簡介
? ? ? ?作為數據庫管理員(DBA),定期進行數據庫的日常巡檢是非常重要的。以下是一些原因:
? ? ? ? 保證系統的穩定性:通過定期巡檢,DBA可以發現并及時解決可能導致系統不穩定的問題,如性能瓶頸、資源利用率過高或磁盤空間不足等。
? ? ? ? 提高數據的安全性:巡檢可以幫助DBA發現潛在的安全風險,例如未經授權的訪問、數據泄露或其他安全漏洞。及時采取措施,可以防止這些風險演變成實際問題。
? ? ? ? 避免數據丟失:DBA可以通過檢查備份和恢復策略來確保數據的完整性,并確保在發生災難時能夠快速恢復業務運營。
? ? ? ? 確保合規性:許多行業都有特定的數據管理規定和法規要求。通過巡檢,DBA可以確保他們的數據庫管理系統符合這些規定和要求。
? ? ? ? 性能優化:巡檢可以幫助DBA識別性能瓶頸,從而優化數據庫以提高其效率和響應速度。
? ? ? ? 資源規劃:通過巡檢,DBA可以了解當前的資源使用情況,預測未來的資源需求,并根據需要調整資源配置。
? ? ? ? 綜上所述,DBA的日常巡檢是保持數據庫健康運行的關鍵環節之一,也是確保業務連續性和高效運行的重要步驟。
28、查看閃回區\快速恢復區空間使用率
select sum(percent_space_used) || '%' "已使用空間比例"from V$RECOVERY_AREA_USAGE
一、閃回區(Flashback Area):
????????閃回區是一個由 Oracle 數據庫管理的特殊區域,用于存儲數據庫中的舊數據和相關的元數據。它可以被用于執行閃回查詢(Flashback Query)和閃回版本查詢(Flashback Version Query),從而可以按時間點恢復數據庫對象的舊版本或檢索已刪除或修改的數據。閃回區是通過配置 DB_FLASHBACK_RETENTION_TARGET 參數來控制保留的時間范圍。通常情況下,它的大小是自動管理的,它會根據需要自動增長或縮小。
二、快速恢復區(Fast Recovery Area):
????????快速恢復區是一個用于存儲備份、恢復和日志文件的目錄。它是為了簡化數據庫備份和恢復操作而引入的一個特殊目錄。通過配置 DB_RECOVERY_FILE_DEST 參數指定快速恢復區的位置。在數據庫運行期間,數據庫會自動將備份和歸檔日志文件保存在快速恢復區中。快速恢復區還會自動管理和清理過期的備份和日志文件,以避免占用過多的磁盤空間。
29、查看僵死進程,分兩種
alter system kill session一執行則session即標記為KILLED,但是如果會話產生的數據量大則這個kill可能會比較久,在這個過程中session標記為KILLED但是這個會話還在V$session中,則V$session.paddr還在,所以可以匹配到V$process.addr,所以process進程還在;當kill過程執行完畢,則這個會話即不在V$session中
????????會話不在的
select * from v$process where addr not in (select paddr from v$session) and pid not in (1,17,18)????????會話還在的,但是會話標記為killed
?
select * from v$process where addr in (select paddr from v$session where status='KILLED')再根據上述結果中的SPID通過如下命令可以查看到process的啟動時間
ps auxw|head -1;ps auxw|grep SPID
這些進程的 PID(Process ID)通常是固定的:
- PID 1 通常是 PMON(Process Monitor)進程,它負責清理失敗的用戶進程,釋放它們占用的資源。
- PID 17 通常是 QMN0(Queue Monitor)進程,它負責處理 Oracle 的隊列消息。
- PID 18 通常是 LCK0(Lock)進程,它負責處理分布式鎖。
這些背景進程是 Oracle 數據庫正常運行所必需的,它們不會關聯到任何用戶會話,所以在 v$session 視圖中沒有對應的行。
30、查看行遷移或行鏈接的表
select * From dba_tables where nvl(chain_cnt,0)<>0????????chain_cnt:表中從一個數據塊鏈接到另一個數據塊或已遷移到新塊的行數,需要鏈接以保留舊的 rowid。此列僅在分析表后更新。
31、數據緩沖區命中率
一、
SELECT a.VALUE+b.VALUE logical_reads, c.VALUE phys_reads,
round(100*(1-c.value/(a.value+b.value)),2)||'%' hit_ratio
FROM v$sysstat a,v$sysstat b,v$sysstat c
WHERE a.NAME='db block gets'
AND b.NAME='consistent gets'
AND c.NAME='physical reads';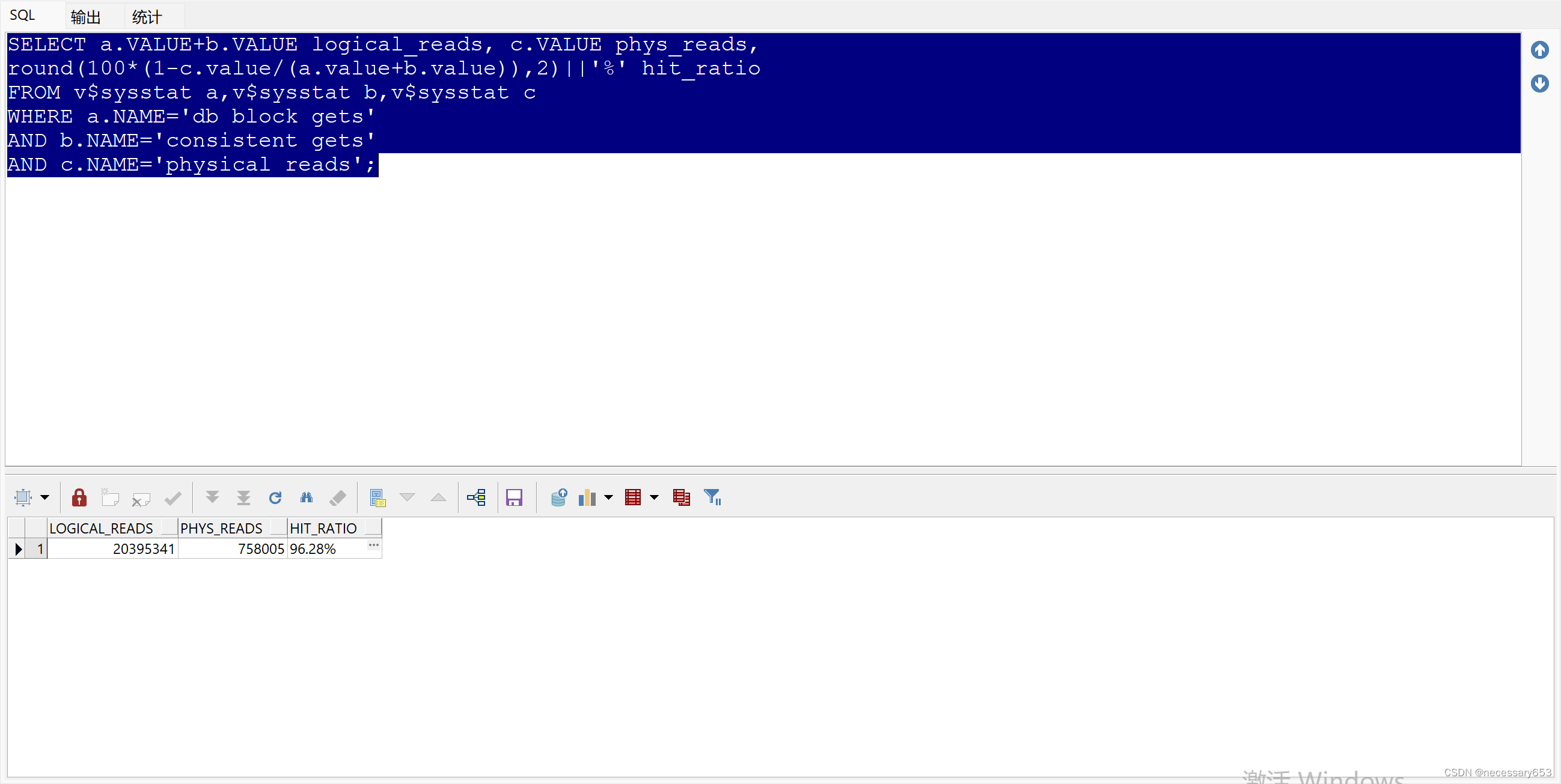
????????用于獲取數據庫中邏輯讀和物理讀的統計信息,并計算命中率?? ?
????????a.VALUE+b.VALUE logical_reads: 這一部分從v$sysstat表中選擇a.VALUE和b.VALUE,并將它們相加,表示邏輯讀的總數。邏輯讀是指數據庫在處理查詢時,從內存中的數據塊獲取信息,而不是從磁盤讀取。
?? ?c.VALUE phys_reads: 這一部分從v$sysstat表中選擇c.VALUE,表示物理讀的總數。物理讀是指數據庫在處理查詢時,從磁盤讀取數據塊。
?? ?round(100*(1-c.value/(a.value+b.value)),2)||'%' hit_ratio: 這一部分計算了命中率,并將其四舍五入到小數點后兩位。命中率是衡量數據庫查詢在內存中成功找到所需數據塊的比例。公式為:命中率 = (1 - (物理讀數 / (邏輯讀數 + 物理讀數))) * 100%。
????????邏輯讀和物理讀的次數。
命中率,這是一個重要的性能指標,可以衡量數據庫在內存中成功找到所需數據塊的比例。如果命中率接近100%,則說明數據庫查詢大部分時間在內存中查找所需數據,而不是從磁盤讀取。這通常是一個積極的跡象,表明數據庫的性能良好。如果命中率較低,則可能需要分析原因并進行優化,例如增加內存、優化數據庫結構或查詢語句等。
二、
SELECT DB_BLOCK_GETS + CONSISTENT_GETS Logical_reads,PHYSICAL_READS phys_reads,round(100 *(1 - (PHYSICAL_READS / (DB_BLOCK_GETS + CONSISTENT_GETS))),2) || '%' "Hit Ratio"FROM V$BUFFER_POOL_STATISTICSWHERE NAME = 'DEFAULT';
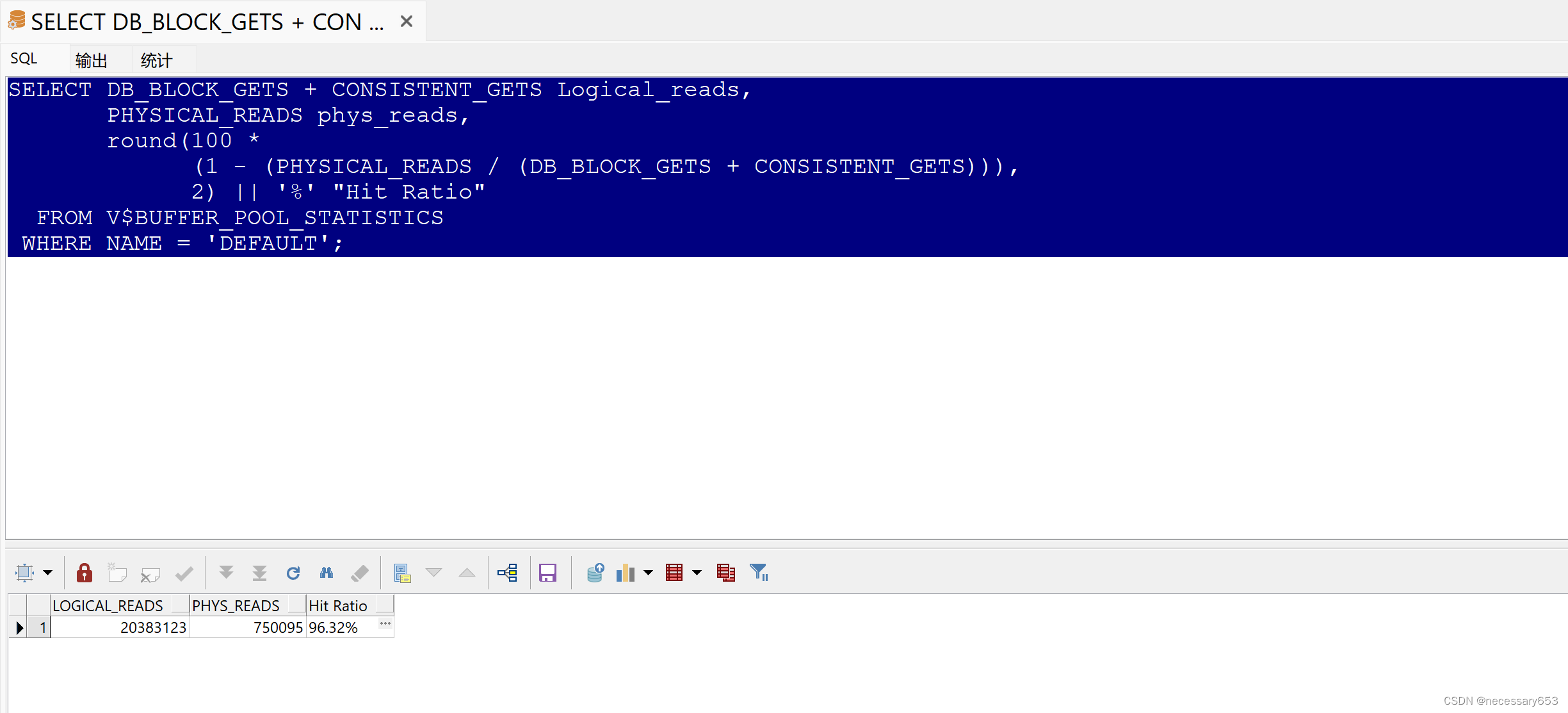
????????在Oracle數據庫中查詢關于緩沖池的統計信息。緩沖池是數據庫中存儲數據塊的地方,這些數據塊包含數據庫中的數據和相關的索引。這個查詢返回了關于緩沖池的三個主要信息:邏輯讀、物理讀以及命中率。
?? ?DB_BLOCK_GETS:這是從數據庫緩沖池獲取數據塊的邏輯操作。當數據庫需要訪問某個數據塊,但該數據塊不在緩沖池中時,就會發生這種操作。
?? ?CONSISTENT_GETS:這是一致性讀獲取的次數。一致性讀是當數據庫需要讀取一個數據塊,但該數據塊在內存中已被其他會話修改過,此時就需要從磁盤讀取這個數據塊,并把這個操作稱為一致性讀。
?? ?LOGICAL_READS:這是上述兩個操作的累加和,表示從數據庫緩沖池獲取數據塊的邏輯操作的總數。
?? ?PHYSICAL_READS:這是從磁盤讀取數據塊的物理操作的總數。當數據塊在內存中找不到,需要從磁盤讀取時,就會發生這種操作。
?? ?Hit Ratio:這是命中率,它表示了內存(緩沖池)中訪問數據塊的效率。命中率越高,表示大部分數據訪問都在內存中完成,不需要從磁盤讀取,這通常是數據庫性能良好的標志。
如果邏輯讀和物理讀的次數非常高,那么可能需要對數據庫進行優化,比如增加內存、調整數據庫的參數等。同時,命中率的計算也可以幫助了解內存的使用效率,如果命中率很低,那么可能需要增加內存或者調整數據庫的結構和查詢語句等來提高性能。
32、共享池命中率
select sum(pinhits)/sum(pins)*100 from v$librarycache;
--兩者語句均可實現
select sum(pinhits-reloads)/sum(pins)*100 from v$librarycache;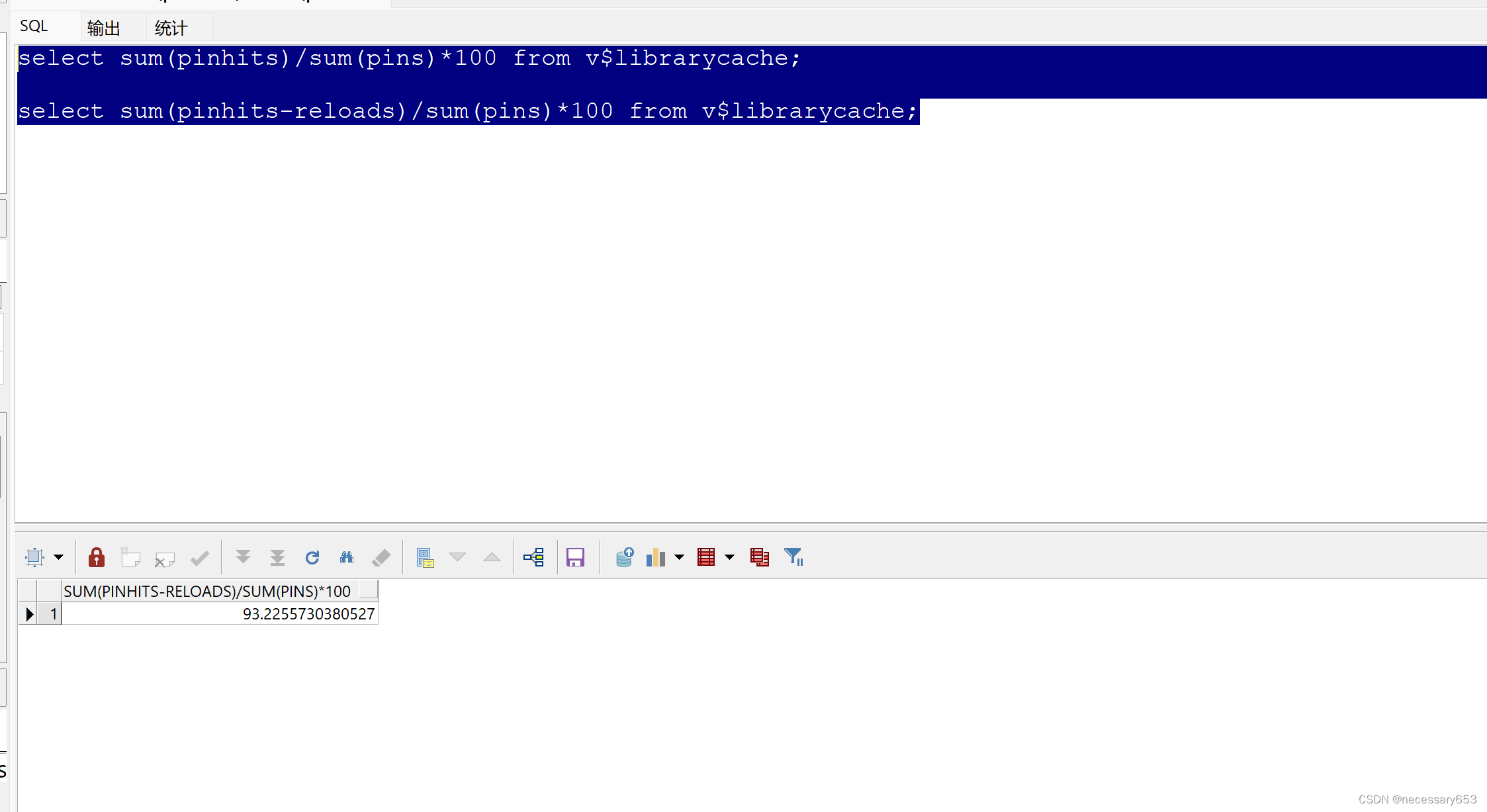
33、查詢歸檔日志切換頻率
一、
select sequence#,to_char(first_time, 'yyyymmdd_hh24:mi:ss') firsttime,round((first_time - lag(first_time) over(order by first_time)) * 24 * 60,2) minutesfrom v$log_historywhere first_time > sysdate - 3order by first_time, minutes;
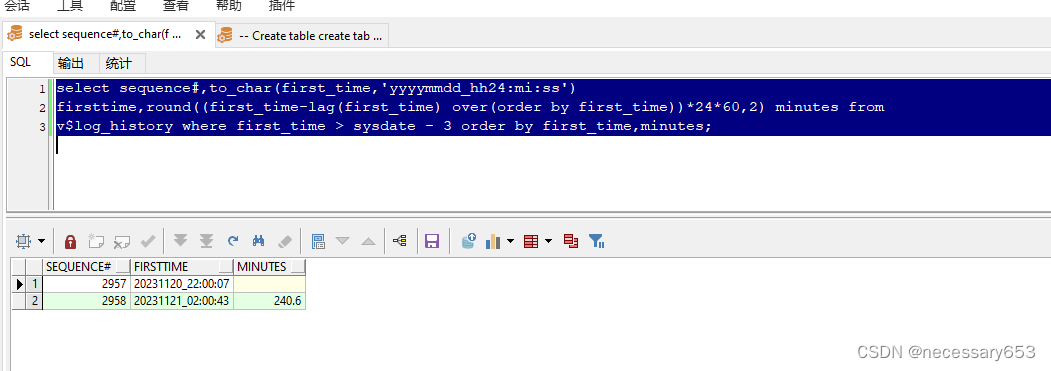
????????sequence#:這是該記錄在 v$log_history 中的序列號。
????????to_char(first_time, 'yyyymmdd_hh24:mi:ss') firsttime:這將 first_time 字段轉換為字符串,格式為 '年月日_時:分:秒',并將其命名為 firsttime。
????????round((first_time - lag(first_time) over(order by first_time)) * 24 * 60, 2) minutes:這部分比較復雜。它首先使用 lag() 函數獲取前一條記錄的 first_time 值,然后計算當前記錄的 first_time 與前一條記錄的 first_time 的時間差(以分鐘為單位),并將這個時間差乘以 24(因為每小時有 24 分鐘)再乘以 60(因為每小時有 60 分鐘),從而得到時間差(以小時為單位),最后四舍五入到小數點后兩位,并將結果命名為 minutes。
????????這個查詢從 v$log_history 視圖中獲取了過去三天內的記錄,并顯示了每條記錄的序列號、時間戳以及與前一條記錄的時間差(以小時為單位)。這樣的信息可以用來分析數據庫的重做日志活動,例如找出何時進行了大量的重做操作或者何時日志活動最為頻繁等。
?二、
select sequence#,to_char(first_time, 'yyyy-mm-dd hh24:mi:ss') First_time,First_change#,switch_change#from v$loghistwhere first_time > sysdate - 3order by 1;
????????從Oracle數據庫的v$loghist視圖中查詢數據。下面我會解釋每個字段的含義:
????????sequence#: 這是在v$loghist中的記錄序列號,可以看作是每條記錄的唯一標識。
????????to_char(first_time, 'yyyy-mm-dd hh24:mi:ss') First_time: 這條是將first_time字段轉換為字符串格式,顯示為'年-月-日 時:分:秒',并將這個列命名為First_time。
????????First_change#: 這個字段的含義可能會因數據庫的上下文而異,一般來說,可能表示首次更改的序號或ID。
????????switch_change#: 這個字段的含義也可能因數據庫的上下文而異,可能表示切換更改的序號或ID。
主要用于分析在過去的三天內數據庫的重做日志歷史記錄。?
?
?34、查詢lgwr進程寫日志時每執行一次lgwr需要多少秒,
????????在state是waiting的情況下,某個等待編號seq#下,seconds_in_wait達多少秒,就是lgwr進程寫一次IO需要多少秒
?
select event, state, seq#, seconds_in_wait, programfrom v$sessionwhere program like '%LGWR%'and state = 'WAITING'
????????event: 這個字段表示會話當前正在等待的事件。例如,它可能正在等待一個鎖,或者正在等待數據庫響應等。
????????state: 這個字段表示會話的狀態。在這個查詢中,我們只選取了狀態為'WAITING'的會話,也就是正在等待的會話。
????????seq#: 這個字段表示會話在Oracle實例中的序列號。
????????seconds_in_wait: 這個字段表示會話在等待中已經等待的秒數。
????????program: 這個字段表示會話正在運行的程序。在這個查詢中,我們只選取了程序名包含'LGWR'的會話,也就是正在運行的程序包含'LGWR'的會話。
????????這個查詢的結果集將包含所有滿足以下條件的會話的信息:程序名包含'LGWR',并且正在等待。這些信息可以幫助確定哪些會話正在等待,以及它們等待了多長時間等。
35、查詢沒有索引的表
Select *from user_tableswhere table_name not in (select table_name from user_indexes);--或者使用以下
Select table_namefrom user_tableswhere table_name not in (select table_name from user_ind_columns);
????????USER_INDEXES視圖提供了有關當前用戶所創建的索引的整體信息,而USER_IND_COLUMNS視圖提供了更詳細的索引列信息。這兩個視圖都是用于監視和管理數據庫對象的工具,
36、查詢7天的db time
--37、查詢7天的db time
WITH sysstat AS(select sn.begin_interval_time begin_interval_time,sn.end_interval_time end_interval_time,ss.stat_name stat_name,ss.value e_value,lag(ss.value, 1) over(order by ss.snap_id) b_valuefrom dba_hist_sysstat ss, dba_hist_snapshot snwhere trunc(sn.begin_interval_time) >= sysdate - 7and ss.snap_id = sn.snap_idand ss.dbid = sn.dbidand ss.instance_number = sn.instance_numberand ss.dbid = (select dbid from v$database)and ss.instance_number = (select instance_number from v$instance)and ss.stat_name = 'DB time')
select to_char(BEGIN_INTERVAL_TIME, 'mm-dd hh24:mi') ||to_char(END_INTERVAL_TIME, ' hh24:mi') date_time,stat_name,round((e_value - nvl(b_value, 0)) /(extract(day from(end_interval_time - begin_interval_time)) * 24 * 60 * 60 +extract(hour from(end_interval_time - begin_interval_time)) * 60 * 60 +extract(minute from(end_interval_time - begin_interval_time)) * 60 +extract(second from(end_interval_time - begin_interval_time))),0) per_secfrom sysstatwhere (e_value - nvl(b_value, 0)) > 0and nvl(b_value, 0) > 0
?
????????Oracle 的性能視圖 dba_hist_sysstat 和 dba_hist_snapshot 中查詢數據庫的 "DB time" 統計信息。"DB time" 是 Oracle 數據庫中一個非常重要的性能指標,它表示在某個時間段內,所有活動的會話在數據庫中消耗的總時間。
????????- date_time:這是一個時間段,表示 "DB time" 的統計信息是在這個時間段內收集的。它由 BEGIN_INTERVAL_TIME 和 END_INTERVAL_TIME 兩個字段拼接而成,BEGIN_INTERVAL_TIME 是時間段的開始時間,END_INTERVAL_TIME 是時間段的結束時間。
????????- stat_name:這是統計信息的名稱,在這個查詢中,它的值總是 "DB time"。
????????- per_sec:這是每秒的 "DB time"。它是在指定的時間段內,"DB time" 的增量除以時間段的長度(以秒為單位)得到的。如果 "DB time" 在這個時間段內沒有增加,那么 per_sec 的值就是 0。
????????這個結果集在 Oracle 數據庫中是用來監控數據庫的性能。通過查看 "DB time" 的變化,你可以了解數據庫的負載是否在增加或減少,這對于數據庫的性能調優和故障排查是非常有用的。
37、查詢產生熱塊較多的對象
?????x$bh .tch表示訪問次數越高,熱點快競爭問題就存在
SELECT e.owner, e.segment_name, e.segment_type
FROM dba_extents e,
(SELECT *
FROM (SELECT addr,ts#,file#,dbarfil,dbablk,tch
FROM x$bh
ORDER BY tch DESC)
WHERE ROWNUM < 11) b
WHERE e.relative_fno = b.dbarfil
AND e.block_id <= b.dbablk
AND e.block_id + e.blocks > b.dbablk;????????Oracle?的?dba_extents?視圖和?x$bh?內部表中查詢信息。dba_extents?視圖提供了數據庫中所有段的擴展信息,x$bh?內部表提供了數據庫的緩沖池中的塊信息。
-?e.owner:這是段的所有者,也就是擁有這個段的用戶的名稱。
-?e.segment_name:這是段的名稱。
-?e.segment_type:這是段的類型,例如?"TABLE",?"INDEX" 等。
????????這個查詢的目的是找出數據庫緩沖池中最熱的(被訪問次數最多的)10個塊所屬的段。這對于了解數據庫的訪問模式和優化數據庫的性能是非常有用的。如果一個表或索引的塊被頻繁地訪問,那么可能需要考慮對這個表或索引進行優化,例如重新組織表,重建索引,或者調整緩沖池的大小。
38、導出AWR報告的SQL語句
--根據以下語句查詢DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid字段需要指定的對應的值
select * from dba_hist_snapshot;select * from table(dbms_workload_repository.awr_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid))select * from TABLE(DBMS_WORKLOAD_REPOSITORY.awr_diff_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid));????????AWR(Automatic Workload Repository)報告在Oracle數據庫中非常重要,它是一個自動負載信息庫,是Oracle 10g以后版本提供的一種性能收集和分析工具。AWR報告能提供一個時間段內整個系統資源使用情況的報告,通過報告可以了解一個系統的整個運行情況。
????????AWR每小時對v$active v$session v$history視圖(內存中的ASH采集信息,理論為1小時)進行采樣一次,并將信息保存到磁盤中,并且保留7天,7天后舊的記錄才會被覆蓋。這些采樣信息被保存在wrh_active_session_history視圖(寫入AWR庫中的ASH信息,理論為1小時以上)中。
????????AWR報告可以提供關于數據庫性能的各種詳細信息,包括CPU使用情況、內存使用情況、磁盤I/O、網絡I/O等。這些信息可以幫助數據庫管理員更好地理解數據庫的性能表現,發現性能瓶頸,并采取適當的措施來優化和提升數據庫的性能。
????????另外,AWR報告還可以在問題發生后進行故障排查和問題解決。如果數據庫性能出現下降或其他問題,可以通過查看AWR報告來了解問題發生時系統的運行情況,從而更好地定位問題的原因。
40、查詢某個SQL的執行計劃
--通過以下查詢語句,獲取對應sql的hash_value
select a.hash_value,a.* from v$sql a where sql_id='&指定的SQL_id'--講以上查詢語句的對應hash_value,填入到下列語句中,'advanced'代表高級信息
select * from table(dbms_xplan.display_cursor(v$sql.hash_value,0,'advanced'));select * from table(xplan.display_cursor('v$sql.sql_id',0,'advanced'));--不過要先創建xplan包,再執行
SQL> CREATE PUBLIC SYNONYM XPLAN FOR SYS.XPLAN;
SQL> grant execute on sys.xplan to public;????????DBMS_XPLAN.DISPLAY_CURSOR 是一個函數,它返回一個表,表中的每一行都是執行計劃的一部分。這個函數有三個參數:
????????- 第一個參數是 SQL 語句的哈希值或 SQL ID。在第一段代碼中,它是 v$sql.hash_value,在第二段代碼中,它是 'v$sql.sql_id'。
????????- 第二個參數是子游標的編號。在這兩段代碼中,它都是 0,表示主游標。
????????- 第三個參數是格式選項。在這兩段代碼中,它都是 'advanced',表示顯示高級信息,包括優化器的成本、字節、基數等。
????????結果集中的每一行都是執行計劃的一部分,包括操作的類型(例如 "TABLE ACCESS FULL", "INDEX RANGE SCAN" 等)、操作的對象(例如表名或索引名)、操作的成本和基數等信息。
????????這個結果集在 Oracle 數據庫中的作用是用來優化 SQL 語句的性能。通過查看執行計劃,你可以了解 Oracle 數據庫是如何執行 SQL 語句的,從而找出性能瓶頸,優化 SQL 語句或數據庫結構。




)


)











