我們都知道在大多數情況下,語言模型的體量和其推理能力之間存在著正相關的關系:模型越大,其處理復雜任務的能力往往越強。
然而,這并不意味著小型模型就永遠無法展現出色的推理性能。最近,奶茶發現了微軟的Orca2公開了論文,它詳細探討了如何提升小型大語言模型的推理能力,這樣的研究無疑是在資源有限或對模型大小有特定要求的場景的重大進步。接下來,讓我們一起來了解這篇論文的詳細工作吧!
論文題目:
Orca 2: Teaching Small Language Models How to Reason
論文鏈接:
https://arxiv.org/pdf/2311.11045.pdf
在研究團隊之前發布的Orca1中,通過使用解釋跟蹤這類更豐富的信號訓練模型,已經超過了傳統指令調優模型在BigBench Hard和AGIEval基準測試中的表現。
大模型研究測試傳送門
GPT-4傳送門(免墻,可直接測試,遇瀏覽器警告點高級/繼續訪問即可):
http://hujiaoai.cn
在Orca2中,研究團隊繼續探索了改進訓練信號來增強小型的大語言模型的推理能力。實驗結果證明過度依賴模仿學習(即復制更強大模型的輸出)可能會限制小模型的潛力。
Orca 2的目標是教會小模型如逐步處理、回憶-生成、回憶-推理-生成、提取-生成和直接回答這些推理技巧,并幫助這些模型決定何時使用最有效的推理策略,研究團隊稱這種方法為“謹慎推理”(Cautious Reasoning),旨在根據任務選擇最佳解決策略。Orca 2模型在15個不同的基準測試(包括約100個任務和超過36000個獨特提示)上進行了評估,表現顯著超過同等大小的模型,并達到或超過了體量為其5-10倍的模型的性能水平。
調優方法
研究團隊采用了 “指令調優”(instruction tuning)和“解釋調優”(explanation tuning) 的方法。
指令調優
指令調優(Instruction Tuning)是訓練的關鍵步驟,涉及從自然語言任務描述和期望行為示范的輸入-輸出對中學習。輸入的是任務的描述,輸出是期望的行為的演示,通過過自然語言任務描述(輸入)和所需行為的演示(輸出)來學習。這種方法在模仿“教師”模型的風格方面非常有效,然而,研究也表明,在對知識密集或推理密集型任務進行評估時,這種方法容易僅復制“風格”,忽視答案的正確性。
解釋調優
針對指令調優的問題,研究團隊引入了解釋調優(Explanation Tuning),使它們能夠從教師模型那里獲取更豐富、更有表現力的推理信號。這些信號是基于系統指令提取的,旨在從強大的LLM(如GPT-4)中提取“慢思考”(Slow Thinking)的豐富示范。通過系統指令獲得詳細解釋來訓練學生模型,目的是提取豐富的、更具表現力的推理信號。
解釋調優開始于編制N個通用系統指令,使模型進行更謹慎的推理,例如“逐步思考”和“生成詳細答案”。接下來,這些指令與廣泛且多樣化的用戶提示結合,形成一個包含(系統指令,用戶提示,LLM答案)的三元組數據集。
學生模型被訓練以根據系統指令和用戶提示來預測LLM的答案。如果用戶提示可以被分為M個不同的類別,這些類別代表了不同類型的問題,解釋調優就會生成M×N個不同的答案組合,從而增加訓練數據的數量和多樣性。

實驗設計
數據集構建
Orca 2數據集有四個主要來源,包括FLAN-v2集合的各個子集合。這些子集合包含多個任務,總共1913個任務。從這些任務中選擇了約包含23個類別的602K個零樣本的用戶查詢,用來構建Cautious-Reasoning-FLAN數據集。
訓練目標
Orca 2模型的訓練起始于LLaMA-2-7B或LLaMA-2-13B的檢查點,首先對FLAN-v2數據集進行了精細的微調處理。隨后,模型在Orca 1提供的500萬條ChatGPT數據上進行了為期3個周期的訓練,繼而在Orca 1和Orca 2共計110萬條GPT-4數據和817千條數據上進行了4個周期的深入訓練。在這一過程中采用了LLaMA的字節對編碼(BPE)分詞器來處理輸入樣本,并運用了打包技術,不僅提高了訓練過程的效率,也確保了計算資源的高效利用。
基線模型
在基準測試中,Orca 2與多個最新的模型進行比較,包括LLaMA-2模型系列和WizardLM。
實驗
在實驗中,Orca 2與多個最新的模型進行了基準測試,包括LLaMA-2模型、WizardLM和GPT模型。這些測試涉及到各種任務,以評估Orca 2在開放式生成、摘要、安全性、偏見、推理和理解能力方面的性能。其中,實驗室提到了Orca-2-13B和Orca-2-7B兩個模型,是Orca 2項目中公開的語言模型,區別是模型的參數量。
被選中的基準測試包括:
-
AGIEval:包括一系列標準化考試,如GRE、GMAT、SAT、LSAT、律師資格考試、數學競賽和國家公務員考試等。
-
DROP:一個需要模型執行諸如加法或排序等離散操作的閱讀理解基準測試。
-
CRASS:評估LLM的反事實推理能力的數據集。
-
RACE:從中國學生英語考試中提取的閱讀理解問題集合。
-
BBH (Big-Bench Hard):BIG-Bench的23個最難任務的子集。
-
GSM8K:測試多步驟數學推理能力的單詞問題集合。
-
MMLU:衡量模型語言理解、知識和推理能力的基準測試,包含57個任務。
-
ARC:AI2推理挑戰,是一個測試文本模型回答科學考試多項選擇題的基準測試,分為“簡單”和“挑戰”兩個子集。
除了上述基準測試外,還進行了針對文本完成、多輪開放式對話、歸納和抽象性摘要、安全性和真實性的評估。

推理能力
Orca 2在多種推理基準上的平均表現顯示了其顯著的推理能力。特別是在AGI Eval、BigBench-Hard (BBH)、DROP、RACE、GSM8K和CRASS測試中,Orca 2的表現超過了同等大小的其他模型。在更大的模型間的比較中,Orca 2-13B的表現與更大的LLaMA-2-Chat-70B相當,并與WizardLM-70B相比較為接近。

知識與語言理解
在MMLU、ARC-Easy和ARC-Challenge任務中,Orca 2-13B的表現超過了同等大小的LLaMA-2-Chat-13B和WizardLM-13B。在MMLU基準上,Orca 2-13B與更大的LLaMA-2-Chat-70B和WizardLM-70B的表現相似。

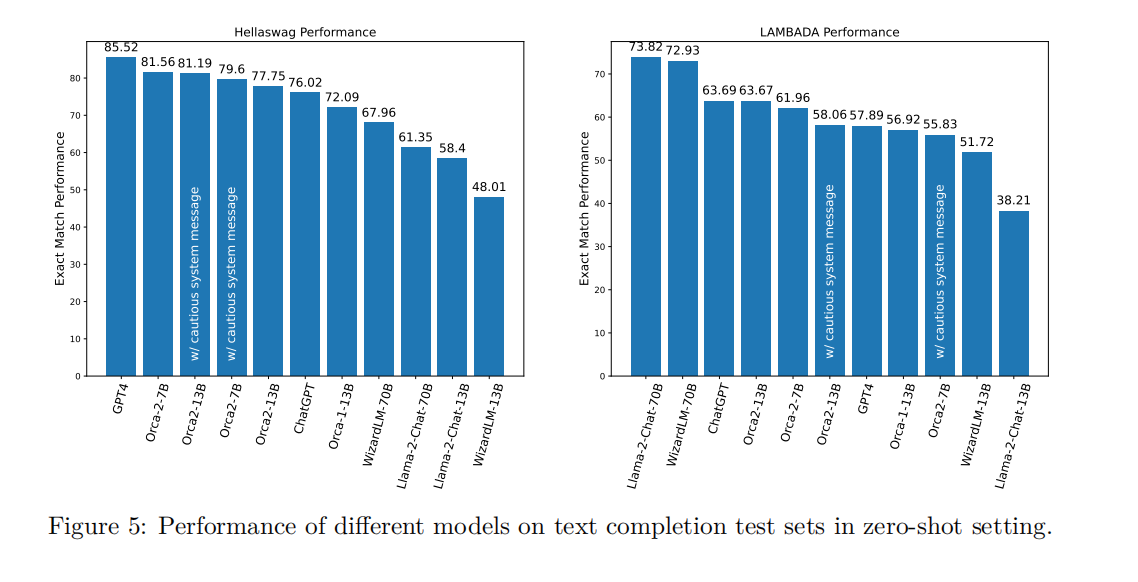
文本完整度
在HellaSwag和LAMBADA測試中,Orca 2-7B和Orca 2-13B均展現出較強的文本完成能力,特別是在HellaSwag測試中表現超過了13B和70B的基準模型。
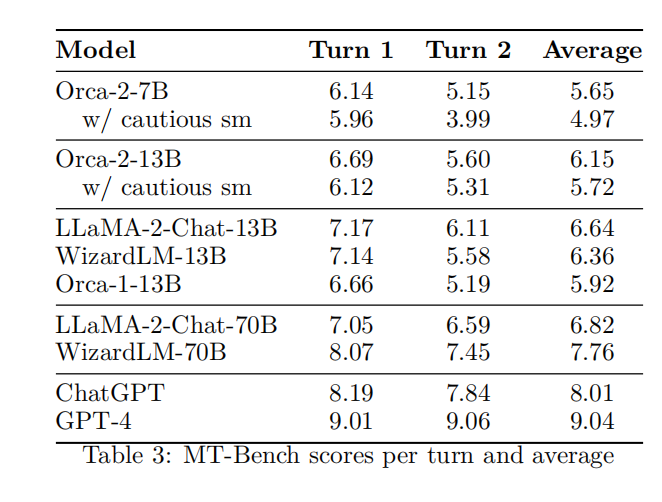
多輪開放式對話
在MT-Bench數據集上,Orca 2-13B與其他13B模型的表現相當。這表明Orca 2具有參與多輪對話的能力,盡管其訓練數據中缺少對話內容。
基于對話的概括和抽象概括
在三個不同的任務中,Orca 2-13B展現了最低的虛構信息生成率,相較于其他Orca 2變體以及其他13B和70B的LLM模型。

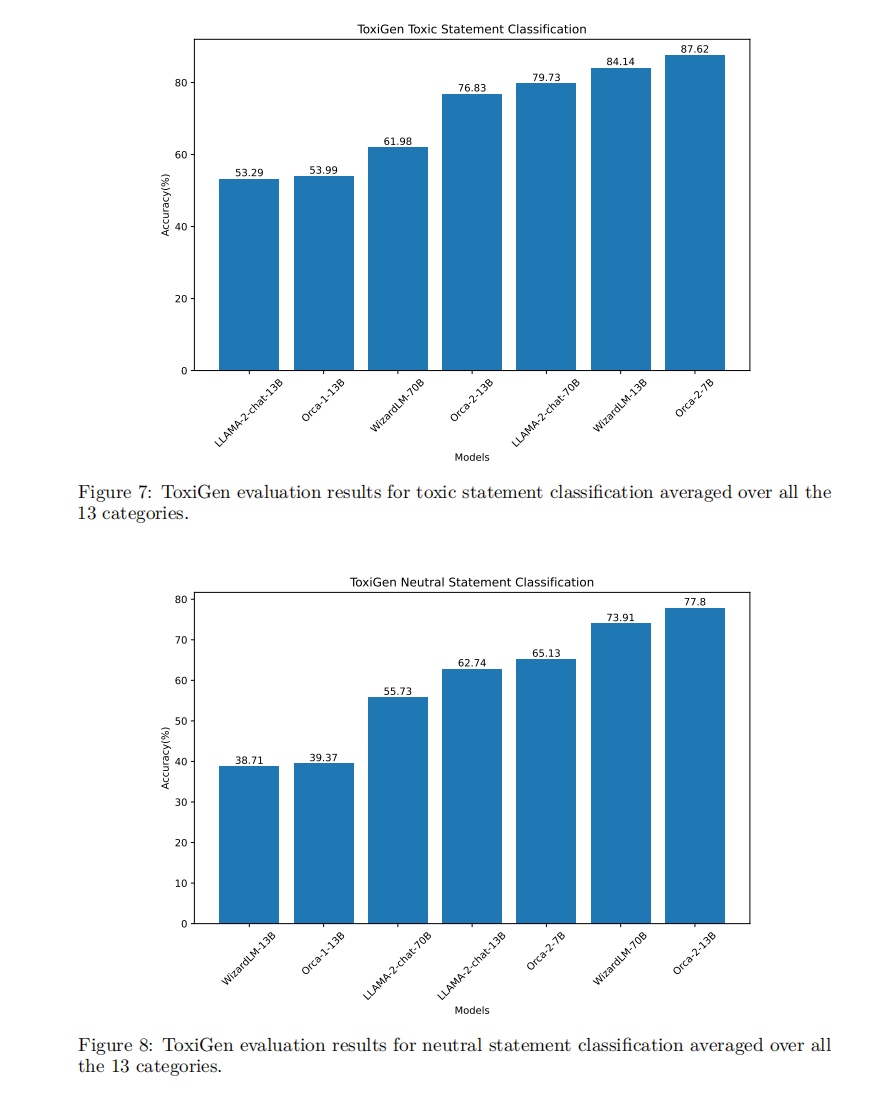
安全性和真實性
在ToxiGen、HHH和TruthfulQA等數據集上的安全性評估顯示,Orca 2在識別有毒聲明和中性聲明方面的表現與其他大小相當的模型相比具有一定的優勢。
Orca 2模型在所進行的基準測試中整體表現卓越,明顯超越了同等規模的其他模型,并能與其體量為5至10倍的模型相抗衡。特別是在零樣本推理任務上,Orca-2-13B的成績顯著高于同類模型,相較于LLaMA-2-Chat-13B和WizardLM-13B,分別取得了47.54%和28.15%的相對提升。這一成績凸顯了Orca 2訓練流程的高效性。這些成果展示了即使在較小規模的大語言模型中,通過精細的訓練方法也能達到優異的推理能力。Orca 2在推理任務上的表現不僅在同等規模模型中脫穎而出,而且在某些場合甚至可與大型的模型匹敵,這對小型模型的進步和發展具有重要的啟示意義。
模型的限制
在論文的第7部分,作者們討論了Orca 2模型的一些限制。這些限制不僅包括基于LLaMA 2模型家族的Orca 2所繼承的限制,還包括大型語言模型和Orca 2特定訓練過程中的通用限制:
1.數據偏見:基于大量數據訓練的大語言模型可能無意中承載了源數據中的偏見。導致偏見或不公平的輸出。
2.缺乏透明度:由于復雜性和規模,大語言模型表現得像“黑盒子”,難以理解特定輸出或決策背后的邏輯。
3.內容傷害:大語言模型可能造成各種類型的內容傷害,建議利用不同公司和機構提供的各種內容審查服務。
4.幻覺現象:作者建議要意識到并謹慎地避免完全依賴于語言模型進行關鍵決策或信息,因為目前還不清楚如何防止這些模型編造內容。
5.濫用潛力:如果沒有適當的保護措施,這些模型可能被惡意用于生成虛假信息或有害內容。
6.數據分布:Orca 2的性能可能與調優數據的分布密切相關。這種相關性可能會限制模型在訓練數據集中代表性不足的領域(如數學和編碼)的準確性。
7.系統信息:Orca 2根據系統指令的不同表現出性能的變化。此外,模型大小引入的隨機性可能導致對不同系統指令產生非確定性響應。
8.零樣本設置:Orca 2主要在模擬零樣本設置的數據上進行訓練。雖然模型在零樣本設置中表現非常強勁,但與其他更大模型相比,它并沒有展現出使用少樣本學習的同等增益。
10.合成數據:由于Orca 2是在合成數據上訓練的,它可能繼承了用于數據生成的模型和方法的優勢和缺點。作者認為Orca 2受益于訓練過程中納入的安全措施和Azure OpenAI API中的安全護欄(如內容過濾器)。然而,需要更詳細的研究來更好地量化這些風險。
11.小型模型容量:訓練后的小型模型,雖然在教會模型解決任務方面大有裨益,但并不一定會教會模型新知識。因此,訓練后的模型主要受限于預訓練期間學到的知識。













十九 漫水填充)






