目錄
一、函數
1.函數的由來
2.函數的作用
3.函數的使用方法
4.函數的定義
5.查看函數
6.刪除函數
7.函數返回值
8.函數的傳參數
9.函數遞歸
二、數組
1.數組的相關介紹
2.聲明數組
3.定義數組的格式
4.冒泡排序
總結:本章主要介紹了函數和數組相關知識
一、函數
1.函數的由來
在編寫腳本時,有些腳本可以反復使用,可以調用函數來解決,腳本定義成函數類似于別名
2.函數的作用
函數的作用:避免腳本重復性,增加可讀性,方便使用
3.函數的使用方法
先定義函數再引用函數
1.直接寫 函數中調用函數 直接寫函數名
2.同名函數 后一個生效
3.調用函數一定要先定義
4.每個函數是獨立
4.函數的定義
基本格式
1.
function 函數名 {
命令序列
}
2.
函數名 () {
命令序列
}
3.
function 函數名 {
命令序列
}
例子:

5.查看函數
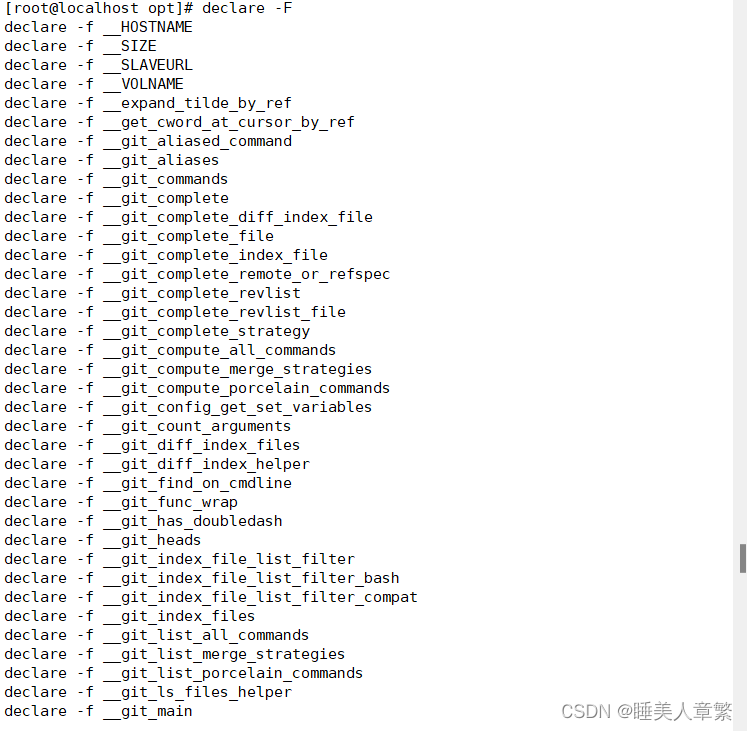
declare -F? ?查看函數列表
declare -f? ? 查看函數的具體定義

6.刪除函數
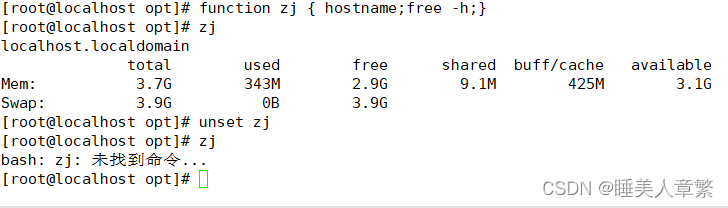
unset 函數名
7.函數返回值
return(自定義返回值)范圍(0-255)超出時除以256取余
return表示退出函數并返回一個退出值,腳本中可以用$?變量表示該值
使用原則:
-
函數一結束就去返回值,應為$?變量只返回執行的最后一條命令的退出返回碼
-
退出碼必須是0-255,超出的值將為除以256取余
[root@localhost opt]# vim f.sh
[root@localhost opt]# bash f.sh
輸入數字:8
16
#!/bin/bash
fc1 (){
read -p "輸入數字:" s
return $[$s*2]
}
fc1
echo $?

8.函數的傳參數
函數的$1和$2是指跟在函數后面的值
腳本中的$1,$2和函數的$1,$2是沒有關系的
[root@localhost data]# vim r.sh
[root@localhost data]# bash r.sh 2 3
2
3
#!/bin/bash
sum1 (){
echo $1
echo $2
}
sum1 $1 $2

函數變量的作用范圍
local命令:只在內部有效對外部無效(局部變量)只對函數有效
name命令:普通變量
export命令:讓子shell繼承變量
如果加local關鍵字可以讓變量只在函數中生效,不會影響外界函數的返回值
9.函數遞歸
函數調用自己本身的函數(階乘)
例:
5!=5*4*3*2*1=120
4!=4*3*2*1=24
#/bin/bash
fact () {if [ $1 -eq 1 ]thenecho "1"elser=$[$1*`fact $[$1-1]`]echo $rfi
}
fact $1
vim jc.sh
[root@localhost data]# bash jc.sh 3
6
[root@localhost data]# bash jc.sh 4
24
二、數組
1.數組的相關介紹
數組分為普通數組和關聯數組
普通數組下標為數字
關聯數組下標為有含義的字符串
變量:存儲單個元素的內存空間
數組:存儲多個元素的連續的內存空間,相當于多個變量的集合
數組名和索引
索引的編號從0開始,屬于數值索引
索引可支持使用自定義的格式,而不僅是數值格式,即為關聯索引
bash的數組支持稀疏格式(索引不連續)
2.聲明數組
使用數組需要先聲明數組
普通數組:? ? ? ? ? ? ? ? ? ? ? ? ? declare -a [數組名]
普通數組不需要手動聲明,系統自動幫你聲明
關聯數組:? ? ? ? ? ? ? ? ? ? ? ? ? declare -A [數組名]
關聯數組一定要聲明
3.定義數組的格式
定義數組格式:
1.數組名=(value0 value1 value2 value3 ......)
2.數組名=([0]=value [1]=value1 [2]=value2 ....)
3.列表名="value0 value1 value2 value3 ...... "
4.數組名=($列表名)
數組名[0]="value1"
數組名[1]="value2"
數組名[2]="value3"
數組的包括數據類型
數值型
字符型
混合型數值加字符
使用" "或' '定義單引號或雙引號括起來
[root@localhost ~]# a=(10 20 30 40 50)
[root@localhost ~]# declare -a
declare -a BASH_ARGC='()'
declare -a BASH_ARGV='()'
declare -a BASH_LINENO='()'
declare -a BASH_SOURCE='()'
declare -ar BASH_VERSINFO='([0]="4" [1]="2" [2]="46" [3]="2" [4]="release" [5]="x86_64-redhat-linux-gnu")'
declare -a DIRSTACK='()'
declare -a FUNCNAME='()'
declare -a GROUPS='()'
declare -a PIPESTATUS='([0]="0")'
declare -a a='([0]="10" [1]="20" [2]="30" [3]="40" [4]="50")'
[root@localhost ~]# echo ${!a[*]}
0 1 2 3 4
[root@localhost ~]# echo ${a[0]}
10
[root@localhost ~]# echo ${a[@]}
10 20 30 40 50
[root@localhost ~]# echo ${#a[@]}
5
[root@localhost ~]# echo ${!a[@]}
0 1 2 3 4
[root@localhost ~]#?
a=(10 20 30 40 50) 定義數組
declare -a? 查看數組
?echo ${!a[*]}? 查看下標
echo ${a[0]}? 查看數組中個體
echo ${!a[*]}? 查看所有下標
echo ${a[@]}? 查看數組中的所有個體
echo ${#a[@]}? ?查看數組的長度(個數)
echo ${!a[@]}? ?查看所有下標
*和@同義
數組分隔
echo ${a[@]:0:5}
[root@localhost ~]# echo ${a[@]:0:5}
10 20 30 40 50
[root@localhost ~]# echo ${a[@]:2:5}
30 40 50
[root@localhost ~]# echo ${a[@]:2:2}
30 40
[root@localhost ~]# echo ${a[@]:2:3}
30 40 50
[root@localhost ~]# echo ${a[@]}
10 20 30 40 50
[root@localhost ~]#?
echo ${a[@]:0:5}? 代表跳過前0個提取后5個
echo ${a[@]:2:2} 代表跳過前2個提取后2個
echo ${a[@]}? 代表數組所有個體
[root@localhost ~]# echo ${a[@]}
10 20 30 40 50
[root@localhost ~]# echo ${a[1]}
20
[root@localhost ~]# a[1]=9
[root@localhost ~]# echo ${a[1]}
9
[root@localhost ~]# echo ${a[@]}
10 9 30 40 50
[root@localhost ~]#?
a[1]=9 數組替換把原來的20換成了9
4.冒泡排序
冒泡 ? 是通過數字比較 將大的數往后排 ?小的數往前面排
5個數字 5-1=4 ?需要比較4輪 ?才能知道每一個數字的具體位置
a=(10?50 89?46?38)?
輪次 ?總個數 ? 需要比較的數 ?比幾次 ? ? 找到的數
第1輪 ?5 ? ? ?5個數 ? ? ? ?比4次 ? ? 找到最大數 ? ?
第2輪 ?5 ? ? ?4個數 ? ? ? ?比3次 ? ? 找到第二大數 ?
第3輪 ?5 ? ? ?3個數 ? ? ? ?比2次 ? ? 找到第三大的數
第4輪 ?5 ? ? ?2個數 ? ? ? ?比1次 ? ? 找到第四大的數
#!/bin/bash
a=(10 50 89 46 38)
for ((i=1;i<5;i++))
dofor ((j=0;j<5-$i;j++))dof=${a[$j]}m=$[$j+1]s=${a[$m]}if [ $f -gt $s ]thenq=$fa[$j]=$sa[$m]=$qfidone
done
echo "排序后的數組為${a[@]}"
[root@localhost data]# vim mpd.sh
[root@localhost data]# bash mpd.sh
排序后的數組為10 38 46 50 89
[root@localhost data]#?







)

】if語句詳解)
)



)
Stack與Queue的模擬實現)



