AI為工業產業智能化數字化賦能早已不是什么新鮮事,越來越多的行業和領域開始更大范圍去擁抱AI,享受科技帶來的變革力量,在我們之前的文章中也有很多相關領域項目的實踐經歷,本文的核心目標就是想要基于鋼鐵領域產品數據來開發構建自動化智能質檢系統,以期探索AI助力鋼鐵產業產品質檢的可行性,首先看下效果:

簡單看下數據集:


本文選擇的是yolov5系列的模型,這里以s系列的模型為例看下詳情:
訓練數據配置文件如下:
# Dataset
path: ./dataset
train:- images/train
val:- images/test
test:- images/test# Classes
names:0: chongkong1: hanfeng2: yueyawan3: shuiban4: youban5: siban6: yiwu7: yahen8: zhehen9: yaozhe模型文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32#Backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]#Head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
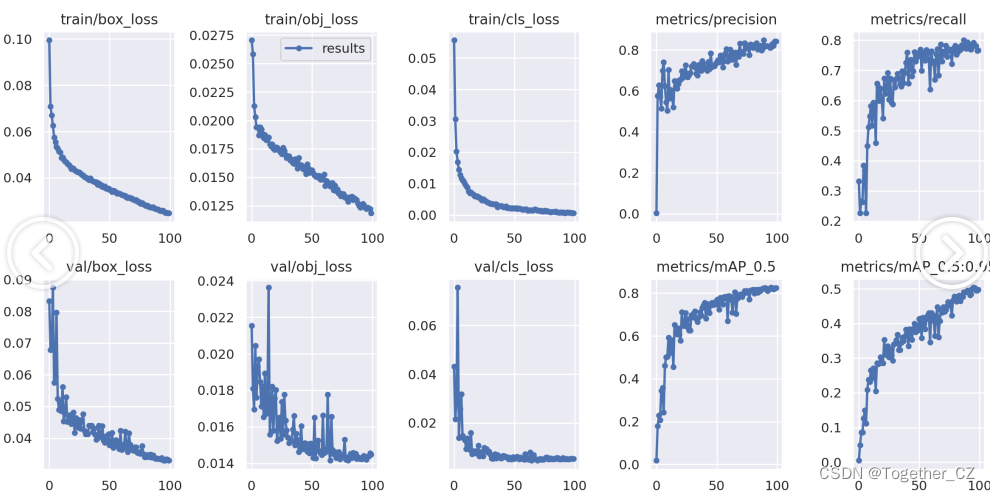
默認100次epoch的迭代計算,結果詳情如下所示:
【Precision曲線】
精確率曲線(Precision-Recall Curve)是一種用于評估二分類模型在不同閾值下的精確率性能的可視化工具。它通過繪制不同閾值下的精確率和召回率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率(Precision)是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率曲線。
根據精確率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察精確率曲線,我們可以根據需求確定最佳的閾值,以平衡精確率和召回率。較高的精確率意味著較少的誤報,而較高的召回率則表示較少的漏報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
精確率曲線通常與召回率曲線(Recall Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。

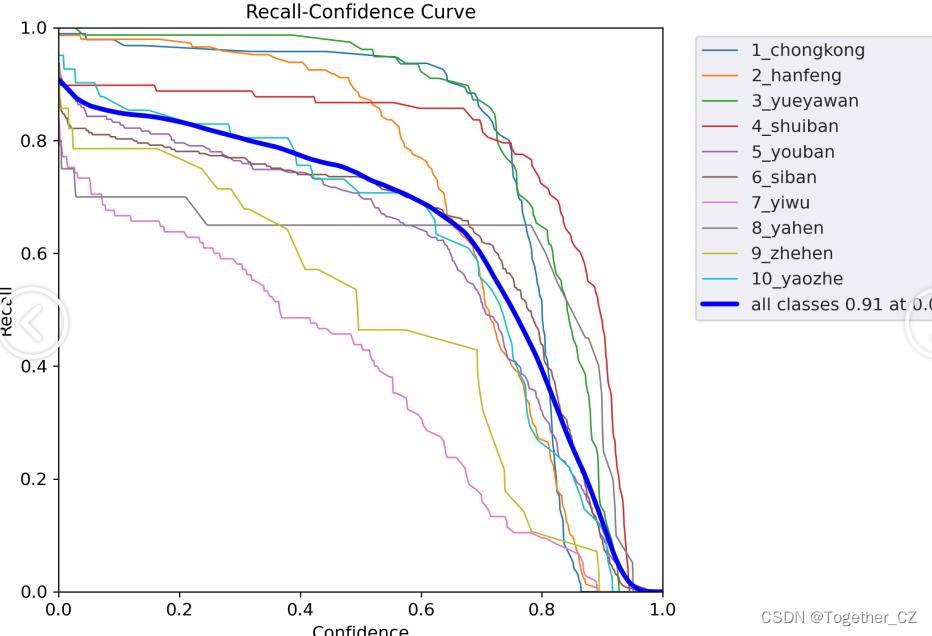
【Recall曲線】
召回率曲線(Recall Curve)是一種用于評估二分類模型在不同閾值下的召回率性能的可視化工具。它通過繪制不同閾值下的召回率和對應的精確率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。召回率也被稱為靈敏度(Sensitivity)或真正例率(True Positive Rate)。
繪制召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的召回率和對應的精確率。
將每個閾值下的召回率和精確率繪制在同一個圖表上,形成召回率曲線。
根據召回率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察召回率曲線,我們可以根據需求確定最佳的閾值,以平衡召回率和精確率。較高的召回率表示較少的漏報,而較高的精確率意味著較少的誤報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
召回率曲線通常與精確率曲線(Precision Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
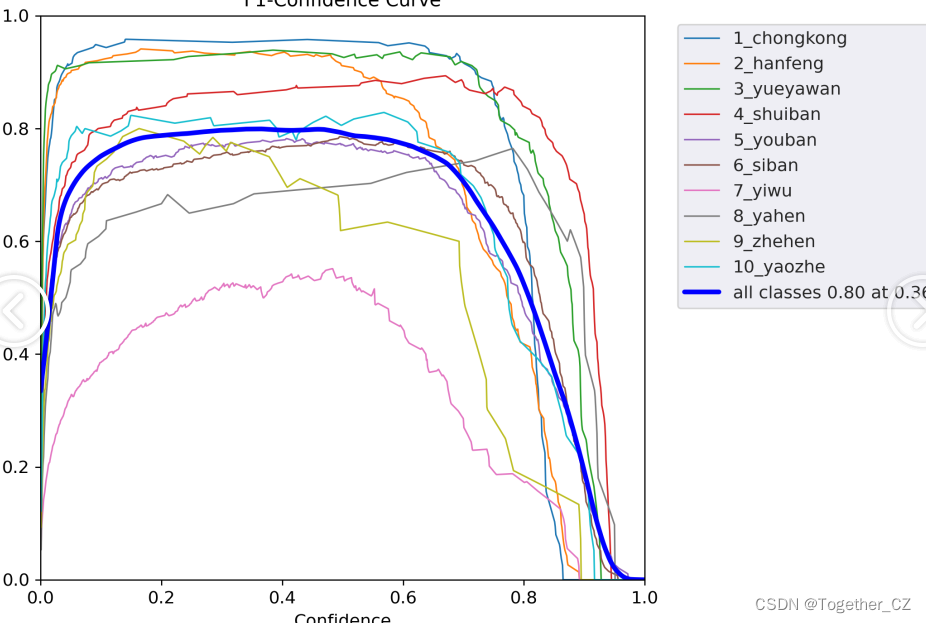
【F1值曲線】
F1值曲線是一種用于評估二分類模型在不同閾值下的性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)、召回率(Recall)和F1分數的關系圖來幫助我們理解模型的整體性能。
F1分數是精確率和召回率的調和平均值,它綜合考慮了兩者的性能指標。F1值曲線可以幫助我們確定在不同精確率和召回率之間找到一個平衡點,以選擇最佳的閾值。
繪制F1值曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率、召回率和F1分數。
將每個閾值下的精確率、召回率和F1分數繪制在同一個圖表上,形成F1值曲線。
根據F1值曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
F1值曲線通常與接收者操作特征曲線(ROC曲線)一起使用,以幫助評估和比較不同模型的性能。它們提供了更全面的分類器性能分析,可以根據具體應用場景來選擇合適的模型和閾值設置。
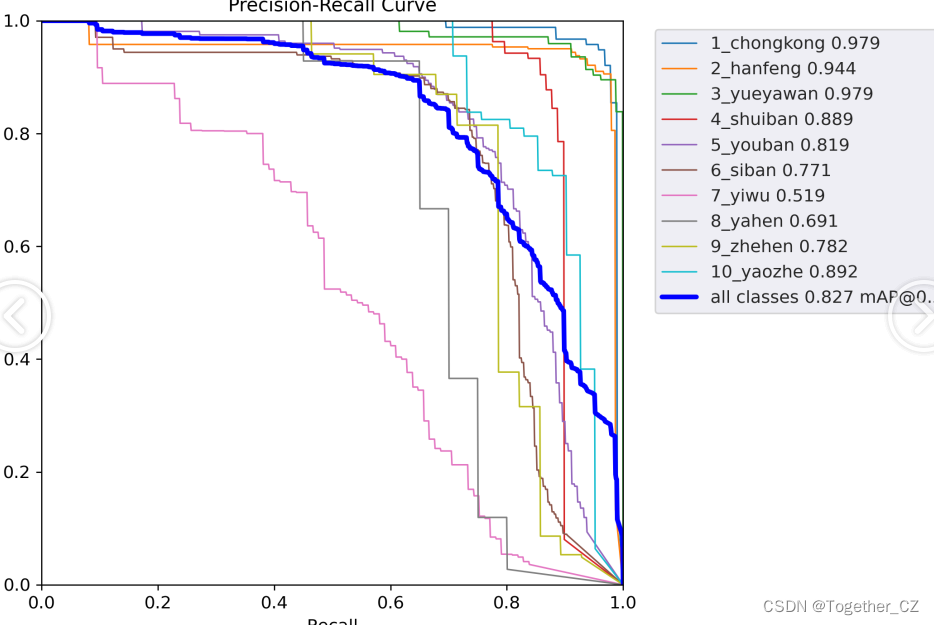
【PR曲線】
精確率-召回率曲線(Precision-Recall Curve)是一種用于評估二分類模型性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)和召回率(Recall)之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率-召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率-召回率曲線。
根據曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
精確率-召回率曲線提供了更全面的模型性能分析,特別適用于處理不平衡數據集和關注正例預測的場景。曲線下面積(Area Under the Curve, AUC)可以作為評估模型性能的指標,AUC值越高表示模型的性能越好。
通過觀察精確率-召回率曲線,我們可以根據需求選擇合適的閾值來權衡精確率和召回率之間的平衡點。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
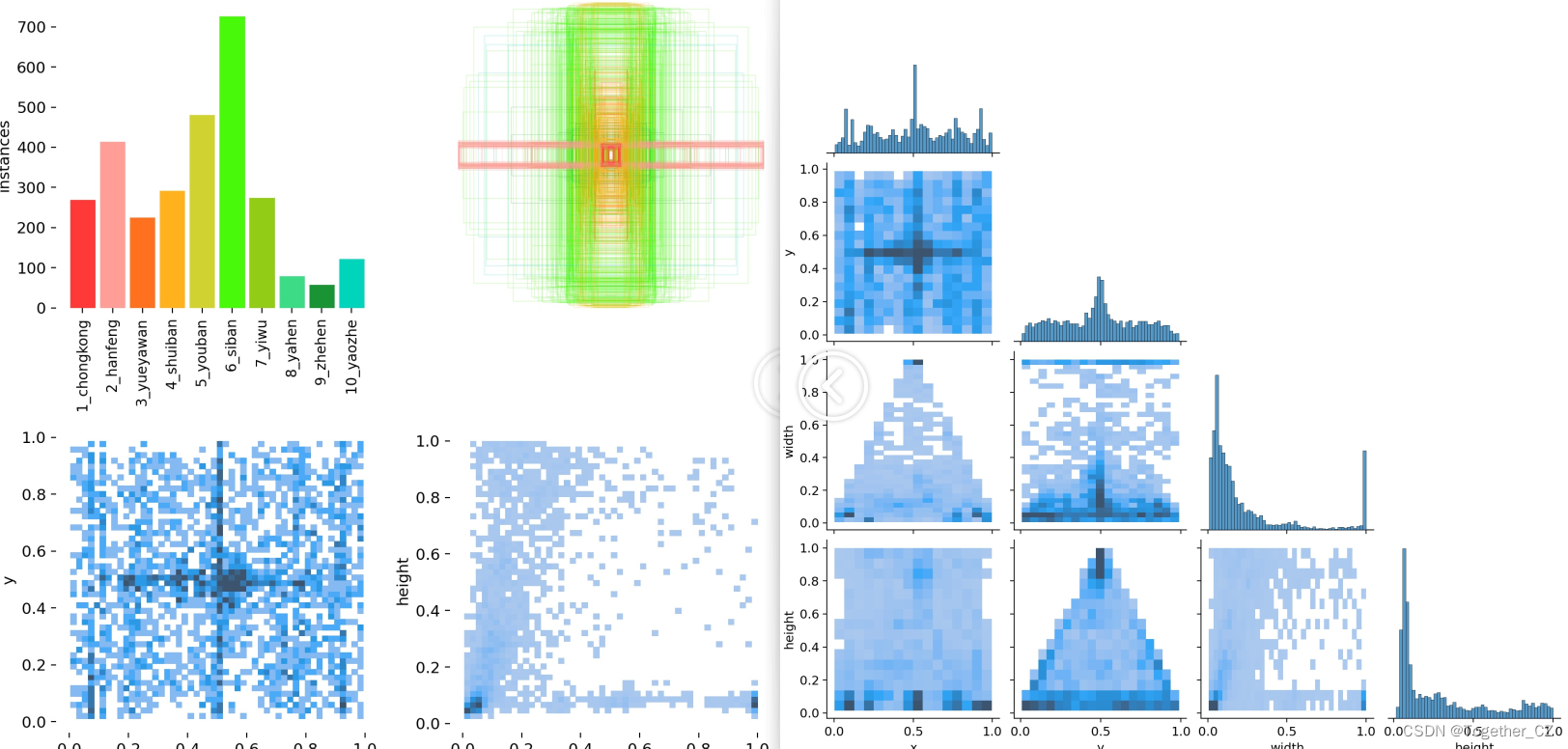
【label數據分布可視化】
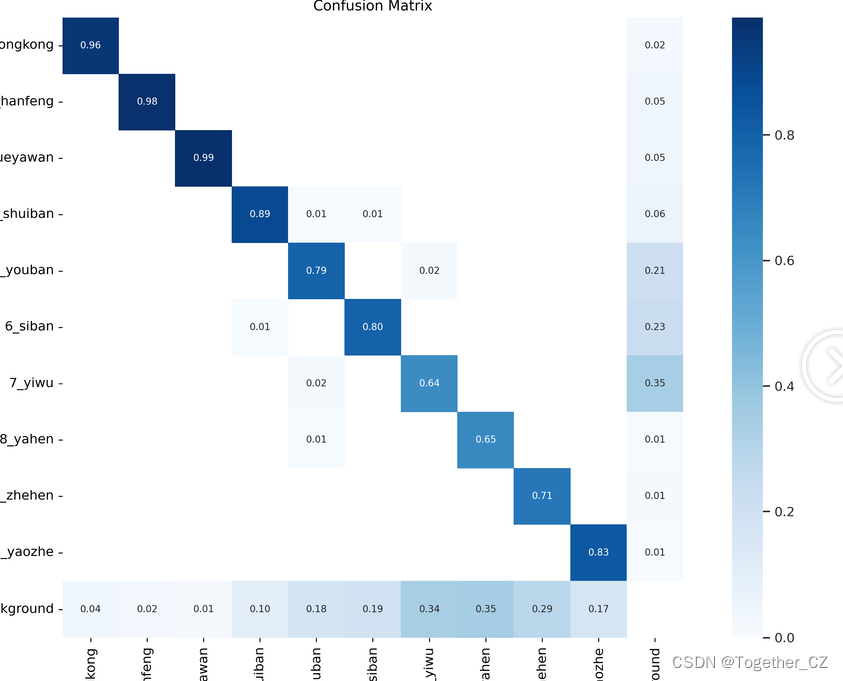
【混淆矩陣】
【訓練可視化】
【Batch計算實例】


這里也基于GradCam計算測試了樣例圖像的heatmap,如下所示:
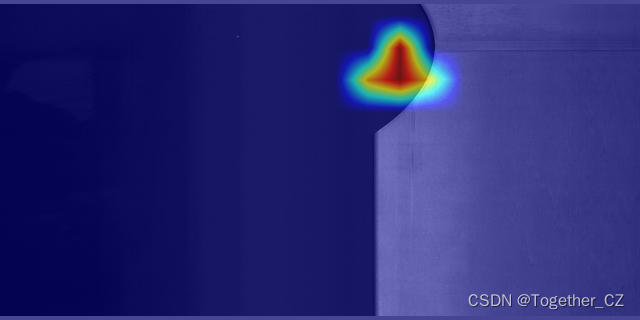


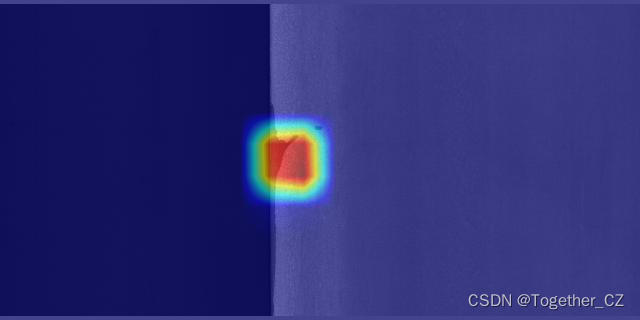
感興趣的也都可以自行嘗試實踐下,可能會有不同的收獲!?



















