前面我們已經學習了STL中底層為紅黑樹結構的一系列關聯式容器——set/multiset 和 map/multimap(C++98).
unordered系列關聯式容器
在C++98中, STL提供了底層為紅黑樹結構的一系列關聯式容器, 在查詢時效率可達到log2N,即最差情況下需要比較紅黑樹的高度次, 當樹中的節點非常多時, 查詢效率也不理想.
最好的查詢是, 進行很少的比較次數就能夠將元素找到, 因此在C++11中, STL又提供了4個unordered系列的關聯式容器, 這四個容器與紅黑樹結構的關聯式容器使用方式基本類似, 只是其底層結構不同.
map,set系列容器和unordered_map,unordered_set系列容器的區別?
1.它們的底層結構是不一樣的:
set/multiset 和 map/multimap它們的底層結構是紅黑樹, 而unordered系列的——unordered_map/unordered_multimap, unordered_set/unordered_multiset它們的底層是哈希表.
unordered系列中, 帶multi的和不帶multi的區別也是允許鍵值重復出現和不允許重復出現的問題.
2.從名字上我們其實就能得出它們的第二個區別:
unordered是無序的意思,?所以map和set我們用迭代器遍歷, 得到的是有序的序列, unordered系列去遍歷的話, 得到的是無序的,?單從使用上來說最大的區別就是有沒有序的問題.
3.map和set系列它們的迭代器是雙向迭代器,?而unordered系列它們的迭代器是單向迭代器.
4. unorder _ map 容器通過鍵訪問單個元素的速度比 map 容器快, 盡管它們通過元素的子集進行范圍迭代的效率通常較低.(和底層實現有關)
?unordered_map和unordered_set的使用
單從使用來說, 這和set/multiset 和 map/multimap的使用用法基本一致, 常用的接口都差不多.
unordered_map的接口:

unordered_map的構造:
| 函數聲明 | 功能介紹 |
| unordered_map | 構造不同格式的unordered_map對象 |
?unordered_map的容量:
| 函數聲明 | 功能介紹 |
| bool empty() const | 檢測unordered_map是否為空 |
| size_t size() const | 獲取unordered_map的有效元素個數 |
unordered_map的迭代器:
| 函數聲明 | 功能介紹 |
| begin | 返回unordered_map第一個元素的迭代器 |
| end | 返回unordered_map最后一個元素下一個位置的迭代器 |
| cbegin | 返回unordered_map第一個元素的const迭代器 |
| cend | 返回unordered_map最后一個元素下一個位置的const迭代器 |
unordered_map的元素訪問:
| 函數聲明 | 功能介紹 |
| operator[] | 返回與key對應的value |
注意: 該函數中實際調用哈希桶的插入操作, 用參數key與V()構造一個默認值往底層哈希桶
中插入, 如果key不在哈希桶中, 插入成功, 返回V(); 插入失敗, 說明key已經在哈希桶中,
將key對應的value返回
unordered_map的查詢:
| 函數聲明 | 功能介紹 |
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中關鍵碼為key的鍵值對的個數 |
注意:?unordered_map中key是不能重復的,因此count函數的返回值最大為1?
unordered_map的修改:
| 函數聲明 | 功能介紹 |
| insert | 向容器中插入鍵值對 |
| erase | 刪除容器中的鍵值對 |
| void clear() | 清空容器中有效元素個數 |
| void swap(unordered_map&) | 交換兩個容器中的元素 |
unordered_map的桶操作:
| 函數聲明 | 功能介紹 |
| size_t bucket_count()const | 返回哈希桶中桶的總個數 |
| size_t bucket_size(size_t n)const | 返回n號桶中有效元素的總個數 |
| size_t bucket(const K& key) | 返回元素key所在的桶號 |
它的迭代器沒有rbegin、rend, 因為它的迭代器是單向的,不支持反向遍歷。
?unordered_set的接口:
 ?接口也都差不多,只是set系列的沒有[]和at接口.
?接口也都差不多,只是set系列的沒有[]和at接口.
#include<set>
#include<unordered_set>
#include<iostream>
using namespace std;int main()
{set<int> s1;unordered_set<int> s2;s1.insert(1);s1.insert(5);s1.insert(4);s1.insert(3);s1.insert(8);for (set<int>::iterator it = s1.begin(); it != s1.end(); it++)cout << *it << " ";
//cout << endl;
//s2.insert(1);s2.insert(5);s2.insert(4);s2.insert(3);s2.insert(8);for (unordered_set<int>::iterator it = s2.begin(); it != s2.end(); it++)cout << *it << " ";return 0;
} ?
?
可以看到set按迭代器訪問是有序的, unordered_set按迭代器訪問是按照插入順序訪問的, unordered_map也是一樣.
set與unordered_set性能對比?
void test2()
{srand(time(nullptr));size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);for (size_t i = 0; i < N; i++){v.push_back(rand()+i);//減少重復值}size_t begin1 = clock();for (auto& e : v)s.insert(e);size_t end1= clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto& e : v)us.insert(e);size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto& e : v)s.find(e);size_t end3 = clock();cout << "set find:" << end3- begin3 << endl;size_t begin4 = clock();for (auto& e : v)us.find(e);size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl;size_t begin5 = clock();for (auto& e : v)s.erase(e);size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto& e : v)us.erase(e);size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl;}
所以, 綜合而言, unordered系列的效率是比較高的, 尤其是find的效率.
OJ例題
349. 兩個數組的交集 - 力扣(LeetCode)?
 map和set的例題-CSDN博客
map和set的例題-CSDN博客
之前有用set的解法, 排序加去重可以解決, 現在可以用unordered_set, unordered_set雖然不能排序, 但是也是可以去重的, 首先我們先對兩個數組進行去重, 然后, 我們遍歷其中一個數組, 遍歷的同時去依次判斷當前元素在不在另一個數組中, 如果在就是交集。

?350. 兩個數組的交集 II - 力扣(LeetCode)

返回結果中每個元素出現的次數, 應與元素在兩個數組中都出現的次數一致(如果在兩數組中出現次數不一致,則考慮取較小值), 但是它沒有要去輸出結果中每個元素是唯一的。?

?

統計次數, 判斷有沒有次數大于1的就行了:

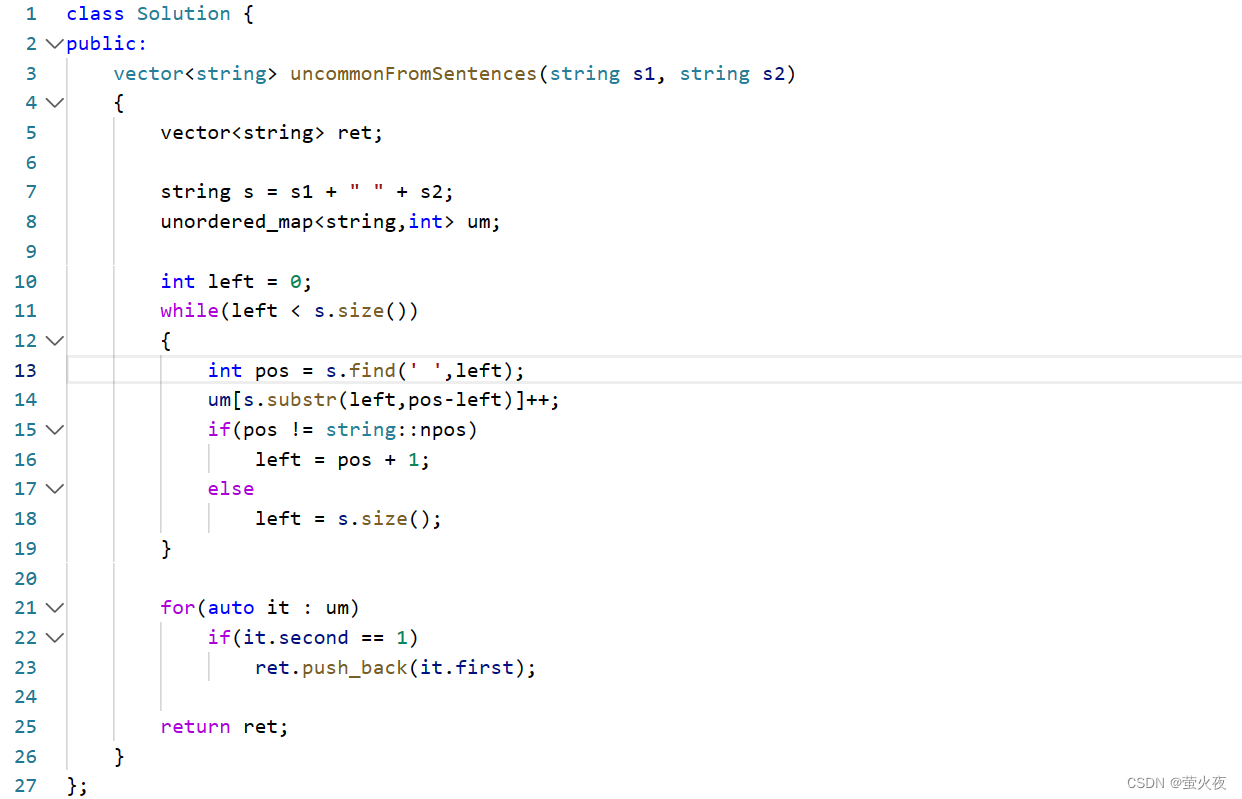
?884. 兩句話中的不常見單詞 - 力扣(LeetCode)
 這道題其實可以求轉化成兩個字符串合并后, 只出現一次的單詞.
這道題其實可以求轉化成兩個字符串合并后, 只出現一次的單詞.
 ?
?




)





![[autojs]ui線程中更新控件的值的問題](http://pic.xiahunao.cn/[autojs]ui線程中更新控件的值的問題)








