目錄
JMeter的安裝配置
測試的性能指標
TPS
響應時長
并發連接 和 并發用戶
CPU/內存/磁盤/網絡 負載
性能測試實戰流程
JMeter
JMeter快速上手
GUI模式 運行
HTTP請求默認值
錄制網站流量
模擬間隔時間
消息數據關聯
變量
后置處理器
CSV 數據文件設置
斷言
循環控制器
預處理器
命令行模式 運行
dashboard 產生圖表
JMeter的安裝配置
參考教程
測試工具JMeter詳細安裝配置教程(保證一次安裝成功)_jmeter安裝教程-CSDN博客
基本能成功,不能成功自己按報錯自行搜索解決辦法
測試的性能指標
參考鏈接
TPS
TPS (transaction per second) 是 服務端 每秒處理請求的數量
TPS 最直觀的反映了 系統的處理能力,當然是重要的性能指標之一。
說到 TPS ,和其相關的還有如下這些名詞:
-
RPS (request per second) 是 測試工具 每秒發送請求的數量
RPS 和 TPS 概念不同,前者是每秒發出的請求數量。后者是處理完成的請求數量。
但是顯然,RPS 是決定 TPS 的重要因素。
TPS 是由 RPS 、網絡延遲 、服務端本身的處理速度 這3個因素決定的。
一個性能表現良好的系統,TPS和RPS幾乎是相同的
-
EPS (error per second) 是 服務端 每秒處理出錯的數量,也包含在TPS中。
一個性能表現良好的系統,EPS 應該一直為0
-
TOPS (timeout per second) 是 服務端 每秒處理超時的數量
超時時間具體是多少,應該由產品需求定義。
一個性能表現良好的系統,TOPS 應該一直為0
前面說過 TPS 是由 RPS 、網絡延遲 、服務端本身的處理速度 這3個因素決定的。
服務端本身的處理速度 就是我們要測試的,測試時,我們要保證的是其他兩個因素:RPS 和 網絡延遲。
做 性能/壓力測試 時, 被測系統和加壓系統, 應該在一個帶寬網速比較理想的環境中,首先保證網絡延遲沒有問題。
然后,性能測試工具要測試TPS能否達到 , 主要就是設置每秒發送請求的數量,也就是RPS。
RPS 是由測試工具決定的。
一個壓測工具本身的加壓性能也很重要。
否則,如果TPS指標比較高,工具本身做不到,就沒法測試了。
如果服務端性能無限強,網絡無限好,在目前的主流機器上,壓測能做到
單進程 Windows系統 2000-5000 RPS, Linux系統下3000-6000 RPS
整機大概在 6000-12000 RPS
定義的一種客戶端 里面的行為代碼 就決定這種客戶端的 RPS
總RPS = 客戶端1 RPS * 客戶端1數量 + 客戶端2 RPS * 客戶端2數量 + …
所以,關鍵看你的客戶端行為定義 和 客戶端數量定義。
一個性能表現良好的系統,TPS 和 RPS 幾乎是相同的。
所以,通常測試指標TPS是多少,工具設置的RPS就是多少。
當然,如果服務端本身的性能不夠,TPS自然也會相應的下降。這時,可以相應的提升一下壓測工具的RPS
?在測試過程中會產生日志文件,記錄每秒 RPS、TPS、EPS、TOPS。
可以對測試數據進行統計作圖。
注意:RPS、TPS、TOPS 都不需要我們做什么,工具會自動記錄。
但是 EPS,必須要我們自己寫代碼,對響應數據進行檢查,并且告知黑羽壓測。
因為工具本身不了解業務邏輯,什么樣的因為數據是錯誤的,工具沒法預先知道。
響應時長
響應時長 就是 服務端 處理請求耗費的時間
平均響應時長
平均響應時長 就是 服務端 處理請求的平均耗費時間。
這是影響用戶體驗的重要指標。設想一下如果 TPS 很高,但是,很多請求要很長時間才得到反應,是什么樣的用戶體驗。。。
在測試過程中會產生日志文件,記錄每秒 平均響應時長。
響應時長區段統計
光看平均響應時長,往往是不全面的。
可能 有些請求會耗時特別長,嚴重影響用戶體驗。但是被平均了就看不出來。
響應時長不能兩極分化。
響應時長區段統計就是查看是否兩極分化的衡量指標。
并發連接 和 并發用戶
并發連接數 是 服務端 和客戶端 建立的?TCP連接的數量
并發用戶數 是 服務端 同時服務的?用戶的數量?。
用戶的一個操作可能引發多個并發連接。
并發連接
通常,并發連接數指標,適用于 測試 面向客戶端程序的 API服務系統,比如 云服務。
和 TPS 對系統性能的衡量側重點不同 ,并發連接數指標 衡量 系統 能?同時處理?客戶的能力。
兩者的區別 用一個比方 來解釋,就像銀行服務:
并發連接數,就像有多少個服務窗口
TPS, 就像每個窗口 服務員的處理速度
每個窗口服務員的處理速度即使很快,但是同時來了很多人,也必須開多個窗口,否則就會有人得不到服務。
對 并發連接 指標, 是通過 客戶端和性能場景 的定義來 設置的 。
如果,這樣定義客戶端
client = HttpClient('192.168.2.103',timeout=10) while True: response = client.sendAndRecv('GET','/api/path1')sleep(60) # 間隔60秒這樣定義性能場景
createClients('client-1', # 客戶端名稱1000, # 客戶端數量0.1, # 啟動間隔時間,秒)就會每隔1秒創建10個客戶端(同時也建立了10個并發連接),直到并發連接數達到1000。
上面代碼中,每個客戶端發送請求消息間隔時間是60秒。如果服務端 保持連接的時長小于60秒(比如 Nginx就是通過?keepalive_timeout 50;?這樣設置的),就會造成連接 被 服務端主動斷開,下次次發送請求要重新進行連接。
Linux下 可以通過 如下命令 查看并發連接的數量
netstat -an | grep ESTABLISHED | grep -w 80 | wc -l作為客戶端,本地可以打開的socket 數量 受操作系統的限制。
我測試過,
在 Windows 10 專業版 16G內存 可以打開6萬個并發連接
而在Linux上通過修改 ip_local_port_range 參數,也可以打開 6萬個并發連接。
并發用戶
通常,并發用戶數指標,適用于 測試 面向真實用戶的 系統,比如 淘寶。
一個用戶的一個操作可能引發多個并發連接
單獨說 并發用戶數 這個指標沒有意義, 必須指定是?哪種性能測試場景?下的并發用戶數。
因為用戶的操作行為不一樣,對服務端的 請求數量 和 并發連接數也不一樣。
而且并發用戶指標 是?一段時間?內 的,說某個時間點的 并發用戶數 也沒有意義,因為該點上,很多用戶可能沒有任何操作。
CPU/內存/磁盤/網絡 負載
我們做性能測試時,不能只看 TPS、響應時長 等指標是否達到,也要看被測系統在達到這些指標時,機器本身的負載情況。
所謂負載情況,主要是: CPU占用率, 內存使用,磁盤IO、磁盤使用率。
測試結束后可以產生系統資源使用圖。
在性能測試分析時,我們主要關注這兩點
- 是否接近滿負荷
如果在達到這些指標時,機器已經處于滿負荷狀態:CPU使用率 接近 100%, 內存幾乎用光,那也是不行的。 因為隨時系統可能出問題。
就是說再加點壓力,或者再持續一段時間,就很可能出現響應超時甚至響應錯誤的情況。
- 是否資源使用持續上升
這點特別體現在 內存使用率 上。
如果系統資源使用圖上,內存使用率是一個斜線不斷上升,的情況,那么很可能被測系統存在內存泄露。
這樣只要再持續一段時間,就很可能出現系統因內存耗盡而奔潰的現象。
出現這樣的圖表,就應該添加測試用例,做一個較長時間的性能測試(longevity testing),觀查系統的行為。
性能測試實戰流程
參考教程
JMeter
JMeter快速上手
參考鏈接:
安裝他提供給我的網站:安裝運行 | 白月黑羽 (byhy.net)
GUI模式 運行
運行JMeter 有2種運行模式:?GUI 圖形界面模式?和?CLI 命令行模式
前者是開發調試用的,后者才是真正執行壓力測試時用的
現在就是開發階段,當然先使用 圖形界面模式,等調試沒有問題,再使用命令行模式
HTTP請求默認值
測試過程中,被測系統換了, 就要換配置的地址, 要手動修改 請求參數,請求取樣器多了, 就非常麻煩了。
可以使用HTTP請求默認值?解決這個問題。
錄制網站流量
JMeter提供了錄制瀏覽器的請求的方法,使用的是代理抓包的機制。
-
確保?
HTTP請求默認值?里面的服務器IP 和錄制的網址一致否則錄制時,每個HTTP請求里面都會帶上IP,還得手工修改刪除,不利于統一使用
HTTP請求默認值?里面的服務器IP。 -
在整個測試計劃下面添加?
HTTP代理服務器英文叫?
HTTP(S) Test Script Recorder -
在?
線程組?里面 添加?邏輯控制器 -> 錄制控制器 -

-
設置
HTTP代理服務器-
分組 選項 選擇:?
將每個組放到新的事物控制器中 -
如果你需要錄制時過濾掉一些請求
點擊Request Filtering 配置頁,
排除模式下 添加 你要 過濾掉 不抓取的 的類型資源 ,使用的是正則表達式
- 點擊代理服務器的啟動按鈕

-
-
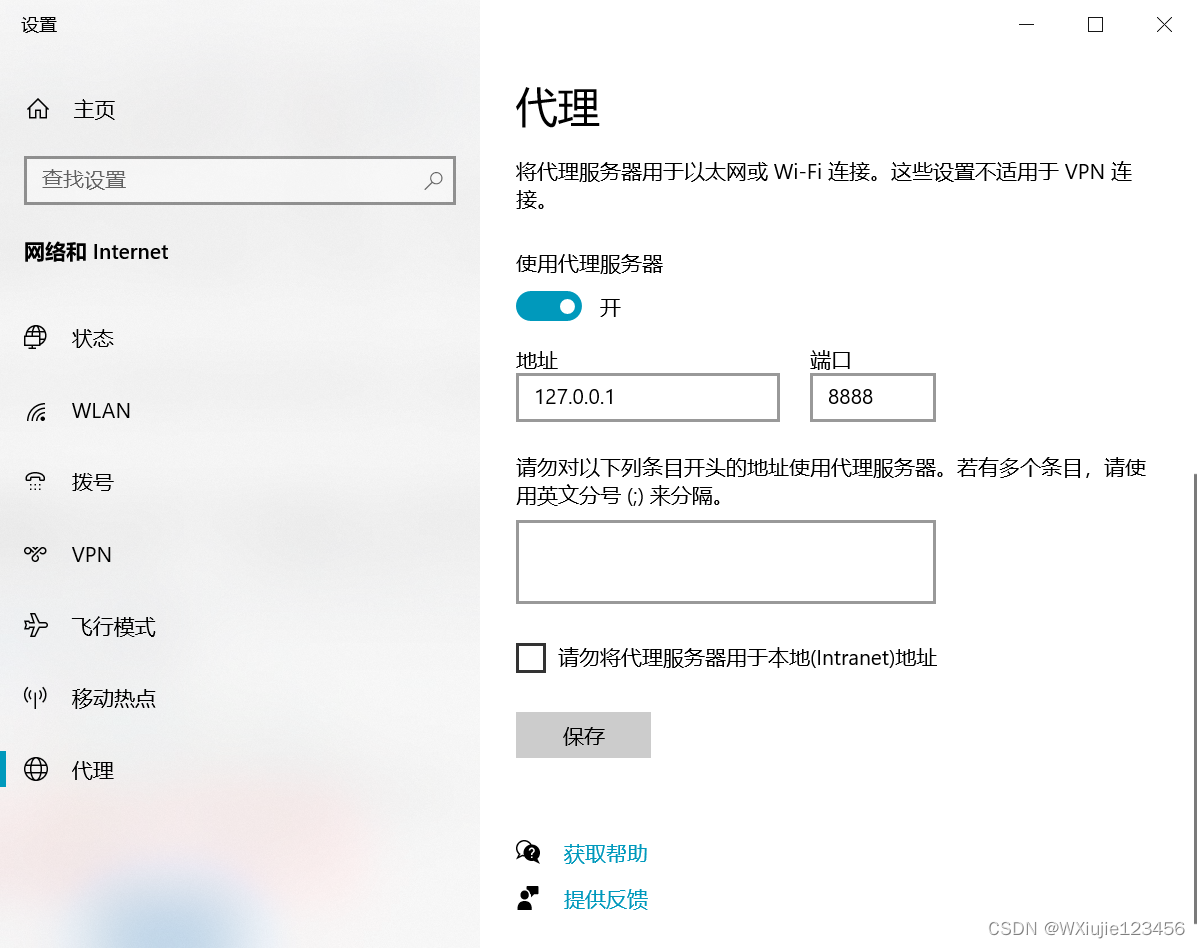
設置瀏覽器代理為 本機(localhost) 的 8888端口,進行對應的界面操作
應該發現抓到了相應的請求。
?其中,配置過程中遇到了JMeter錄制不上的情況,按照下面的方法來
jmeter性能測試腳本錄制不了的幾種情況_jmeter錄制腳本不成功_曹紅杏的博客-CSDN博客
這個問題前后花了我三四個小時,上述教程我在很前期就見過,也照著做了,但是在查ip的時候我偷懶在瀏覽器搜的本機ip,查到的是本機對外(公網)的一個ip,但是教程中用的是一個局域網ip,導致就各種嘗試都不對,真tm開心。
具體流程如下:
edge瀏覽器下:設置->搜索“代理”
???????
注意,瀏覽器訪問要錄制的頁面要設置成本機ip的方式訪問(有坑:外網IP和內網ip的區別-CSDN博客)
基本就可以錄制了。
對了要注意 它錄制的是一定時間間隔內操作的網絡訪問所以在錄制時,瀏覽器窗口還是盡可能干凈些吧。
此外打開f12,關閉cookie緩存

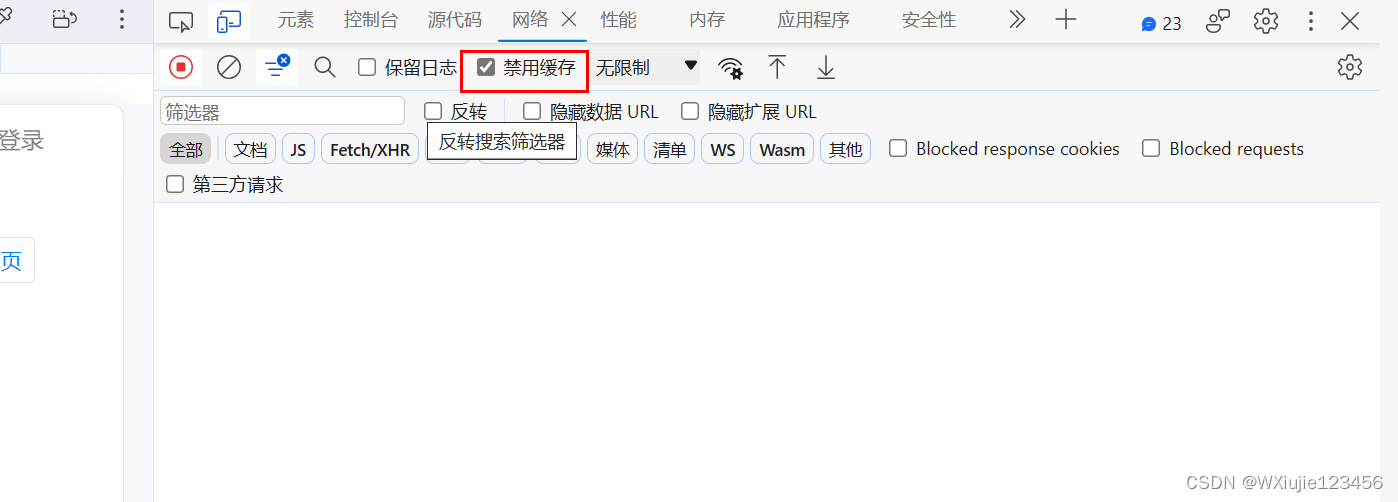
-
右鍵點擊?
錄制線程組?點擊?驗證?,查看一下是否能正確模擬 -
繼續其它場景的錄制和拖動
-
結束錄制,修改瀏覽器設置,取消代理
模擬間隔時間
場景1中兩組請求中間沒有間隔,不符合實際情況。
怎么讓它們有間隔呢?
可以使用 JMeter的?定時器 Timer
定時器 執行優先級高于 取樣器, 會先暫停, 可以放在下一個消息的前面
也可以使用 取樣器 里面的?測試活動 flow control action?取樣器
Cookie管理器
假設現在有一個性能測試用例,要求:
用戶數量 1200 個, 賬號為 sz_000001 ~ sz_001200, 密碼都是 111111在10分鐘依次進行如下操作 :打開登錄頁,進行登錄后,進入首頁
如果你還用前面錄制的方式,錄制后,驗證一下,就可以發現:
有些后續的API請求返回的結果是錯誤,返回信息表示,沒有登錄。
即使前面 發送的登錄請求返回表示成功了。 為什么呢?
這是因為 這個被測系統 使用的 用戶驗證機制是?Cookie Session機制
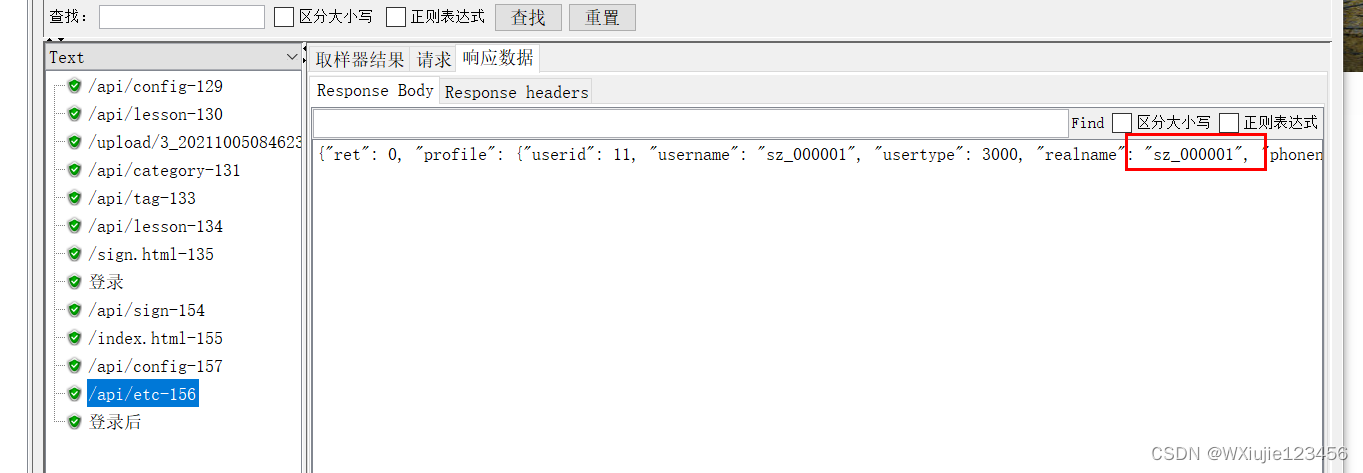
這就需要 讓JMeter自動把接收到的 HTTP 響應消息中的?Cookie?保存起來,并且在后續發給該網站的請求中自動攜帶上, 可以在測試計劃節點下面添加一個?HTTP Cookie管理器

效果
消息數據關聯
做API接口性能測試的時候,后面的請求參數 往往 需要?根據前面的請求結果?來決定。
這樣,測試工具填入的數據就是動態的,沒法預先寫死。
比如前面的測試場景,后續還需要做如下操作:
用戶登錄后,打開?學習中心 -> 我的任務?頁面,查看前2個任務。
這樣,就要獲取前2個任務的id, 因為每個學員?任務分配?的id都是不一樣的。
JMeter 需要 從 前面 列出任務的 HTTP API響應結果 里面提取出 ID, 供后面的請求使用。
如何做到呢?
這就要使用?后置處理器?和?變量?。
JMeter 通過 后置處理器 取出 取樣器響應結果中 要提出取出來的數據, 存入變量,后續請求使用這些變量。
變量
JMeter中,使用變量,是通過?${變量名}?這樣的格式
變量可以用戶自己定義產生,也可以由前置處理器、后置處理器 等 JMeter 元件產生。
有的是JMeter內置變量,比如表示當前線程號的變量?__threadNum?,就可以這樣使用?${__threadNum}
后置處理器
后置處理器通常用于對 取樣器 結果進行后續處理。
后置處理器 的有效范圍是 同級所有取樣器,如果只要針對某個取樣器,應該添加在它下面
常用的一個后置處理器是?JSON提取器?, 可以把 HTTP響應消息中的數據提取到變量中,供后續使用
說明文檔:https://jmeter.apache.org/usermanual/component_reference.html#JSON_Extractor
測試網頁:?http://jsonpath.herokuapp.com
具體操作紀律:
打開錄制功能,分別錄制下面的 動作

分別點擊下面兩個按鈕
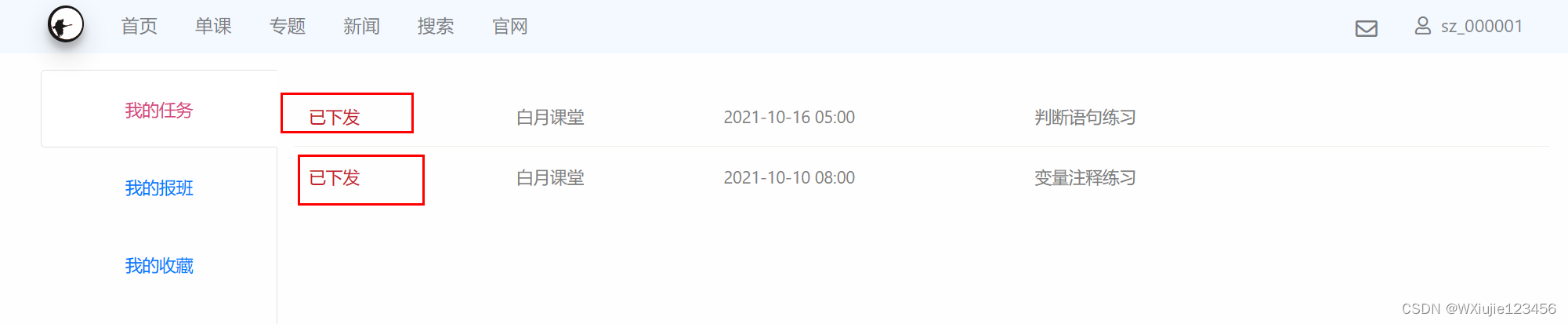

這些操作盡可能快的做完,錄制上,然后點擊自己錄制的結果,翻閱一下,把鏈接不是來自192.168.172.1的那些請求刪掉(可能是瀏覽器本身在刷新訪問其他頁面,含有一些隱形的操作也被錄了進來)
然后把這批請求組成的事務拖動到含有登錄操作的線程組下面,閱讀接口 手冊(或者自己簡單翻閱一下或者網頁查看f12),找到單擊動作得到的id值對應的請求鏈接(上面那張截圖的兩個“我的任務”的訪問需要這個id),然后給這個請求“/api/assignment-391”添加后置處理器->Josn提取器。

提取器的設置如下
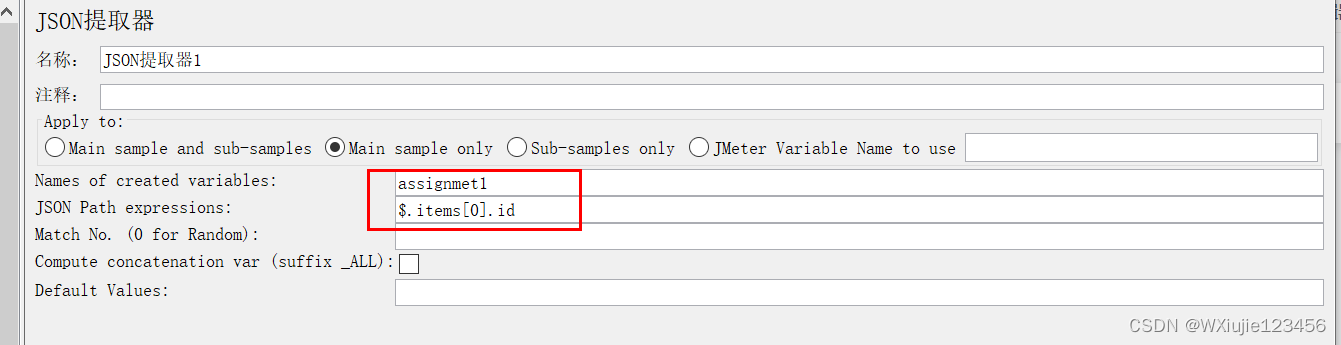
然后將上面JSON提取器設置的變量給需要引用他的頁面引用一下

然后 驗證一下有沒有成功,下圖可見傳參成功
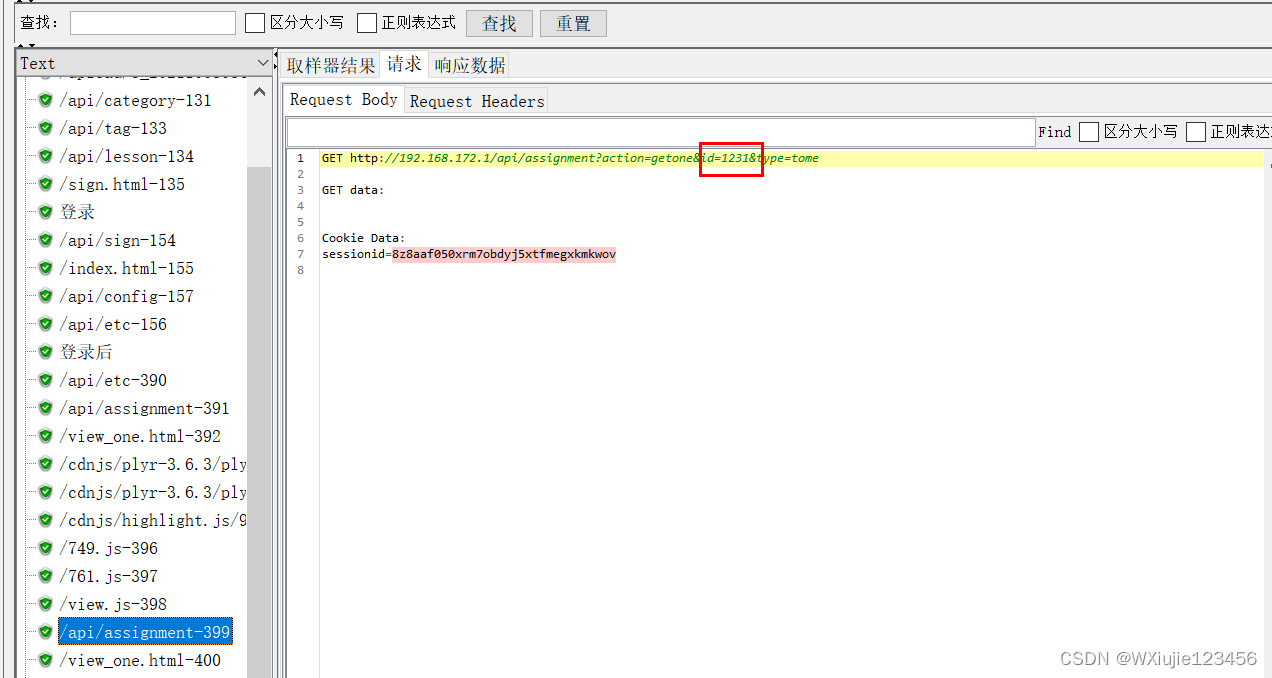
HTTP響應中有UTF8編碼的中文顯示為亂碼,可以再設置一個?BeanShell PostProcessor?類型的后置處理器,并且在?Script?中增加?prev.setDataEncoding("UTF-8");
CSV 數據文件設置
有時候,性能測試有大量的數據 需要從 CSV 格式的文件讀入使用。
CSV格式的文件,其實就是文本文件,里面記錄了性能測試數據,比如
sz_000001,111111
sz_000002,111111
sz_000003,111111
這時,可以在某個?線程組下面?添加?CSV data set config(CSV 數據文件設置)?元件
CSV 數據文件設置可以為每列設置一個變量名,比如上例就是?loginname,password
JMeter會把 每行數據依次分配給一個線程。
這樣,每個線程里面的元件 就可以使用 這些變量 ,得到對應的數據。
具體使用?點擊這里參考官方文檔
得到csv文件的方式 :上面的三行數據拷貝放到一個空的data.txt文件中,然后改后綴為csv
設置如下,可見又設置了兩個變量

引用兩個變量

斷言
利用JMeter斷言, 可以判定 從被測系統 收到的響應消息是否正確。
斷言的有效范圍是 同級所有取樣器,如果只要針對某個取樣器,應該添加在它下面。
例如,可以判斷響應是否包含某些特定文本、數據。
甚至可以使用 Groovy、 BeanShell 這樣的腳本語言做 更加靈活的斷言判定。
比如下面使用?JSR223 斷言?腳本,可以檢查JSON格式消息體響應中的total字段值是否小于10
import groovy.json.JsonSlurperdef jsonSlurper = new JsonSlurper();
def retObj = jsonSlurper.parseText(prev.getResponseDataAsString());if(retObj.total < 10){AssertionResult.setFailureMessage("retObj.total <10");AssertionResult.setFailure(true);
}


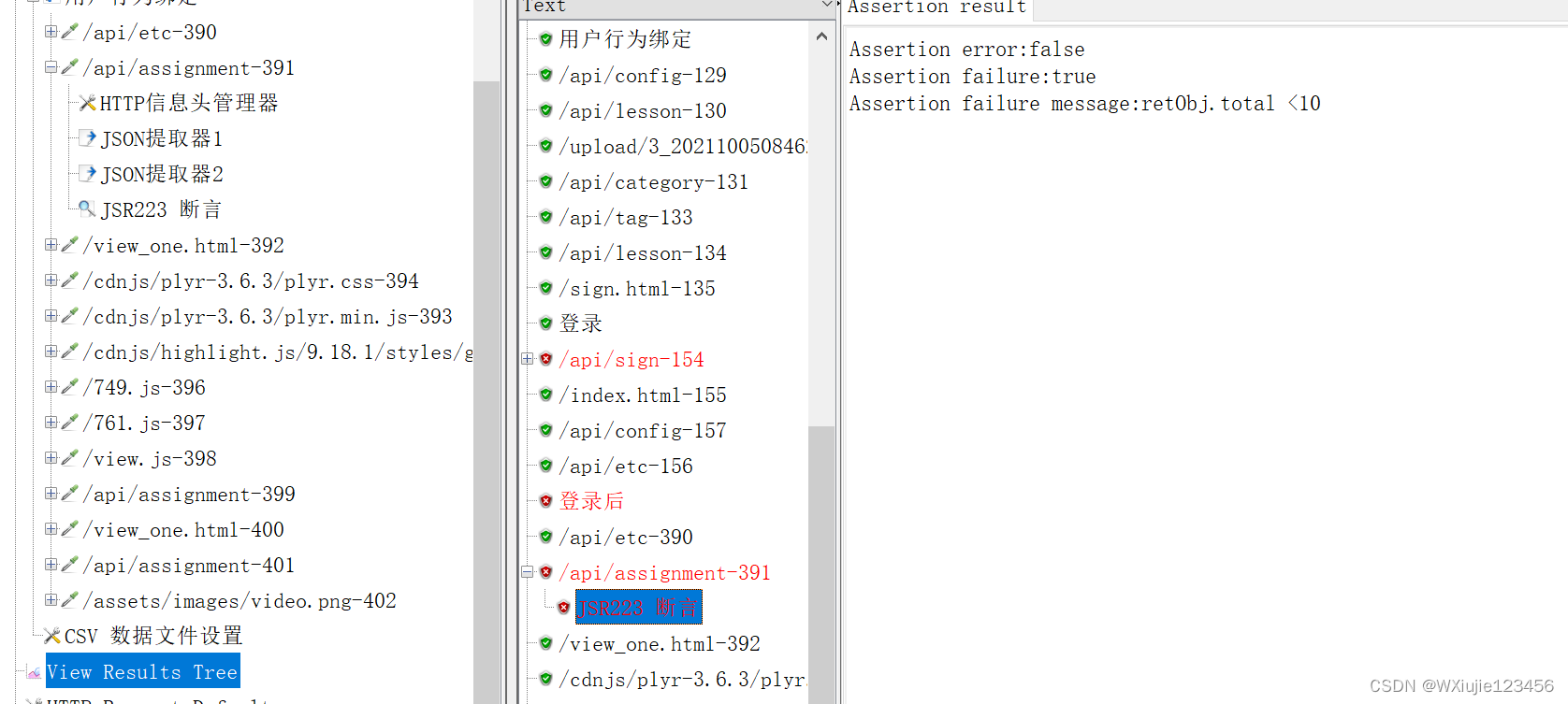
循環控制器
線程組可以整體循環, 但是如果你只想循環 線程組其中的一部分操作呢?
比如:
用戶登錄一次, 后續操作循環10次,每次間隔20秒 可以使用循環控制器。
循環控制器 內部的元件有時 需要用到?當前循環序號?。
JMeter 的當前循環序號放到變量?__jm__<循環控制器名稱>__idx?中。
比如你的 循環控制器 名為 LC, 你就可以通過?${__jm__LC__idx}?訪問到 當前循環序號。

預處理器
預處理器 在取樣器請求 發出前執行一些操作
用的比較多的是:設置一些參數、修改取樣器的設置、腳本預處理
有效范圍是同級所有取樣器,如果只要針對某個取樣器,應該添加在它下面。
常用的有 用戶參數、HTML鏈接解析器、JSR223/BeanShell 等前置處理器
比如,下面JSR223前置處理器的代碼可以把一個 當前循環序號變量值進行預先處理 加1。
long number = Long.parseLong(vars.get('__jm__LC1__idx'))
number = number + 1;
vars.put('loopno',String.valueOf(number))
// OUT.println vars.get('loopno')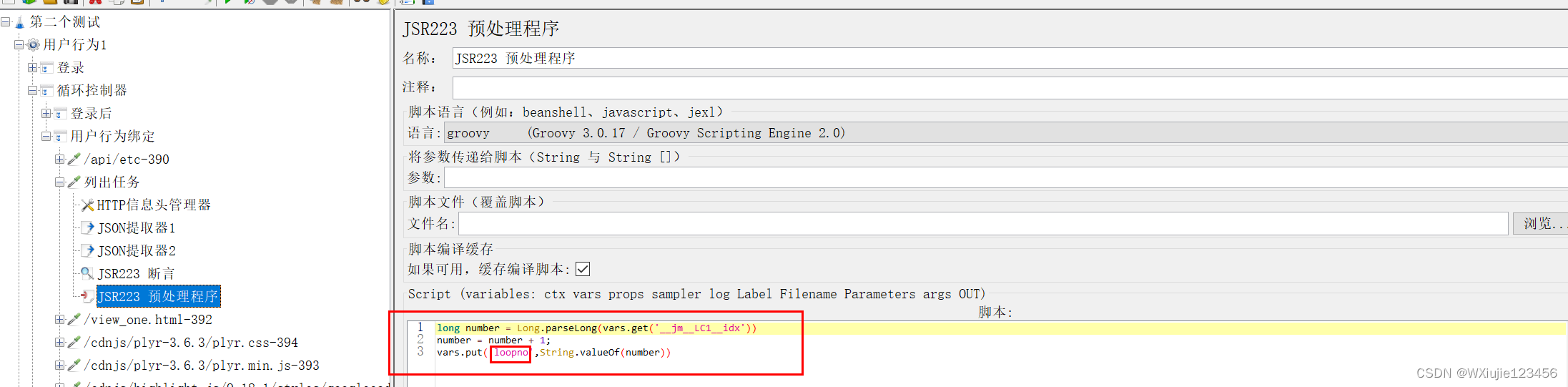

命令行模式 運行
真正實施性能測試應該在命令行模式下運行,命令格式如下:
E:\apache-jmeter-5.6.2\bin\jmeter -n -t loadtest-case1.jmx -l log.jtl注意JMeter的路徑替換為你的安裝路徑
假設 我們有如下的性能測試用例
只有一種用戶行為:無需登錄,先訪問首頁,再訪問 單課頁 ,再訪問 新聞頁
訪問頁面間隔 10 秒用戶數量 1200 個,在10分鐘依次上線dashboard 產生圖表
E:\apache-jmeter-5.6.2\bin\jmeter -g log.jtl -o report1就會產生report1目錄,里面的index.html 打開就是報告
注意?-o?后面的目錄 一定要不存在,或者內容為空,否則會報錯。
其中?APDEX (Application Performance Index)?里面的?T (Toleration threshold)?和?F (Frustration threshold)?可以通過 JMeter 工具 bin 目錄下面的?user.properties?配置文件里面 這兩個選項來設置
jmeter.reportgenerator.apdex_satisfied_threshold
jmeter.reportgenerator.apdex_tolerated_threshold我的一些結果
 ?
?
 ?
?
我本機結果比較抽風,領會精神吧
 ?
?
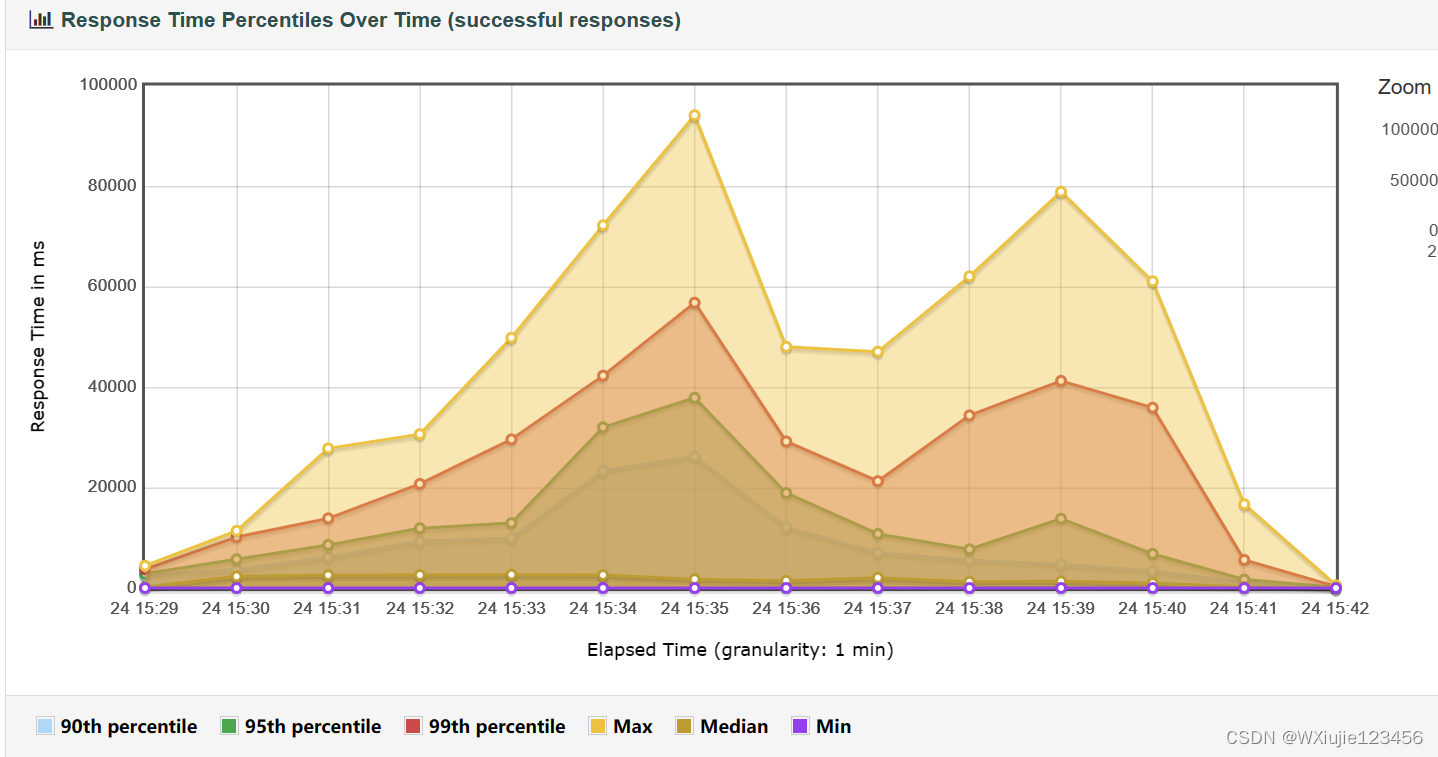 ?
?
 ?
?
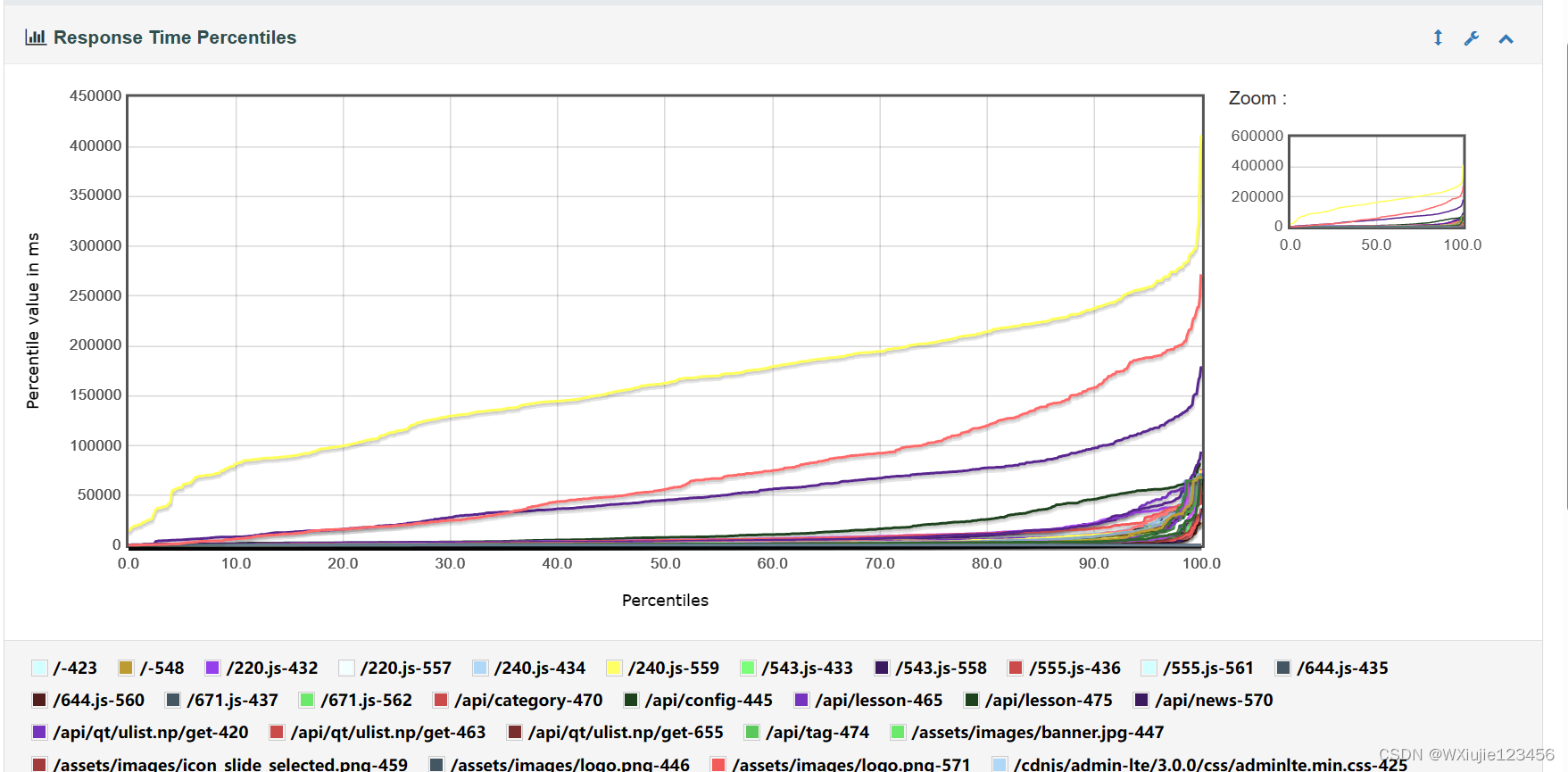

))

和4.輸出部分(線性層、softmax層))
)














