本文整理自阿里云智能開源表存儲負責人,Founder of Paimon,Flink PMC 成員李勁松在云棲大會開源大數據專場的分享。本篇內容主要分為四部分:
- 數據分析架構演進
- 介紹 Apache Paimon
- Flink + Paimon 流式湖倉
- 流式湖倉Demo演示
數據分析架構演進
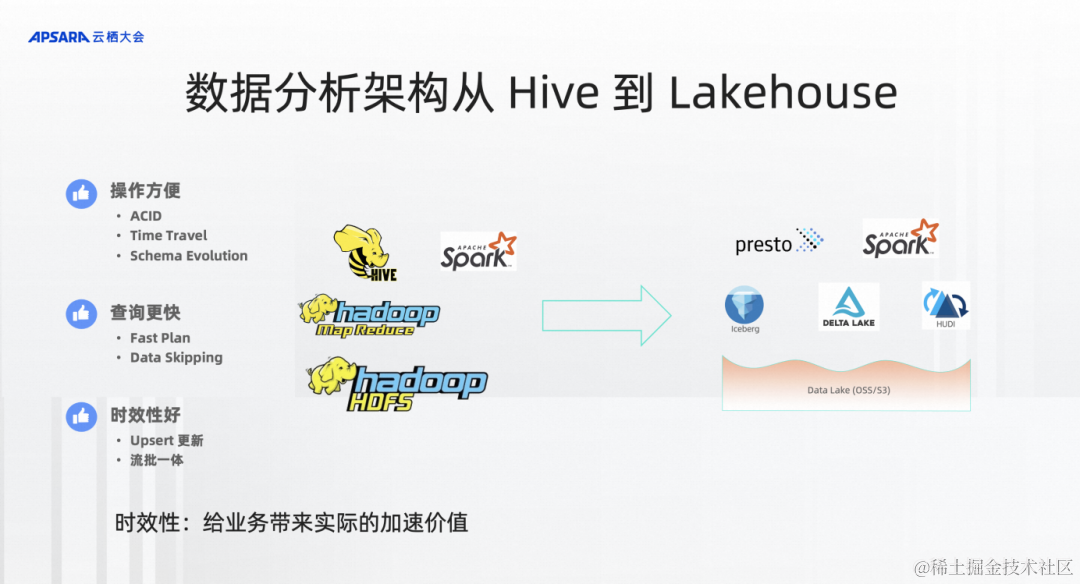
目前,數據分析架構正在從Hive到Lakehouse的演變。傳統數倉包括Hive、Hadoop正在往湖、Lakehouse 架構上演進,Lakehouse 架構包括Presto、Spark、OSS,湖格式?(Delta、Hudi、Iceberg)?等等架構,這是現在比較大的趨勢。Lakehouse 架構包含了諸多新能力。
首先OSS比起傳統的HDFS有了更加彈性、更加計算存儲分離的能力。而且OSS還有熱冷存儲分離能力,數據可以歸檔到冷存,你會發現它的冷存儲非常便宜,給了你存儲的靈活性。
再往上會發現這些湖格式有著一些好處。具體是哪些好處呢?
第一點操作方便,湖格式有ACID、Time Travel、Schema Evolution,這些可以讓你有更好的管控能力。
第二個可能查詢更快,比如說plan階段會耗時更短,Hive在超大數據量、超多文件的時候會有一些查詢的問題。所以湖格式在這方面也會解決得更好。
上面的兩個好處不一定能打動公司的決策人,其實也不是每家公司都在升級或者都已經升級,其中一個大的原因就是大家雖然說Hive老了,但它還是能再戰一戰的,因為前面這兩個好處不一定對于每家公司都是剛需。大量的公司都還是繼續用Hive,也許底下的存儲換成OSS (或者OSS-HDFS)?,但還是老的Hive那套。
舉例來說,現在已經有了運行穩定的火車,現在可以把它升級一下,增加餐車,裝潢一遍,切分成更多節更靈活,但是需要升級為新的一套架構,你愿意冒著風險升級嗎?但是如果能升級成高鐵動車呢?
所以我要介紹左邊第三個好處。Lakehouse可以做到時效性更好。
時效性更好不一定是所有業務都需要更好的時效性,都要從天到達分鐘級,而是你可以選擇其中某些數據進行實時化升級,還可以選擇某些時間進行實時化,主流數據仍然是離線狀態。
時效性更好可能會給你的一些業務帶來真正的改變,甚至說對于你的架構能帶來大幅的簡化,讓整個數倉更穩定。

時效性在計算領域的領頭羊是Apache Flink。剛才說提升時效性是Lakehouse下一步的發展重點,現在要做的就是把Streaming計算標準技術也就是Apache Flink帶到Lakehouse架構當中。
所以前幾年我們也做有很多相關的探索,包括在Iceberg和Hudi上的投入,都成功地把Flink和Iceberg的對接、和Hudi的對接打磨出來。但是可能打磨得效果也沒有那么好,如果大家用過Flink + Iceberg或者Flink + Hudi可能也有一些吐槽。關鍵問題在于,Iceberg 和 Hudi 都是面向 Spark、面向離線而生的數據湖技術,與實時和 Flink 有著不太好的匹配。
所以我們研發了新型數據湖格式 Apache Paimon,它是一個流式數據湖格式。我們分析一下數據湖四劍客有什么樣的歷史和初衷。

Apache Iceberg 和 Delta Lake,他們其實是對傳統Hive格式的一種升級。本質上還是面向Append數據的處理,在離線數倉T+1的分析上比起Hive更有優勢和更方便的使用,更多還是面向傳統的離線處理。
Apache Hudi其實是在Hive的基礎上提供增量更新的能力,這是它的初衷。它的基礎架構還是面向全增量合并的方式,Flink 的集成不如 Spark,一些功能只在Spark有,Flink沒有。
Apache Paimon是從Flink社區中孵化出來的,面向流設計的數據湖,目的就是支持大規模更新和真正的流讀。
流和湖的結合難點其實在更新。如果大家對Flink比較熟悉,Flink SQL 成功的原因之一是它真正對Changelog做出了原生的處理,這個changelog本身就是一種更新。
Iceberg、Hudi、Delta是因為他們都是面向批處理、Spark的增量?+?全量的方式。一旦需要涉及到合并就是增量數據和全量數據的一次超大合并。相當有全量10 TB,增量哪怕1 GB也可能會涉及到所有文件的合并,這10個TB的數據要全部重寫一次,然后合并才算完成,合并的代價非常大。
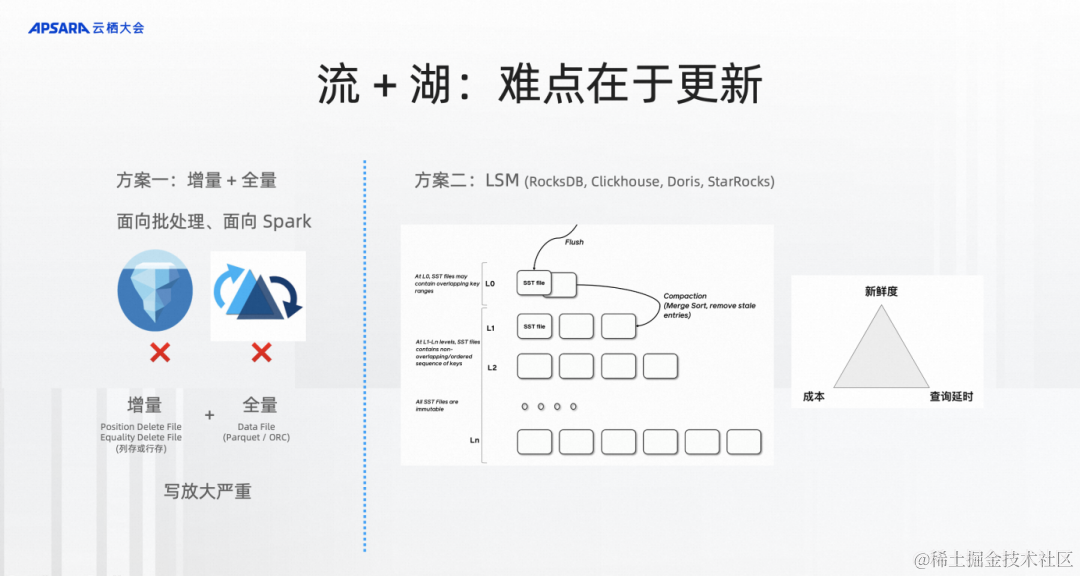
右邊是面向更新的技術,LSM,全名是Log Structured Merge-Tree,這種格式在實時領域已經被大量的各種數據庫應用起來,包括 RocksDB、Clickhouse、Doris、StarRocks 等等。
LSM帶來的變化是每次合并都可能是局部的。每次合并只用按照一定的策略來merge數據即可,這種格式能真正在成本、新鮮度和查詢延時的三角trade-off中可以做到更強,而且在三角當中可以根據不同的參數做不一樣的trade-off的選擇。
介紹 Apache Paimon
我們剛剛介紹了演進的過程,需要Flink +?湖存儲來做Flink Lakehouse,也介紹了難點。第二部分就介紹一下Apache Paimon。

Apache Paimon是什么樣的東西?你可以簡單認為基礎的架構就是湖存儲+ LSM的結合,對于湖存儲來說基本的能力是寫和讀。Apache Paimon在這個基礎上和Flink做了更深度的集成,各種 CDC 數據可以通過Flink CDC做到 Schema Evolution 和整庫同步地把數據同步到Paimon中。
也可以通過Flink、Spark、Hive、寬表合并的方式或者通過批寫覆蓋的方式寫到Paimon中,這是基本的 Lakehouse能力。也可以在后面批讀,通過Flink、Spark、StrarRocks、Trino做一些分析,也可以這里通過Flink來流讀Paimon里面的數據,流讀生成的 Changelog,流讀方面的特性,后面我也會介紹。

這是Paimon的架構圖,這主要是Paimon流式一體實時數據湖大致的發展歷程。最開始在2022年初發現了開源社區技術上的一塊缺失,所以在Flink社區提出了Flink Table Store。直到2023年1月發布了第一個穩定的版本0.3,3月份進入Apache孵化器。今年9月份發布了Paimon 0.5版本,這是Paimon全面成熟的版本,包括CDC入湖和Append數據處理。
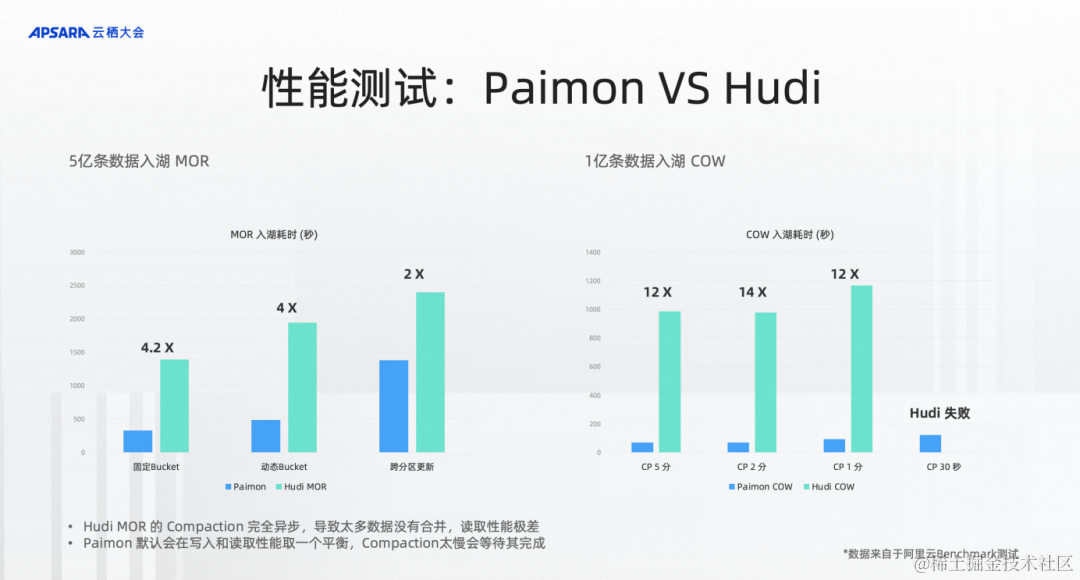
我們也在阿里云上測試Apache Paimon和Hudi的性能,測試湖存儲的 MergeOnRead 的更新性能,可以看到左邊是大致是5億條數據入湖,按照類似的配置、相同的索引來入湖,我們來評估5億條入湖需要多少時間。經過測試發現Paimon入湖的過程中,吞吐或者耗時能達到Hudi的4倍,但是查詢相同的數據,發現Paimon的查詢性能是Hudi的10倍甚至20倍,Hudi 還會碰到因內存變小而無法讀取的情況。
為什么呢?我們分析到,Hudi MOR是純Append,雖然后臺有compaction,但是完全不等Compaction。所以在測試中Hudi的Compaction只做了一點點,讀取的時候性能特別差。
基于這點,我們也做了右邊的benchmark,就是1億條數據的CopyOnWrite,來測試合并性能,測試CopyOnWrite情況下的 compaction 性能。測試的結果是發現不管是2分鐘、1分鐘還是30秒,Paimon性能都是大幅領先的,是12倍的性能差距。在30秒的時候,Hudi跑不出來,Paimon還是能比較正常地跑出來。

所以回過頭來,我希望通過這三句話的關鍵詞來描述Paimon能做到什么。
第一,低延時、低成本的流式數據湖。如果你有用過Hudi,我們希望你替換到Paimon之后以1/3的資源來運行它。
第二,使用簡單、入湖簡單、開發效率高。可以輕松地把數據庫的數據以CDC的方式同步到數據湖Paimon中。
與Flink集成強大,數據流起來。
Flink + Paimon 流式湖倉
第一部分講了數據架構演進,就是我們為什么要做Paimon,第二部分介紹Paimon能干什么,有哪些集成、優勢,性能上表現如何。接下來第三部分就是Flink + Paimon怎么構建流式湖倉。
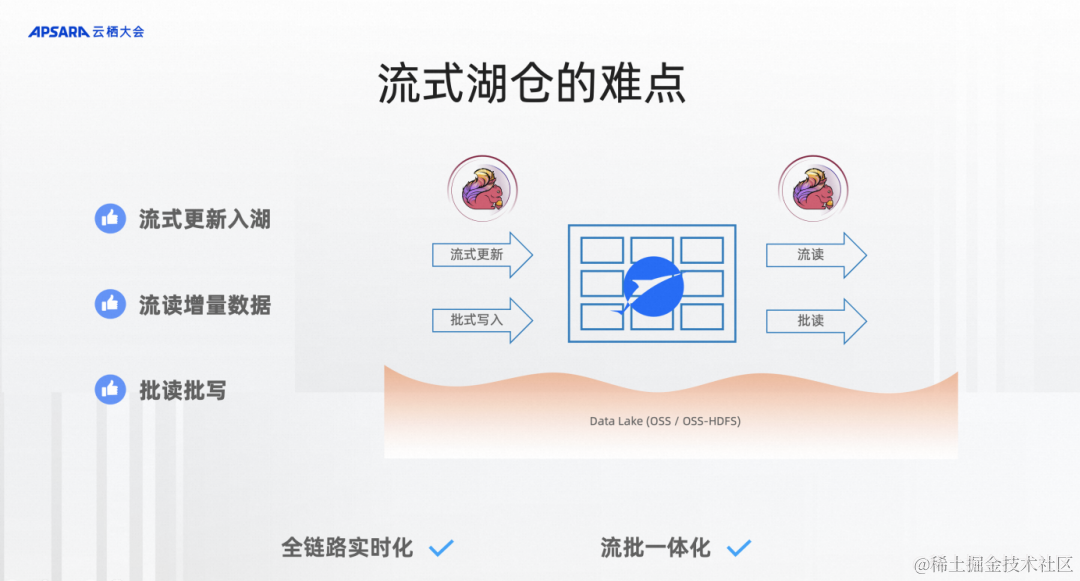
首先我們看一個大致的圖,其實流式湖倉本質還是一個湖倉,湖倉能干什么?最基本的就是批寫、批讀,能比起傳統的Hive數倉有更好的優勢。在這個基礎上要提供一個強大的流式數據更新入湖以及流式數據增量數據的流讀,達到全鏈路的實時化、流批一體化,難點就是流式更新和流讀。
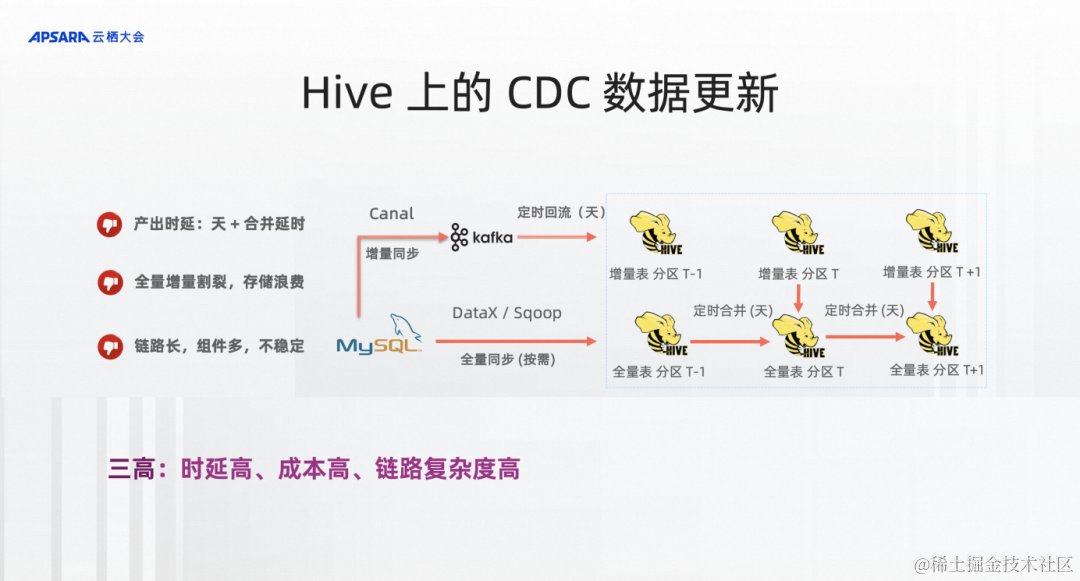
一個最典型的流式湖倉能解決的場景,Hive上CDC數據,也就是從MySQL、傳統數據庫的數據、CDC數據能流到倉或者湖中的鏈路。這是一個比較陳舊,但是也是大量在企業中被應用的架構圖。
你可能在第一次運行的時候或者按需通過全量同步的方式同步到Hive全量分區表中,成為一個分區。接下來每天要通過增量同步的方式同步到kafka中,通過定時回流的方式把增量的CDC數據同步成Hive中的一個增量表。每天晚上同步完后,大概0點10分的時候就可以做一個增量表和全量表的合并,合并之后形成新的分區就是MySQL新一天的全量。
通過這樣的技術可以看到它的產出時延是非常高的,至少需要T+1,并且還要等增量數據和全量數據合并。而且全量增量是割裂的,存儲也非常浪費。你可以看到Hive全量表每個分區就是一個全量的數據,你要存100天的數據就至少是100倍的存儲。
第三也是鏈路非常長,非常復雜,涉及到各種各樣好幾個技術,在真實的業務場景中非常容易遇到的就是這個產出,哪個組件有問題,數據產出不了,導致后面一系列的離線作業跑不了。所以這里描述的就是三高,時延高、成本高、鏈路復雜度高。
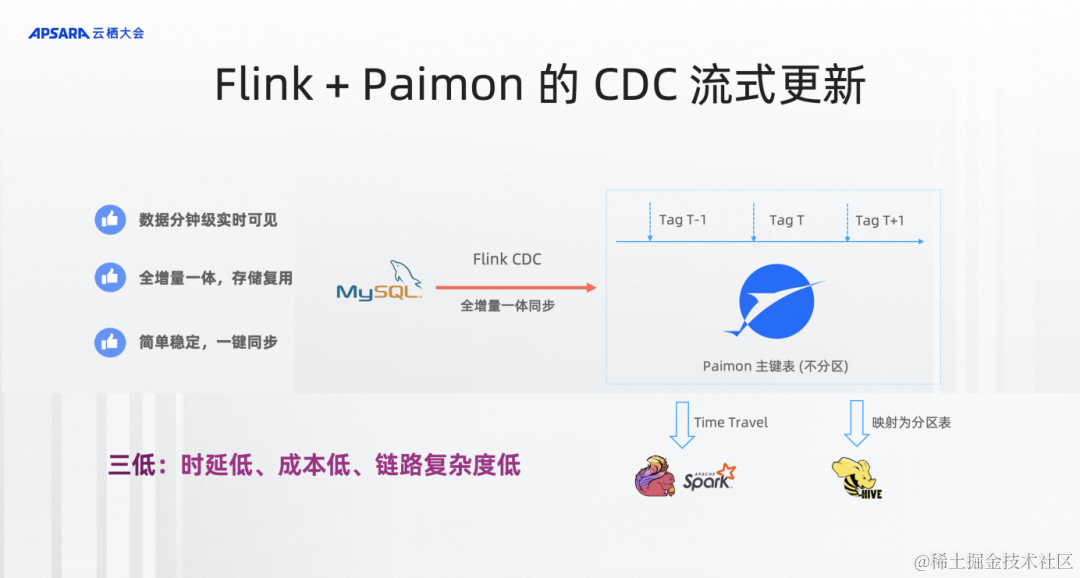
切到Flink+Paimon的流式CDC更新,我們希望把架構做得非常簡單,不用Hive的分區表,只要定義Paimon的主鍵表,不分區。它的定義就非常像MySQL表的定義。
通過Flink CDC、Flink作業把CDC數據全增量一體到Paimon中就夠了,就可以實時看到這張表的狀態,并且實時地查到這張表。數據被實時的同步,但是離線數倉是需要每天的view,Paimon要提供Tag技術。今天打了一個Tag就記住了今天的狀態,每次讀到這個Tag都是相同的數據,這個狀態是不可變的。所以通過Tag技術能等同取代Hive全量表分區的作用,Flink、Spark可以通過Time Travel的語法訪問到Tag的數據。
傳統的Hive表那是分區表,Hive SQL也沒有Time Travel的語義,怎么辦?在Paimon中也提供了Tag映射成Hive分區表的能力,還是可以在Hive SQL中通過分區查詢,查詢多天的數據。Hive SQL是完全兼容一行不改的狀態來查詢到Paimon的組件表,所以經過這樣的架構改造之后,你可以看到整個數據分鐘級實時可見,各整個全增量一體化,存儲是復用,比較簡單穩定而且一鍵同步,這里不管是存儲成本還是計算成本都可以大幅降低。
存儲成本通過Paimon的文件復用機制,你會發現打十天的Tag其實存儲成本只有一兩天的全量成本,所以保留100天的分區,最后存儲成本可以達到50倍的節省。
在計算成本上雖然需要維護24小時都在跑的流作業,但是你可以通過Paimon的異步compaction的方式,盡可能地縮小同步的資源消耗,甚至Paimon也提供整庫同步的類似功能給到你,可以通過一個作業同步上百張或者幾百張表。所以整個鏈路能做到三低:時延低、成本低和鏈路復雜度低。
接下來介紹兩個流讀。大家可能覺得Paimon是為實時而生的,更好地流讀,其實沒有什么實感。包括Hudi、Iceberg也能流讀,我在這里通過兩個機制來說明Paimon在數據流讀上做了大量的工作。
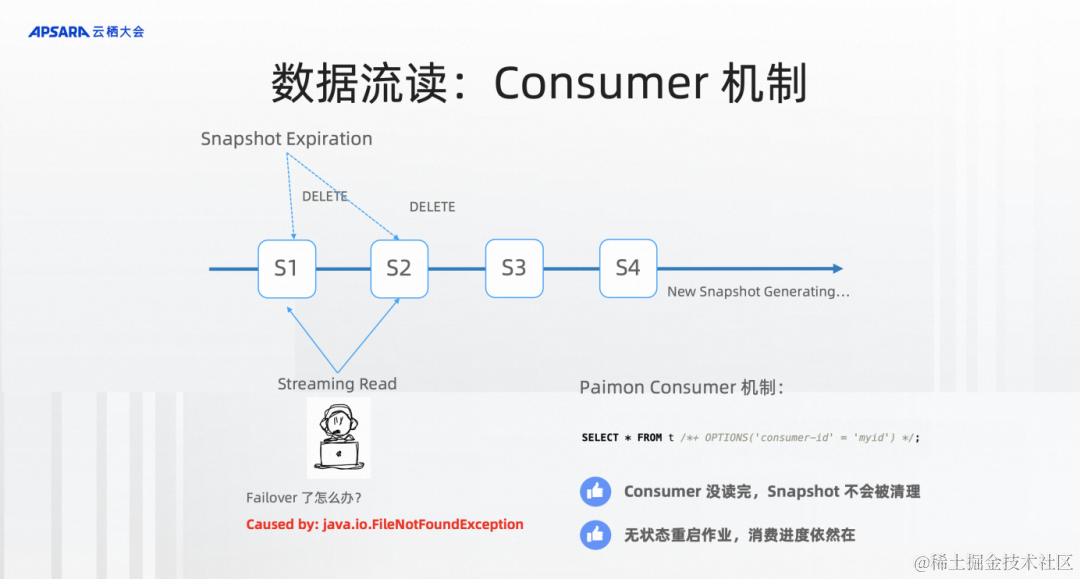
Consumer機制。如果沒有這個能力,經常流讀的時候碰到非常頭疼的東西就是FileNotFoundException,這個機制是什么樣的呢?因為我們在數據產出過程當中,需要不斷地產生Snapshot。太多的Snapshot會導致大量的文件、導致數據存儲非常地冗余,所以需要有Snapshot的清理機制。但是另外流讀的作業可不知道這些,萬一我正在流讀的Snapshot被Snapshot Expiration給刪了,那不就會出現FileNotFoundException,怎么辦?而且更為嚴重的是,流讀作業可能會failover,萬一它掛了2個小時,重新恢復后,它正在流讀的 snapshot 已經被刪除了,再也恢復不了。
所以Paimon在這里提出了consumer機制。consumer機制就是在Paimon里用了這個機制之后,會在文件系統中記一個進度,當我再讀這個Snapshot,Expiration就不會刪這個Snapshot,它能保證這個流讀的安全,也能做到像類似 kafka group id 流讀進度的保存。重啟一個作業無狀態恢復還是這個進度。所以consumer機制可以說是流讀的基本機制。
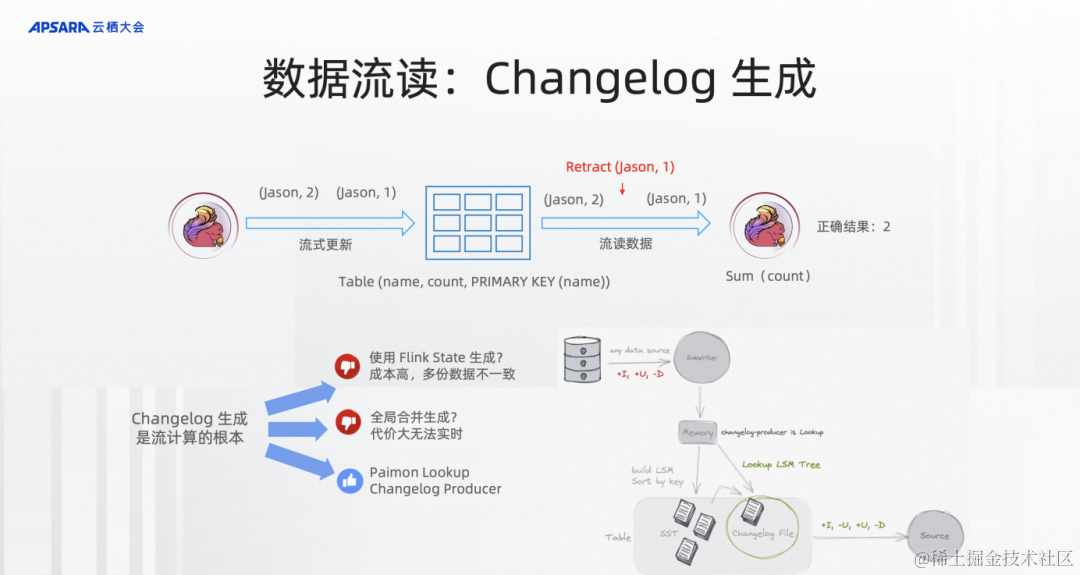
第二,Changelog生成。假設有這樣一張Paimon的PK表,key是名字,Value是count,上游在不斷地流寫,下游在不斷地流讀。流寫可能會同一個組件寫相同的數據,比如說先前寫的jason是1,后面又寫一個jason是2。你會發現流讀的作業在做一個正確流處理的時候,比如說做一個sum,sum結果應該是2還是3,如果沒有這個changelog的生成就不知道這是同一個主鍵,我要先把jason -> 1給retract掉,再寫jason -> 2。所以這里也對我們湖存儲本身要表現得像一個數據庫生成binlog的方式,下游的流讀計算才能更好、更準確。
changelog生成有哪些技術呢?在Flink實時流計算中,大家如果寫過作業的話,也可能寫過大量用State的方式來去重。但是這樣的方式state的成本比較高,而且數據會存儲多份,一致性也很難保障。或者你可以通過全量合并的方式,比如說Delta、Hudi、Paimon都提供了這樣的方式,可以在全量合并的時候生成對應的changelog,這個可以,但是每次生成changelog都需要全量合并,這個代價也會非常大。
第三,Paimon這邊獨有的方式,它有chagelog-producer=lookup,因為它是LSM。LSM是有點查的能力,所以你可以配置這樣一個點查的方式在寫入的時候能通過批量高效率的點查生成對應的chanelog讓下游的流處理能夠正確地流處理。
上面兩個部分就是Paimon的更新和流讀。流式湖倉面向流批一體的Flink的流批一體。之前是流批一體的計算,現在有了存儲以后是流批一體的計算?+?流批一體的存儲。
但是,有同學在用阿里云 Serverless Flink發現沒有批的基本能力:調度和工作流?
流式湖倉不僅要解決流的能力,還需要解決批的離線處理能力,批是湖倉的基礎,流只是在這個流式湖倉中真正的流可能只有10%、20%,并不是整個湖倉的全部。所以Flink的流批一體離不開Flink的真正批處理。
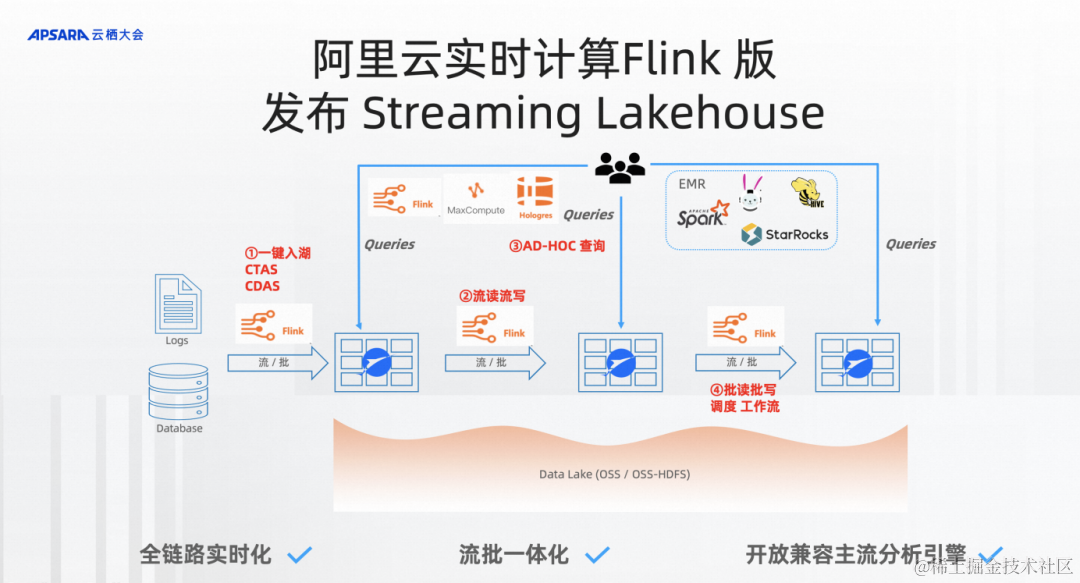
大家也可以看到流式湖倉的圖里,可能需要4個步驟來處理數據。
第一步是一鍵入湖,通過Flink CTAS/CDAS一鍵入湖。
第二步里面Pipeline全鏈路實時化是流起來的,所以需要我對存儲有流讀流寫的能力。
第三步就是這些數據全都是可以通過開放分析引擎來分析到數據。
第四步就是湖倉本質的東西批讀批寫,在產品上需要的東西基本上就是調度、工作流。
大家期待已久,阿里云 Serverless Flink也正式迎來了產品上的調度和工作流的能力,能讓你在Serverless Flink達到真正的完整批處理鏈路的能力。
接下來我就想通過一個準實時流式湖倉的案例,是電商的數據分析。通過Flink實時入湖入到ODS層Paimon表,通過流式流起來流到DWD,再流到DWM,再到DWS,這樣一整套完整的流式湖倉。
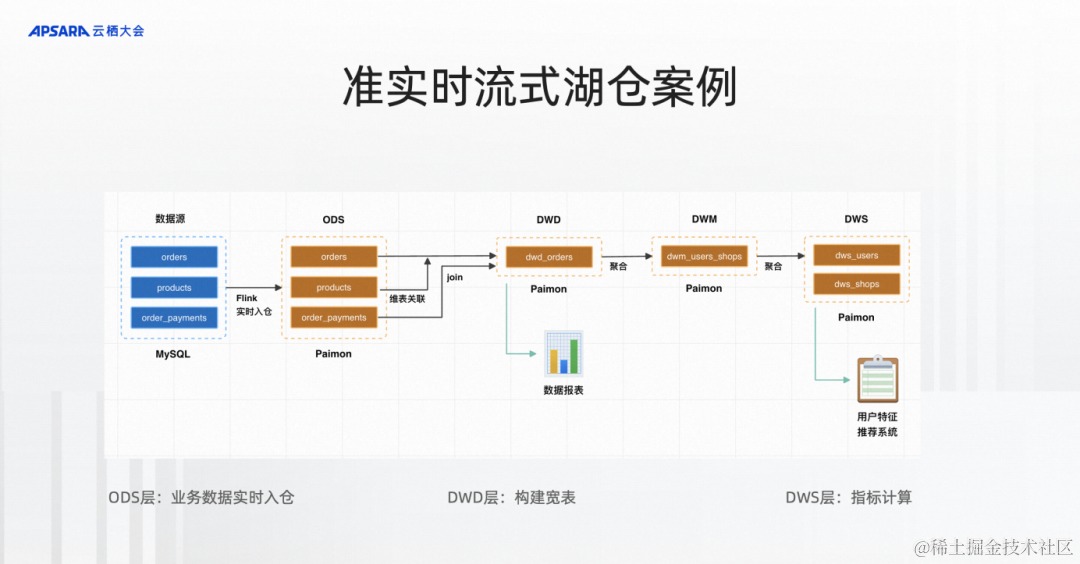
流式湖倉Demo演示
Demo演示觀看地址:
https://yunqi.aliyun.com/2023/subforum/YQ-Club-0044
開源大數據專場回放視頻?01:52:42?-?01:59:00?時間段
Serverless Flink不只有流ETL的能力,現在也有一個比較完善的批處理方式,以前可能是流在一個開發平臺,批在一個開發平臺,非常地割裂,現在能做到的是整個開發平臺都可以在Serverless Flink上,整個計算引擎可以是 Flink Unified的,而且底下的存儲都是Unified的一套Paimon存儲,完成離線處理以及實時處理或者準實時處理的能力,能達到從開發到計算和存儲的完整Unified方案。批處理的版本即將發布,大家有需要可以聯系我們提前試用。




![【Sorted Set】Redis常用數據類型: ZSet [使用手冊]](http://pic.xiahunao.cn/【Sorted Set】Redis常用數據類型: ZSet [使用手冊])



)

-uniclould增刪改查業務開發)








