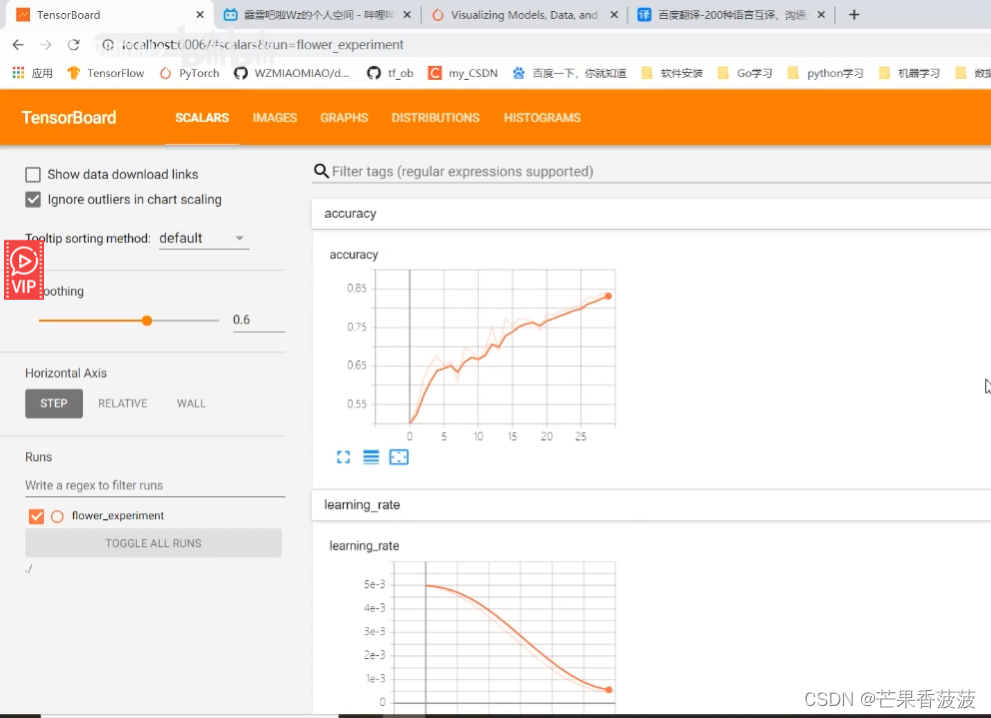
在我們的scalars當中

那么這里呢就比如說我們這里有tracy
還有我們的learning?rate
還有我們的train?loss
那么第三個就是保存權重數值
它的一個分布在tensorboard當中的histogram當中
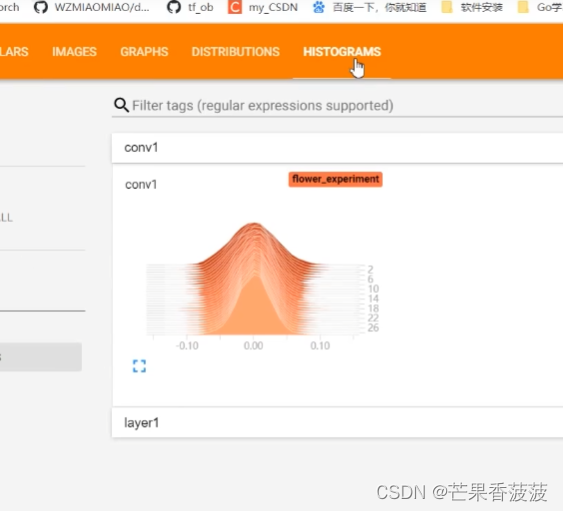
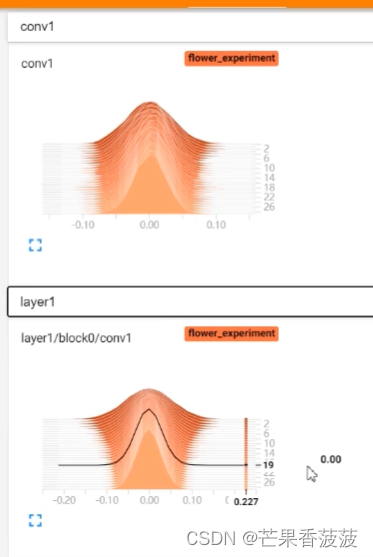
在這個里面呢一般就是保存我們每一個層結構
它的一個權重的數值的一個分布
那么最后一個呢就是保存我們預測圖片的一些信息
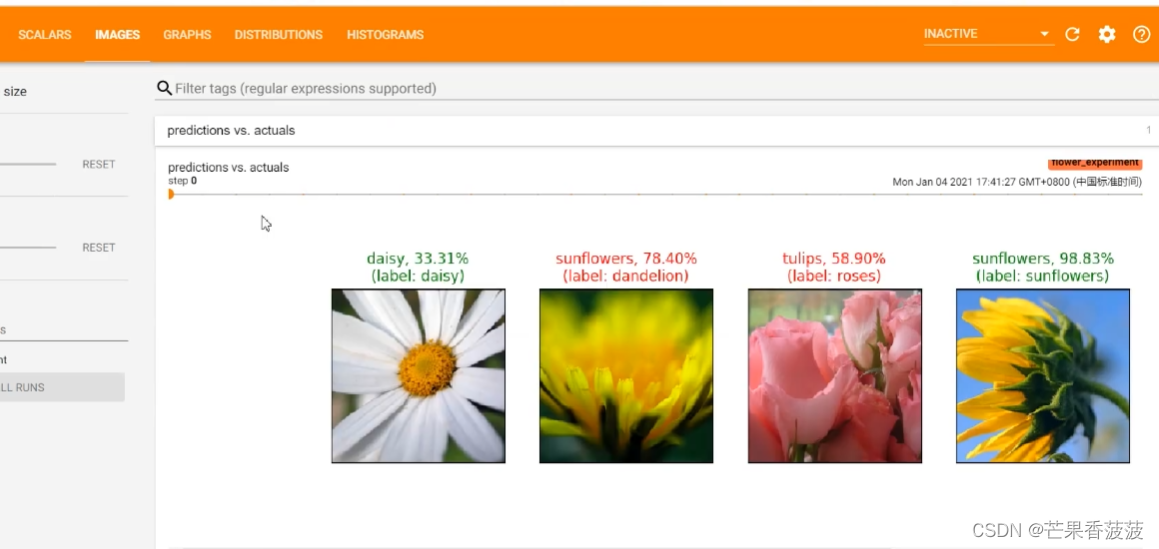
就比如說在我們的image當中保存有我們訓練的每一個step對于我們給定的一些圖片
它的一個預測的一個結果
首先我們這里需要建一個文件夾
叫做plot?image
那么在這個文件夾當中呢
我們所保存的圖片是我們待會兒在訓練過程當中
會對我們的這些圖片進行預測

由于本節課訓練是以我們之前的花分類數據集為例
所以呢我們這里需要先提前準備好我們的花分類數據集
我這里有給下載花分類數據集的一個地址

下載完之后呢
我們這里的image?root就指向我們解壓之后文件夾它的一個路徑
那么準備好我們的數據集之后呢
接下來就是關于預訓練權重了
那么這里也是根據你個人的需求來進行選擇了
如果你是需要去使用它的預訓練權重的話
你就在這個pytorch官方的這個地址上去下載這個權重文件
然后將這里的defaul指向你剛剛下載這個權重路徑就可以了
那如果你不去指認的話
那么它默認的就是不去使用任何預訓練權重了
那么本教程其實是沒有去使用這個預訓練權重的
因為如果你使用了預訓練權重之后呢
你會發現它的accuracy?loss基本上是沒有變化的
因為在你訓練的第一個epoch
它的準確率就已經達到97%了
所以基本看不出有什么變化
這里我不去使用預訓練權重
就可以看到它的loss變化以及accuracy變化
那么這個參數freeze?layers

就是說是否去凍結我們的除全連接層以外的所有網絡結構啊
這里默認是false
就是不去凍結
如果你設置為true的話
它就會去單獨訓練最后這個全連接層
之前的權重是不會去訓練的
那么如果你使用這個預訓練權重的話
你可以將這里設置為true
可以加快模型的訓練
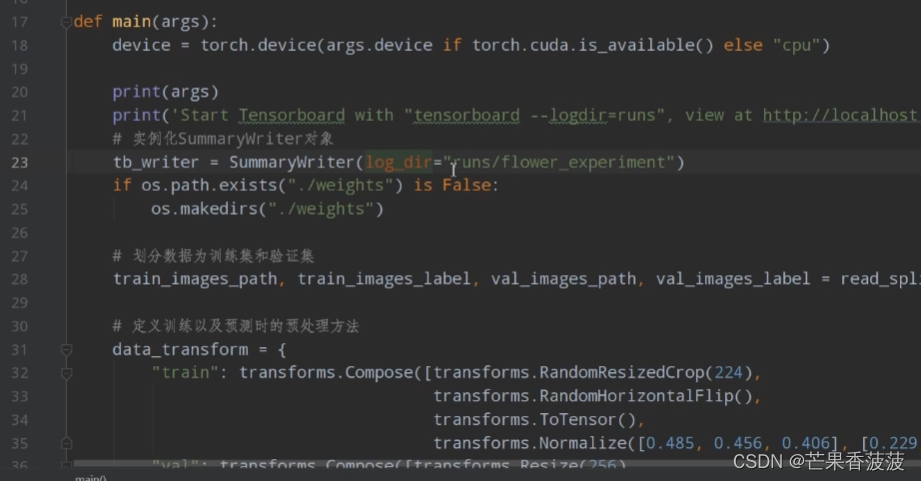
首先我們這里的summary?writer
它是來自于touch?utils的tensorboard的模塊當中導入進來的

所以我們這里先實例化我們的tensorboard對象

這里我們需要插入這個參數呢
就是說我們將我們的tensorboard的文件保存在哪里
我這里就是保存在當前項目目錄下的runs
然后flower?experiment這個文件夾當中
那么當我們實例化之后呢
它就會在我們當前項目想創建一個runs這個文件
然后會將我們對應的tbd文件保存在flower?experiment當中

實例化我們的tensorboard對象之后呢
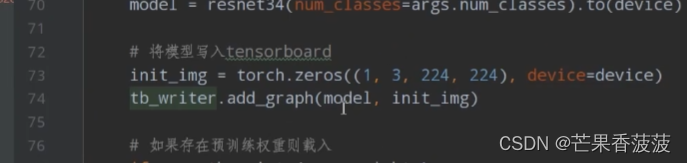
這里有去添加我們網絡的一個結構圖
在我們實例化我們的模型之后呢
緊接著在這里我創建了一個initial?image
它就是一個零矩陣了
這里為什么要去創建一個initial?image呢
因為在我們添加這個graph的時候
我們是需要將我們這個initial?image傳入到我們的模型當中
讓它進行一個這樣傳播
然后會根據我們輸入的數據
在模型中正向傳播的一個流程來創建我們的網絡結構圖
所以我們這里傳入的數據只要和我們的圖片大小相同就可以了

所以呢我這里就有創建一個initial?image
那么我們通過我們實例化的tensorboard
它的add?graph這個函數項目的模型
以及我們初始的一個圖片傳入進去就ok了
 在我們的這個位置有使用到add?scaler
在我們的這個位置有使用到add?scaler
那么這里呢其實就是在我們訓練的每個epoch之后
也就是在我們驗證完我們的模型之后
我們會去保存一下我們當前這一輪訓練的訓練集的平均損失loss
還有我們驗證集的accuracy
以及我們的learning?rate

我們傳入有這五個變量
第一個那就是我們實例化的模型
第二個image
第二對應的就是我們剛剛這個plot?image它的一個根目錄
第三個transform對應著我們驗證集所使用的一個圖像預處理
第四個參數對應就是我們總共要展示多少張圖片
第五參數就是我們說使用的device信息
然后接下來我們再往下走就到了我們這里的add?figure
也就是添加我們預測plot?image文件夾下這幾張圖片

第一個是我們這張圖片它的一個名稱
它的一個標題
然后第二個參數對應的就是figure這個對象
第三個global?step朋友們是通過epoch來指定的
首先在我們訓練過程當中呢
我們會去生成一個json文件
這個json文件保存的就是我們類別索引
以及它的一個名稱的一個對應關系


那么這里呢只要是正常訓練的話
就會生成它
那如果它不存在的話
就說明訓練過程是有問題的
那么這里就會報出一個錯誤
就是沒有找到這個文件
然后接下來我們就會讀取這個文件

我們通過touch?stack方法將我們的images
也就是我們剛剛所保存的一個圖片的列表進行一個拼接
拼接成一個batch
那么這里大家需要注意的是
我們的stack方法會對我們的數據增加一個新的維度
那么通過我們剛才預處理之后
其實我們的每一個圖片就變成了一個tensor的格式
它的shape就是3x224x224
那么這里呢我們會在它的最前面新增一個維度
那么就變成了拼接之后呢
它就變成了batch?x?3x224x224
我已經將我之前訓練好的結果保存在對應的文件夾下面了
那么接下來我們就來打開tenor?board來看一下
那么首先進入我們的項目根目錄
然后呢進入我們的runs文件

然后打開終端
打開終端之后呢
然后就輸入tensorboard
然后logdir
然后就輸入當前路徑就可以了

然后接下來大家需要注意的是
我們還需要再加上一個參數啊
就是這個samples?per?plugin
然后在這個參數當中
我們需要指定一下我們所展示圖片的一個數目
如果我們不指定這個參數的話
它默認會去采樣十張圖片
因為在我這個訓練過程當中呢
如果按照默認參數來的話
只能看到十張
所以我這里會加上這么一個參數
指定為50之后呢
它就會展示所有的圖片了
那么回車之后呢
終端就提示我們在local?host?端口可以看到
那么我們就進入瀏覽器
輸入local?host?6006回車
然后就可以看到我們訓練過程當中保存了一系列的數據了
那么在這個blog當中
我們可以看到我們那個數據的流向
就是根據這個箭頭可以判斷出數據的流向
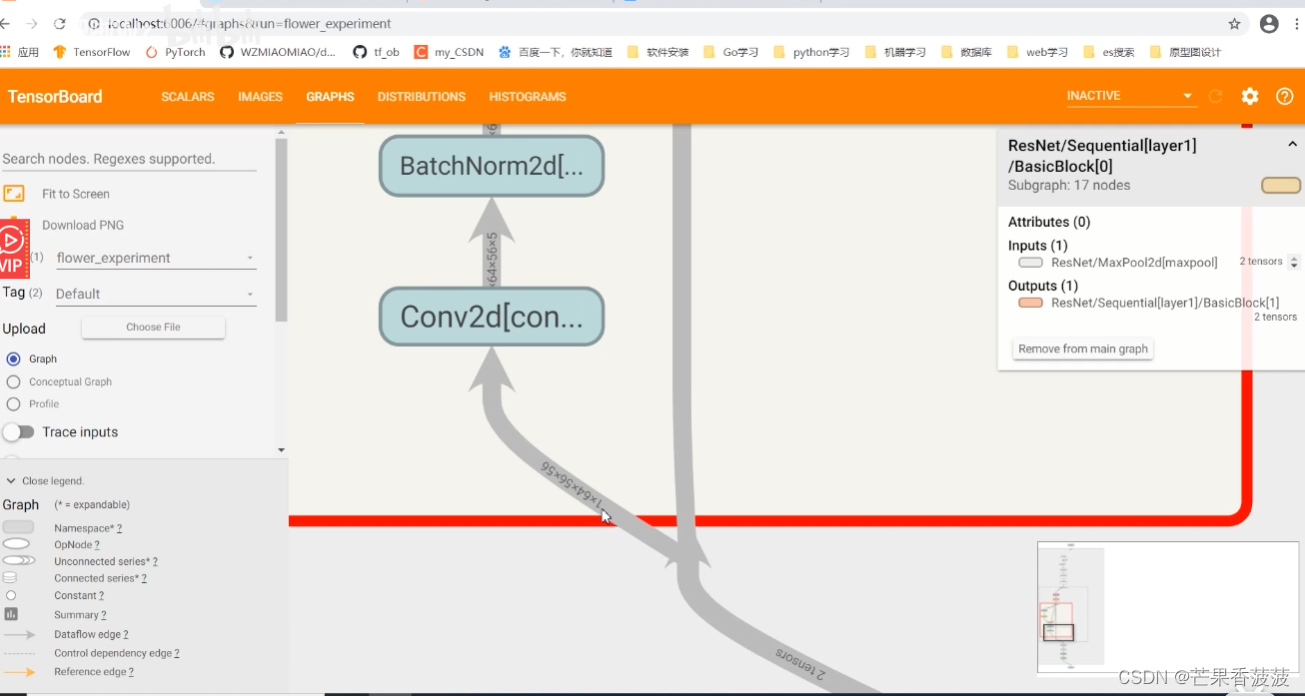
我們的初始化方法中只定義了一個relu
也就是說我們在我們主干分支當中所使用的這個relu結構
與我們主干分支與捷徑分支相加之后所經過的機函的relu是同一個
所以這里會有一個往回流的一個箭頭
然后經過relu之后呢
它就會輸入到下一個模塊當中
如果你想為了這個圖看起來更好看的話
其實你可以在定義block的時候
定義兩個relu
主分支上使用主分支這個relu
然后相加之后再使用另外一個relu
這樣的話就不會出現像我們這個箭頭往回指的這個情況





SpringBoot實現雪花算法id注冊功能)
聊天)









)


