成都云覽科技有限公司傾力打造了鳳凰瀏覽器,專注于為海外用戶提供服務,公司致力于構建一個全球性的數字內容連接入口,為用戶帶來更為優質、高效、個性化的瀏覽體驗。
作為數據驅動的高科技公司,從數據中挖掘價值一直是公司核心任務,公司以前選用了眾多組件來提升內部大數據分析效率,如 Trino 作為即席查詢的工具、用 ClickHouse 和 StarRocks 來加速報表業務查詢,但經過長期實踐,最終決定將所有內部數據分析平臺統一至 StarRocks。
而且,社區在 3.0.0 版本中發布了存算分離能力,與公司內部大數據平臺部門正在推動的降本增效理念非常契合,部門也在第一時間測試驗證,確定評測各方面滿足業務需求后,已經開始逐步在線上業務中替換現有系統,未來也會作為公司大數據平臺部門統一數據架構的重點發展方向。
平臺現狀
作為公司內部大數據平臺部門,主要負責公司海量數據處理、數據質量保證及指標體系維護的工作,服務公司四大業務場景:用戶畫像、報表、實驗系統以及業務服務。公司大數據平臺經過上云及幾次云平臺遷移,當前結合某云 EMR、對象存儲建設存算分離的架構,主要架構如下圖所示:
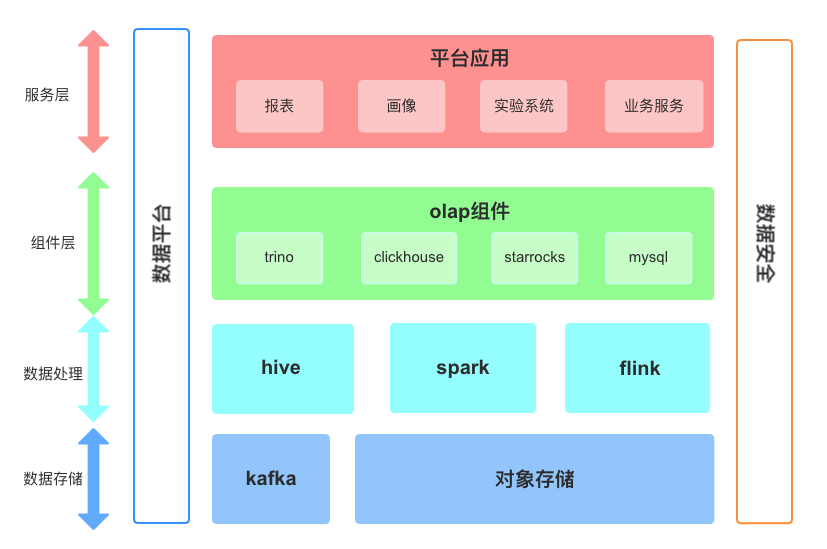
如圖所示,原始數據存儲在 Kafka 中,通過 Flink 消費,寫入到 OSS 中,然后通過 Hive 和 Spark 進行數據進一步加工,最后再將數據導入不同的 OLAP 組件中供業務查詢。后期統一了計算引擎,使用 Spark on K8s 的架構,使用 Spark SQL 和自定義了 UDF/UDAF 對數據進行統一處理。
平臺痛點
我們在發展過程中不斷采用新技術來滿足不同業務需求,日積月累,各種數據處理與分析組件越來越多,面臨著巨大的壓力與挑戰,主要表現在以下幾點:
使用組件多,維護成本高
公司的業務近幾年飛速增長,伴隨著業務擴張帶來了數據量指數式增長。我們的分析平臺規模也相應增長,使用的規模變大,平臺維護成本也成倍增長。例如,僅 OLAP 我們就使用了 Trino、ClickHouse、StarRocks。其中,Trino 給業務同學提供即席查詢用途,ClickHouse 負責應用與用戶洞察、實驗系統和報表,StarRocks 對接業務報表。維護成本高體現在:
學習成本高,不同的系統實現不同,語法兼容性不同,對開發人員提出了很高要求。
定位問題復雜,三種組件對應三套監控系統,定位排查問題需要查看不同的監控系統,搜索各自的日志,排查鏈路很長。
鏈路冗長,數據時效性難以保證
數據由客戶端上報,通過統一的轉發服務,進入到不同的 Kafka 實例中,再經由 Flink 消費,sink 到數倉的 ODS 層,最后通過 tez 和 Spark SQL 對數據進行處理,構建數倉分層。而這其中 ODS 層的數據統一處理,整體時間就需要3小時左右,偶爾中間任務數據產出有誤,需重跑整條鏈路,數據延時會被進一步拉長。
服務穩定性不足
當并發量大、大查詢多時,Trino 很容易出現內存溢出,穩定性不足,目前統計線上查詢失敗的情況約有10%左右由內存溢出導致。ClickHouse 則無法處理高并發場景,很容易因 cpu 打滿導致服務重啟。
StarRocks 存算分離調研
StarRocks 社區在 3.0.0 版本推出了存算分離版本,與我們內部追求降本增效的目標不謀而合,我們也第一時間進行了調研測評。
在調研時我們特別關注這幾個方面:
查詢效率,相比存算一體,用戶不能感覺到較為明顯的查詢變慢
顯著的成本降低,這也是我們嘗試存算分離新架構的初衷
能夠無縫替換我們正在使用的各個組件,為未來統一分析打好基礎
運維簡單,減輕開發運維同學的日常工作復雜度
最后是需要社區比較活躍,問題能得到及時的處理
以下是我們針對各個維度的一些調研結果。
性能對比
我們針對單表和多表 Join 兩種真實線上場景進行了具體測試,采用兩個相同規模的集群,對同一數據量的表,進行相同的查詢,多次查詢,取平均值的方式進行對比。ClickHouse 集群規模:單節點 96C * 384G , StarRocks 集群 6 * 16C * 64G。單表查詢的數據量大小為 200G,數據行數為1.3億行,對表進行 count 計數查詢。Join 查詢為表進行自 Join,然后進行 count 計數查詢。
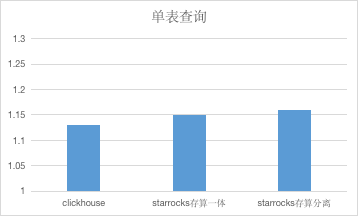
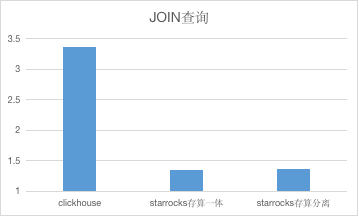 StarRocks VS ClickHouse
StarRocks VS ClickHouse
測試表明,在 ClickHouse 最拿手的單表查詢場景中, StarRocks 存算分離性能可以保持一致,在多表 Join 場景中,StarRocks 能快3倍左右。
存儲成本
在對比了性能后,我們對比了存算一體和存算分離的成本情況。在存算一體中數據量 1T 的表通過 export 到 OSS,再通過 Broker Load 到存算分離集群中,由標準磁盤存儲轉換為對象存儲,后期還可以在對象存儲內將數據進行冷熱歸檔,進一步節省成本。從云服務文檔中了解到,標準磁盤存儲 1T 存儲一天7 (某云法蘭克福 OSS 計費),存儲費用降為原來的1/15。成本的詳細計算可以看后文。
易用性
我們了解到 StarRocks 也推出了 Operator 支持 K8s 集群部署。利用 K8s 本身的容災恢復機制以及強大的 StarRocks Operator 顯著降低了集群部署運維復雜性。另外,StarRocks 還提供了較為豐富的監控和診斷工具,便于我們在第一時間觀察系統運行情況。
StarRocks 存算分離實踐
查詢優化
物化視圖
在一些實時查詢的場景,我們發現,通過物化視圖進行預聚合的方式,能達到查詢事半功倍的效果。例如我們的實時分析場景,通過 Flink 直接將明細數據寫入到 StarRocks,最初直接對原始明細數據復雜查詢,耗時約30秒左右,后來看社區力推物化視圖,我們也為該表創建異步物化視圖,對明細數據進行預聚合,結果顯示,查詢延遲降低為3秒左右,帶來了10倍性能提升。
物化視圖的場景我們剛剛體驗,就取得了比較驚艷的效果,未來我們將在更多場景中推廣該能力,進一步提升業務同學體驗。
數據分桶
在初見 StarRocks 存算分離時,我們簡單認為數據存儲在對象存儲中,建表時我們沒有關注分桶數設置,分桶數設置過多,結果在使用時發現隨著系統 Tablet 數量越來越多,發現 FE 的內存被打滿。后來在社區同學幫助下定位發現是由于 Tablet 過多導致 FE 節點一直在 GC。最后通過增加 FE 內存,再按數據量合理分配不同表的分桶數便徹底解決了該問題。
根據我們實際使用的經驗來看,一般為每個分桶差不多容納 1 ~ 3G 數據容量比較合理,過多的數據分桶會產生大量的小文件且降低了 I/O 效率,而分桶數不足則可能會影響查詢的并發效果。
聚合查詢模型
最初公司大部分報表都是參照 Kylin 模型,使用 Hive、Spark 將數據預聚合處理,再將處理結果數據導入到 StarRocks 中進行查詢,依靠 StarRocks 強大的查詢能力降低查詢延遲。
這種方式雖然提升了查詢速度,但會導致數倉中結果表的數據量膨脹,且部分報表增加維度后會存在數據兼容性問題。后來我們將部分預聚合查詢轉換為 StarRocks 的聚合模型,通過測試和提前預聚合的查詢效率幾乎相同,同時也解決了數據膨脹和歷史數據兼容問題。
Cache
上面我們提到調研測評時,我們也詳細評估了存算分離與其他系統的性能對比,上面的測試都是在開啟 Local Disk Data Cache 情況下達到,因此,我們對于線上所有的表在創建時都開啟了 Data Cache。
目前,我們線上計算節點規模為6個,每個計算節點配置了 2 塊 200G 容量大小的 SSD(最好不要用 HDD),通過該配置,我們基本上能將業務訪問的熱點數據都緩存在 Local Disk 上。同時,我們觀察到目前線上磁盤使用到達一定量時,存儲空間會自動下降,經過與社區溝通發現這是內部觸發了自動 LRU 緩存淘汰,這一點極大緩解了我們空間焦慮。
降本
使用 StarRocks 存算分離替換現有架構后,能在以下三個方面給成本帶來較大的降低:
將 OLAP 組件換成 StarRocks,首先是通過聚合模型替代在數倉中的結果表預聚合,不必對所有維度進行排列組合,計算各個組合的結果數據。省去這一步驟后,存儲對比之前減少了20%左右。 通過使用 StarRocks 存算分離,數據被存儲在對象存儲,通過將存算一體集群中 5T 左右的數據導入到對象存儲中,一個月能節省 1000$ 左右,未來隨著數據量的不斷增長,成本降低會愈發明顯。 使用 K8s 部署,方便部署的同時也省去了一筆不菲的云平臺服務費。
通過以上幾點綜合測算,相比原來使用 Spark 離線計算出結果,再將結果導入ClickHouse 的方式,使用 StarRocks 存算分離,我們將成本降低了 46%。
運維監控
StarRocks 的監控可以無縫對接 Prometheus 和 Grafana,使用 StarRocks 存算分離版本后,我們根據建議首先配置了較為完善的監控,StarRocks 存算分離在存算一體基礎上增加了不少對于系統 I/O 等指標,通過這些監控我們可以直觀查看當前的各種指標。

FE、BE相關監控
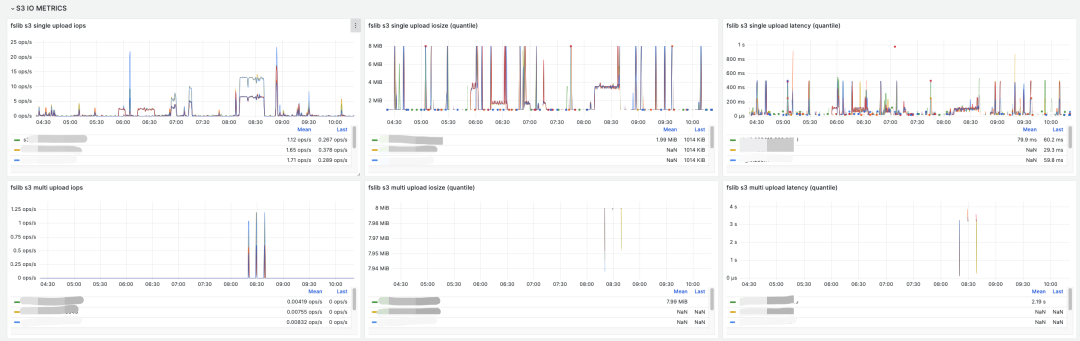
StarRocks I/O 相關監控
另外,我們使用過程中比較關注查詢性能問題,而也出現過由于版本太多導致了查詢時讀取文件數較多的問題,在社區提醒下,可以利用 SQL 監控當前集群 Compaction 情況:
有了這種監控,我們也能看出當前是否出現 Compaction 慢等情況并考慮是否資源不足,需要擴容。
另外,從使用來看,相比于存算一體,存算分離版本有一個極大的簡化就是無需關注多副本數據一致性,存算分離數據位于 OSS 之上,本地緩存單副本,再也無需關注副本的數據均衡遷移、數據修復等問題,這是一個不小的解放。
最后,社區的各種文檔也比較豐富,尤其是存算分離最近給我們提供了最佳實踐、各種運維指導、參數優化等文檔,作為 StarRocks 新用戶,我們也能根據這些文檔快速上手取得最佳效果。當然,隨著使用的深入,我們還希望能更深入地了解 StarRocks 內部實現原理,希望社區能在這方面提供更多指導。
我們使用存算分離集群,上線初期遇到了一些 bug 導致集群運行不穩定,但是在社區幫助下,我們快速定位并修復后,現在集群已經穩定運行了3月有余。
數據遷移
由于目前社區尚未提供一鍵式遷移工具將數據從存算一體集群遷移至存算分離集群,咨詢過社區后,我們決定采用 export 到對象儲存再使用 Broker Load 到新集群的方式進行數據遷移。
另外,在進行 Broker Load 時,導入任務和線上查詢任務會對磁盤的 I/O 資源產生爭用,這可能會導致 K8s 將 BE 節點驅逐,進而導致短時間 StarRocks 查詢變慢,對此我們也建議降低 Broker Load 并發度,同樣通過分批導入的方式來減少 I/O 爭搶。
通過 Export + Broker Load 配合我們提到的優化手段,目前,我們已經將線上 80% 的業務數據遷移到存算分離集群中,并做到用戶在使用上體驗感更佳。后續會繼續將所有業務遷移至集群,最終完成統一大業。
另外,我們也從社區獲知,社區已經在推進一鍵式遷移工具的開發,如果不著急的小伙伴可以等等這個,我們后續也會嘗試使用這種新方式來提升數據遷移效率,另外,我們也很期待社區能推出從更多數據源的遷移方式,便于我們可以更快速地將數據架構統一至 StarRocks。
未來規劃
短期目標|數據湖 + StarRocks 縮短計算鏈路
數據入倉后,ODS 層的統一處理需要2-3個小時,這對數據及時產出有不小的影響,且計算成本較高。通過對數據湖的調研,我們計劃將 ODS 層的處理提前到 Flink 當中,省去這幾個小時的計算時間和計算資源,將 Flink 處理的數據直接落入數據湖中。利用 StarRocks 和數據湖的結合,實現對數據的實時查詢,解決離線數倉中的數據不方便實時查詢的問題。
長期規劃|使用 StarRocks 構建數據湖倉一體新架構
在文章的開頭我們也提過,公司現在使用了三種 OLAP 組件服務不同場景,每種組件都需要將 Spark 加工好的數據導入至對應系統,運維復雜,難以保證數據時效性同時數據的多方存儲也進一步提升了成本。我們也一直在思考,能否做到 Spark 不參與計算加工,只用 StarRocks 搭建數倉呢?經過我們調研推導,發現還是有可能實現這一步的。
具體來說,Flink 消費 Kafka 的數據后,直接入湖(Hudi、Iceberg 等),接下來我們利用 StarRocks 作為計算引擎直接查詢湖上數據,利用強大的湖查詢能力(這塊尚未深入測試,看社區其他用戶有不少 Good Case)可以直接進行查詢,對于某些查詢效率較低的查詢,我們直接為其構建物化視圖。
我們之前的測試表明,利用物化視圖能帶來 10 倍以上的加速效果。構建數倉的過程中,涉及到簡單的 ETL 也能夠通過邏輯視圖結合物化視圖的方式來完成。通過這樣一套 Lakehouse 新架構,我們理想中能夠達到以下幾點目的:
去掉當前多套 OLAP 服務,只保留 StarRocks 作為計算引擎,節約大量計算資源
數據無需多處存儲,降低數據延遲時效性。同時使用存算分離架構,數據單一存儲能節約大量存儲成本(尤其原來存算一體架構下數據依靠云盤多副本存儲,云盤價格過于昂貴) 利用 StarRocks 存算分離帶來的彈性和數據共享能力,我們可以做到
1). 為不同的業務實現資源硬隔離;
2). 業務峰谷期間可以輕松實現快速彈性,業務高峰期快速擴容以應對突發流量,業務低峰期可以快速縮容以削減成本
架構簡化也減輕了運維復雜度,使得我們有更多時間可以考慮提升業務增效,來達到公司降本增效的目的。
而且,通過調研學習,發現眾多業內技術領先企業和我們的想法不謀而合。
本文由 mdnice 多平臺發布
)


)















