檢索增強生成 (RAG) 定義
檢索增強生成 (RAG) 是一種利用來自私有或專有數據源的信息來補充文本生成的技術。 它將旨在搜索大型數據集或知識庫的檢索模型與大型語言模型 (LLM) 等生成模型相結合,后者獲取該信息并生成可讀的文本響應。
檢索增強生成可以通過添加來自其他數據源的上下文并通過培訓補充 LLMs 的原始知識庫來提高搜索體驗的相關性。 這增強了大型語言模型的輸出,而無需重新訓練模型。 其他信息來源的范圍包括 LLM 未受過培訓的互聯網上的新信息、專有業務背景或屬于企業的機密內部文件。
RAG 對于問答和內容生成等任務很有價值,因為它使生成式 AI系統能夠使用外部信息源來生成更準確和上下文感知的響應。 它實現搜索檢索方法(通常是語義搜索或混合搜索)來響應用戶意圖并提供更相關的結果。
那么,什么是信息檢索呢?
信息檢索(information retrieval - IR)是指從知識源或數據集中搜索和提取相關信息的過程。 這很像使用搜索引擎在互聯網上查找信息。 你輸入查詢,系統會檢索并向你顯示最有可能包含你正在查找的信息的文檔或網頁。
信息檢索涉及對大型數據集進行有效索引和搜索的技術; 這使得人們更容易從大量可用數據中訪問他們需要的特定信息。 除了網絡搜索引擎之外,IR 系統還經常用于數字圖書館、文檔管理系統和各種信息訪問應用程序。
AI 語言模型的演變

多年來,人工智能語言模型已經發生了顯著的發展:
- 在 20 世紀 50 年代和 1960 年代,該領域還處于起步階段,基本的基于規則的系統對語言的理解有限。
- 20 世紀 70 年代和 80 年代引入了專家系統:這些系統編碼了人類解決問題的知識,但語言能力非常有限。
- 20 世紀 90 年代見證了統計方法的興起,這些方法使用數據驅動的方法來完成語言任務。
- 到 2000 年代,支持向量機(在高維空間中對不同類型的文本數據進行分類)等機器學習技術已經出現,盡管深度學習仍處于早期階段。
- 2010 年代標志著深度學習的重大轉變。 Transformer 架構通過使用注意力機制改變了自然語言處理,這使得模型在處理輸入序列時能夠關注輸入序列的不同部分。
如今,Transformer 模型處理數據的方式可以通過預測單詞序列中接下來出現的單詞來模擬人類語音。 這些模型徹底改變了該領域,并導致了 LLM 的興起,例如谷歌的 BERT(來自 Transformers 的雙向編碼器表示)。
我們看到大量預訓練模型和專為特定任務設計的專用模型的組合。 RAG 等模型繼續受到關注,將生成式 AI 語言模型的范圍擴展到標準訓練的限制之外。 2022 年,OpenAI 推出了 ChatGPT,這可以說是最著名的基于 Transformer 架構的 LLM。 它的競爭對手包括基于聊天的基礎模型,例如 Google Bard 和微軟的 Bing Chat。 Meta 的 LLaMa 2 不是消費者聊天機器人,而是開源 LLM,熟悉 LLM 工作原理的研究人員可以免費使用。
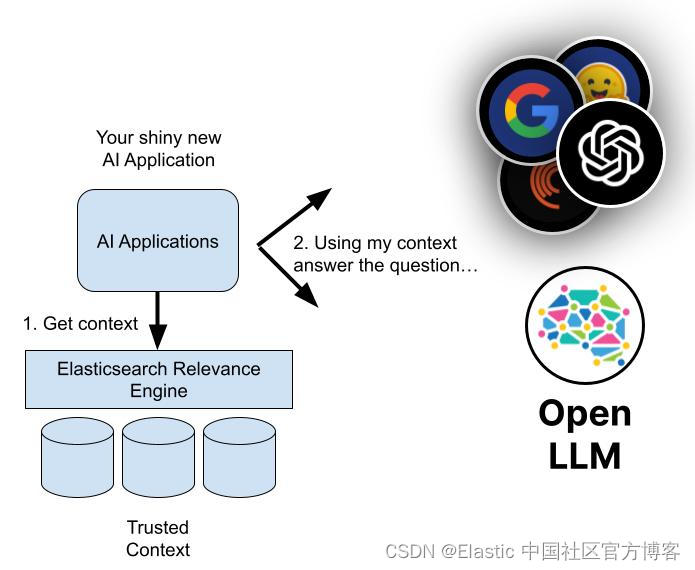
檢索增強生成如何工作?
檢索增強生成是一個多步驟過程,從檢索開始,然后導致生成。 下面是它的工作原理:
檢索
- RAG 以輸入查詢開始。 這可能是用戶的問題或任何需要詳細響應的文本。
- 檢索模型從知識庫、數據庫或外部源(或同時從多個源)獲取相關信息。 模型搜索的位置取決于輸入查詢的要求。 現在,檢索到的信息可作為模型所需的任何事實和上下文的參考源。
- 檢索到的信息被轉換為高維空間中的向量。 這些知識向量存儲在向量數據庫中。
- 檢索模型根據檢索到的信息與輸入查詢的相關性對檢索到的信息進行排名。 選擇得分最高的文檔或段落進行進一步處理。
生成
- 接下來,生成模型(例如 LLM)使用檢索到的信息生成文本響應。
- 生成的文本可能會經過額外的后處理步驟,以確保其語法正確且連貫。
- 總體而言,這些響應更準確,并且在上下文中更有意義,因為它們是由檢索模型提供的補充信息塑造的。 這種能力在公共互聯網數據不足的專業領域尤其重要。
檢索增強生成的好處
與孤立工作的語言模型相比,檢索增強生成有幾個好處。 以下是它改進文本生成和響應的幾種方法:
- RAG 確保你的模型可以訪問最新的事實和相關信息,因為它可以定期更新其外部參考。 這確保了它生成的響應包含可能與進行查詢的用戶相關的最新信息。 你還可以實施文檔級安全性來控制對數據流中數據的訪問并限制對特定文檔的安全權限。
- RAG 是一種更具成本效益的選擇,因為它需要更少的計算和存儲,這意味著你不必擁有自己的 LLM 或花費時間和金錢來微調你的模型。
- 聲稱準確性是一回事,但實際證明它是另一回事。 RAG 可以引用其外部來源并將其提供給用戶以支持他們的響應。 如果他們選擇這樣做,用戶就可以評估來源以確認他們收到的響應是準確的。
- 雖然 LLM 支持的聊天機器人可以制作比以前的腳本響應更加個性化的答案,但 RAG 可以更加定制其答案。 這是因為它能夠在通過衡量意圖綜合答案時使用搜索檢索方法(通常是語義搜索)來引用一系列上下文信息點。
- 當面對未經訓練的復雜查詢時, LLM 有時會 “產生幻覺”,提供不準確的答案。 通過將其響應與相關數據源的附加參考結合起來,RAG 可以更準確地響應模糊的查詢。
- RAG 模型用途廣泛,可應用于一系列自然語言處理任務,包括對話系統、內容生成和信息檢索。
- 偏見可能是任何人造人工智能中的一個問題。 通過依靠經過審查的外部來源,RAG 可以幫助減少其反應中的偏見。
檢索增強生成與微調
檢索增強生成和微調 (fine-tunning) 是訓練人工智能語言模型的兩種不同方法。 雖然 RAG 將廣泛的外部知識檢索與文本生成結合起來,但微調側重于用于不同目的的狹窄數據范圍。
在微調過程中,預訓練模型會根據專門數據進行進一步訓練,以使其適應任務子集。 它涉及根據新數據集修改模型的權重和參數,使其能夠學習特定于任務的模式,同時保留初始預訓練中的知識。
微調可用于各種人工智能。 一個基本的例子是在識別互聯網上的貓照片的背景下學習識別小貓。 在基于語言的模型中,除了文本生成之外,微調還可以幫助完成文本分類、情感分析和命名實體識別等工作。 然而,這個過程可能非常耗時且昂貴。 RAG 加快了流程,并以更少的計算和存儲需求整合了這些成本。
由于 RAG 可以訪問外部資源,因此當任務需要合并來自 Web 或企業知識庫的實時或動態信息以生成明智的響應時,RAG 特別有用。 微調具有不同的優勢:如果手頭的任務定義明確并且目標是單獨優化該任務的性能,則微調可能非常有效。 這兩種技術的優點是不必為每項任務從頭開始培訓 LLM。
檢索增強生成的挑戰和局限性
雖然 RAG 具有顯著的優勢,但它也面臨著一些挑戰和限制:
- RAG 依賴于外部知識。 如果檢索到的信息不正確,它可能會產生不準確的結果。
- RAG 的檢索組件涉及搜索大型知識庫或網絡,這可能在計算上昂貴且緩慢 - 盡管仍然比微調更快且更便宜。
- 無縫集成檢索和生成組件需要仔細的設計和優化,這可能會導致訓練和部署方面的潛在困難。
- 在處理敏感數據時,從外部來源檢索信息可能會引起隱私問題。 遵守隱私和合規性要求也可能會限制 RAG 可以訪問的來源。 但是,這可以通過文檔級訪問來解決,你可以在其中向特定角色授予訪問和安全權限。
- RAG 基于事實準確性。 它可能難以生成富有想象力或虛構的內容,這限制了其在創意內容生成中的使用。
檢索增強生成的未來趨勢
檢索增強生成的未來趨勢集中在使 RAG 技術更高效、更適應各種應用。 以下是一些值得關注的趨勢:
個性化
RAG 模型將繼續納入用戶特定的知識。 這將使他們能夠提供更加個性化的響應,特別是在內容推薦和虛擬助理等應用程序中。
可定制的行為
除了個性化之外,用戶本身還可以更好地控制 RAG 模型的行為和響應方式,以幫助他們獲得所需的結果。
可擴展性
RAG 模型將能夠處理比目前更大量的數據和用戶交互。
混合模式
RAG 與其他人工智能技術(例如強化學習)的集成將允許更通用和上下文感知的系統,可以同時處理各種數據類型和任務。
實時、低延遲部署
隨著 RAG 模型檢索速度和響應時間的提高,它們將更多地用于需要快速響應的應用程序(例如聊天機器人和虛擬助手)。
使用 Elasticsearch 檢索增強生成
借助 Elasticsearch Relevance Engine,你可以為生成式 AI 應用程序、網站、客戶或員工體驗構建支持 RAG 的搜索。 Elasticsearch 提供了一個全面的工具包,使你能夠:
- 存儲和搜索專有數據和其他外部知識庫以從中獲取上下文
- 使用多種方法從你的數據生成高度相關的搜索結果:文本、向量、混合或語義搜索
- 為你的用戶創建更準確的響應和更有吸引力的體驗
了解 Elasticsearch 如何為你的企業改進生成式 AI












)


)
)


