文章目錄
- 前言:Android 在設備上改進內存的秘密
- 優化編譯器101
- 代碼大小改進
- 消除寫入障礙
- 隱式暫停檢查
- 合并回調
- 其他優化改進
- 代碼下沉
- 循環優化
- 消除死代碼 – SimplifyAlwaysThrows
- 加載存儲消除 – 使用 try catch 塊
- 加載存儲消除 – 使用釋放/獲取操作
- 新的內聯啟發式
- 不斷折疊
- 把它們放在一起
- 進一步閱讀
前言:Android 在設備上改進內存的秘密

Android 運行時 (ART) 執行由 Java 或 Kotlin 語言編寫的應用程序和系統服務生成的Dalvik字節碼。我們不斷改進 ART 以生成更小、性能更高的代碼。改進 ART 可以使系統和用戶體驗整體上更好,因為它是 Android 應用程序的共同點。在這篇博文中,我們將討論在不影響性能的情況下減少代碼大小的優化。
代碼大小是我們關注的關鍵指標之一,因為生成的文件越小,對內存(RAM 和存儲)越有利。通過新版本的 ART,我們估計每臺設備可為用戶節省約 50-100MB 的空間。這可能正是您更新您喜愛的應用程序或下載新應用程序所需要的。由于 ART 可從 Android 12 開始更新,這些優化適用于1B+ 設備,谷歌在全球范圍內為這些設備節省了47-95 PB(47-95 百萬 GB!)!
本博文中提到的所有改進都是開源的。它們可以通過 ART 主線更新獲得,因此您甚至不需要完整的操作系統更新即可獲得好處。我們可以把蛋糕倒過來吃!
優化編譯器101
ART使用設備上的 dex2oat 工具將應用程序從DEX 格式編譯為本機代碼。第一步是解析 DEX 代碼并生成中間表示(IR)。使用 IR,dex2oat 執行許多代碼優化。管道的最后一步是代碼生成階段,其中 dex2oat 將 IR 轉換為本機代碼(例如,AArch64 匯編)。
優化管道具有執行的階段,以便每個階段專注于一組特定的優化。例如,常量折疊是一種優化,嘗試用常量值替換指令,例如將加法運算2 + 3折疊為5。
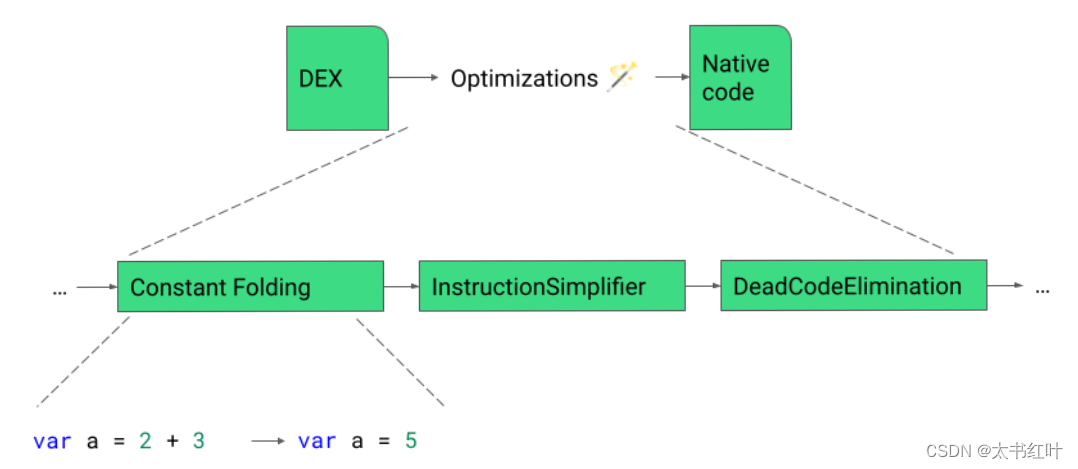
IR 可以打印和可視化,但與 Kotlin 語言代碼相比非常冗長。出于本博文的目的,我們將展示使用 Kotlin 語言代碼進行的優化,但要知道它們正在發生在 IR 代碼上。
代碼大小改進
對于所有代碼大小優化,我們對 Google Play 商店中超過 50 萬個 APK 進行了測試,并匯總了結果。
消除寫入障礙
我們有一個新的優化過程,稱為“寫入障礙消除”。寫屏障會跟蹤自垃圾收集器 (GC) 上次檢查以來已修改的對象,以便 GC 可以重新訪問它們。例如,如果我們有:

以前,我們會為每個對象修改發出一個寫屏障,但我們只需要一個寫屏障,因為:1)標記將在o本身中設置(而不是在內部對象中),2)垃圾收集不能與這些集合之間的線程進行了交互。
如果指令可能觸發 GC(例如 Invokes 和 SuspendChecks),我們將無法消除寫入障礙。在下面的示例中,我們不能保證 GC 不需要檢查或修改修改之間的跟蹤信息:

實施這一新通道有助于減少 0.8% 的代碼大小。
隱式暫停檢查
假設我們有幾個線程正在運行。掛起檢查是安全點(由下圖中的房屋表示),我們可以在其中暫停線程執行。使用安全點的原因有很多,其中最重要的是垃圾收集。當發出安全點調用時,線程必須進入安全點并被阻塞,直到它們被釋放。
以前的實現是顯式布爾檢查。我們將加載該值,對其進行測試,并在需要時分支到安全點。
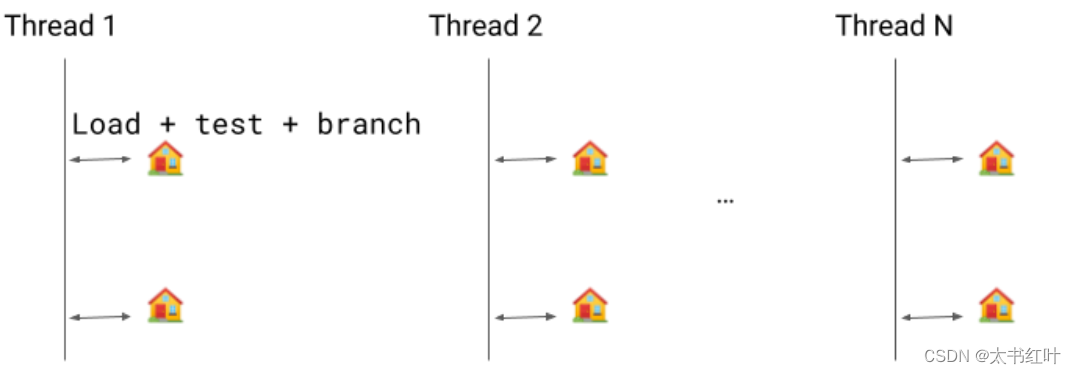
隱式掛起檢查是一種優化,消除了對測試和分支指令的需要。相反,我們只有一個負載:如果線程需要掛起,該負載將捕獲,并且信號處理程序會將代碼重定向到掛起檢查處理程序,就像該方法進行了調用一樣。
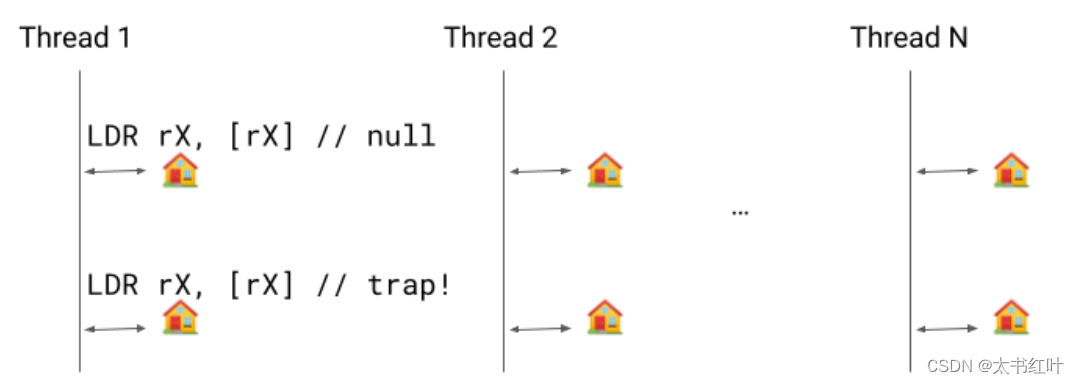
更詳細地說,保留寄存器 rX 預加載了線程內的一個地址,其中我們有一個指向其自身的指針。只要我們不需要進行掛起檢查,我們就保留該自指向指針。當我們需要進行掛起檢查時,我們清除指針,一旦它對線程可見,第一個LDR rX, [rX]將加載 null,第二個將出現段錯誤。
掛起請求本質上是要求線程很快掛起一段時間,因此等待第二次加載的輕微延遲是可以接受的。
此優化將代碼大小減少了 1.8%。
合并回調
已編譯方法通常具有入口框架。如果它們擁有它,這些方法必須在返回時解構它,這也稱為退出框架。如果一個方法有多個返回指令,它將生成多個退出幀,每個返回指令一個。
通過將返回指令合并為一條,我們能夠擁有一個返回點并能夠刪除多余的退出幀。這對于具有多個 return 語句的 switch 情況特別有用。

合并返回可將代碼大小減少 1%。
其他優化改進
我們改進了許多現有的優化過程。在這篇博文中,我們將它們分組在同一部分,但它們彼此獨立。以下部分中的所有優化都有助于減少 5.7% 的代碼大小。
代碼下沉
代碼下沉是一種優化過程,它將指令下推到不常見的分支,例如以 throw 結尾的路徑。這樣做是為了減少可能不會使用的指令上浪費的周期。
我們通過 try catch 改進了圖中的代碼下沉:現在,只要我們不將代碼下沉到與它開始的嘗試不同的嘗試中(或者如果它不在開始的嘗試中,則在任何嘗試中),我們現在允許下沉代碼和)。

在第一個示例中,我們可以接收對象創建,因為它只會在if(flag)路徑中使用,而不會在其他路徑中使用,并且它位于同一個嘗試中。通過此更改,在運行時只有當flag為 true時才會運行。在不涉及太多技術細節的情況下,我們可以關注的是實際的對象創建,但加載Object類仍然保留在if之前。這很難用 Kotlin 代碼來展示,因為同一條 Kotlin 行在 ART 編譯器級別會變成多條指令。
在第二個示例中,我們不能下沉代碼,因為我們將在另一個嘗試中移動實例創建(可能會拋出異常)。
Code Sinking主要是一種運行時性能優化,但它可以幫助減輕寄存器壓力。通過將指令移近其用途,在某些情況下我們可以使用更少的寄存器。使用更少的寄存器意味著更少的移動指令,這最終有助于減少代碼大小。
循環優化
循環優化有助于在編譯時消除循環。在下面的示例中, foo中的循環將a乘以10,10次。這與乘以100相同。我們啟用循環優化以在帶有 try catch 的圖中工作。

在foo中,我們可以優化循環,因為 try catch 是不相關的。
然而,在bar或baz中,我們不對其進行優化。如果循環中有一個 try,或者整個循環是否在 try 內部,那么了解循環將采用的路徑并不是一件容易的事。
消除死代碼 – 刪除不需要的 try 塊
我們通過實施優化來刪除不包含拋出指令的 try 塊,從而改進了死代碼消除階段。我們還可以刪除一些 catch 塊,只要沒有活動的 try 塊指向它。
在下面的示例中,我們將bar內聯到foo中。之后,我們知道該師不能投擲。稍后的優化過程可以利用這一點并改進代碼。
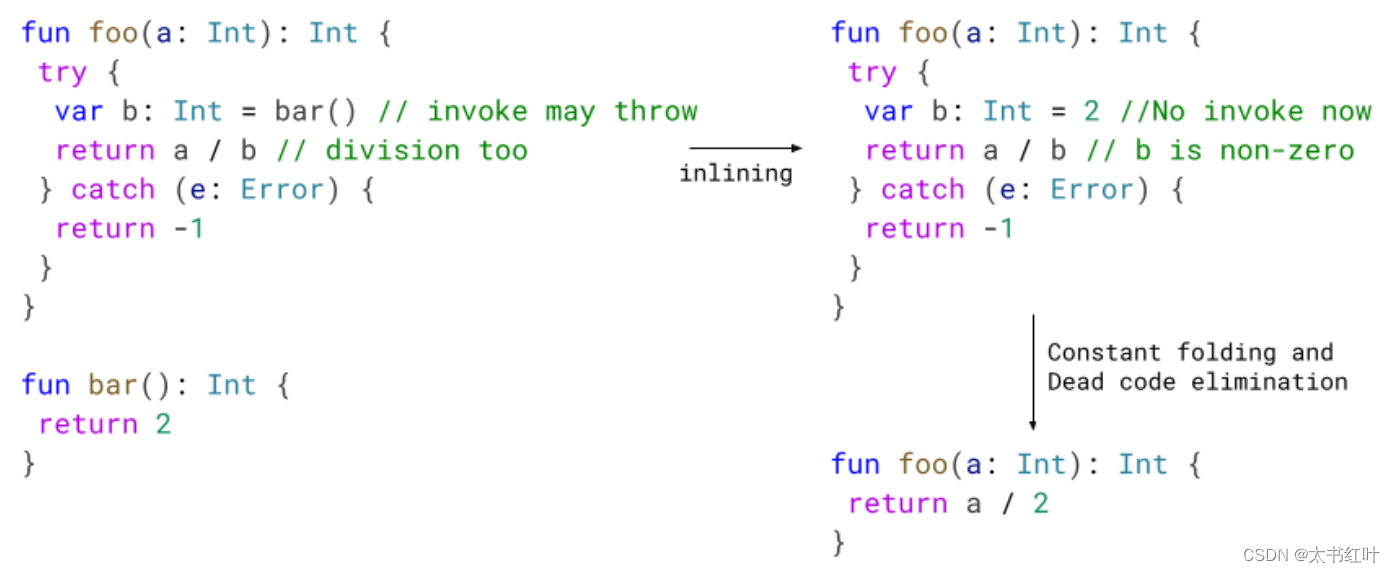
只需從 try catch 中刪除死代碼就足夠了,但更好的是,在某些情況下我們允許進行其他優化。如果您還記得的話,當循環有一個 try 或它位于一個 try 內部時,我們不會進行循環優化。通過消除這種冗余的 try/catch,我們可以循環優化,生成更小、更快的代碼。

消除死代碼 – SimplifyAlwaysThrows
在死代碼消除階段,我們有一個稱為SimplifyAlwaysThrows 的優化。如果我們檢測到調用總是會拋出異常,我們可以安全地丟棄該方法調用之后的任何代碼,因為它永遠不會被執行。
我們還更新了SimplifyAlwaysThrows,以便在帶有 try catch 的圖中工作,只要調用本身不在 try 內部。如果它在 try 內部,我們可能會跳轉到 catch 塊,并且很難找出將要執行的確切路徑。

我們還改進了:
- 通過查看參數來檢測調用何時拋出。在左邊,我們將把divide(1, 0)標記為總是拋出,即使泛型方法并不總是拋出。
- SimplifyAlwaysThrows適用于所有調用。以前我們有限制,例如不要對導致if的調用執行此操作,但我們可以刪除所有限制。

加載存儲消除 – 使用 try catch 塊
負載存儲消除(LSE) 是一種刪除冗余負載和存儲的優化過程。
我們改進了這個過程以處理圖中的 try catch。在foo中,我們可以看到,如果存儲/加載不直接與 try 交互,我們可以正常執行 LSE。在bar中,我們可以看到一個示例,我們要么走正常路徑而不拋出異常,在這種情況下我們返回1;或者我們拋出,抓住它并返回2。由于每條路徑的值都是已知的,因此我們可以刪除冗余負載。

加載存儲消除 – 使用釋放/獲取操作
我們改進了加載存儲消除過程,以在具有釋放/獲取操作的圖表中工作。這些是易失性加載、存儲和監視操作。澄清一下,這意味著我們允許 LSE 在具有這些操作的圖中工作,但我們不會刪除所述操作。
在示例中,i和j是常規整型,vi是易失性整型。在foo中,我們可以跳過加載值,因為集合和加載之間沒有釋放/獲取操作。在bar中,易失性操作發生在它們之間,因此我們無法消除正常負載。請注意,不使用易失性加載結果并不重要——我們無法消除獲取操作。

此優化與易失性存儲和監視器操作(Kotlin 中的同步塊)類似。
新的內聯啟發式
我們的內聯傳遞具有廣泛的啟發式。有時我們決定不內聯一個方法,因為它太大,或者有時我們決定強制內聯一個方法,因為它太小(例如,像對象初始化這樣的空方法)。
我們實現了一個新的內聯啟發式:不要內聯調用導致拋出。如果我們知道要拋出異常,我們將跳過內聯這些方法,因為拋出本身的成本足夠高,以至于內聯該代碼路徑是不值得的。
我們將跳到內聯的三個方法系列:
- 在拋出之前計算并打印調試信息。
- 內聯錯誤構造函數本身。
- 最后塊在我們的優化編譯器中被重復。我們有一個用于正常情況(即嘗試不拋出),還有一個用于異常情況。我們這樣做是因為在特殊情況下我們必須:捕獲、執行finally
塊并重新拋出。特殊情況下的方法現在不會內聯,但正常情況下的方法會內聯。

不斷折疊
常量折疊是一種優化過程,如果可能的話,將操作更改為常量。我們實現了一種優化,可以傳播在if防護中使用時已知為常量的變量。圖中有更多常量可以讓我們稍后執行更多優化。
在foo中,我們知道a在if保護中的值為2。我們可以傳播該信息并推斷b必須是4。同樣,在bar中,我們知道cond在if情況下必須為 true ,在else情況下必須為 false (簡化圖表)。

把它們放在一起
如果我們考慮到本博文中的所有代碼大小優化,我們的代碼大小將減少 9.3%!
從長遠來看,一部普通手機可以有 500MB-1GB 的優化代碼(實際數字可以更高或更低,具體取決于您安裝了多少應用程序,以及您安裝了哪些特定應用程序),因此這些優化可以節省大約 50每臺設備 -100MB。由于這些優化適用于 1B+ 設備,我們在全球范圍內節省了 47-95 PB!
進一步閱讀
如果您對代碼更改本身感興趣,請隨時查看。本博文中提到的所有改進都是開源的。如果您想幫助全世界的 Android 用戶,請考慮為 Android 開源項目做出貢獻!
————————————:Santiago Aboy Solanes - 軟件工程師










)








|LeetCode1049. 最后一塊石頭的重量 II、LeetCode494. 目標和)