一、說明
????????增強大型語言模型 (LLM) 安全性的追求是技術創新、道德考慮和實際應用的復雜相互作用。這項努力需要一種深入而富有洞察力的方法,將先進的數學模型與道德原則和諧地融合在一起,以確保LLM的發展不僅在技術上穩健,而且在道德上合理且對社會負責。
????????在這篇博客中,我提供了數學工具、框架和想法來增強LLM的安全性。??

二、?穩健的訓練數據:多樣性和代表性的數學方法
減少LLM偏差的基石在于訓練數據的組成。這可以通過復雜的優化框架來實現:
2.1 訓練數據優化框架
????????可以通過結合基于熵的多樣性度量和更細致的差異指數以及對覆蓋和冗余的復雜評估來增強優化框架:
![]()
在哪里,
- H?(?D?) 是多樣性的香農熵,提供數據集信息豐富度的度量。
- Δ(?D?) 是基于基尼系數的差異指數,提供了更精確的數據表示不平等度量。
- C?(?D?) 是基于 Jaccard 指數的覆蓋度量,評估數據元素的唯一性。
- R?(?D?) 是基于數據元素頻率分析的冗余度量。
- α、λ、β和γ是平衡每一項貢獻的系數。
2.2 增強度量的數學公式
基于熵的多樣性(香農熵):
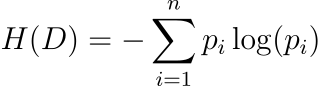
????????其中,pi?表示數據集中第 i個類別或特征出現的概率。
????????香農熵是數據集中不確定性或隨機性的度量。在LLM的訓練數據中,熵值越高表示數據集越多樣化。這種多樣性對于訓練穩健的模型至關重要,因為它確保接觸廣泛的語言輸入和場景,從而降低模型輸出中存在偏差的風險。
基于基尼系數的差距指數:
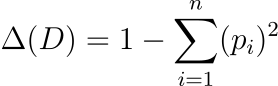
????????該指數衡量不同類別或特征的表示的不平等程度。
????????基于基尼系數的差異指數是數據集中不同類別或特征表示的不平等的度量。在LLM的訓練數據中,較低的 Δ(?D?) 值表示不同類別或特征的表示更加平衡和公平,這對于最大限度地減少模型輸出中的偏差至關重要。該索引有助于確保訓練數據中沒有單一類別或特征過度占主導地位或代表性不足。
基于 Jaccard 指數的覆蓋范圍:
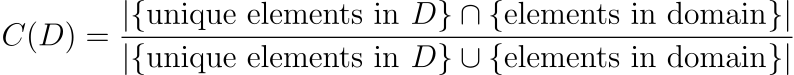
????????該索引評估D中的唯一元素與域中所有可能元素之間的重疊。
????????杰卡德指數是兩個集合之間相似性的度量。在LLM訓練數據的背景下,它量化了數據集D覆蓋整個感興趣領域的程度。C?(?D?)值越高,表明數據集包含更廣泛的領域元素,這對于確保模型訓練數據的全面覆蓋和代表性至關重要。該指標有助于評估數據集是否充分代表了其要建模的領域的多樣性。
基于頻率分析的冗余:
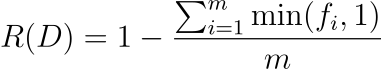
- fi?表示數據集中第 i個元素的頻率。
- min(?fi??,1) 確保每個元素對總和的貢獻最多為 1,無論其頻率如何。這對于防止高頻元素過度影響冗余分數非常重要。
- 除以m可以標準化度量,使其獨立于數據集的大小。
????????此冗余指標量化了數據集中唯一數據的比例。R?(?D?)值越低表示冗余度越高,這意味著數據集包含大量重復或重復元素。該指標對于評估訓練LLM的數據集的質量非常有用,因為過多的冗余可能會扭曲模型的學習過程并影響其性能。
2.3 示例:多語言翻譯LLM強化培訓
????????在多語言翻譯LLM中,這種先進的方法可確保訓練數據涵蓋廣泛的語言、方言和語言風格。基于熵的多樣性度量確保了語言的豐富性,基于基尼系數的指數最大限度地減少了對任何特定語言的偏見,基于杰卡德指數的覆蓋范圍確保了廣泛的語言譜,基于頻率分析的冗余度量避免了常見短語的過度表達或結構。
三、道德準則和監督:道德合規的算法框架
????????道德評估框架可以擴展到多標準決策分析(MCDA)模型,納入一系列道德維度及其復雜的相互依賴性:
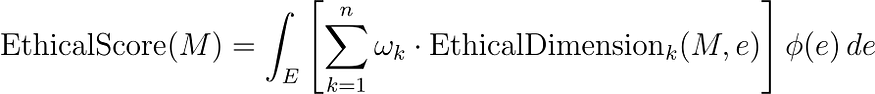
在這里,
- EthicalScore(?M?) 是模型M的綜合道德評分。
- EthicalDimension?k??(?M?,?e ) 代表在各種場景e中評估的一系列道德維度(如公平、透明、問責、隱私等)。
- ωk?是每個道德維度的權重系數,反映它們的相對重要性。
- ψ?(?e?) 是一個加權函數,根據頻率、影響或利益相關者關注等因素為不同場景分配重要性。
- E上的積分可確保對不同場景進行全面評估。
????????該方程代表了評估LLM道德表現的綜合方法。它考慮道德行為的多個方面,每個方面都有其重要性,并根據不同場景的相關性或影響來調整評估。這種方法可確保對模型在各種潛在情況下遵守道德標準的情況進行細致入微和徹底的評估
示例:自動駕駛法學碩士的道德評估
????????考慮用于自動駕駛決策系統的LLM。這個先進的框架評估模型在緊急決策、行人安全和遵守交通法規等場景中的道德表現。該模型不僅針對即時決策結果進行評估,還針對長期社會影響和法律合規性進行評估。
3.1 進一步的數學擴展:倫理決策理論和MCDA
????????為了量化每個道德維度,我們可以從道德決策理論和 MCDA 中得出:
公平指標(功利主義方法):
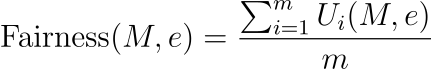
????????其中,Ui??(?M?,?e?) 表示場景e中第 i個利益相關者的效用或收益,m是利益相關者的數量。
????????該方程代表了一種實現公平的功利主義方法,其中模型在特定場景中的公平性是根據它為所有相關利益相關者提供的平均收益或效用來評估的。這種方法可確保評估模型的決策或輸出對不同利益相關者群體的總體影響,從而促進公平和平衡的結果。
透明度指標(信息論):
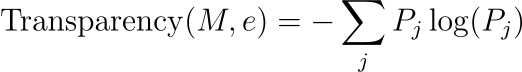
????????其中Pj?是模型提供的第 j個解釋或決策路徑的概率。
????????該方程表示基于模型提供的解釋或決策路徑的多樣性和分布的透明度度量。它類似于信息論中的熵概念,其中較高的值表示更多樣化,因此可能更透明的解釋集。該指標對于評估模型解釋其決策或輸出的能力特別有用,這是道德人工智能和機器學習系統的一個重要方面。
責任指標(風險評估):
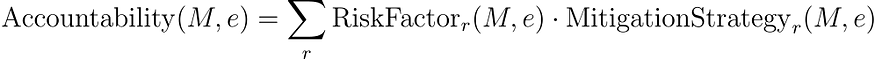
????????其中 RiskFactor?r??(?M?,?e ) 評估與第 r個決策路徑相關的風險,MitigationStrategy?r??(?M?,?e?) 評估潛在糾正措施的有效性。
該方程通過評估模型識別和減輕各種風險的能力來評估模型的責任性。每個風險因素都被量化,并評估其相應緩解策略的有效性。然后通過對所有已識別風險的評估進行求和來確定總體責任。這種方法可確保對模型負責任地處理潛在問題的能力及其糾正問題的準備情況進行全面評估,這對于道德人工智能系統至關重要。
四、高級安全協議:非線性隨機控制和穩定性分析
????????增強型隨機控制模型可以通過結合非線性動力學和穩定性分析來進一步細化:
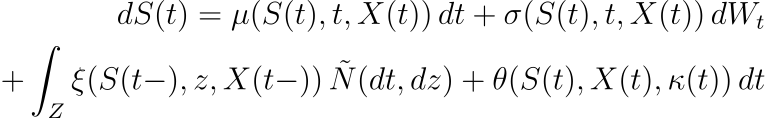
????????在這個高級模型中:
- μ?(?S?(?t?),?t?,?X?(?t?)) 和σ?(?S?(?t?),?t?,?X?(?t?)) 是安全級別S?(?t?)、時間t和附加狀態變量X?(?t)。
- θ?(?S?(?t?),?X?(?t?),?κ?(?t?)) 是根據當前狀態和控制動作κ?(?t?) 進行調整的反饋控制項。
- 可以應用李亞普諾夫穩定性分析來確保安全水平保持在期望的范圍內,從而增強模型的穩健性。
????????方程的敘述:
- 時間t時安全水平S?(?t ) 的微分變化由dS?(?t?)給出,它是四個分量的總和。
- 第一個分量μ?(?S?(?t?),?t?,?X?(?t?))?dt表示漂移項,它是安全級別S?(?t?)、時間t和外部狀態變量X?(?t?)的函數。
- 第二個分量σ?(?S?(?t?),?t?,?X?(?t?))?dWt?表示擴散項,對安全性中的隨機波動進行建模,其中dWt?是維納過程的微分。
- 第三個分量 ∫?Z??xi?(?S?(?t??),?z?,?X?(?t??))?N?~(?dt?,?dz?) 表示跳躍項,解釋由于罕見或極端事件導致的安全水平突然變化,其中N?~ 是補償泊松隨機測度。
- 第四個分量θ?(?S?(?t?),?X?(?t?),?κ?(?t?))?dt是反饋控制項,根據當前狀態S?(?t?)、外部變量X?(?t?) 和控制進行動態調整動作κ?(?t?)。
????????該方程對LLM中安全機制的動態進行建模,考慮到可預測和不可預測的變化,以及自適應響應各種條件和場景的能力。這種復雜的方法可以實時調整安全協議,這對于動態和不可預測的環境至關重要。
示例:自主導航中的自適應安全LLM
????????考慮用于自主導航系統的LLM。非線性隨機控制模型使系統能夠自適應地響應各種導航場景,從標準城市駕駛到復雜的緊急情況。反饋控制項θ根據當前交通狀況、天氣和車輛性能實時調整導航算法,而李亞普諾夫穩定性分析確保這些調整保持導航系統的整體安全性和穩定性。
4.1 進一步的數學擴展:基于強化學習的適應
為了優化基于學習的環境中的安全機制,我們可以引入強化學習框架:
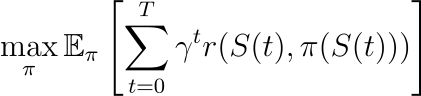
在這里:
- 目標是在政策π下,在時間范圍T內最大化預期累積獎勵。
- r?(?S?(?t?),?π?(?S?(?t?))) 是獎勵函數,量化在狀態S?(?t ) 下采取行動π?(?S?(?t?)) 的收益。
- γ是一個折扣因子,平衡當前和未來的獎勵。
- E?π? 表示策略π下的期望。
該方程通過多種方式與 LLM(大型語言模型)安全性間接相關:
- 安全響應培訓:在LLM的背景下,強化學習可用于訓練模型以生成安全、適當且合乎道德的響應。獎勵函數r?(?S?(?t?),?π?(?S?(?t?))) 可以設計為向符合安全和道德準則的輸出分配較高的獎勵,并為有害的、有偏見的輸出分配較低(或負)的獎勵。或不合適。
- 安全自適應學習:強化學習框架允許LLM從交互和反饋中不斷學習。通過根據收到的獎勵調整策略π,LLM可以自適應地提高其安全性方面的表現。這在“安全響應”的定義可能隨著時間的推移而變化的動態環境中特別有用。
- 基于場景的訓練:?RL 框架中的狀態S?(?t?) 可以代表 LLM 運行的不同場景或上下文。通過考慮廣泛的場景,強化學習方法可以確保LLM在不同情況(包括邊緣情況)下保持安全。
- 平衡即時和長期安全:?RL 方程中的折扣因子γ有助于平衡即時獎勵與長期結果。這對于LLM的安全至關重要,因為它確保模型不僅能在短期內生成安全響應,還能學習維持長期安全的策略。
- 可定制的安全指標:強化學習中獎勵函數的靈活性允許結合可定制的、細致入微的安全指標。安全的不同方面,例如避免錯誤信息、尊重隱私或防止攻擊性內容,可以編碼到獎勵函數中。
五、人工智能輔助紅隊(AART):高級博弈論和系統分析框架
????????AART 框架可以通過集成博弈論模型和復雜系統分析來增強,以模擬更復雜的對抗性交互:

在這個高級方程中:
- GameTheoreticResponse(?M?,?Ai??)使用博弈論原理評估模型M對對抗性輸入Ai?的策略響應。
- αi?代表每個博弈論對抗場景的重要性。
- SystemsRobustnessMetric(?M?,?s?) 評估模型在復雜系統場景s中的穩健性。
- β?(?s?) 是復雜系統場景 S 空間上的權重函數。
敘述:
- 模型M的AARTScore AARTScore(?M?)計算為顯著性系數αi? 和對抗性輸入Ai的博弈論響應 GameTheoreticResponse(?M?,?Ai??) 的乘積之和,加上空間上的積分復雜的系統場景S?.
- 該積分計算每個場景s的加權函數β?(?s?) 和系統魯棒性度量 SystemsRobustnessMetric(?M?,?s?) 的乘積。
????????這是評估LLM抵御對抗性攻擊的穩健性的綜合方法。它考慮了模型對特定對抗性輸入的戰略響應及其在復雜的全系統場景中的整體魯棒性。這種雙重方法確保了對LLM應對復雜和多方面的對抗性挑戰的能力進行全面評估。
示例:國家安全LLM的戰略和系統分析
????????考慮用于國家安全分析的LLM。增強的 AART 框架采用博弈論模型來模擬與潛在對手的戰略互動,評估模型提供戰略見解的能力。此外,它還使用復雜系統分析來評估模型在涉及地緣政治事件、信息戰和網絡威脅的復雜網絡的場景中的穩健性。
5.1 進一步的數學擴展:多智能體建模和進化動力學
????????為了更真實地模擬對抗場景,可以使用多智能體建模方法:
![]()
在這里:
- Ai?是由多智能體模型 M 生成的對抗性輸入。
- θ 代表控制代理行為的參數。
- D和I代表代理的數據分布和交互規則。
????????用于測試LLM的對抗性輸入不僅是隨機生成的,而且是由模擬現實且具有戰略相關性的對抗性場景的復雜模型產生的。
????????參數 θ 控制模型內代理的行為,而 D 和 I 分別表示底層數據分布和控制代理交互的規則或約束。這種方法允許創建具有挑戰性和多樣化的對抗性輸入,可以有效地測試和增強LLM的穩健性。
????????結合進化動力學可以隨著時間的推移適應和優化對抗策略:
![]()
????????其中,EvolutionaryAdversarialEffectiveness(?M?,?Ai ?) 衡量在挑戰模型M時隨時間演變的對抗策略的有效性。
????????AART 和 LLM 對抗性測試背景下的“進化對抗有效性”函數是一種概念函數,而不是標準的、普遍定義的函數。其具體表述可能會根據對抗性測試的目標和所測試的LLM的特征而有所不同。不過,我可以提供這樣一個函數可能需要什么的一般概念:
該功能的目標:
- “EvolutionaryAdversarialEffectiveness”函數的主要目標是評估給定的對抗性輸入(通過進化策略生成)在暴露 LLM 中的漏洞或弱點方面的有效性。
該功能的可能組成部分:
- 漏洞利用分數:衡量對抗性輸入利用 LLM 中已知或潛在漏洞的程度。這可能涉及測試LLM對旨在引發偏見、不正確或不道德反應的輸入的響應。
- 穩健性挑戰得分:評估對抗性輸入對LLM穩健性的挑戰程度,可能是通過呈現LLM必須處理的復雜、模糊或新穎的場景。
- 多樣性和新穎性分數:與典型訓練數據或之前的對抗性示例相比,評估對抗性輸入的獨特性,確保LLM在廣泛的場景中進行測試。
數學表示:
該函數的簡化表示可能如下所示:
![]()
其中,V?(?M?,?Ai??) 是給定對抗性輸入Ai?的模型M 的漏洞利用分數,R?(?M?,?Ai??) 是魯棒性挑戰分數,D?(?Ai??) 是多樣性和新穎性分數。權重 1,2、w?1?、w?2?和w?3?平衡了每個組件的重要性。
進化方面:
- 進化方面意味著該函數在迭代過程中使用,其中對抗性輸入逐漸完善以變得更加有效。這可能涉及遺傳算法等技術,其中輸入根據其有效性分數在幾代人中不斷演變。
????????在實踐中,目標函數的具體表述將根據LLM的特殊性和對抗性測試的目標進行定制,并且可能涉及機器學習指標、統計分析和特定領域評估的組合。
六、透明度和問責制:先進的統計和理論框架
????????透明度指數可以通過捕獲可解釋性各個方面的指標來增強,并且可以引入問責框架來量化模型的責任和可追溯性。該指數可以通過納入統計可解釋性和決策一致性的衡量標準來增強:
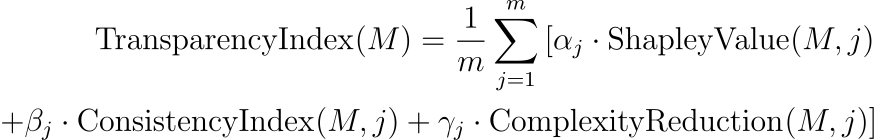
在這里:
- ShapleyValue(?M?,?j?)使用合作博弈論中的 Shapley 值來量化場景j中每個輸入特征對模型輸出的貢獻。
- ConsistencyIndex(?M?,?j?) 衡量相似場景中模型輸出的一致性,從而增強可預測性。
- ComplexityReduction(?M?,?j?) 繼續評估模型簡化復雜信息的能力。
全面的問責框架:
問責框架可以包括因果影響分析和道德決策審計:
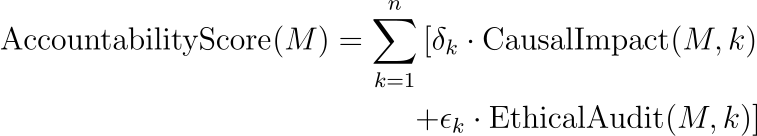
在哪里:
- CausalImpact(?M?,?k?) 使用因果推理技術評估模型決策和結果之間的因果關系。
- EthicalAudit(?M?,?k?) 是一個審核過程,根據道德準則和標準評估模型的決策。
示例:內容推薦 LLM 中的高級指標
????????考慮用于內容推薦的LLM。先進的透明度指數評估模型的決策過程,確保建議基于相關功能,并且在相似的用戶配置文件中保持一致。問責分數評估建議對用戶行為的因果影響,并進行道德審核,以確保內容符合社區標準并且不會宣揚有害行為。
進一步的數學擴展:責任的因果推理
為了量化因果影響,可以采用反事實分析:
![]()
????????其中,Y_?do(?X?=?x )? 是將干預X設置為值x(模型做出的決策)時的預期結果,?Y?do(?X?=?x?′)? 是替代決策 ′ 的預期結果X?'。
????????這代表了一種量化模型所采取的特定決策或行動的因果效應的方法。它使用因果推理中的反事實概念,其中Y_?do(?X?=?x?)? 表示模型采取操作x時的預期結果,Y_?do(?X?=?x?′)? 表示替代操作 ′?x的預期結果′。
????????這種方法對于理解模型決策的直接影響至關重要,而不僅僅是相關性,并且在理解因果關系至關重要的場景中尤其重要。
????????提高LLM的安全性是一項多方面的挑戰,需要深入了解這些先進技術的數學復雜性和倫理影響。通過將復雜的數學模型、道德考慮和實際應用相結合,我們可以為LLM鋪平道路,這些LLM不僅在技術上精通,而且在道德上健全且對社會有益。



![[Makefile] include 關鍵字](http://pic.xiahunao.cn/[Makefile] include 關鍵字)
--安全滲透簡介)










)



