目錄
- 一、數據準備
- 二、創建自定義視覺資源
- 三、創建新項目
- 四、選擇訓練圖像
- 五、上傳和標記圖像
- 六、訓練分類器
- 七、評估分類器
- 概率閾值
- 八、管理訓練迭代
在本文中,你將了解如何使用Azure可視化頁面創建圖像分類模型。 生成模型后,可以使用新圖像測試該模型,并最終將該模型集成到你自己的圖像識別應用中。
關注TechLead,分享AI全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人。
一、數據準備
- 一組用于訓練分類模型的圖像。 可以使用 GitHub 上的一組示例圖像。 或者,可以根據下面的提示選擇你自己的圖像。
二、創建自定義視覺資源
若要使用自定義視覺服務,需要在 Azure 中創建“自定義視覺訓練和預測”資源。 為此,在 Azure 門戶中填寫創建自定義視覺頁上的對話框窗口,以創建“訓練和預測”資源。
三、創建新項目
在 Web 瀏覽器中,導航到自定義影像服務網頁,然后選擇“登錄” 。 使用登錄 Azure 門戶時所用的帳戶進行登錄。
- 若要創建首個項目,請選擇“新建項目” 。 將出現“創建新項目”對話框 。

- 輸入項目名稱和描述。 然后選擇自定義視覺訓練資源。 如果登錄帳戶與 Azure 帳戶相關聯,則“資源”下拉列表將顯示所有兼容的 Azure 資源。
注意
如果沒有可用的資源,請確認已使用登錄 Azure 門戶時所用的同一帳戶登錄 customvision.ai。 此外,請確認在自定義視覺網站中選擇的“目錄”與自定義視覺資源所在 Azure 門戶中的目錄相同。 在這兩個站點中,可從屏幕右上角的下拉帳戶菜單中選擇目錄。
-
選擇“項目類型”下的“分類”。 然后,在“分類類型”下,根據用例選擇“多標簽”或“多類”。 多標簽分類將任意數量的標記應用于圖像(零個或多個),而多類分類將圖像分類為單個類別(提交的每個圖像將被分類為最有可能的標記)。 以后可以更改分類類型(如果需要)。
-
接下來,選擇一個可用域。 每個域都會針對特定類型的圖像優化模型,如下表所述。 稍后可按需更改域。
域 目的 常規 針對各種圖像分類任務進行優化。 如果其他域都不合適,或者不確定要選擇哪個域,請選擇“通用”域。 食物 針對餐廳菜肴的照片進行優化。 如果要對各種水果或蔬菜的照片進行分類,請使用“食品”域。 特征點 針對可識別的自然和人造地標進行優化。 在照片中的地標清晰可見的情況下,該域效果最佳。 即使照片中的人物稍微遮擋了地標,該域仍然有效。 零售 針對購物目錄或購物網站中的圖像進行優化。 若想對連衣裙、褲子和襯衫進行精準分類,請使用此域。 壓縮域 針對移動設備上實時分類的約束進行優化。 可導出壓縮域生成的模型在本地運行。 -
最后,選擇“創建項目”。
四、選擇訓練圖像
作為最低要求,我們建議在初始訓練集中每個標記使用至少 30 張圖像。 此外還需要收集一些額外的圖像,以便在訓練模型后測試模型。
為了有效地訓練模型,請使用具有視覺多樣性的圖像。 選擇在以下方面有所不同的圖像:
- 照相機角度
- 照明
- background
- 視覺樣式
- 個人/分組主題
- 大小
- type
此外,請確保所有訓練圖像滿足以下條件:
- .jpg、.png、.bmp 或 .gif 格式
- 大小不超過 6 MB (預測圖像不超過 4 MB)
- 最短的邊不小于 256 像素;任何小于此像素的圖像將通過自定義影像服務自動縱向擴展
五、上傳和標記圖像
在本部分中,將上傳圖像并手動標記圖像以幫助訓練分類器。
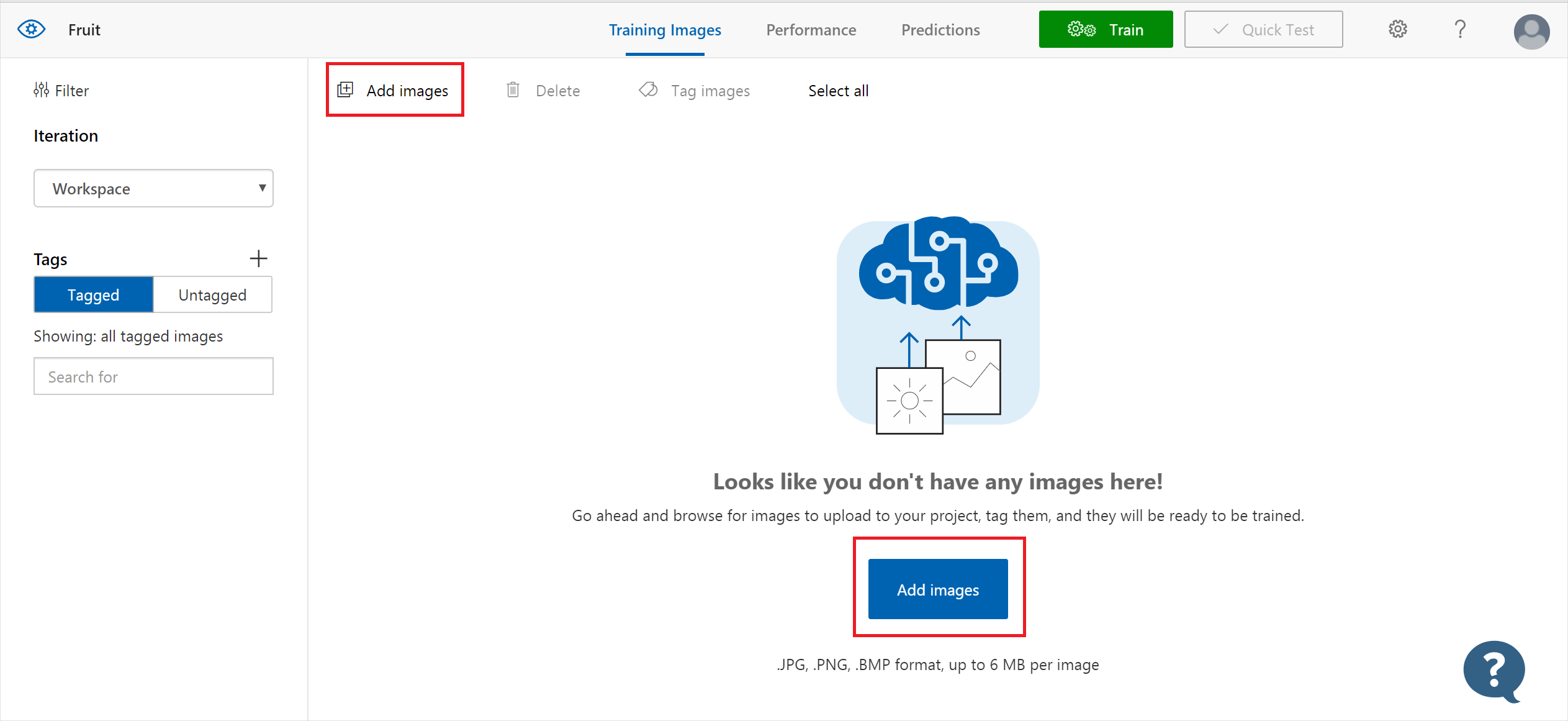
- 若要添加圖像,請選擇“添加圖像”,然后選擇“瀏覽本地文件” 。 選擇“打開”以移至標記。 標記選擇將應用于已選擇要上傳的整組圖像,因此根據其應用的標記將圖像分成單獨的組更容易上傳。 還可在上傳圖像后更改單個圖像的標記。
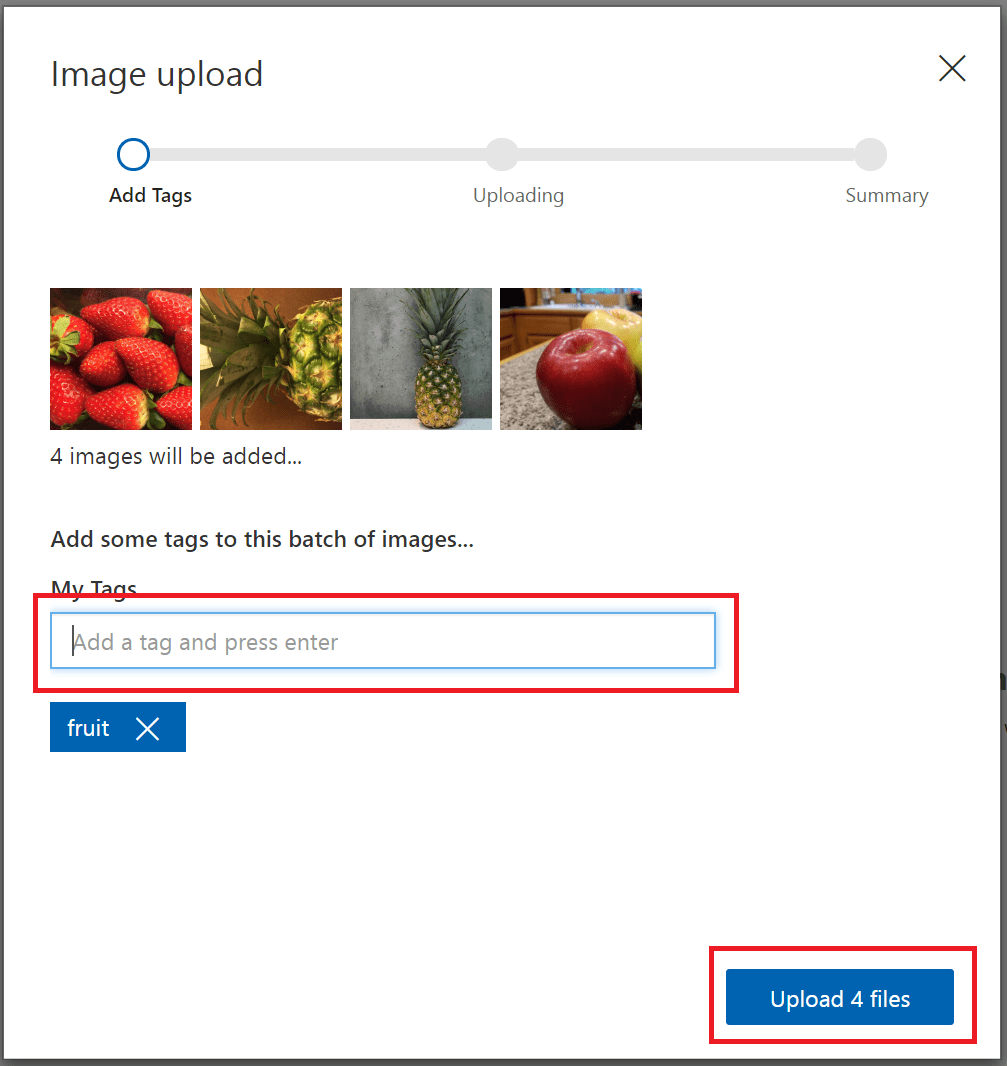
- 若要創建標記,請在“我的標記”字段中輸入文本,然后按 Enter 鍵。 如果標記已存在,它會在下拉列表菜單中顯示。 在多標簽項目中,可以將多個標記添加到圖像,但多類項目中只能添加一個標記。 若要完成上傳圖像,請使用“上傳 [編號] 文件”按鈕。
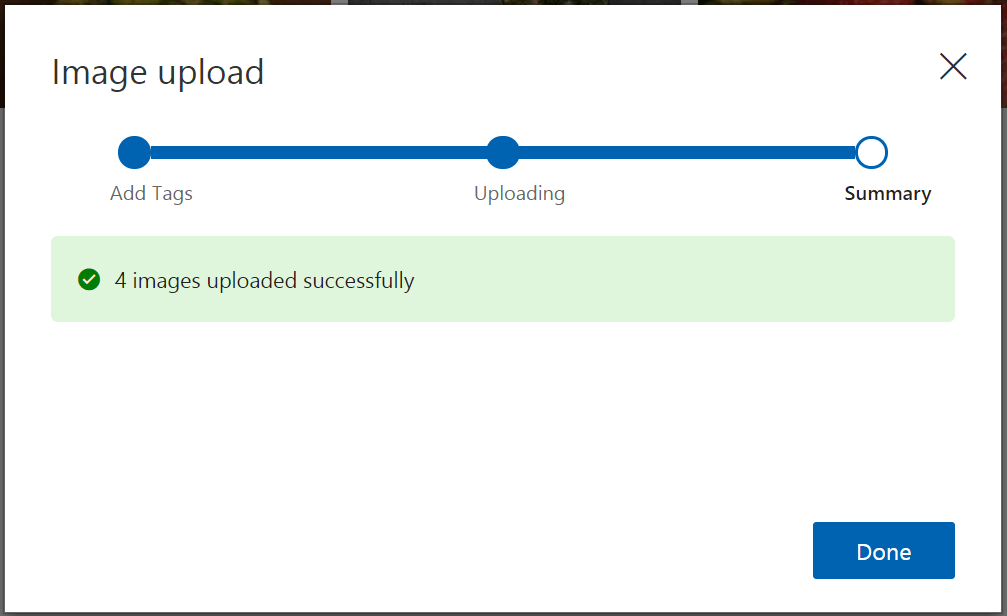
- 上傳圖像后,選擇“完成”。
若要上傳另一組圖像,請返回到本部分頂部并重復上述步驟。
六、訓練分類器
若要訓練分類器,請選擇“訓練”按鈕。 分類器使用所有當前圖像來創建模型,該模型可標識每個標記的視覺質量。 這個過程可能需要幾分鐘。

此訓練過程應該只需要幾分鐘的時間。 在此期間,會在“性能”選項卡顯示有關訓練過程的信息。
七、評估分類器
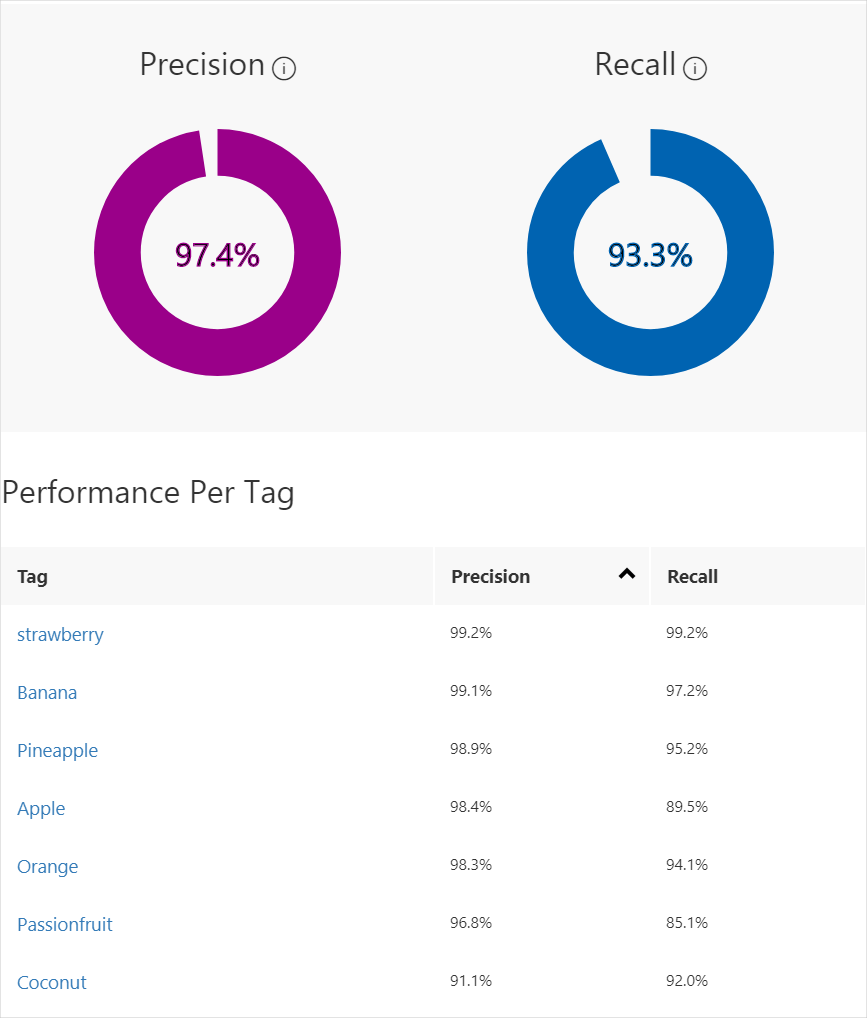
完成訓練后,評估并顯示該模型的性能。 自定義視覺服務使用提交用于訓練的圖像來計算精確度和召回率。 精確度和召回率是分類器有效性的兩個不同的度量:
- 精確度表示已識別的正確分類的分數。 例如,如果模型將 100 張圖像識別為狗,實際上其中 99 張是狗,那么精確度為 99%。
- 召回率表示正確識別的實際分類的分數。 例如,如果實際上有 100 張蘋果的圖像,并且該模型將 80 張標識為蘋果,則召回率為 80%。
概率閾值
請注意“性能”選項卡左窗格上的“概率閾值”滑塊 。這是預測被視為正確時所需具有的置信度(用于計算精度和召回率)。
當解釋具有高概率閾值的預測調用時,它們往往會以犧牲召回為代價返回高精度的結果 - 檢測到的分類是正確的,但許多分類仍然未被檢測到。 使用較低的概率閾值則恰恰相反 - 大多數實際分類會被檢測到,但該集合內有更多誤報。 考慮到這一點,應該根據項目的特定需求設置概率閾值。 稍后,在客戶端接收預測結果時,應使用與此處所用概率閾值相同的概率閾值。
八、管理訓練迭代
每次訓練分類器時,都會創建一個新的迭代,其中包含已更新的性能指標。 可以在“性能”選項卡的左窗格中查看所有迭代。還可以找到“刪除”按鈕,如果迭代已過時,可以使用該按鈕刪除迭代。 刪除迭代時,會刪除唯一與其關聯的所有圖像。
請參閱[將模型與預測 API 配合使用],以了解如何以編程方式訪問已訓練模型。
關注TechLead,分享AI全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿里云認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人。



















