操作環境:
MATLAB 2022a
1、算法描述
Q-learning是一種無模型的強化學習算法,適用于有限的馬爾可夫決策過程(MDP)。它的核心是學習一個動作價值函數(action-value function),即Q函數,這個函數用于估計在某狀態下采取特定動作能帶來的期望回報。
詳細步驟如下:
-
初始化Q表:首先,我們需要初始化一個Q表,這個表格包含了所有可能狀態和在這些狀態下可以采取的動作的組合。每個狀態-動作對應的值(Q值)初始通常設為0。
-
探索與利用:在每個時間步驟,智能體(agent)需要決定是探索新動作還是利用已知的信息。這通常通過ε-greedy策略實現,即以ε的概率進行隨機探索,以1-ε的概率選擇當前已知最優動作。
-
動作執行和環境反饋:智能體根據選定的策略執行動作,然后環境會根據智能體的動作提供下一個狀態和獎勵。
-
Q值更新:智能體根據獲得的獎勵和預期未來回報更新Q表。
-
重復過程:重復上述過程,直到滿足某些停止準則,例如達到最大迭代次數或Q表收斂。
2、仿真結果演示

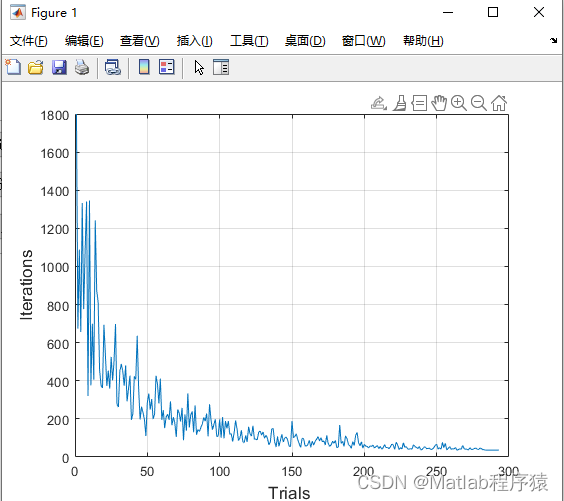
3、關鍵代碼展示
略
4、MATLAB?源碼獲取
? ? ? V
點擊下方名片



和表空間(Tablespace))













)

