總覽

協同過濾算法,就是一種完全依賴用戶和物品之間行為關系的推薦算法。
從字面理解,協同大家的反饋、評價和意見一起對海量的信息進行過濾,從中篩選出用戶可能感興趣的信息。
知識概括
從這幾個方面進行分析。
一、基于用戶的協同過濾
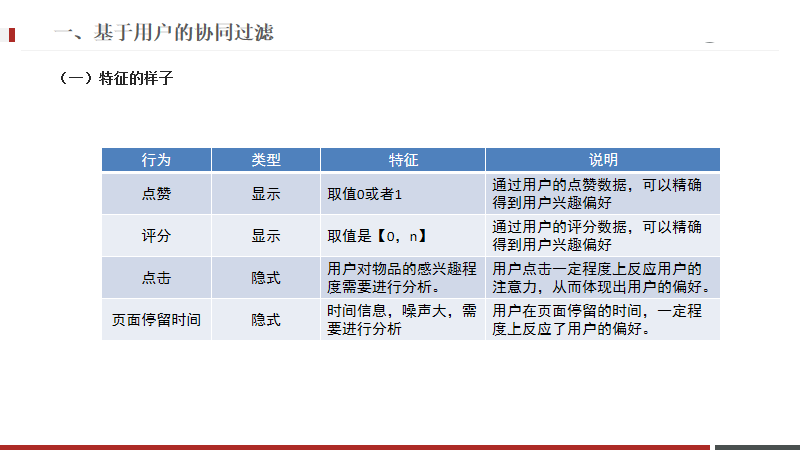
顯示能夠直接看出用戶的偏好,
隱式需要自己動手挖掘數據,如果方法不夠準確,可能找的會有問題。
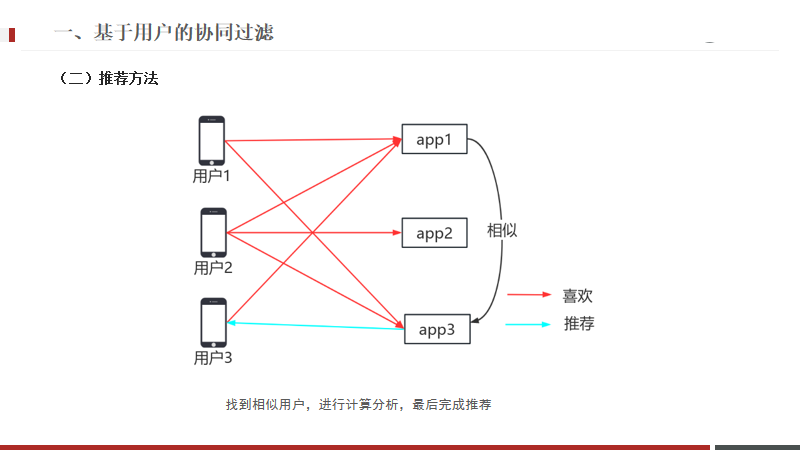
從這個圖中可以看出,用戶一與用戶三都喜歡APP1,
這兩位用戶的興趣可能是一樣的,可以做出推測,用戶3可能是喜歡app3的
 稀疏是說通常商品非常多,用戶購買的只是其中極小一部分
稀疏是說通常商品非常多,用戶購買的只是其中極小一部分
計算講的是用戶和物品的矩陣會非常龐大,此外還有增量數據的同步問題。人們的興趣一直在變,去同步這種變化的數據就是一種計算問題。
冷啟動是指新用戶到來,本身沒有和其他用戶有關聯,這種情況該如何推薦
二、基于物品的協同過濾
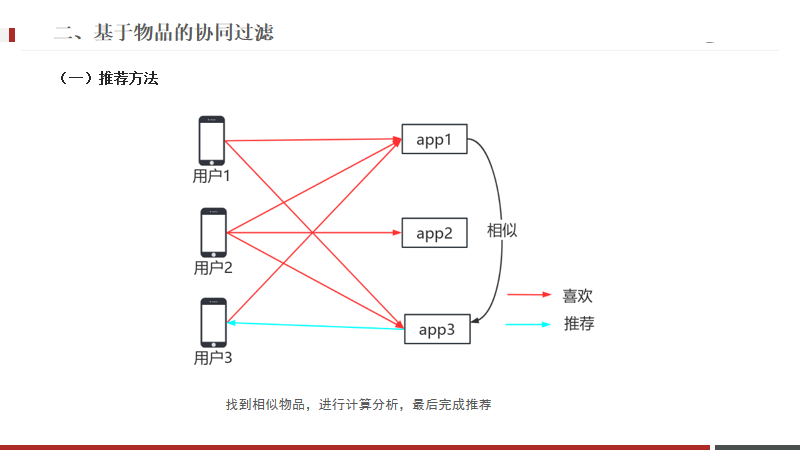
在推薦中,如果用物品1和物品3經常一起出現,也就是說用戶購買1的時候也大概率會買3,
那么出現新用戶3喜歡物品1,同時也用戶3推薦物品3.
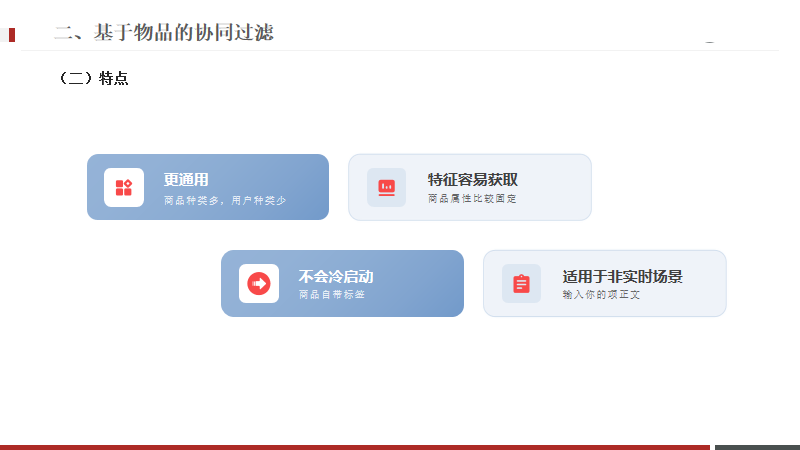
更流行,現階段各大網站基本都是用戶較多,
商品(種類)比用戶少的多商品屬性通常比較固定,特征獲取容易,而且基本不會改變
即便上架了新商品,它自身也有各種標簽,不會像用戶一樣是張白紙
應用場景更適合當下各種網站,APP(實時的除外,例如新聞)的、
三、矩陣分解

如果有100w的用戶,1個億的產品,這兩個組合一個矩陣,數據量太大,計算分析困難。
怎么樣能通過一種方法降低這個計算復雜度,將最終目標實現,就是矩陣分解要做的事情。

這是用戶歌曲之間的行為數據,1代表聽過個,0代表沒有聽過。
可以看出是比較稀疏的矩陣,目標是預測空白值是多少。
如果直接算的話,計算效率比較低
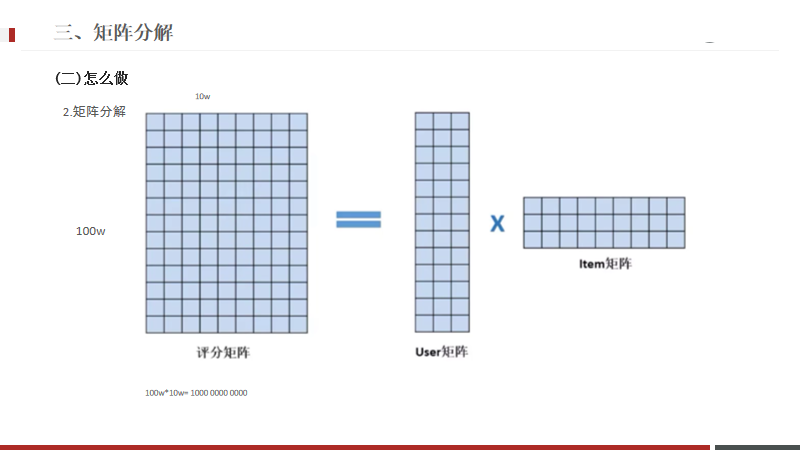
原始矩陣是100w10w,
拆分為兩個矩陣:100w3 與 3*10w兩個矩陣,這兩個矩陣就相對小很多,
這個3是隱向量,

最后可以分解成這樣的矩陣,
這里的三個特征,就是隱向量,其實就是特征的高維表達,很難去解釋。
這里的民謠、兒歌,是為了方便理解,這樣寫出來的。但其實沒有辦法解釋,如右下角所示。
優化好小矩陣中的數值,最終合并成一個大表。

如圖中所示,通過不斷調整參數,最后得到一個計算機能理解的特征,
就是隱向量的一般含義。
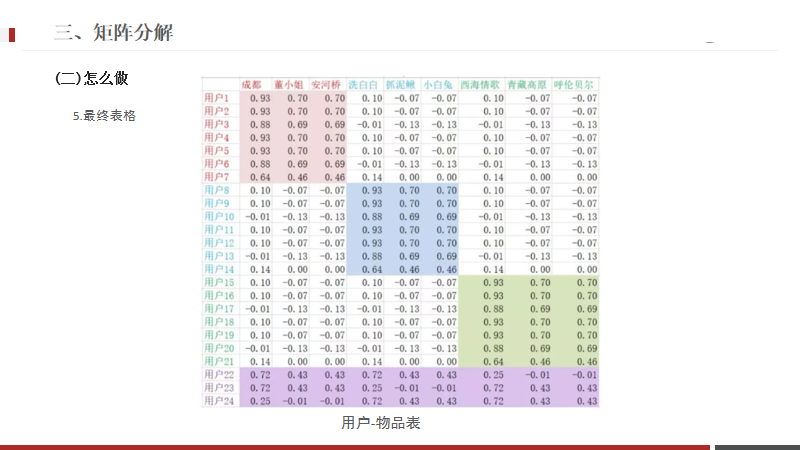
這是最終的表格
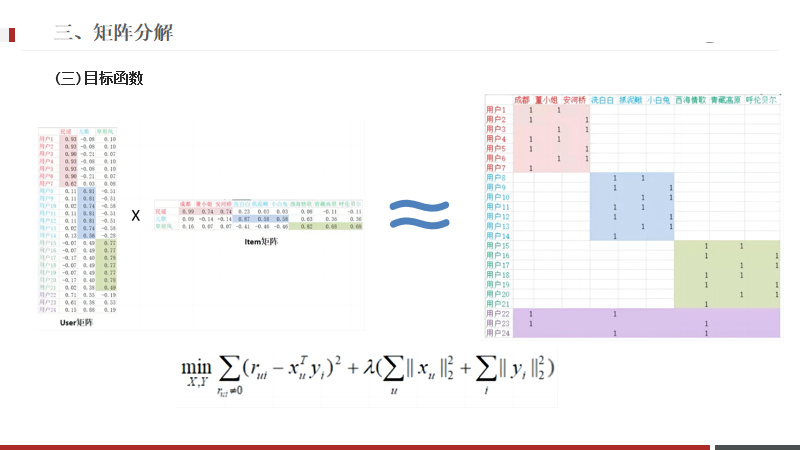
使用矩陣分解,希望還原后的矩陣,和原來是越相似越好。
rui 相當于原來的大矩陣,xy就是分解出來的兩個小矩陣,希望他們之間的差異越來越小。

默認為1,rui當前的指標,比如點擊次數,阿爾法相當于是系數,就是權重的設置。
行為越多,置信度的值會越來越大。
置信度的值越大,表示預測的越準確。
需要PPT的私聊







 97. 交錯字符串(動態規劃))

)
:Python Imaging Library(PIL)庫:圖像讀取、寫入、復制、粘貼、幾何變換、圖像增強、圖像濾波)








