本文是關于基于YOLOv4開發構建目標檢測模型的超詳細實戰教程,超詳細實戰教程相關的博文在前文有相應的系列,感興趣的話可以自行移步閱讀即可:
《基于yolov7開發實踐實例分割模型超詳細教程》
《YOLOv7基于自己的數據集從零構建模型完整訓練、推理計算超詳細教程》
《DETR (DEtection TRansformer)基于自建數據集開發構建目標檢測模型超詳細教程》
《基于yolov5-v7.0開發實踐實例分割模型超詳細教程》
《輕量級模型YOLOv5-Lite基于自己的數據集【焊接質量檢測】從零構建模型超詳細教程》
《輕量級模型NanoDet基于自己的數據集【接打電話檢測】從零構建模型超詳細教程》
《基于YOLOv5-v6.2全新版本模型構建自己的圖像識別模型超詳細教程》
《基于自建數據集【海底生物檢測】使用YOLOv5-v6.1/2版本構建目標檢測模型超詳細教程》
?《超輕量級目標檢測模型Yolo-FastestV2基于自建數據集【手寫漢字檢測】構建模型訓練、推理完整流程超詳細教程》
《基于YOLOv8開發構建目標檢測模型超詳細教程【以焊縫質量檢測數據場景為例】》
最早期接觸v3和v4的時候印象中模型的訓練方式都是基于Darknet框架開發構建的,模型都是通過cfg文件進行配置的,從v5開始才全面轉向了PyTorch形式的項目,延續到了現在。
yolov4.cfg如下:
[net]
batch=64
subdivisions=8
# Training
#width=512
#height=512
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1learning_rate=0.0013
burn_in=1000
max_batches = 500500
policy=steps
steps=400000,450000
scales=.1,.1#cutmix=1
mosaic=1#:104x104 54:52x52 85:26x26 104:13x13 for 416[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-7[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-10[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-28[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-28[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-16[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=1
activation=mish##########################[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky### SPP ###
[maxpool]
stride=1
size=5[route]
layers=-2[maxpool]
stride=1
size=9[route]
layers=-4[maxpool]
stride=1
size=13[route]
layers=-1,-3,-5,-6
### End SPP ###[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = 85[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[route]
layers = -1, -3[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = 54[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[route]
layers = -1, -3[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky##########################[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5[route]
layers = -4[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=256
activation=leaky[route]
layers = -1, -16[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 3,4,5
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5[route]
layers = -4[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=512
activation=leaky[route]
layers = -1, -37[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5yolov4-tiny.cfg如下:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=1
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1learning_rate=0.00261
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1[convolutional]
batch_normalize=1
filters=32
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky##################################[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=80
num=6
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=0
resize=1.5
nms_kind=greedynms
beta_nms=0.6[route]
layers = -4[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = -1, 23[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 1,2,3
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=80
num=6
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=0
resize=1.5
nms_kind=greedynms
beta_nms=0.6最開始的時候還是蠻喜歡這種形式的,非常的簡潔,直接使用Darknet框架訓練也很方便,到后面隨著模型改進各種組件的替換,Darknet變得越發不適用了。YOLOv4的話感覺定位相比于v3和v5來說比較尷尬一些,git里面搜索yolov4,結果如下所示:

排名第一的項目是pytorch-YOLOv4,地址在這里,如下所示:
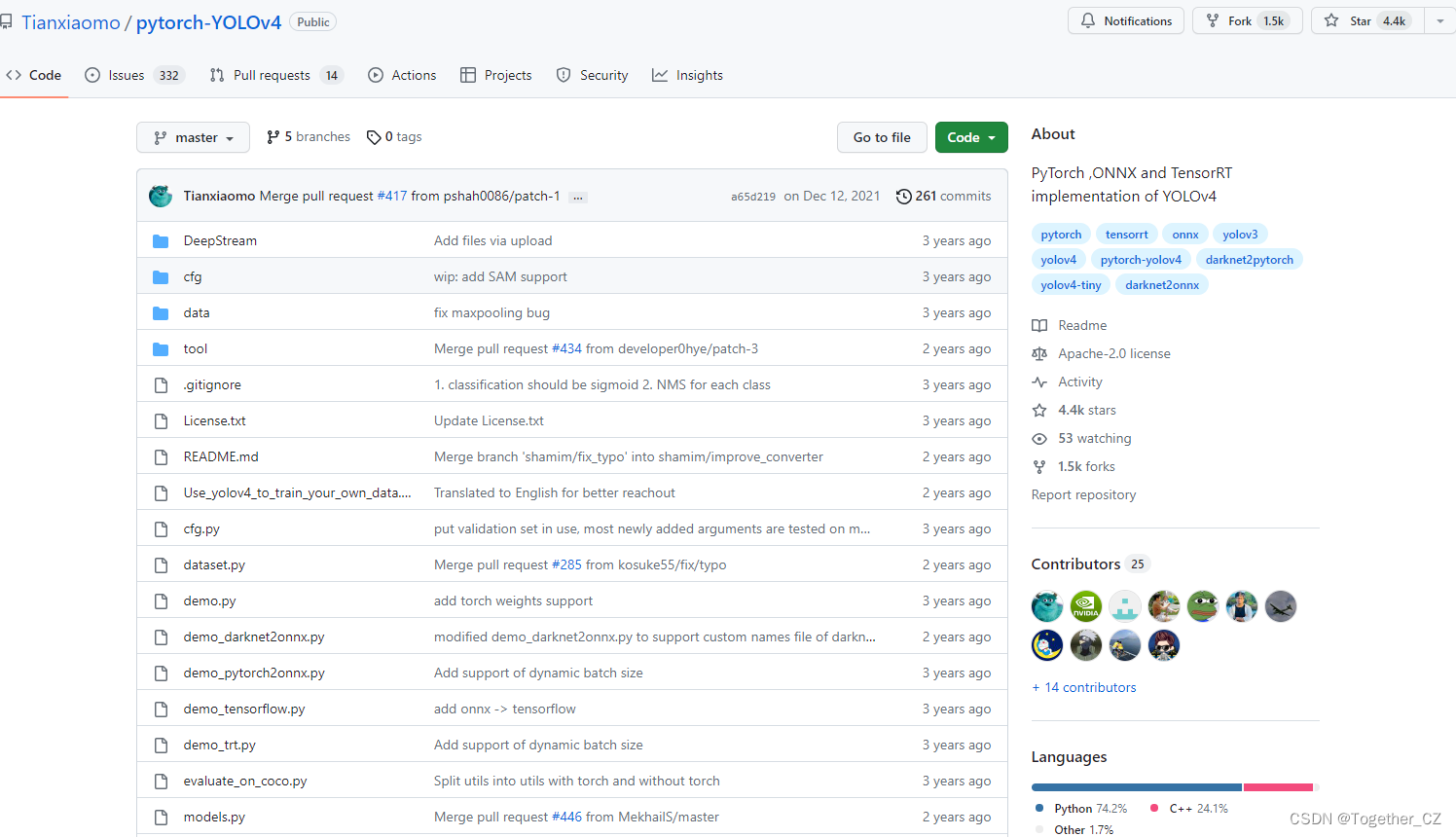
從說明里面來看,這個只是一個minimal的實現:
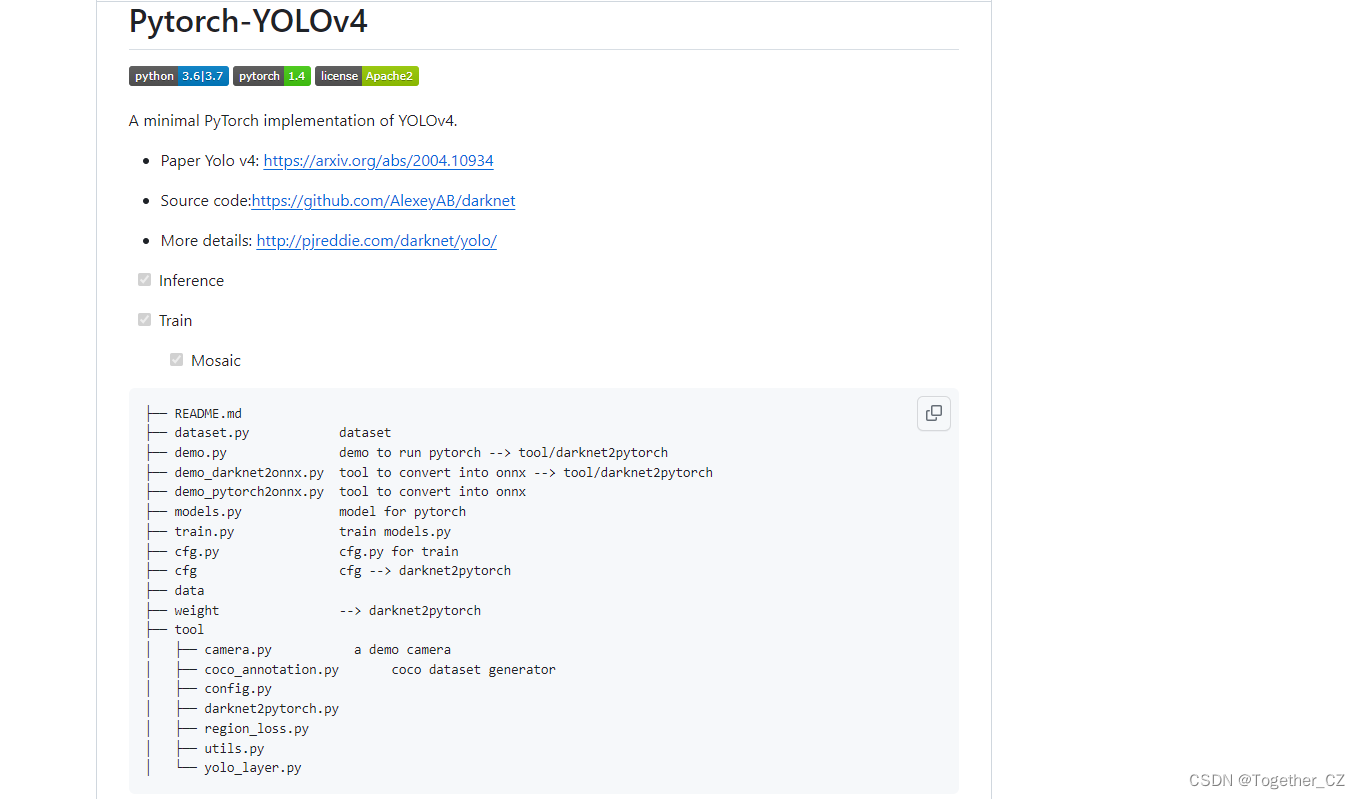
官方的實現應該是:
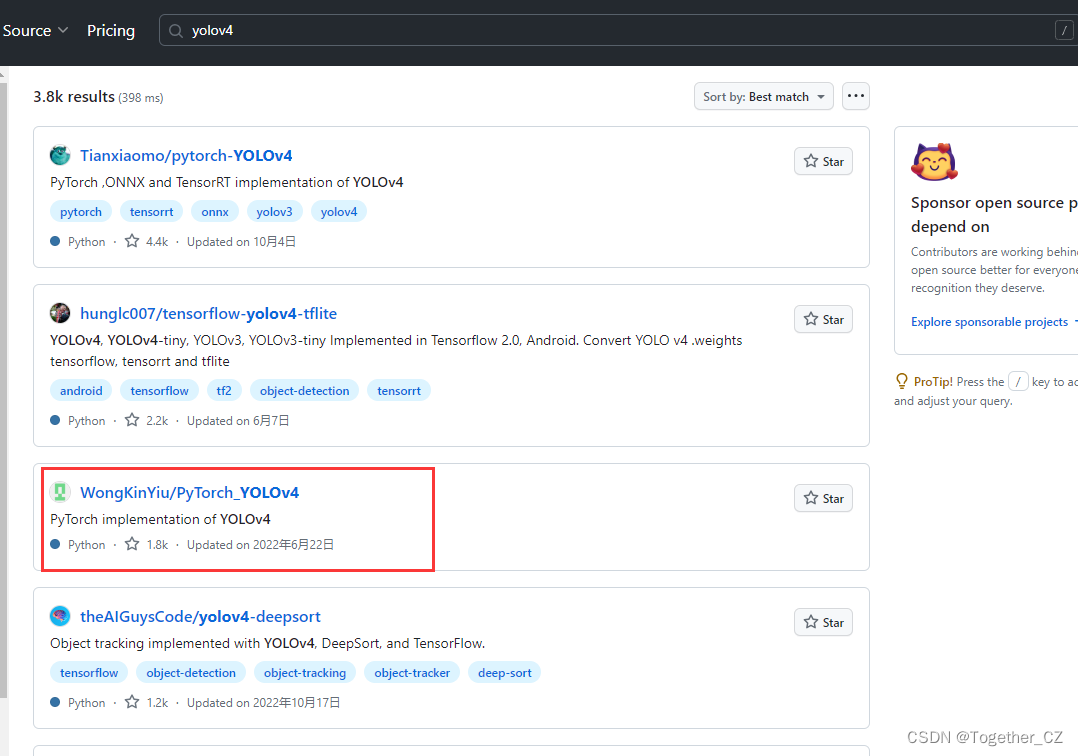
仔細看的話會發現,官方這里提供了YOLOv3風格的實現項目以及YOLOv5風格的實現項目,本文主要是以YOLOv3風格的YOLOv4項目為基準來講解完整的實踐流程,項目地址在這里,如下所示:

首先下載所需要的項目,如下:
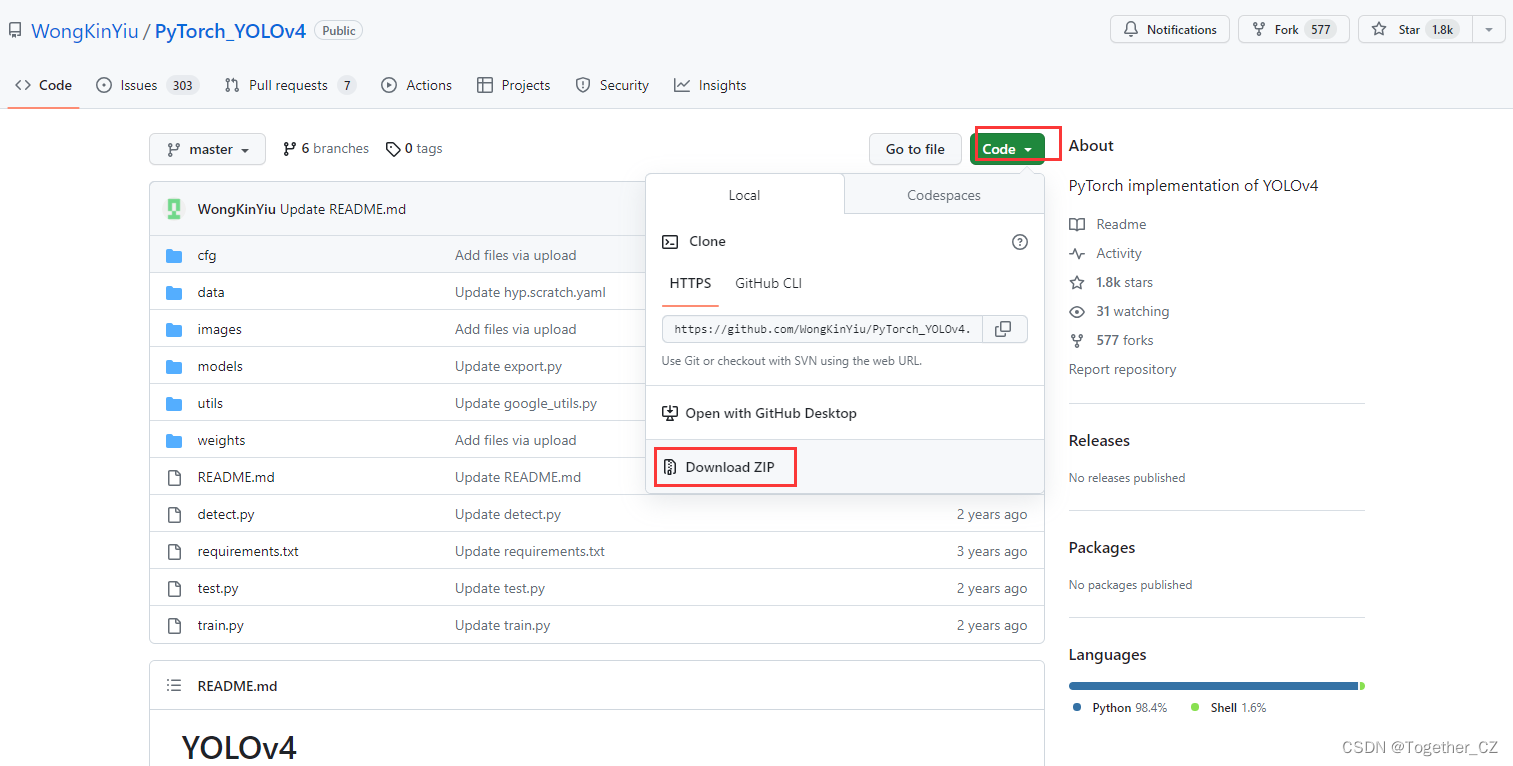
下載到本地解壓縮后,如下所示:
網上直接百度下載這兩個weights文件放在weights目錄下,如下所示:
然后隨便復制過來一個自己之前yolov5項目的數據集放在當前項目目錄下,我是前面剛好基于yolov5做了鋼鐵缺陷檢測項目,數據集可以直接拿來用,如果沒有現成的數據集的話可以看我簽名yolov5的超詳細教程里面可以按照步驟自己創建數據集即可。如下所示:

這里我選擇的是基于yolov4-tiny版本的模型來進行開發訓練,為的就是計算速度能夠更快一些。
修改train.py里面的內容,如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov4-tiny.weights', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/yolov4-tiny.cfg', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()終端直接執行:
python train.py即可。
當然也可以選擇基于參數指定的形式啟動,如下:
python train.py --device 0 --batch-size 16 --img 640 640 --data self.yaml --cfg cfg/yolov4-tiny.cfg --weights 'weights/yolov4-tiny.weights' --name yolov4-tiny根據個人喜好來選擇即可。
啟動訓練終端輸出如下所示:
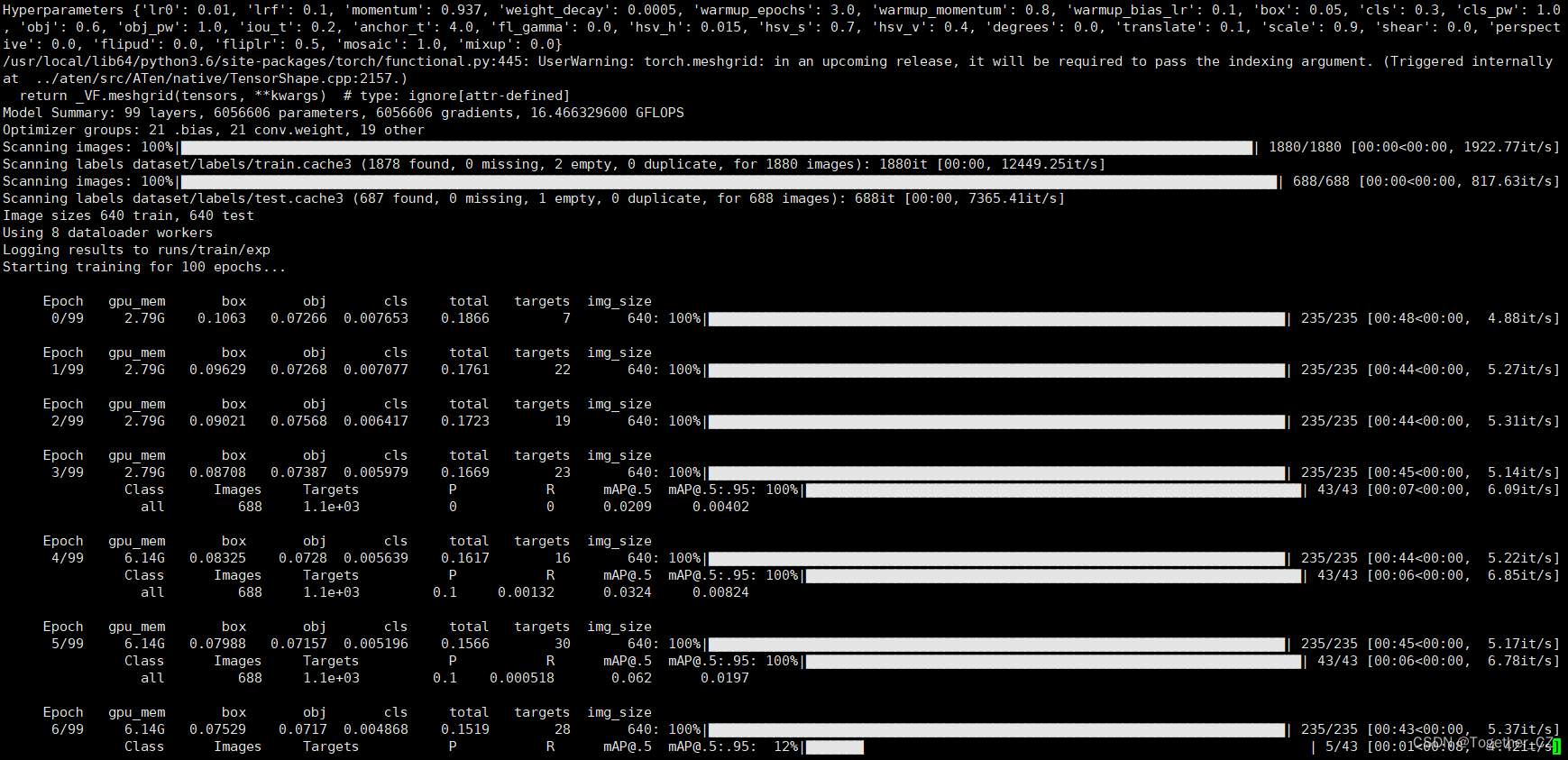
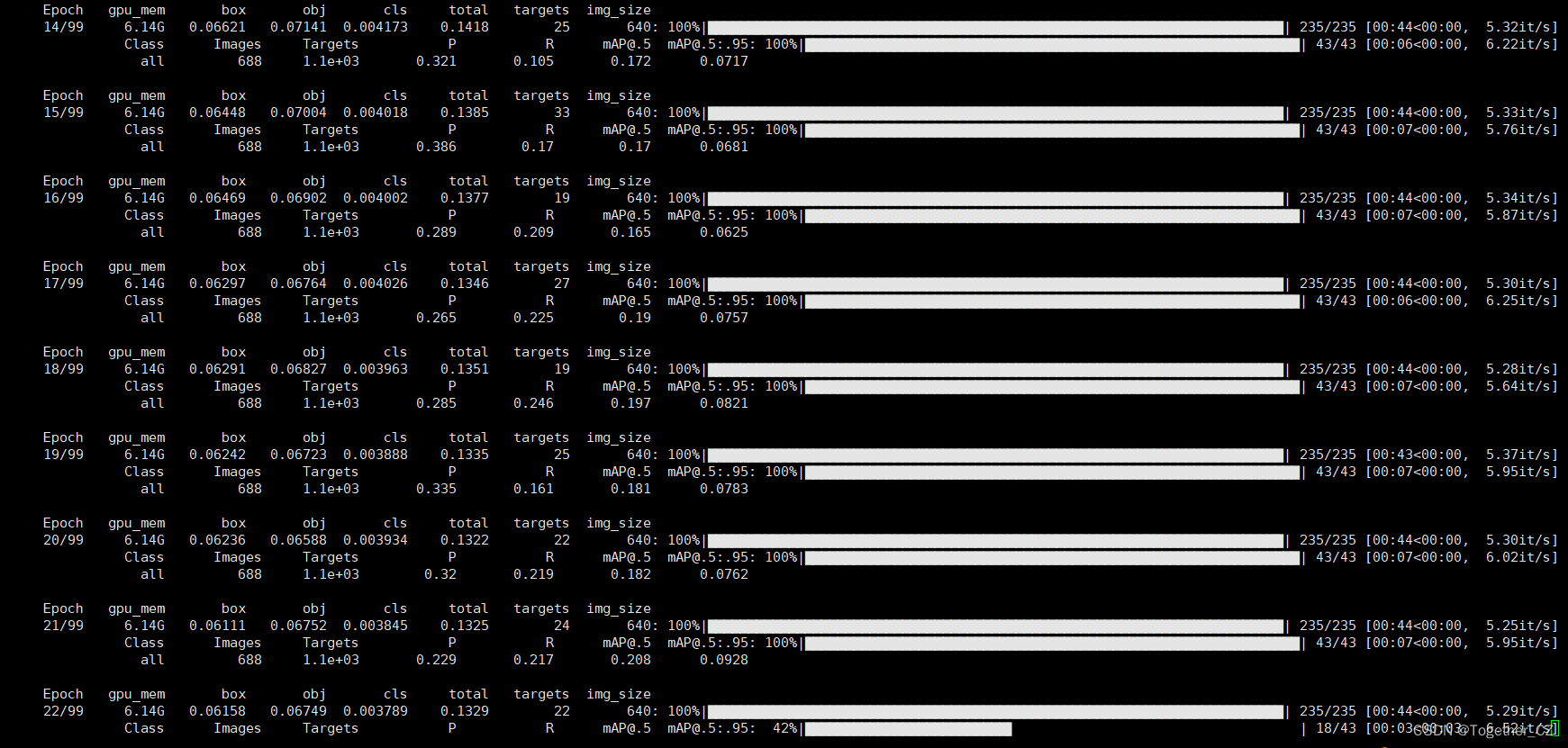

訓練完成截圖如下所示:
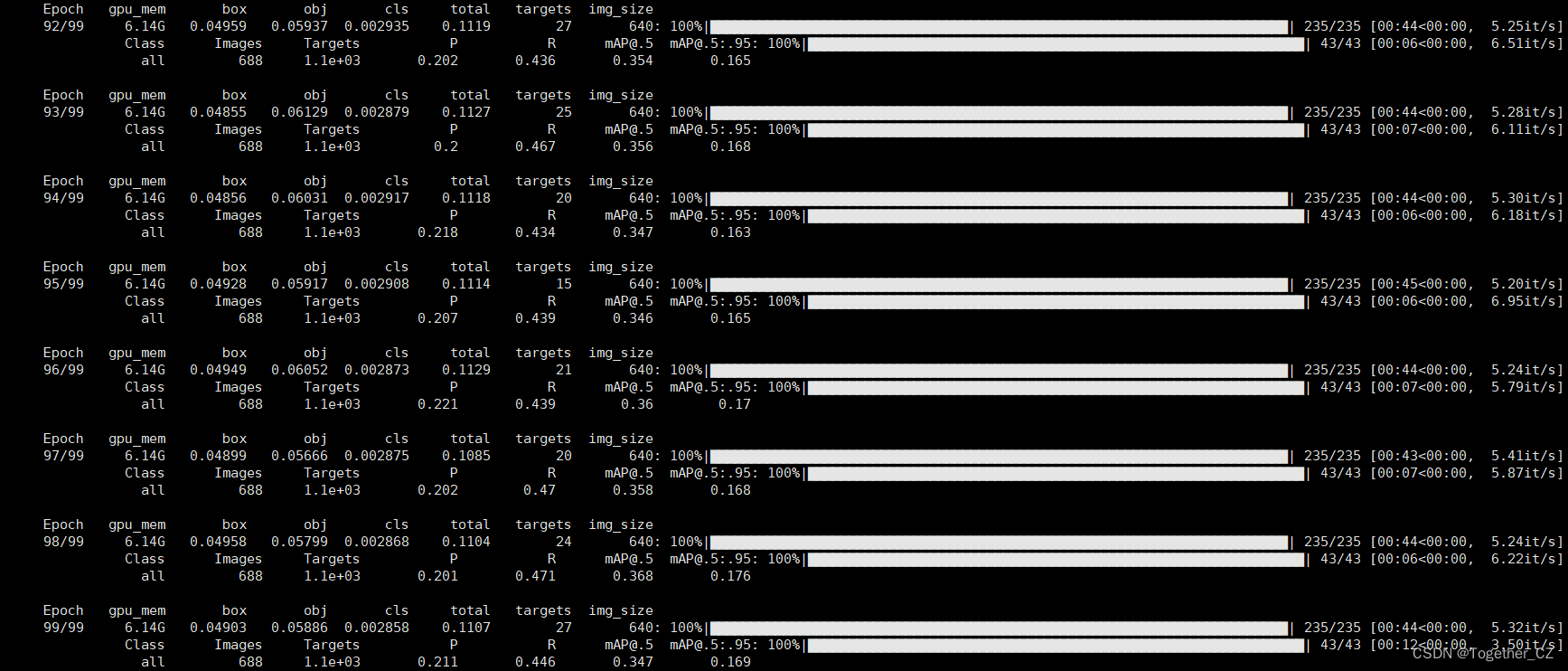
?訓練完成我們來看下結果文件,如下所示:
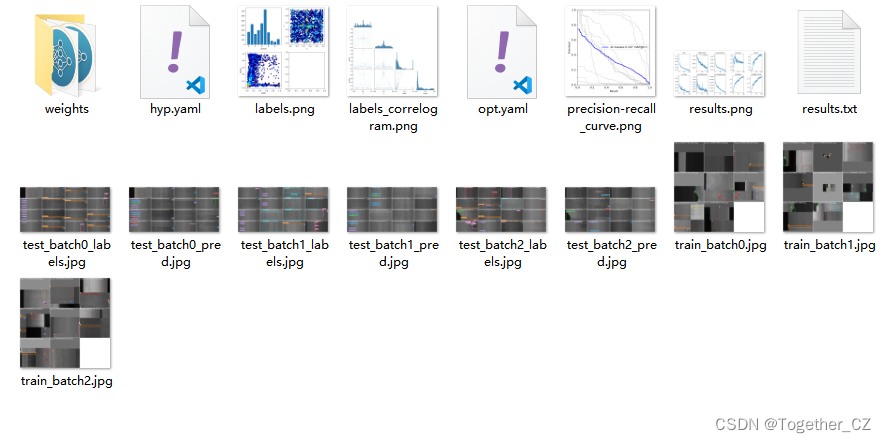
可以看到:結果文件直觀來看跟yolov5項目差距還是很大的,評估指標只有一個PR圖,所以如果是做論文的話最好還是使用yolov5來做會好點。
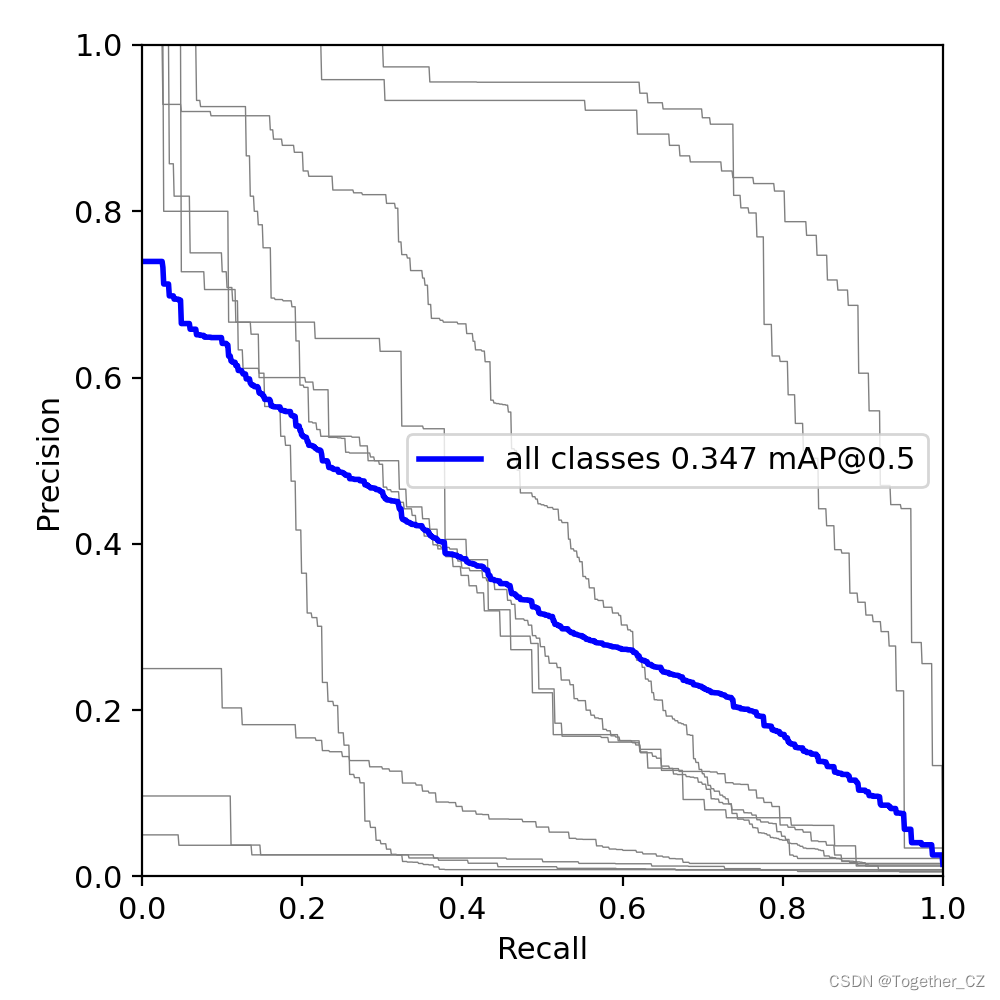
PR曲線如下所示:
訓練可視化如下所示:

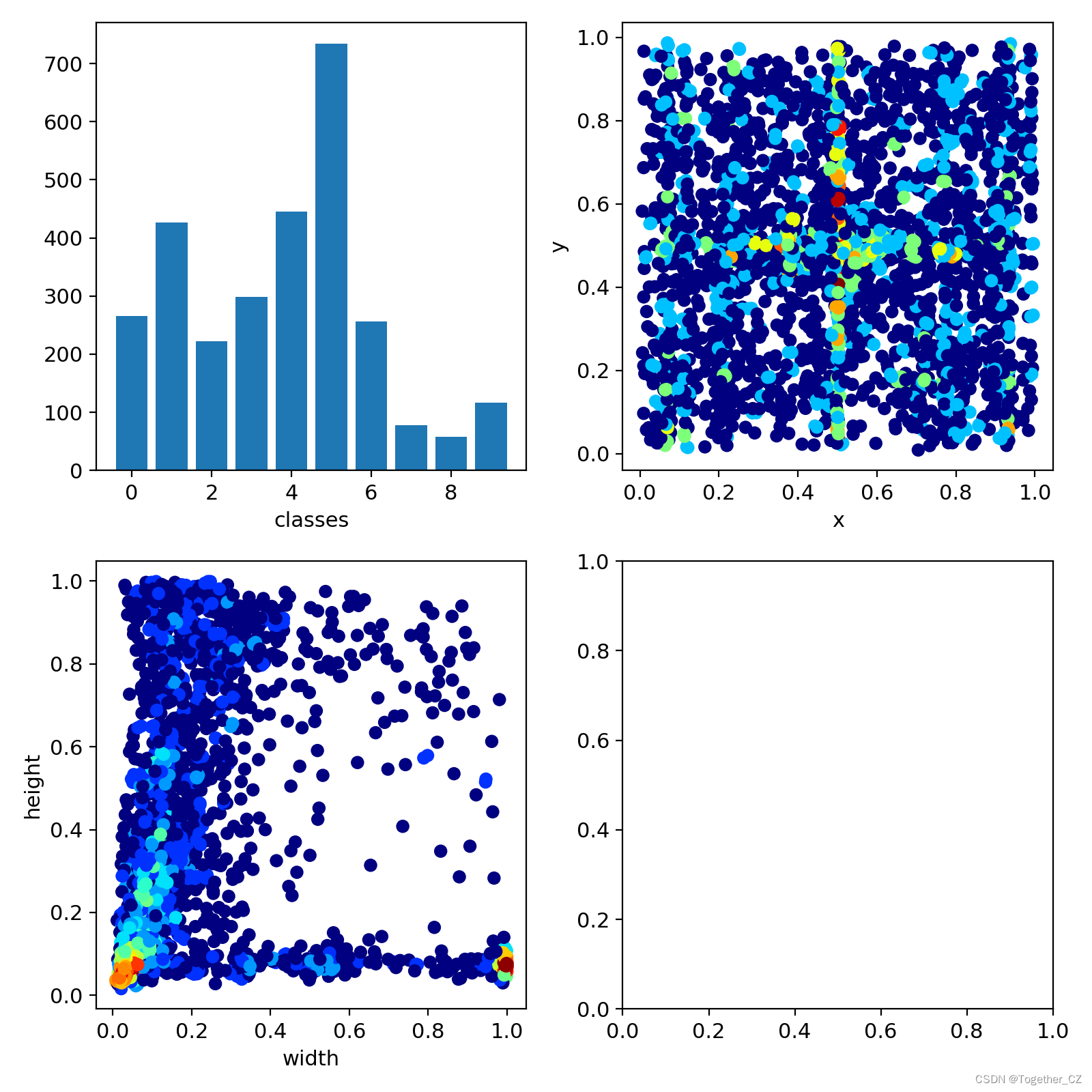
LABEL數據可視化如下所示:
weights目錄如下所示:
這個跟yolov5項目差異也是很大的,yolov5項目只有兩個pt文件,一個是最優的一個是最新的,但是yolov4項目居然產生了19個文件,保存的可以說是非常詳細了有點像yolov7,但是比v7維度更多一些。
感興趣的話都可以按照我上面的教程步驟開發構建自己的目標檢測模型。
)




)


)



)




![CVE-2023-22515:Atlassian Confluence權限提升漏洞復現 [附POC]](http://pic.xiahunao.cn/CVE-2023-22515:Atlassian Confluence權限提升漏洞復現 [附POC])

