文章目錄
- 介紹
- 思路
- CoT方法
- Few-shot CoT
- CoT Prompt設計
- CoT
- 投票式CoT-自洽性(Self-consistency)
- 使用復雜的CoT
- 自動構建CoT
- CoT中示例順序的影響
- Zero-shot CoT 零樣本思維鏈
- GoT,Graph of Thoughts
- 總結
介紹
在過去幾年的探索中,業界發現了一個現象,在增大模型參數量和訓練數據的同時,在多數任務上,模型的表現會越來越好。因而,現有的大模型LLM,最大參數量已經超過了千億。
然而,增大模型參數規模,對于一些具有挑戰的任務(例如算術、常識推理和符號推理)的效果,并沒有太大提升。對于算術類推理任務,我們期望模型生成自然語言邏輯依據來指導并生成最終答案,但是獲得邏輯依據是比較復雜昂貴的(標注成本層面)。
自從發現了大模型ICL(In-Context Learning)的能力后,這個問題有個新的解決思路:對某個任務Task,能否為大模型提供一些上下文in-context example作為Prompt,以此來提升模型的推理能力?實驗表明,在復雜推理任務上加入ICL帶來的增益不明顯。因此,便衍生出了CoT的技術。
Chain-of-Thought(CoT)是一種改進的Prompt技術,目的在于提升大模型LLM在復雜推理任務上的表現,如算術推理(arithmetic reasoning)、常識推理(commonsense reasoning)、符號推理(symbolic reasoning)。思維鏈(CoT)便是一種用于設計 prompt 的方法,即 prompt 中除了有任務的輸入和輸出外,還包含推理的中間步驟(中間思維)。研究表明,CoT 能極大地提升 LLM 的能力,使之無需任何模型更新便能解決一些難題。
思路
ICL的思路是在新測試樣本中加入示例(demonstration)來重構prompt。
與ICL(In-Context Learning)有所不同,CoT對每個demonstration,會使用中間推理過程(intermediate reasoning steps)來重新構造demonstration,使模型在對新樣本預測時,先生成中間推理的思維鏈,再生成結果,目的是提升LLM在新樣本中的表現。
CoT方法
一般來說CoT會分為兩種:基于人工示例標注的Few-shot CoT和無人工示例標注的Zero-shot CoT。下面將逐一介紹。
Few-shot CoT
假設基于ICL的測試樣本輸入表示為 < i n p u t , d e m o n s t r a t i o n s > <input, demonstrations> <input,demonstrations>,那么加入Few-shot CoT的測試樣本輸入,可表示為 < i n p u t , C o T > <input, CoT> <input,CoT>。
CoT Prompt設計
我們知道了加入CoT的示例后,能提升LLM的表現。那么我們應該如何構造或使用CoT?
CoT
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
這是思維鏈的開山之作。GPT 生成式預訓練模型中的“T”,也就是 Transformer,就是谷歌大腦搞出來的。但是,預訓練 + 精調的大模型搞了幾年,仍然沒辦法很好地完成多步驟推理任務,比如數學問題和常識推理。
所以 Jason Wei 等人提出了思維鏈提示的方法,真的一下子就讓大模型的邏輯推理能力不一樣了。
具體來說,有三個不一樣:
- 常識推理能力趕超人類。以前的語言模型,在很多挑戰性任務上都達不到人類水平,而采用思維鏈提示的大語言模型,在 Bench Hard(BBH) 評測基準的 23 個任務中,有 17 個任務的表現都優于人類基線。比如常識推理中會包括對身體和互動的理解,而在運動理解 sports understanding 方面,思維鏈的表現就超過了運動愛好者(95% vs 84%)。
- 數學邏輯推理大幅提升。一般來說,語言模型在算術推理任務上的表現不太好,而應用了思維鏈之后,大語言模型的邏輯推理能力突飛猛進。MultiArith 和 GSM8K 這兩個數據集,測試的是語言模型解決數學問題的能力,而通過思維鏈提示,PaLM 這個大語言模型比傳統提示學習的性能提高了 300%!在 MultiArith 和 GSM8K 上的表現提升巨大,甚至超過了有監督學習的最優表現。這意味著,大語言模型也可以解決那些需要精確的、分步驟計算的復雜數學問題了。
CoT 提示過程是一種最近開發的提示方法,它鼓勵大語言模型解釋其推理過程。思維鏈的主要思想是通過向大語言模型展示一些少量的 exapmles,在樣例中解釋推理過程,大語言模型在回答提示時也會顯示推理過程。這種推理的解釋往往會引導出更準確的結果。
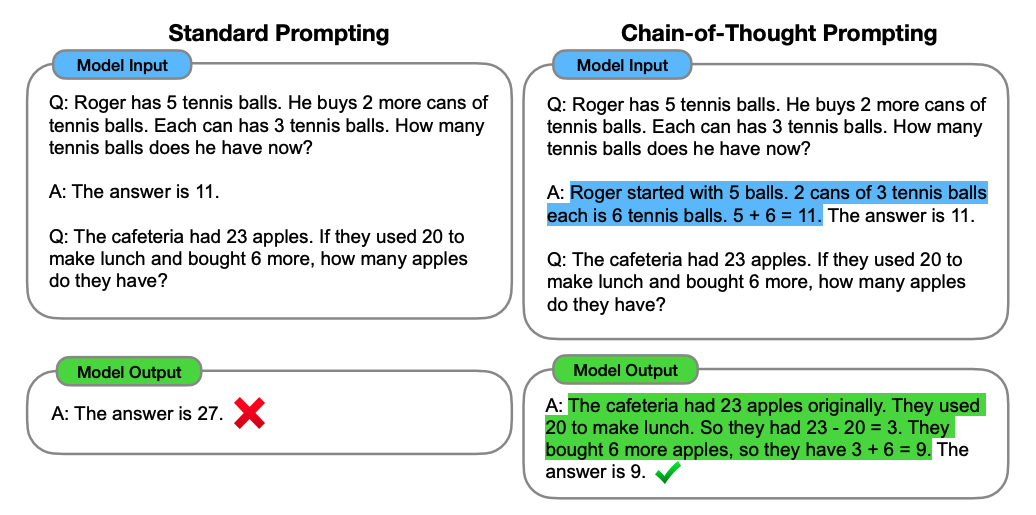
以一個數學題為例:
標準prompting,模型輸入:
問:羅杰有5個網球,他又買了兩盒網球,每盒有3個網球。他現在有多少網球?
答:答案是11
問:食堂有23個蘋果,如果他們用掉20個后又買了6個。他們現在有多少個蘋果?
模型輸出:
答:答案是27 × \times ×
可以看到模型無法做出正確的回答。但如果說,我們給模型一些關于解題的思路,就像我們數學考試,都會把解題過程寫出來再最終得出答案,不然無法得分。CoT 做的就是這件事,示例如下:
CoT prompting,模型輸入:
問:羅杰有5個網球,他又買了兩盒網球,每盒有3個網球。他現在有多少網球?
答:羅杰一開始有5個網球,2盒3個網球,一共就是2*3=6個網球,5+6=11。答案是11.
問:食堂有23個蘋果,如果他們用掉20個后又買了6個。他們現在有多少個蘋果?
模型輸出:
答:食堂原來有23個蘋果,他們用掉20個,所以還有23-20=3個。他們又買了6個,所以現在有6+3=9。答案是9 ? \checkmark ?
可以看到,類似的算術題,思維鏈提示會在給出答案之前,還會自動給出推理步驟。
CoT 在實現上修改了 demonstration(示例) 每個 example 的 target,source 保留原樣,但 target 從原先的 answer(a) 換成了 rationale? + a。因此可以看到右側,所有內容均由模型生成,模型不是生成 a,而是生成r+a。
思維鏈提示,就是把一個多步驟推理問題,分解成很多個中間步驟,分配給更多的計算量,生成更多的 token,再把這些答案拼接在一起進行求解。
投票式CoT-自洽性(Self-consistency)
《Self-Consistency Improves Chain of Thought Reasoning in Language Models》
這篇文章是 CoT 后很快的一個跟進工作,是 CoT 系列改進的重要一步,在 2022 年 3 月在arxiv上被放出來。這篇文章幾乎用的和 CoT 完全一樣的數據集和設置,主要改進是對答案進行了多數投票(majority vote),并且發現其可以顯著地提高思維鏈方法的性能。
論文基于一個思想:一個復雜的推理任務,其可以有多種推理路徑(即解題思路),最終都能夠得到正確的答案。故Self-Consistency在解碼過程中,拋棄了greedy decoding的策略,而是使用采樣的方式,選擇生成不同的推理路徑,每個路徑對應一個最終答案。
具體做法為:
- 對于單一的測試數據,通過多次的解碼采樣,會生成多條推理路徑和答案。
- 基于投票的策略,選擇最一致的答案。
在下面的圖中,左側的提示是使用少樣本思維鏈范例編寫的。使用這個提示,獨立生成多個思維鏈,從每個思維鏈中提取答案,通過“邊緣化推理路徑”來計算最終答案。實際上,這意味著取多數答案。
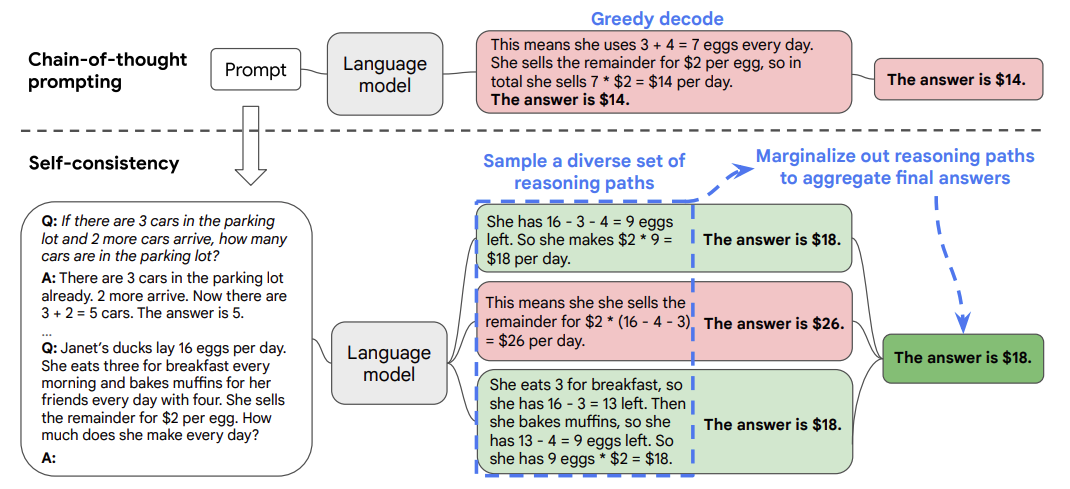
實驗表明,對于同一問題生成更多的推理鏈以供投票往往能取得更好的效果。當推理鏈數量足夠多時,這種方法效果能夠勝過使用greedy decoding的CoT方法。
《On the advance of making language models better reasoners》
論文在Self-Consistency的基礎上,進一步做了優化。
- Diverse Prompts
- 對于每個測試問題,構造了 M 1 M_1 M1?種不同的prompt(即由不同demonstration構造的prompt)
- 對于每種不同的prompt,讓LLM生成 M 2 M_2 M2?條推理路徑。
- 則對于同一個測試問題,共生成了 M 1 ? M 2 M_1*M_2 M1??M2?條結果
- Verifier
- 訓練了一個Verifier,用于判斷當前推理路徑得出的答案正確與否。
- 關于樣本構建,使用LLM生成的推理路徑和答案,與grandtruth進行對比,一致的即視為正樣本,否則負樣本。
- Vote
- 訓練好Verifier后,對與一個測試問題與LLM生成的多條推理路徑,Verifier進行二元判別
- 結合判別結果和投票結果,得出模型的最終預測。
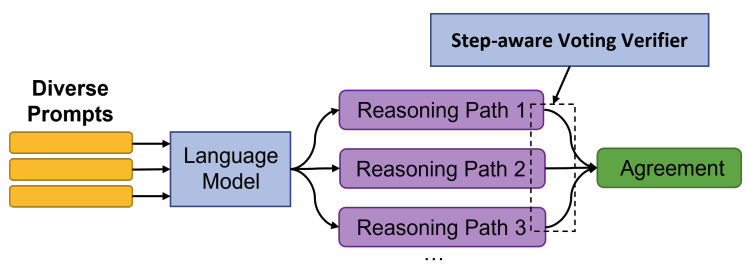
實驗結果顯示,本論文的方法相對基于Greedy Decode和Self-Consistency能得到更優的效果。
使用復雜的CoT
《Complexity-based prompting for multi-step reasoning》
面對這么多可選的CoT,簡單的CoT示例和復雜的CoT示例,對新的樣本推理結果會不會產生影響?答案是Yes。
論文探討了一個問題,在包含簡單推理路徑的demonstrations和復雜推理路徑的demonstrations下,哪個效果會表現較好?(這里的簡單和復雜是指 推理鏈/推理步驟的長度)
本論文繼承了Self-Consistency的思想,具體方法:
- 對于同一個測試問題,使用功能LLM(GPT-3)生成 N N N條不同的推理鏈+答案;
- 對于生成的推理鏈+答案,按照推理鏈的長度進行倒序排序;
- 保留TopK條推理鏈+答案,并使用投票的方式,選取最終預測。
實驗結果表明,本論文的方法效果優于以下方法: (1)人工構建Cot、(2)random Cot、(2)Complex CoT(數據集中最長的多個思維鏈作為demonstrations)。

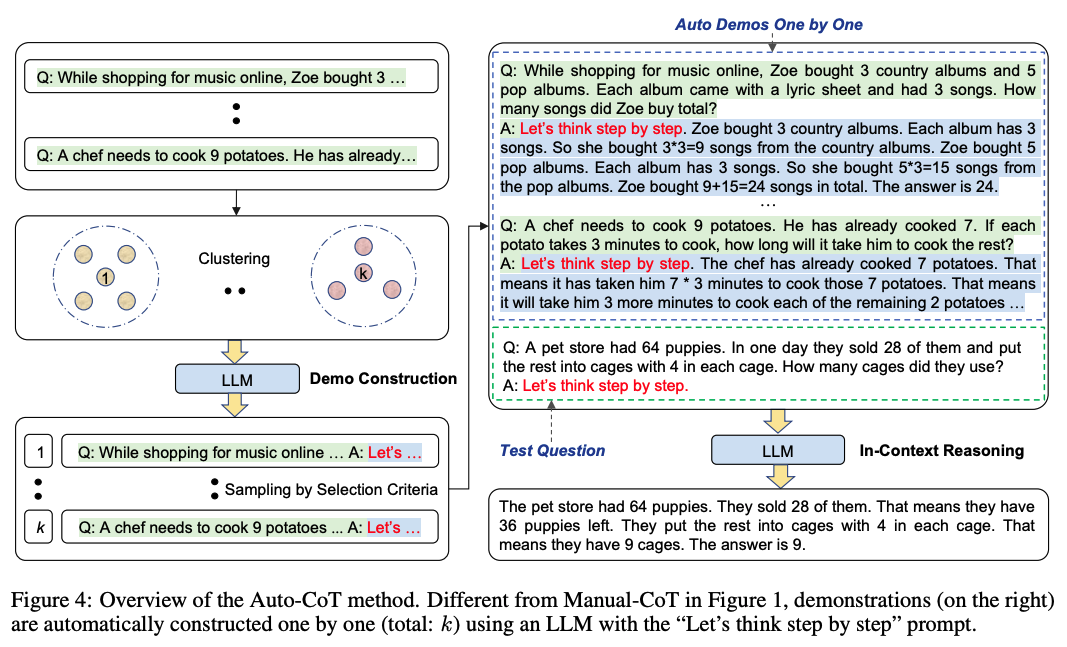
自動構建CoT
《Automatic chain of thought prompting in large language models》
上面提到的方法是基于人工構造CoT,那我們能否讓模型自己來生成CoT?本論文就提供了這樣一種自動生成CoT的思路。
本論文提到的Manual-CoT,可以等同于Few-shot CoT來理解。
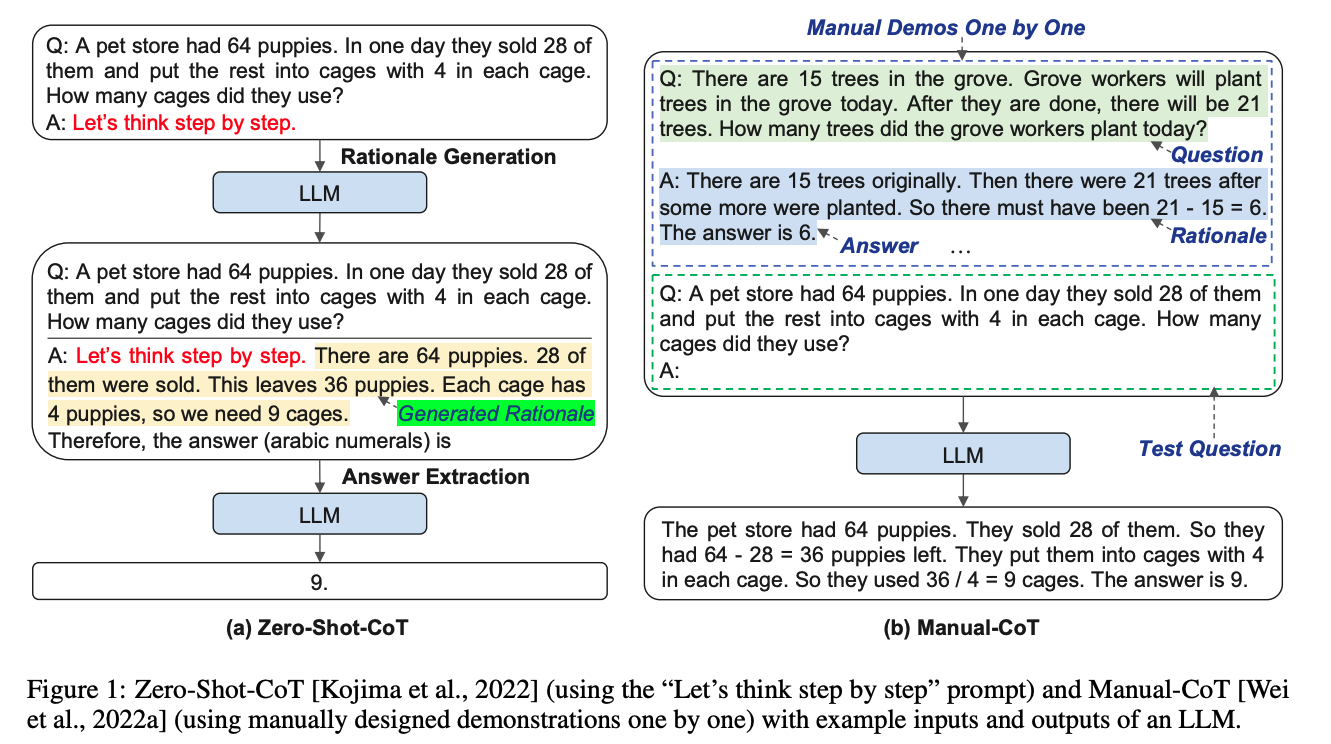
由于Zero-Shot-CoT方法存在不穩定性,而Manual-CoT方法需要大量人工成本投入。作者提出了一種基于Auto-CoT的方法,自動構建包含問題和推理鏈的說明樣例(demonstrations)。
整個過程分了兩個階段:
- question cluster: 目的是將數據集中的question劃分到不同簇中。
- 使用Sentence-Bert計算每個question的向量表示;
- 使用k-means方法將question記性簇劃分;
- 最后對每個簇中的question,根據距離中心點距離,升序排序。
- demostration sampling: 目的是從每個簇中選取一個代表性的question,基于LLMs,使用Zero-Shot-CoT生成推理鏈。
-
對于每一個簇 i i i里的每一個問題 q j ( i ) q^{(i)}_j qj(i)?,使用Zero-Shot-CoT的方法,將 [ Q : q j ( i ) , A : [ P ] ] [Q:q^{(i)}_j,A:[P]] [Q:qj(i)?,A:[P]](其中 [ P ] [P] [P]表示"Let’s think step by step")輸入到LLMs,LLMs生成該問題的推理鏈 r j ( i ) r^{(i)}_j rj(i)?和答案 a j ( i ) a^{(i)}_j aj(i)?;
-
若問題 q j ( i ) q^{(i)}_j qj(i)?不超過60個tokens,且推理鏈 r j ( i ) r^{(i)}_j rj(i)?不超過5個推理步驟,則將問題+推理鏈+答案,加入到demostrations列表中: [ Q : q j ( i ) , A : r j ( i ) 。 a j ( i ) ] [Q:q^{(i)}_j,A:r^{(i)}_j。a^{(i)}_j] [Q:qj(i)?,A:rj(i)?。aj(i)?];
-
遍歷完所有簇,將得到k個demostrations,將其拼接上測試question,構造成新的Prompt,輸入LLMs便可得到生成結果。
值得一提的是,Auto-CoT在多個開源推理任務的數據集上,效果與Manual-CoT相當,甚至某些任務表現得更好。
CoT中示例順序的影響
《Chain of thought prompting elicits reasoning in large language models》
盡管CoT是ICL的一種特殊形式,但是與ICL有所不同的是,CoT中demonstrations的排序對其在新測試樣本中的生成結果影響較小,論文對demonstrations進行重排序,在多數推理任務上僅導致小于2%的性能變化。(demonstrations順序對ICL影響較大)
Zero-shot CoT 零樣本思維鏈
與Few-shot CoT不同,Zero-shot CoT并不需要人為構造demonstrations,只需要在prompt中加入一個特定的指令,即可驅動LLMs以思維鏈的方式生成結果。
當然這種不需要人工構造demonstrations的方式,效果相對Few-shot CoT會表現稍微差一點點。但是相對Zero-shot和Few-shot的方法而言,Zero-shot CoT在復雜任務推理上卻能帶來巨大的效果提升。

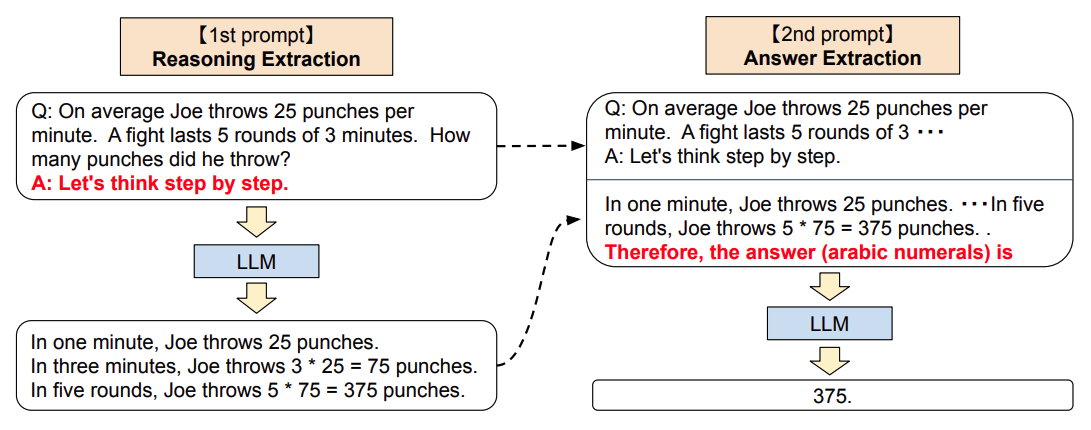
《Large language models are zero-shot reasoners》
論文首先提出了Zero-shot CoT的方法,整個流程包含兩部分:
1.Reasoning Extraction
- 使用一個特定的"reasoning" prompt,是語言模型LLM生成原始問題的思維鏈,如"Let’s think step by step."(讓我們一步步來思考)
2.Answer Extraction
- 基于第一步的結果,添加一個"answer" prompt,要求LLM生成正確的結果。
- 這一個步驟中,LLM的輸入格式為:quesiton + “reasoning” prompt + result(CoT) + “answer” prompt,輸出為:result(answer)
值得一提的是,論文同時發現了,當模型LLM變得越來越大,對于使用Zero-shot的結果帶來的增益不大,但是對使用Zero-shot CoT的結果帶來的增益較大。
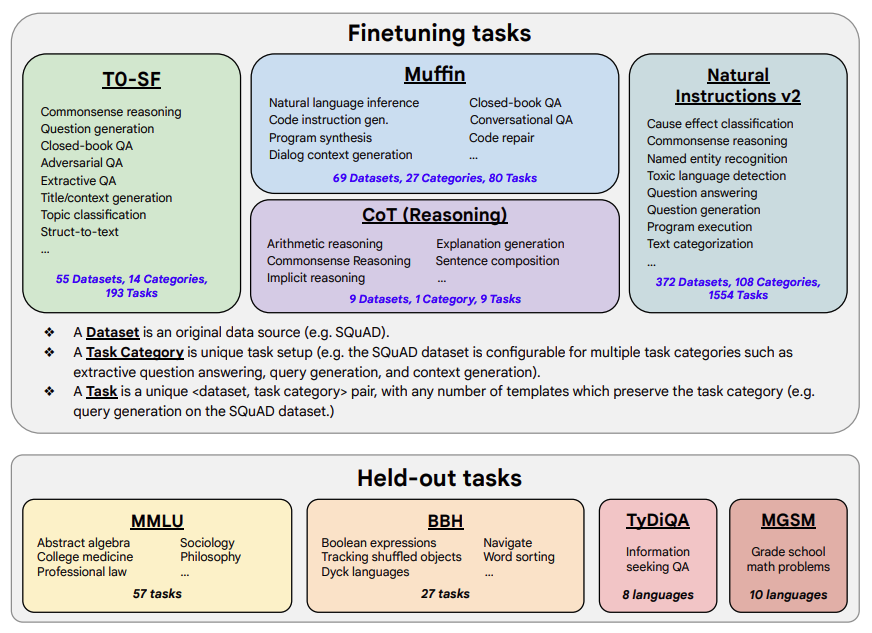
《Scaling Instruction-Finetuned Language Models》
既然在上一篇論文中,已經發現了LLM存在Zero-shot CoT的能力,那如果事先對LLM進行基于CoT的instruction tuning,那模型使用Zero-shot CoT方式在對unseen樣本進行預測時,效果會不會更好?本論文給出了肯定的答案。
論文探索了以下可能影響LLM在unseen task上表現的因素:
- 任務數量
- 模型大小
- 指令微調(instruction tuning)
論文微調數據集包含了1836種指令任務,473個數據集和146種任務類型構成,數據集中包含了9個人工標注的CoT數據集。同時保留一個沒出現過的held-out數據集作為模型評估數據集。
使用的模型是PaLM,而經過instruction tuning的模型,稱為FlanPaLM(Finetuned Language PaLM)。
- 增加微調任務數量,可以提高LLM表現。但任務數量超過一定值后,不管模型尺寸是否增大,受益都不大。推測原因有:
(1)額外的任務多樣化不足,沒有為LLM提供新的知識;
(2) 多任務指令微調只是更好地激發了模型從預訓練任務中學習到知識的表達能力,而微調任務超過一定值后,對表達能力沒有太大幫助。 - 微調和未微調的PaLM,從8B增大到540B,在unseen任務上效果越來越好;
- 微調數據與CoT數據的關系
(1) 微調數據中刪除CoT數據,會降低PaLM的推理能力
(2) 微調數據包含CoT數據,會全面提高所有評測任務的表現
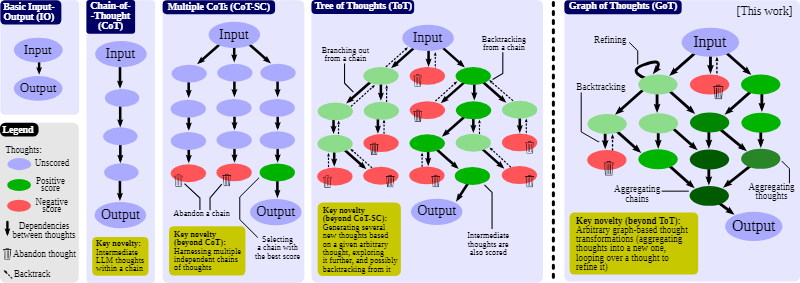
GoT,Graph of Thoughts
研究論文:https://arxiv.org/pdf/2308.09687v2.pdf
官方實現:https://github.com/spcl/graph-of-thoughts
有研究者改進了 CoT,提出了使用 CoT 實現自我一致的方法(CoT-SC);這個方案是生成多個 CoT,再選出其中最佳的結果。還有研究者更進一步提出了思維樹(ToT),其做法是通過樹(tree)來建模 LLM 推理過程。這能讓模型使用不同的思維路徑,并能提供全新的功能,比如基于不好的結果反向回溯推理過程。不幸的是,由于 ToT 方法為思維過程強加了嚴格的樹結構,所以會極大限制 prompt 的推理能力。
蘇黎世聯邦理工學院、Cledar 和華沙理工大學的一個研究團隊提出了更進一步的想法:思維圖(GoT)。讓思維從鏈到樹到圖,為 LLM 構建推理過程的能力不斷得到提升,研究者也通過實驗證明了這一點。他們也發布了自己實現的 GoT 框架。
在進行思考時,人類不會像 CoT 那樣僅遵循一條思維鏈,也不是像 ToT 那樣嘗試多種不同途徑,而是會形成一個更加復雜的思維網。舉個例子,一個人可能會先探索一條思維鏈,然后回溯再探索另一條,然后可能會意識到之前那條鏈的某個想法可以和當前鏈結合起來,取長補短,得到一個新的解決方案。類似地,大腦會形成復雜的網絡,呈現出類似圖的模式,比如循環模式。算法執行時也會揭示出網絡的模式,這往往可以表示成有向無環圖。
為了解答這些問題以及更多其它問題,這些研究者設計了一種實現 GoT 的模塊化架構。該設計有兩大亮點。
一是可實現對各個思維的細粒度控制。這讓用戶可以完全控制與 LLM 進行的對話并使用先進的思維變換,比如將正在進行的推理中兩個最有希望的思維組合起來得到一個新的。
二是這種架構設計考慮了可擴展性 —— 可無縫地擴展用于新的思維變換、推理模式(即思維圖)和 LLM 模型。這讓用戶可使用 GoT 快速為 prompt 的新設計思路構建原型,同時實驗 GPT-3.5、GPT-4 或 Llama-2 等不同模型。
總結
對于大模型LLM涌現的CoT能力,業界目前的共識是:當模型參數超過100B后,在復雜推理任務中使用CoT是能帶來增益的;而當模型小于這個尺寸,CoT并不會帶來效果增益。要讓大型語言模型(LLM)充分發揮其能力,有效的 prompt 設計方案是必不可少的,為此甚至出現了 prompt engineering 這一新興領域。
目前,思維鏈只是在一些有限的領域,比如數學問題,五個常識推理基準(CommonsenseQA,StrategyQA,Date Understanding 和 Sports Understanding 以及 SayCan)上顯現出作用,其他類型的任務,像是機器翻譯,性能提升效果還有待評估。
還記得在Pretrain+Fine-tuning時代下,對于復雜數學推理任務,如MultiArith、GSM8K下,效果還是不太理想,而短短幾年時間,LLM+CoT的模式已經大大提升了該領域的解決能力。隨著LLM的繼續發展,未來必定會發現更多LLM隱藏的能力和使用方法,讓我們拭目以待。


)







 setInterval())

)






