1.研究背景與意義
隨著計算機技術的不斷發展,圖像處理和計算機視覺領域取得了長足的進步。圖像風格遷移是其中一個備受關注的研究方向,它可以將一幅圖像的風格特征應用到另一幅圖像上,從而創造出新的圖像。這項技術具有廣泛的應用前景,如藝術創作、電影特效、虛擬現實等領域。
傳統的圖像風格遷移方法主要基于優化算法,通過最小化圖像的內容損失和風格損失來實現。然而,這些方法存在一些問題,如計算復雜度高、結果不穩定等。近年來,生成式對抗網絡(GANs)的出現為圖像風格遷移帶來了新的突破。
GANs是一種由生成器和判別器組成的神經網絡結構,通過博弈的方式訓練生成器生成逼真的圖像,同時判別器則試圖區分真實圖像和生成圖像。GANs的核心思想是通過生成器和判別器之間的對抗學習,不斷提升生成器的生成能力,從而生成更加逼真的圖像。
基于生成式對抗網絡的圖像風格遷移系統具有以下幾個方面的研究意義:
-
提高圖像風格遷移的效果:傳統的圖像風格遷移方法往往無法完全捕捉到圖像的風格特征,導致生成的圖像與目標風格之間存在差異。而基于GANs的方法可以通過對抗學習不斷優化生成器,從而生成更加逼真、細致的圖像,提高圖像風格遷移的效果。
-
提高圖像風格遷移的穩定性:傳統的圖像風格遷移方法在處理復雜的圖像時往往存在結果不穩定的問題,生成的圖像可能會出現失真、模糊等情況。而基于GANs的方法可以通過對抗學習的方式提高生成器的穩定性,生成更加清晰、真實的圖像。
-
拓展圖像風格遷移的應用領域:基于生成式對抗網絡的圖像風格遷移系統具有廣泛的應用前景。例如,在藝術創作領域,藝術家可以利用這一系統將不同風格的繪畫作品進行融合,創造出獨特的藝術作品。在電影特效領域,可以利用該系統將不同風格的特效圖像應用到電影中,增強視覺效果。在虛擬現實領域,可以利用該系統將真實世界的風格特征應用到虛擬場景中,提升虛擬現實的真實感。
總之,基于生成式對抗網絡的圖像風格遷移系統具有重要的研究意義和廣泛的應用前景。通過提高圖像風格遷移的效果和穩定性,可以為藝術創作、電影特效、虛擬現實等領域帶來更多可能性,推動圖像處理和計算機視覺技術的發展。
2.圖片演示



3.視頻演示
基于生成式對抗網絡的圖像風格遷移系統_嗶哩嗶哩_bilibili
4.生成式對抗網絡簡介
卷積神經網絡與循環神經網絡是目前較常見的兩類人工神經網絡算法,前者長于處理圖像信息,后者常用于處理序列信息。它們都需要大量的訓練樣本來保證訓練的質量,需要成千上萬張圖片來做訓練。但與脫胎于生物神經元模型的深度學習算法不同,成年人的學習過程卻并不需要海量的樣本和數據。因此,有學者開始嘗試發展小樣本學習的神經網絡算法,希望用少量的樣本就可以訓練出較為準確的網絡模型,生成式對抗網絡就是近年來發展較快的模型之一。
2014年,I.J.Goodfellow等人提出了一個深度學習算法的新框架,該模型借鑒了二人零和博弈的思想,通過對抗過程估計生成模型,即假設在游戲博弈過程中雙方都同時采取最優的方案并使用,使得游戲結果達到納什均衡的狀態。在該算法中,生成式模型G和判別式模型D一起進行訓練。其中,G負責學習樣本數據分布,D則估計樣本來自生成器G或訓練數據的概率。生成式模型需要盡量降低判別式模型對數據做出
正確判斷的概率,而判別式模型則要不斷識別出生成式模型生成的假數據,兩個模型間相互對抗,互相提高,最終使得生成式模型生成的數據與真實數據在數據分布上差別很小,而判別式模型最后則無法判斷該數據是來自真實的數據集還是由生成器G所生成。
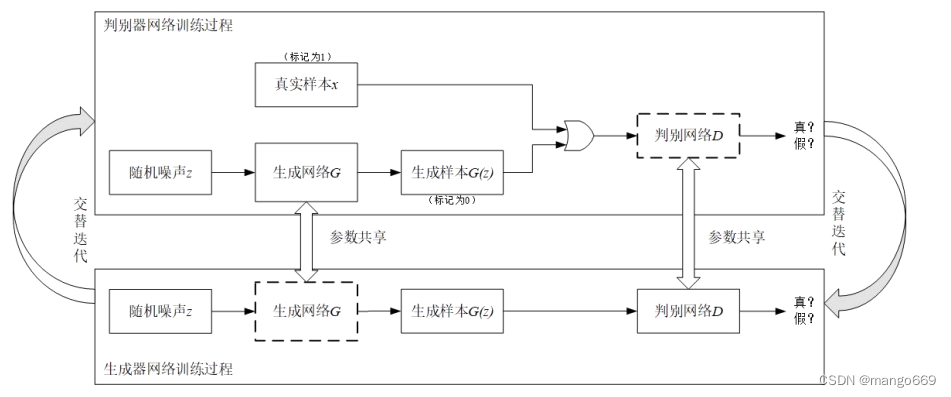
GoodFellow提出的生成式對抗網絡,判別器網絡使用常規的訓練方法,訓練數據則包括小批量的真實樣本數據集和隨機噪聲z,真實的樣本被標記為1,生成器網絡輸入噪聲之后生成的假樣本標記為0。用G(z)表示新的數據集,判別式模型D則有兩個輸入,分別是表示真實數據的x和生成式模型G生成的數據,真實數據的分布則用Pilan(t)表示,判別式模型對數據進行判斷,輸出一個標量值。然后做反向傳播更新生成器網絡的參數,判別器網絡的參數不變,交替訓練,經過多次迭代,假樣本的數據分布相較于真實數據幾乎相同,即生成器網絡生成的假數據判別器已經無法正確出該數據的真偽,訓練過程如圖所示。
5.核心代碼講解
5.1 cycleGAN.py
class ResidualBlock(nn.Layer):"""定義殘差塊"""def __init__(self, in_channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2D(in_channels, in_channels, kernel_size=3, stride=1, padding=1)self.bn1 = nn.BatchNorm2D(in_channels)self.prelu = nn.PReLU()self.conv2 = nn.Conv2D(in_channels, in_channels, kernel_size=3, stride=1, padding=1)self.bn2 = nn.BatchNorm2D(in_channels)def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.prelu(out)out = self.conv2(out)out = self.bn2(out)out += identityreturn outclass cycleGAN(nn.Layer):"""定義cycleGAN網絡"""def __init__(self, upscale_factor=4, num_residual_blocks=16):super(cycleGAN, self).__init__()self.conv1 = nn.Conv2D(3, 64, kernel_size=3, stride=1, padding=1)self.prelu = nn.PReLU()# 添加殘差塊residual_blocks = []for _ in range(num_residual_blocks):residual_blocks.append(ResidualBlock(64))self.residual_blocks = nn.Sequential(*residual_blocks)self.conv2 = nn.Conv2D(64, 64, kernel_size=3, stride=1, padding=1)self.bn2 = nn.BatchNorm2D(64)# 上采樣層,使用反卷積進行上采樣upsampling_layers = []for _ in range(int(upscale_factor / 2)):upsampling_layers.append(nn.Conv2DTranspose(64, 64, kernel_size=3, stride=2, padding=1, output_padding=1))upsampling_layers.append(nn.BatchNorm2D(64))upsampling_layers.append(nn.PReLU())self.upsampling = nn.Sequential(*upsampling_layers)self.conv3 = nn.Conv2D(64, 3, kernel_size=3, stride=1, padding=1)def forward(self, x):out = self.conv1(x)out = self.prelu(out)residual = self.residual_blocks(out)out = self.conv2(residual)out = self.bn2(out)out += residualout = self.upsampling(out)out = self.conv3(out)return out
該程序文件cycleGAN.py定義了一個CycleGAN網絡模型。該模型包含兩個主要部分:ResidualBlock和cycleGAN。
ResidualBlock是一個殘差塊,用于增加網絡的深度和學習能力。它包含兩個卷積層和兩個批歸一化層。在前向傳播過程中,輸入通過第一個卷積層和批歸一化層,然后通過PReLU激活函數。然后,輸出通過第二個卷積層和批歸一化層。最后,將輸入和輸出相加得到殘差塊的輸出。
cycleGAN是整個網絡模型。它包含一個卷積層、一個PReLU激活函數、多個ResidualBlock殘差塊、一個卷積層和一個批歸一化層。在前向傳播過程中,輸入通過第一個卷積層和PReLU激活函數。然后,輸出通過多個ResidualBlock殘差塊。接下來,輸出通過第二個卷積層和批歸一化層,并與之前的殘差塊輸出相加。最后,輸出通過上采樣層進行上采樣,并通過最后一個卷積層得到最終的輸出。
該模型用于圖像超分辨率重建任務,通過學習低分辨率圖像和高分辨率圖像之間的映射關系,實現將低分辨率圖像轉換為高分辨率圖像的功能。
5.2 demo.py
class ImageNoise:def __init__(self, path1, path2):self.path1 = path1self.path2 = path2def sp_noise(self, image, prob):"""添加椒鹽噪聲prob:噪聲比例"""output = np.zeros(image.shape,np.uint8)thres = 1 - probfor i in range(image.shape[0]):for j in range(image.shape[1]):rdn = random.random()if rdn < prob:output[i][j] = 0elif rdn > thres:output[i][j] = 255else:output[i][j] = image[i][j]return outputdef add_noise(self, prob=0.1):for i in os.listdir(self.path1):im = cv2.imread(self.path1 + '/' + i)# 調用噪聲函數生成噪聲圖片img_sp = self.sp_noise(im, prob)# 均值濾波img_blur = cv2.blur(img_sp, (20, 20))cv2.imwrite(self.path2 + '/' + i, img_blur)
這個程序文件名為demo.py,它的功能是給指定文件夾中的圖片添加椒鹽噪聲,并對添加噪聲后的圖片進行均值濾波處理,然后將處理后的圖片保存到另一個文件夾中。
具體實現過程如下:
- 導入所需的庫:os、cv2、random、numpy。
- 定義兩個文件夾路徑變量path1和path2,分別表示原始圖片所在的文件夾和處理后圖片保存的文件夾。
- 定義一個函數sp_noise,用于給圖片添加椒鹽噪聲。該函數接受兩個參數,一個是圖片對象image,另一個是噪聲比例prob。函數內部會根據噪聲比例隨機生成椒鹽噪聲,并將噪聲添加到圖片上,最后返回添加噪聲后的圖片。
- 使用os.listdir遍歷path1文件夾中的所有文件。
- 使用cv2.imread讀取每個文件的圖片。
- 調用sp_noise函數給圖片添加椒鹽噪聲,噪聲比例為0.1。
- 使用cv2.blur對添加噪聲后的圖片進行均值濾波處理,濾波器大小為(20, 20)。
- 使用cv2.imwrite將處理后的圖片保存到path2文件夾中,文件名與原始圖片相同。
5.3 setup.py
class PPGAN:def __init__(self):with open('requirements.txt', encoding="utf-8-sig") as f:self.requirements = f.readlines()def readme(self):with open('README.md', encoding="utf-8-sig") as f:self.README = f.read()def setup(self):setup(name='ppgan',packages=find_packages(),include_package_data=True,entry_points={"console_scripts": ["paddlegan= paddlegan.paddlegan:main"]},author='PaddlePaddle Author',version=__version__,install_requires=self.requirements,license='Apache License 2.0',description='Awesome GAN toolkits based on PaddlePaddle',long_description=self.readme(),long_description_content_type='text/markdown',url='https://github.com/PaddlePaddle/PaddleGAN',download_url='https://github.com/PaddlePaddle/PaddleGAN.git',keywords=['gan paddlegan'],classifiers=['Intended Audience :: Developers', 'Operating System :: OS Independent','Natural Language :: Chinese (Simplified)','Programming Language :: Python :: 3','Programming Language :: Python :: 3.5','Programming Language :: Python :: 3.6','Programming Language :: Python :: 3.7', 'Topic :: Utilities'],)
這是一個Python的安裝腳本文件,文件名為setup.py。該腳本用于安裝ppgan工具包,并設置相關的配置信息。腳本中使用了setuptools庫來進行安裝和打包操作,使用了find_packages函數來查找所有的包,使用了open函數來讀取文件內容。
腳本中定義了一個readme函數,用于讀取README.md文件的內容作為長描述。在setup函數中,設置了ppgan的名稱為’ppgan’,包含所有的包,包括數據文件,設置了命令行入口為’paddlegan’,作者為’PaddlePaddle Author’,版本號為__version__,依賴包為requirements.txt中的內容,許可證為Apache License 2.0,描述為’Awesome GAN toolkits based on PaddlePaddle’,長描述為README.md的內容,URL為源碼,下載URL為,關鍵詞為’gan paddlegan’,分類器為一些開發者相關的信息和Python版本信息。
6.系統整體結構
以下是每個文件的功能概述:
| 文件路徑 | 功能 |
|---|---|
| cycleGAN.py | 實現CycleGAN模型的訓練和推理 |
| demo.py | 演示文件,用于展示模型的使用方法 |
| setup.py | 安裝文件,用于安裝依賴和設置環境 |
| ui.py | 用戶界面文件,用于創建圖形用戶界面 |
| applications_init_.py | 應用程序模塊的初始化文件 |
7.圖像風格遷移
藝術風格遷移是一種有吸引力的技術,可以利用內容圖像的結構和示例風格圖像的風格樣式來創造藝術圖像。它已經成為學術界和工業界普遍的研究課題。近年來,人們提出了許多神經風格遷移的方法,大致可分為兩類:圖像優化方法和模型優化方法。
圖像優化方法是利用固定網絡迭代優化風格化圖像。Gatyset等人的開創性工作在迭代優化過程中實現風格遷移,其中風格樣式是通過從預先訓練的深度神經網絡中提取的特征的相關性來捕獲的。后續工作主要以不同損失函數的形式改進。雖然取得了優越的風格化結果,例如STROTSS,但這些方法的廣泛應用仍然受到其在線優化過程緩慢的限制。相反,模型優化方法通過訓練來更新神經網絡,并在測試中進行前饋。主要有三種細分類型:
(1)Per-Style-Per-Model方法,被訓練來合成具有單一特定風格的圖像;
(2)Multi-Style-Per-Model方法,引入多種網絡架構,同時處理多種風格;
(3)Arbitrary-Style-Per-Model方法,進一步采用多種特征修改機制來遷移任意風格。
回顧這些方法,我們發現雖然局部風格樣式可以被遷移,但是混合了全局和局部風格的復雜樣式仍然不能被正確地遷移。與此同時,很多情況下會出現偽影和瑕疵。為此,在本次工作中,我們的主要目標是通過前饋網絡實現高質量的藝術風格遷移,在美學上保留局部和全局的樣式。
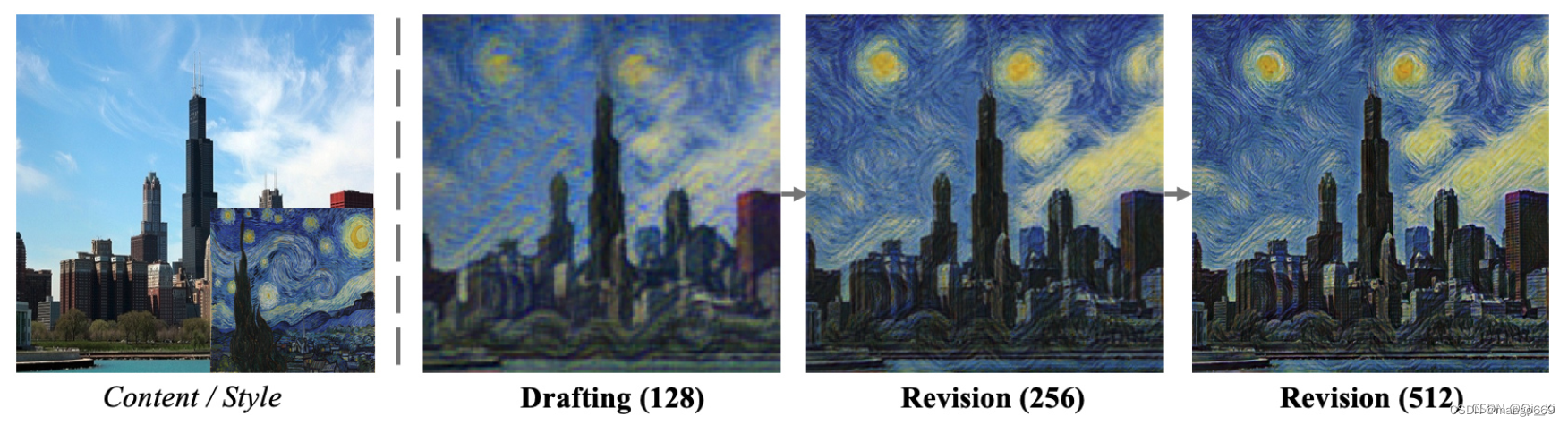
人類畫家在繪畫時如何處理復雜的風格樣式?一個常見的過程,特別是對于初學者來說,是先畫一個草圖捕捉整體結構,然后逐步修改局部細節,而不是直接一步一步完成最終的畫。受此啟發,我們提出了一種新的用于風格遷移的神經網絡——拉普拉斯金字塔網絡(LapStyle)。首先,在我們的框架中,Drafting Network被設計用于在低分辨率下遷移全局風格樣式,因為我們觀察到,由于更大的感受野和更少的局部細節,全局風格更容易在低分辨率下遷移。然后使用Revision Network根據草稿和拉普拉斯濾波在2倍分辨率的內容圖像上提取的紋理,通過產生殘差圖像,在高分辨率下修改局部細節。注意,我們的Revision Network可以以金字塔的方式堆疊,以生成更高分辨率的細節。最終的風格化圖像是通過聚合所有金字塔層的輸出得到的。此外,我們采用淺色塊判別器對局部風格樣式進行對抗性學習。如圖1所示,我們的“Drafting and Revison”過程取得了不錯的風格化結果。
綜上所述,主要貢獻如下:
我們引入了一個新的框架“Drafting and Revison”,通過將風格遷移過程拆分為全局風格樣式起草和局部風格樣式修訂來模擬繪畫創作機制。
我們提出了一種新的前饋式遷移方法LapStyle。采用Drafting Network遷移低分辨率的全局風格樣式,采用高分辨率Revision Network根據內容圖像的多級拉普拉斯濾波輸出,以金字塔方式修正局部風格樣式。
實驗證明,我們的方法可以生成高分辨率和高質量的風格化結果,其中全局和局部風格樣式都是有效合成的。此外,本文提出的LapStyle具有極高的效率,能夠在512分辨率下達到100fps的速度。
8.網絡結構
對于輸入的內容圖像xc和風格圖像xs,分別提取其拉普拉斯金字塔區。, r.2和(xs,r’s),其中x,是xc兩倍下采樣的結果,而殘差圖r ,是利用拉普拉斯濾波器得到的,保存了下采樣時丟失的高頻信息。風格圖像也做了同樣的處理
在第一階段,Drafting Network首先使用預訓練的神經網絡對來自又.和x.的內容特征和風格特征進行編碼,然后使用多粒度的風格特征對內容特征進行調制,最后使用解碼器生成風格化圖像.xs。在第二階段,Revision Network首先將.c上采樣到x s,然后將x 和r o連接起來作為網絡輸入,生成帶有高頻風格化細節的殘差圖rs。最后,我們通過聚合低分辨率風格化結果和高分辨率殘差圖得到最終風格化圖像xcs。
Drafting Network
Drafting Network的目的是在低分辨率下綜合全局樣式。為什么用低分辨率?我們觀察到,由于接收域大,局部細節少,全局樣式在低分辨率下更容易遷移。為了實現單一風格的遷移,早期的工作直接訓練一個編碼器-解碼器模塊,其中只有內容圖像被用作輸入。為了更好的結合風格特性和內容特性,我們從最近的任意風格遷移方法中采用了AdaIN。
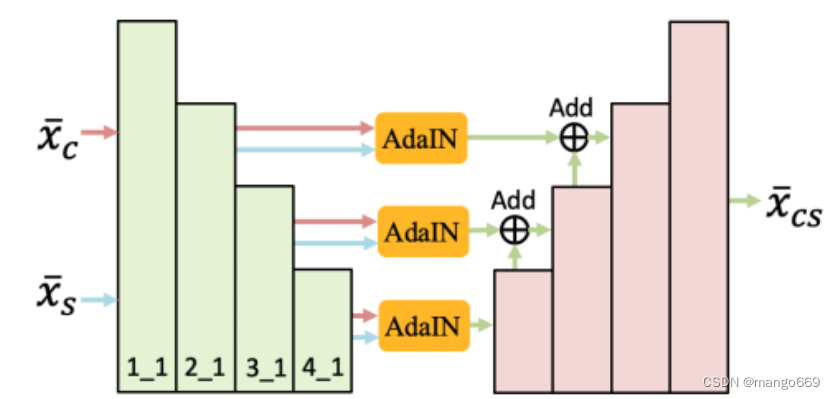
Drafting Network的結構如圖3所示,其中包括一個編碼器、幾個AdaIN模塊和一個解碼器。 (1) 編碼器是一個預先訓練好的VGG-19網絡,在訓練過程中是固定的。對于給出的x xxc和x xxs,VGG編碼器在2_1、3_1和4_1層提取多個粒度的特征。 (2) 然后,我們分別在2_1、3_1和4_1層后使用AdaIN模塊在內容和風格特征之間進行特征調制。 (3) 最后,在解碼器的每個粒度中,來自AdaIN模塊的相應特征通過跳躍連接進行合并,在這里,利用低級別和高級別的AdaIN模塊之后的跳躍連接有助于保留內容結構,特別是對于低分辨率圖像。
Revision Network
Revision Network的目的是通過生成殘差細節圖像來修正粗糙的風格化圖像,而最終的風格化圖像是通過聚合r c和粗糙的風格化圖像區xs生成的。這個過程確保了全局風格樣式在xs中的分布得到了妥善的保留。同時,Revision Network更容易學習利用殘差細節圖像對局部風格圖像進行修正。
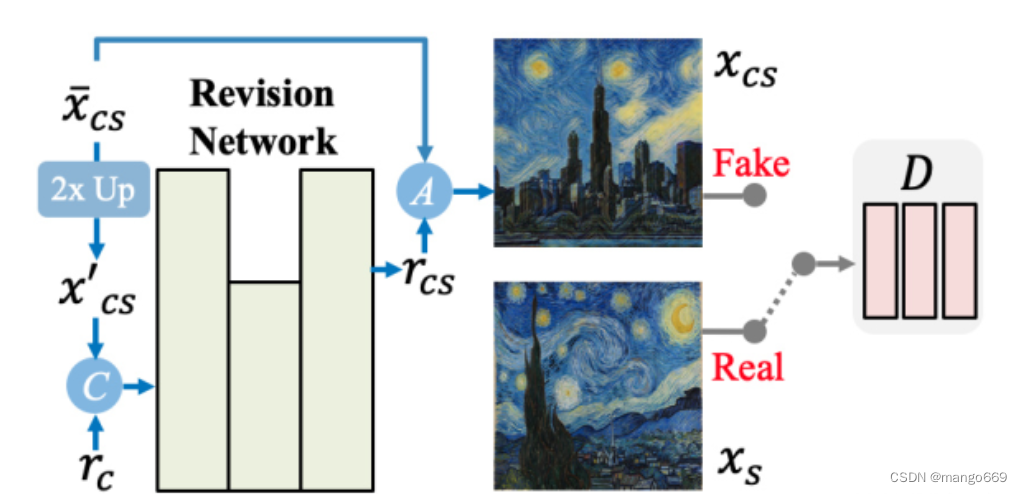
如圖所示,Revision Network設計為簡單有效的編解碼器架構,只有一個下采樣層和一個上采樣層。此外,我們還引入了一個patch判別器來幫助Revision Network在對抗學習設置下捕獲精細的patch紋理。我們選擇定義一個相對較淺的D,(1)避免過度擬合,因為我們只有—個風格圖像;(2)控制感受野,以確保只能捕獲局部樣式。
9.系統整合
下圖完整源碼&環境部署視頻教程&自定義UI界面

參考博客《基于生成式對抗網絡的圖像風格遷移系統》
)
)




)



隊列實現棧功能)


)





