遙感領域的通用大模型 2023.11.13在CVPR發表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
實驗
? 在本節中,我們將嚴格評估我們的SpectralGPT模型的性能,并對其進行基準測試SOTA基礎模型:ResNet50 [36]、SeCo [37]、ViT[22]和SatMAE[30]。此外,我們評估了其在四個下游EO任務中的能力,包括單標簽場景分類、多標簽場景分類、語義分割和變化檢測,以及廣泛的消融研究。
? 我們定量評估了預訓練基礎模型在4個下游任務中的性能,包括單標簽RS場景分類任務的識別精度、多標簽RS場景分類任務的宏觀和微觀平均精度(mAP),即宏觀mAP (micro-mAP)、語義分割任務的總體精度(OA)和平均交聯(mIoU),以及變化檢測的精度、召回率和F1分數。此外,我們還進行了有見地的消融研究,探索了掩蔽比、解碼器深度、模型大小、補丁大小和訓練時代等關鍵因素。利用4個NVIDIA GeForce RTX 4090 gpu的計算能力,我們精心微調下游任務和消融研究的預訓練基礎模型,從而提供對SpectralGPT在RS域中的能力和適應性的全面見解。
A. EuroSAT上的單標簽RS場景分類
? 對于下游單標簽RS場景分類任務,我們使用EuroSAT數據集[38]。這個數據集包括從34個歐洲國家收集的27000張哨兵2號衛星圖像。這些圖像被分為10個土地使用類別,每個類別包含2000到3000個標記圖像。該數據集中的每張圖像分辨率為64 × 64像素,包含13個光譜帶。值得注意的是,為了與之前的數據處理保持一致,所有圖像都排除了B10波段。此外,我們遵循[39]中建議的訓練/驗證分割。在EuroSAT數據集上,這些預訓練的模型經過微調,跨越150個epoch,批量大小為512。這一微調過程采用了基本學習率為2 × 1 0 ? 4 10^{-4} 10?4的AdamW優化器,并結合了與先前工作[24]一致的數據增強,包括權重衰減(0.05)、drop path(0.1)、repb(0.25)、mixup(0.8)和cutmix(1.0)。利用預訓練模型的基礎編碼器,將其輸出通過平均池化層進行預測。訓練目標是最小化交叉熵損失。圖4給出了下游單標簽場景分類任務的網絡架構。
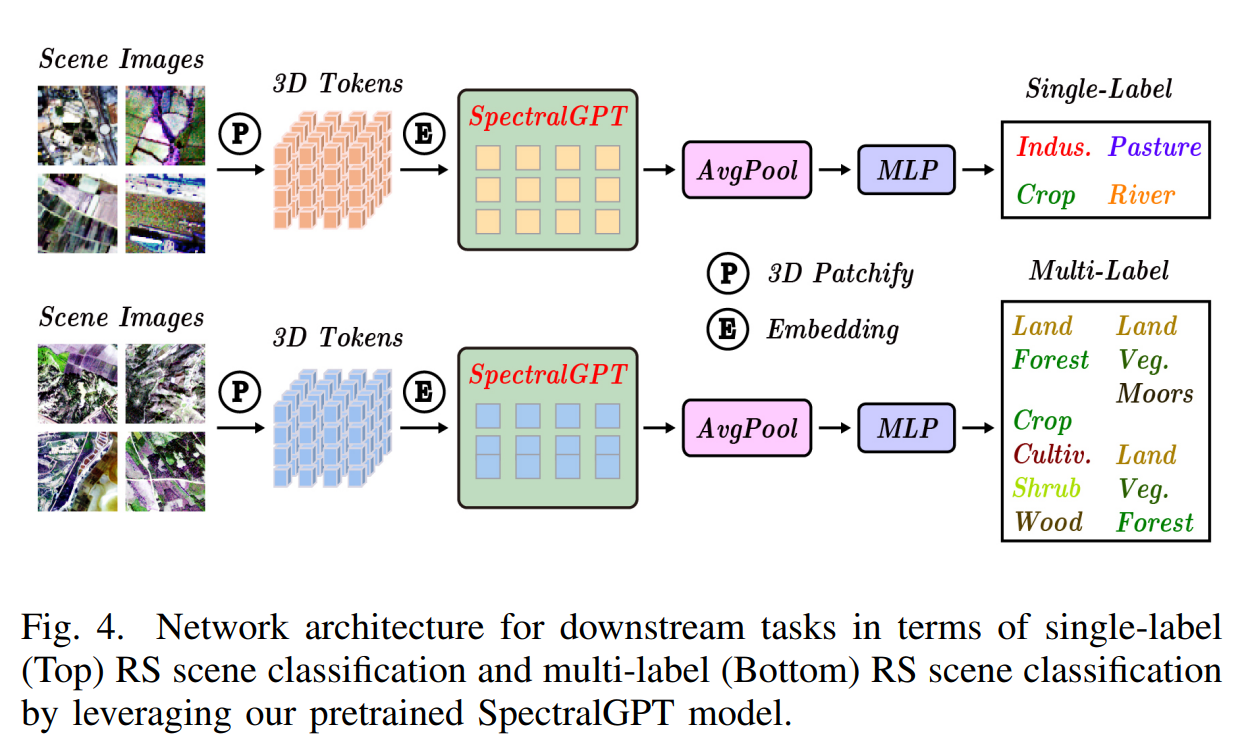
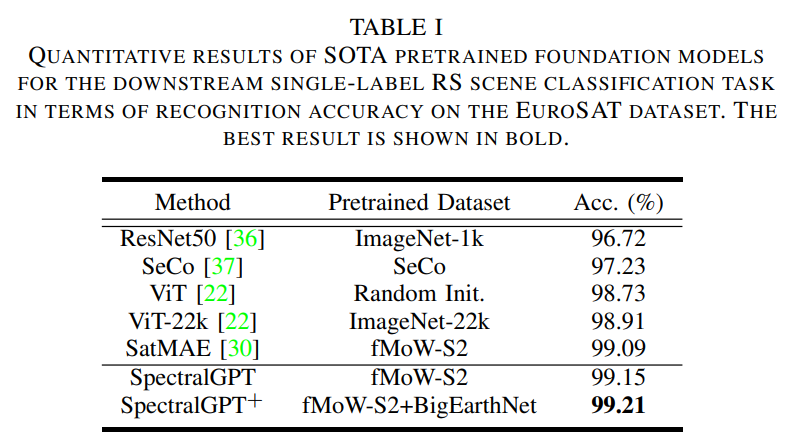
? 預訓練模型的編碼器作為基礎骨干,其輸出服從于平均池化層以生成預測。訓練目標包括最小化交叉熵損失。在表1中,我們對我們提出的方法與其他預訓練模型進行了比較分析,報告了驗證集上最高的Top 1 精度。獲得的結果突出了所提出方法的有效性,實現了令人印象深刻的精度99.15%。此外,當模型在fMoW-S2和BigEarthNet數據集上進行預訓練時,可以觀察到顯著的性能提升,最終達到99.21%的顯著準確率。這強調了利用不同數據源來改進模型性能的優勢。
B. BigEarthNet上的多標簽遙感場景分類
? 對于多標簽RS場景分類任務,我們使用bigearth - s2數據集[34]。這個廣泛的數據集由125個Sentinel-2 tiles組成,包括590,326張12波段圖像,跨越19個類別,用于多標簽分類。這些圖像的分辨率從10米到60米不等,12%的低質量圖像被排除在外。訓練和驗證集與先前的研究[39]一致,有354,196個訓練樣本和118,065個驗證樣本。為了準備模型訓練,使用雙線性插值將不同分辨率的圖像標準化為128 × 128像素的統一尺寸。
? 在bigearth - s2數據集上,這些基礎模型使用10%的訓練數據子集進行微調,遵循與EuroSAT微調實驗中應用的設置相似的設置,除了學習率提高了2× 1 0 ? 4 10^{-4} 10?4,這與先前的研究結果一致[30],[37]。大多數現有方法,包括那些使用預訓練基礎模型的方法,通常使用bigearth - s2數據集中的所有可用圖像進行訓練。相比之下,我們提出的SpectralGPT即使只利用10%的訓練樣本,也能實現更高的分類性能。考慮到這個的多標簽分類性質任務中,我們的訓練目標涉及多標簽軟邊際損失,性能評估基于mAP度量。值得注意的是,我們使用macro和micro mAP測量來計算mAP。這種方法特別適用于bigearth - s2數據集,它顯示了類的不平衡。多標簽分類框架如圖4所示。
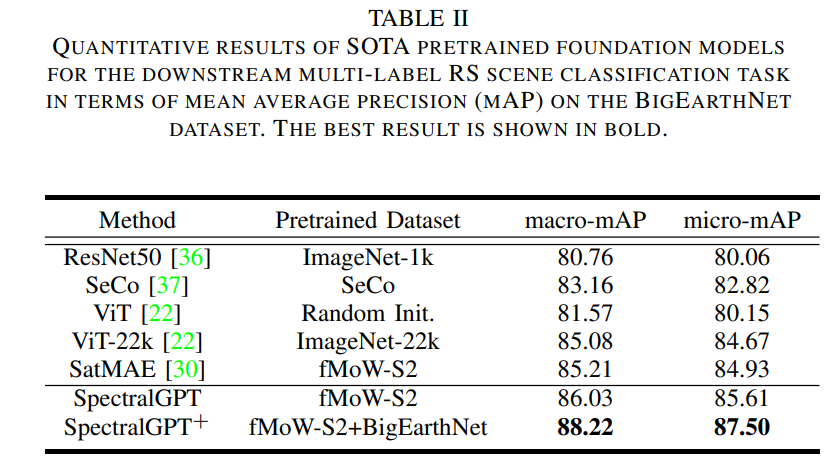
? 表2給出了我們的預訓練模型與其他提出的預訓練模型和從零開始訓練的模型的比較分析,展示了提出的方法的卓越性能。特別是,與在ImageNet-22k和SatMAE相比,我們的SpectralGPT模型的性能macro-mAP(micro-mAP)比它們高出0.84% (0.82%)和0.71%(0.68%)。值得注意的是,引入了額外的預訓練數據(BigEarthNet),即SpectralGPT+,導致了顯著的性能提升,模型取得了令人印象深刻的成績macro-mAP(micro-mAP) 為88.22%(87.50%) ,比僅在fMoW-S2上訓練的模型高出2.19%(1.86%)。這種實質性的改善可歸因于兩個關鍵因素。首先,模型在BigEarthNet上的初始預訓練(即使沒有標簽)使其對數據集的分布有了很強的掌握,加速了微調過程中的收斂,增強了mAP。其次,采用MIM方法作為預訓練 pretext 任務,再加上龐大的數據規模,需要與訓練策略保持一致,強調隨機掩膜框架和90%掩膜比的重要性,以促進更魯棒的表示學習。此外,由于我們的評估集中在一個多標簽分類任務上,并且只使用了10%的訓練數據,結果強調了我們提出的模型在處理具有挑戰性的下游任務時的優越泛化和少量學習能力。
C.基于SegMunich的RS語義分割
? 對于語義分割任務,我們創建了一個新的SegMunich數據集,該數據集來自Sentinel-2光譜衛星[41]。該數據集由10波段最佳像素合成,尺寸為3,847 × 2,958像素,空間分辨率為10米。它在2020年4月之前的三年內捕捉了慕尼黑的城市景觀,并包括一個分割掩模,精心描繪了13個土地利用和土地覆蓋(LULC)類別。這個掩碼的數據來自不同的地方,包括OpenStreetMap的街道網絡數據和OSMLULC 平臺數據為其余12個類別,均以相同的10米空間分辨率獲得。為了創建語義分割的綜合特征表示,數據集將10米光譜帶(B1、B2、B3和B4)與重采樣的20米光譜帶(B5、B6、B7、B8A、B11、B12)結合起來,并將其上采樣以匹配10米分辨率。這種譜帶的融合確保了數據集為語義分割任務提供了豐富和信息豐富的數據。
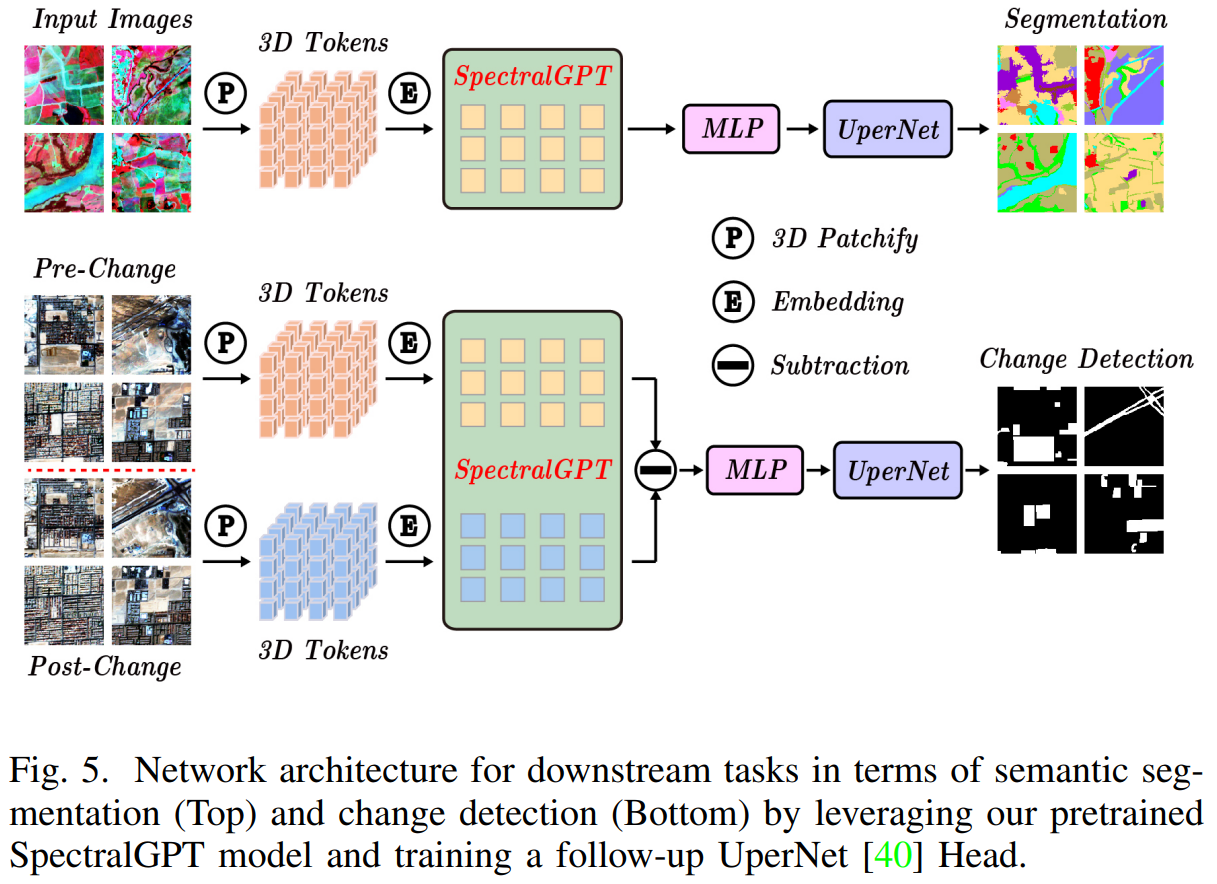
? 在SegMunich數據集上,我們將UperNet框架[40]與預訓練的基礎模型結合使用,最初將編碼器最后一層的每個像素的四個token合并為一個token。圖像數據被分成128 x 128像素的標記,重疊50%。然后將數據集分成8:2的訓練驗證比,并進行數據增強技術,包括隨機翻轉和旋轉。在對該數據集進行微調期間,我們使用96個批處理大小,并將基本學習率設置為5 x 1 0 ? 4 10^{-4} 10?4。優化函數和損失函數與EuroSAT實驗中使用的函數保持一致,確保對模型訓練和評價采取連貫統一的方法。分割架構如圖5所示。
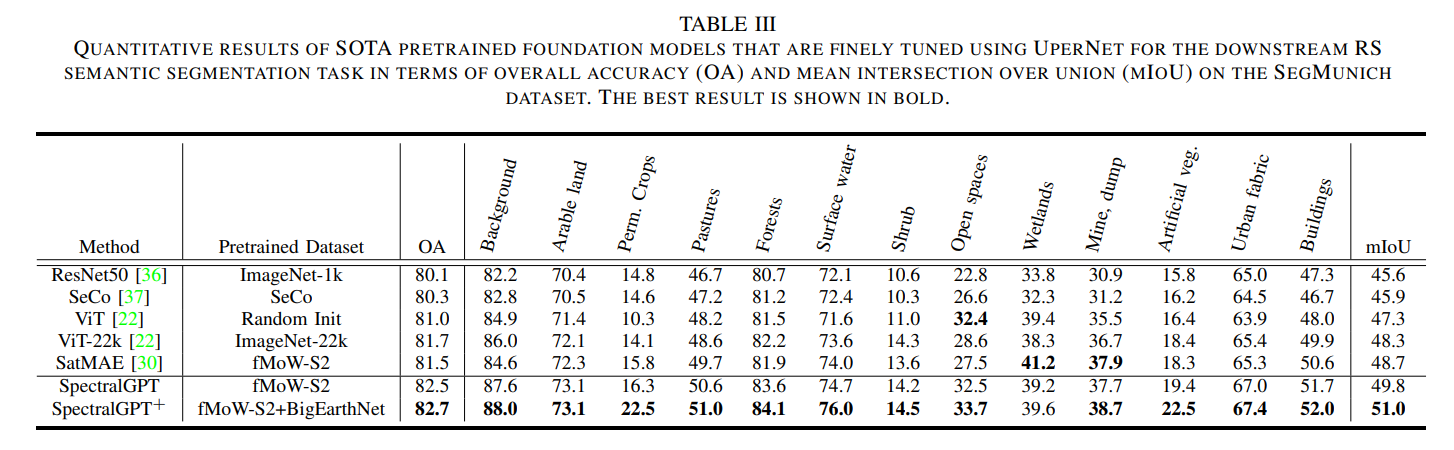
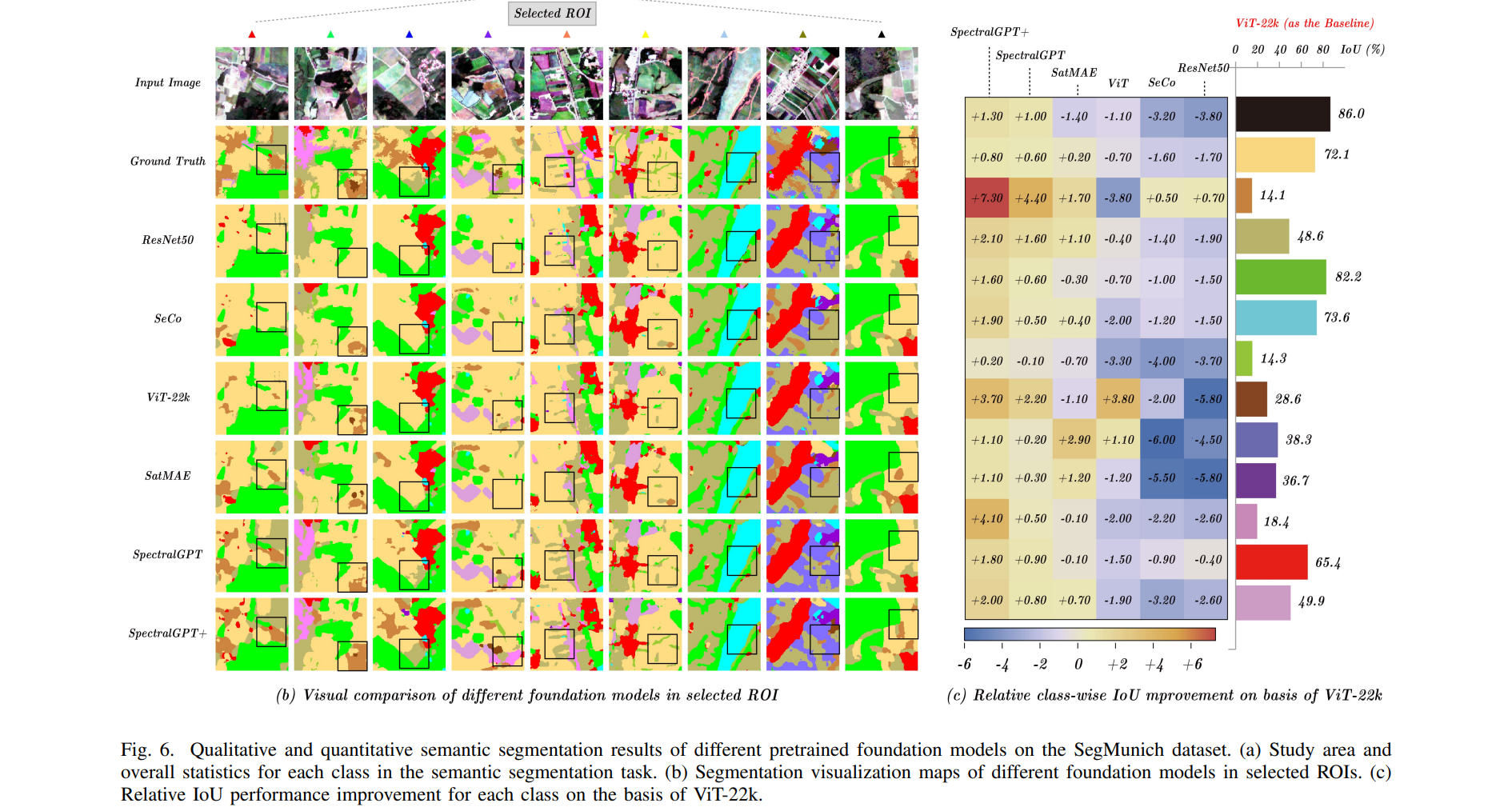
? 表III列出了語義分割任務的OA和mloU的定量結果。我們的SpectralGPT (SpectralGPT+)表現優于其他所有產品,mIoU比第二名(即SatMAE)高出1.1% (2.3%)。圖6(a)提供了分割任務所研究的慕尼黑地區的視覺描述,以及13個類別的比例。如**圖6(b)所示,幾個roi的定性比較表明,在大多數情況下,與競爭模型相比,我們的模型在識別更廣泛的土地利用類別方面具有優越的能力。此外,當考慮將ViT-22k 作為性能比較的基線時,我們的模型在所有分割類別中始終表現出色,如圖6?**所示,特別是對于作物、牧場、開放空間、植被等類別。通過將類別統計數據與分類IoU結果相結合,我們的SpectralGPT模型在減輕類別不平衡分類帶來的挑戰方面表現出色。與其他基礎模型相比,這將大大提高性能。

D.對OSCD的RS變化檢測
? 對于變化檢測任務,我們使用OSCD數據集[42]。圖7(a)顯示了幾個城市規模的例子。該數據集包括24個城市的Sentinel-2圖像,其中14張用于訓練,10張用于評估。這些圖像拍攝于2015年至2018年之間,包含13個光譜波段,分辨率分別為10米、20米和60米。該數據集在像素級進行了注釋,以表明變化,特別是關注城市發展。在OSCD數據集上,我們執行圖像裁剪以創建大小為128 × 128像素的斑塊,重疊率為50%,并且我們應用隨機翻轉和旋轉作為數據增強技術。對于每一對圖像,兩者都通過共享編碼器同時處理,并計算其特征之間的差異,然后傳遞給UperNet。每個特征像素由4個標記組成,類似于分割方法,我們使用線性層將這4個標記合并為1個標記。該模型以負對數似然損失為訓練目標,以批大小為64個,學習率設置為1× 1 0 ? 3 10^{-3} 10?3,訓練60個epoch。在變更檢測任務中利用預訓練的SpectralGPT模型的整個框架如圖5所示。
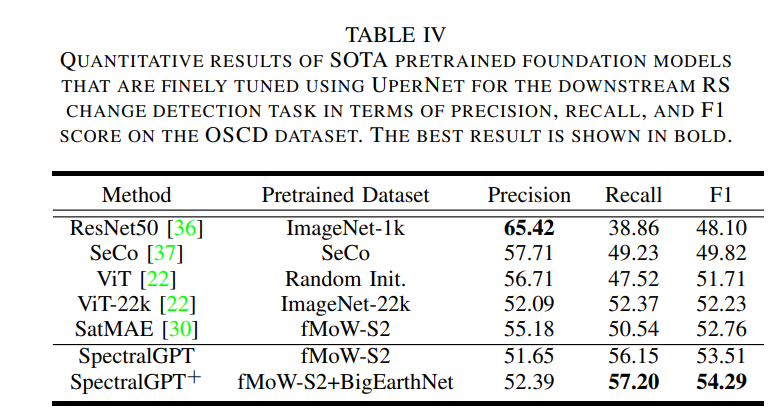
? 模型性能通過精度、召回率和F1分數來評估,其定量結果如表4所示,在OSCD數據集上,我們提出的模型獲得了最高的F1分數,超過了第二好的模型(即SatMAE) 0.75%(1.53%)。然而,值得注意的是,我們的模型在F1得分和召回率方面表現出色,但與其他模型相比,精度相對較低。這種現象可以歸因于兩個主要因素。首先,變化檢測任務內固有數據的極度不平衡(見圖7(b)),其中陽性和陰性樣本的數量差異顯著,可能導致模型將陰性案例分類為陽性,以犧牲精度為代價提高召回率。其次,ViT架構的復雜性需要大量的數據來緩解過擬合。模型可能會與過擬合作斗爭,并且對域外數據的適應性變差。解決這一挑戰可能需要提供額外的微調數據或者降低模型的等級。在定性結果方面,我們的模型在**圖7(d)**的選定roi中預測變化像素方面表現出色,假陰性較少。值得注意的是,**圖7?**強調了SpectralGPT的卓越性能,其中我們的模型在一半的測試城市中取得了最好的結果。此外,被比較的模型在10個不同的的城市表現趨勢一致,Lasvegas 和 Montpellier分別在F1中獲得了最高和第二高的分數



)
)














BUUCTF-RSA3(共模攻擊))

