1、特點
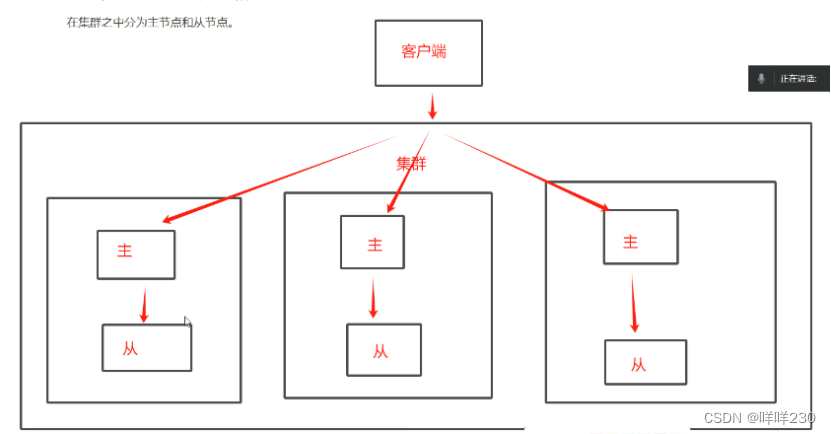
集群由多個node節點組成,redis數據分布在這些節點中,在集群中分為主節點和從節點,一個主對應一個從,所有組的主從形成一個集群,每組的數據是獨立的,并且集群自帶哨兵模式
2、工作原理
集群模式中,主從一一對應,數據寫入和讀取與主從模式一樣,主負責寫,從只能讀;集群模式自帶哨兵模式,可以自動實現故障切換,但在故障切換完成之前,整個集群不可用,切換完畢后,集群立刻恢復
3、集群模式按照數據分片
(1)數據分片:集群核心功能。每個主都可以對外提供讀、寫功能,但數據是一一對應寫入主的對應從節點,所以在集群模式中,不能保證數據的完整性
(2)高可用:集群主要目的
4、數據分片的實現過程
redis的集群引入hash槽的概念
redis集群中共有16384個哈希槽位(0-16383)
如何分配hash槽位?
根據集群中的主從節點數分配hash槽位,每個主從節點只負責一部分的hash槽位。每次讀寫都涉及hash槽位,key通過CRC16的校驗機制,對16384取余,余數值決定數據放入哪個hash槽位,通過余數值找到對應槽位找到所在節點,直接跳轉到這個節點進行存儲操作【每個節點的hash槽位值是連續的。若出現不連續的hash槽位或hash槽位沒有被全部分配,集群會報錯】
hash槽位的原理結構圖:

故障切換過程中為什么會提示集群不可用?hash槽位無人接手
主宕機后,主節點原來負責的hash槽位將會不可用,此時需要從節點代替主節點繼續負責原有的hash槽位,保證集群正常工作。故障切換過程中,會提示集群不可用;切換完成后,集群恢復,繼續工作
5、redis-cluster集群實驗
實驗目的:實現集群高可用
實驗條件:
| IP地址 | 初始服務器 | 組件 |
| 20.0.0.14 | 創建集群,自動隨機分配一一對應的主從服務器 | redis服務 |
| 20.0.0.24 | redis服務 | |
| 20.0.0.34 | redis服務 | |
| 20.0.0.44 | redis服務 | |
| 20.0.0.54 | redis服務 | |
| 20.0.0.64 | redis服務 |
實驗步驟:
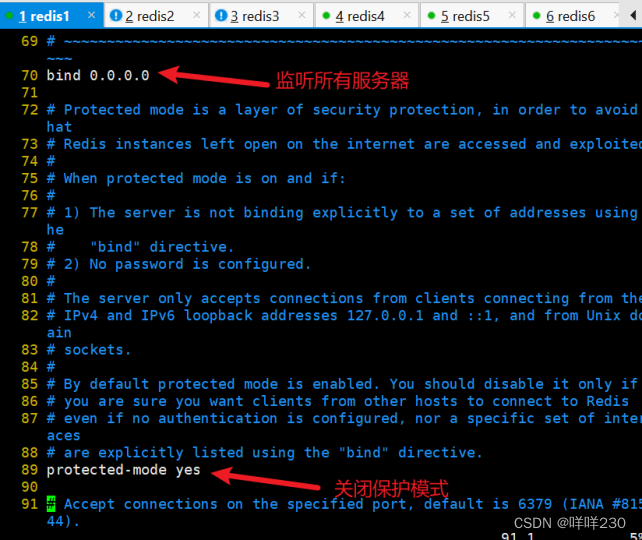
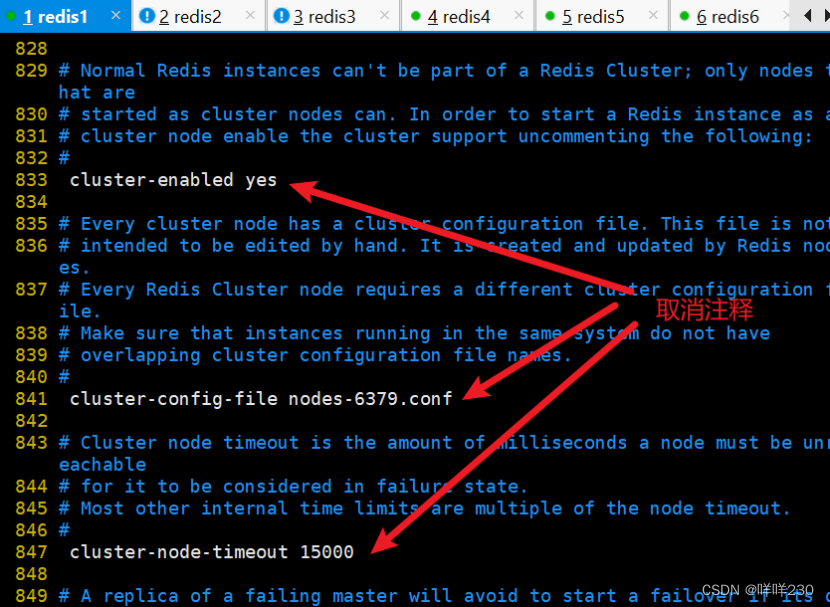
(1)修改配置文件【所有服務器】
vim /etc/redis/6379.conf



(2)、創建集群
redis-cli -h 20.0.0.14 --cluster create 20.0.0.14:6379 20.0.0.24:6379 20.0.0.34:6379 20.0.0.44:6379 20.0.0.54:6379 20.0.0.64:6379 --cluster-replicas 1

?-cluster- replicas?1?規定一個主只有一個從【主從是隨機分配的】
集群模式中,集群模式不能切換庫,只能選擇默認庫——0庫
(3)、查看hash槽位CLUSTER nodes

此時的主、從服務器
| 主 | 從 |
| 20.0.0.14——redis1 | 20.0.0.54——redis5 |
| 20.0.0.24——redis2 | 20.0.0.64——redis6 |
| 20.0.0.34——redis3 | 20.0.0.44——redis4 |
(4)測試
在任意一個主中創建鍵值對
主20.0.0.14——redis1 ???從20.0.0.54——redis5
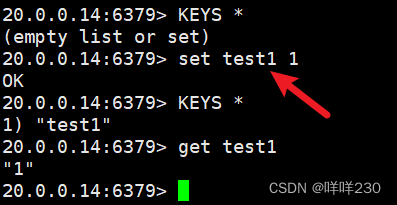

①驗證從節點能不能讀。不能


此處error不是報錯,表明客戶端嘗試讀取鍵值對test1,但是實際槽位在4768,因此集群要求客戶端移動到4768槽位所在的主機節點獲取數據
②驗證從節點能不能寫。不能

③驗證分配hash槽位后,不在相應的hash槽位上的主節點能不能寫。不能,只能到指定節點上操作
主
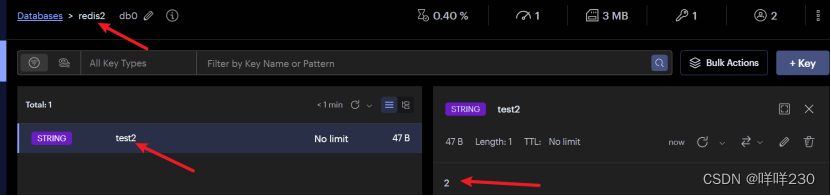
從
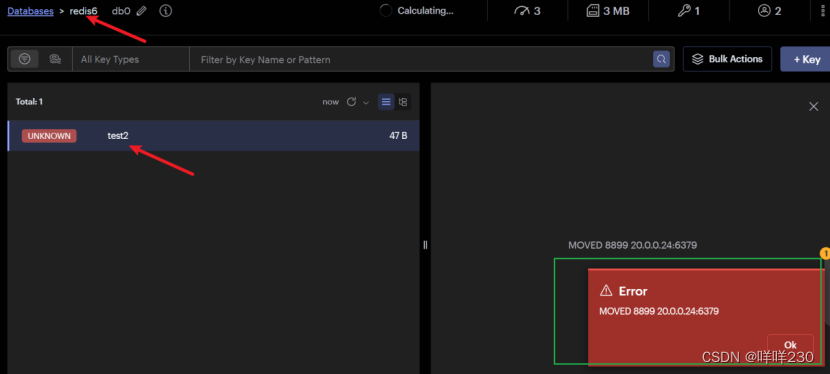
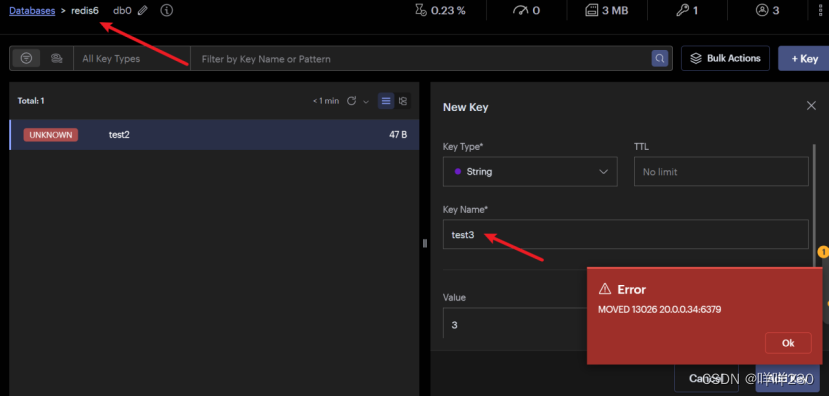
(5)模擬故障
任意一臺主服務器故障
主20.0.0.34——redis3故障,從20.0.0.44——redis4成為新主

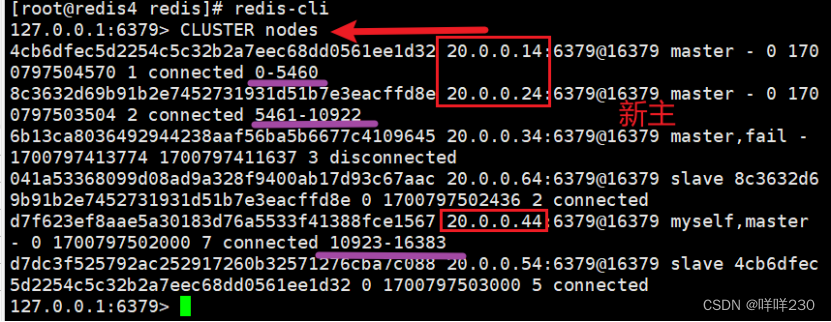
(6)恢復故障
恢復原主20.0.0.34——redis3


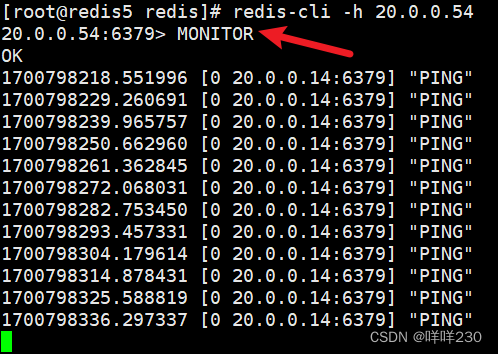
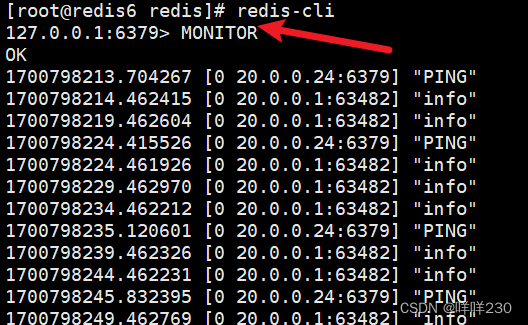
(7)、監控redis實時工作日志,檢測主從節點之間的心跳線
主

從
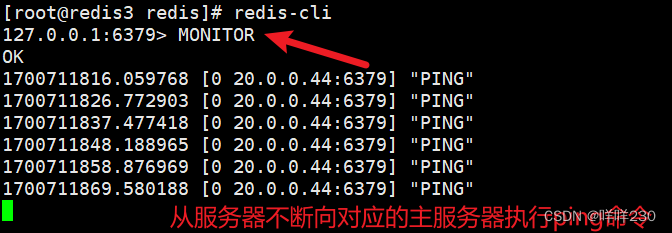


















)