歡迎大家點贊、收藏、關注、評論啦 ,由于篇幅有限,只展示了部分核心代碼。
文章目錄
- 一項目簡介
- 二、功能
- 三、系統
- 四. 總結
一項目簡介
??深度學習在計算機視覺領域的應用已經取得了顯著的進展,特別是在多人多攝像頭場景下的摔倒跌倒檢測。通過深度學習技術,我們可以自動從視頻中識別出人的行為,從而為安全監控、人機交互等領域提供重要的支持。
PyTorch框架是一種流行的深度學習框架,它提供了易于使用的API和強大的GPU加速功能,使得研究人員和開發人員能夠快速構建和訓練深度學習模型。
在多人多攝像頭場景下,摔倒跌倒檢測是一個具有挑戰性的任務,因為它涉及到多個攝像頭的同步、多視角視頻的拼接、以及復雜背景下的目標檢測。為了解決這些問題,我們可以使用基于PyTorch的深度學習模型,如卷積神經網絡(CNN)和循環神經網絡(RNN)等。
主要內容:
- 介紹背景和意義
- 深度學習框架的選擇(PyTorch)
- 多人多攝像頭場景下的挑戰
- 基于PyTorch的摔倒跌倒檢測模型的設計與實現
- 實驗結果與分析
- 總結與展望
為了實現高效的摔倒跌倒檢測,我們需要設計一個合適的深度學習模型,并對其進行充分的訓練和優化。以下是一些可能的步驟和方法:
步驟一:收集數據集
為了訓練有效的模型,我們需要一個大規模的多人多攝像頭摔倒跌倒數據集。這個數據集應該包括不同角度、不同光照條件下的摔倒跌倒視頻。此外,為了提高模型的泛化能力,我們還需要對數據集進行適當的標注和預處理。
步驟二:模型設計
基于PyTorch的深度學習模型通常包括卷積層、池化層、全連接層等。我們可以使用CNN來提取視頻中的特征,使用RNN來捕捉時間序列信息,以及使用注意力機制來增強模型的魯棒性。為了提高模型的性能,我們還可以結合使用其他技術,如數據增強、正則化等。
步驟三:模型訓練與優化
在訓練過程中,我們需要使用適當的損失函數和優化器來最小化模型的預測誤差。為了提高模型的泛化能力,我們還需要對模型進行適當的超參數調整和優化。此外,我們還可以使用驗證集來評估模型的性能,并根據結果對模型進行調整和優化。
實驗結果與分析:
通過訓練和測試基于PyTorch的摔倒跌倒檢測模型,我們可以得到一些實驗結果。這些結果將包括準確率、召回率、F1得分等指標,以及可視化結果和深度學習模型的性能曲線等。通過分析這些結果,我們可以評估模型的性能,并進一步優化模型以提高準確性和魯棒性。
總結與展望:
通過深度學習和PyTorch框架,我們可以實現高效的摔倒跌倒檢測。雖然目前的研究已經取得了一定的成果,但仍有許多挑戰需要解決。未來的研究可以關注以下幾個方面:
- 更大規模的數據集:為了進一步提高模型的性能,我們需要更多的多攝像頭摔倒跌倒數據集。
- 更先進的模型架構:隨著深度學習技術的發展,我們可以探索更先進的模型架構來提高摔倒跌倒檢測的準確性和魯棒性。
- 多模態信息融合:除了視頻信息外,我們還可以考慮融合其他模態信息,如語音、姿態等,以提高摔倒跌倒檢測的準確性。
- 實時性和低功耗:為了在現實場景中廣泛應用摔倒跌倒檢測技術,我們需要考慮實時性和低功耗的問題。
二、功能
??環境:Python3.8、OpenCV4.5、PyCharm2020
簡介:我們通過支持多攝像機和多人跟蹤以及長短時記憶(LSTM)神經網絡來預測兩類:“墜落”或“無墜落”,從而增強了人體姿勢估計(openpifpaf庫)。從姿態中,我們提取了五個時間和空間特征,并由LSTM分類器進行處理。
三、系統

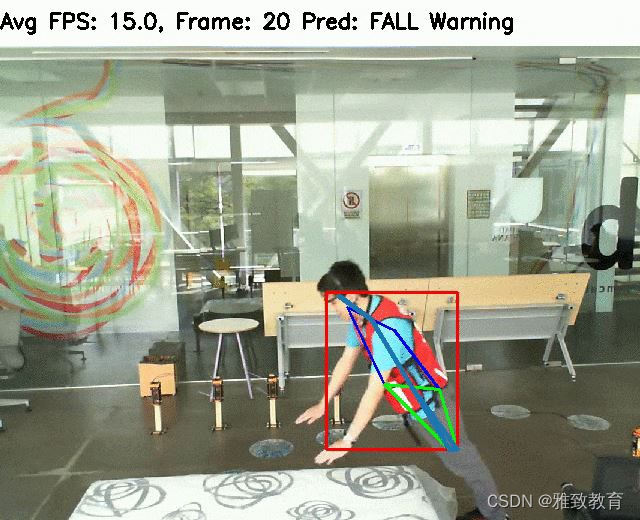

四. 總結
??總之,基于PyTorch框架的深度學習在多人多攝像頭摔倒跌倒檢測領域具有廣闊的應用前景。通過不斷的研究和探索,我們可以為安全監控、人機交互等領域帶來更多的便利和價值。





 事件修飾符、系統命令)



)







)
![2023年中國釩鐵產量及行業進出口現狀分析[圖]](http://pic.xiahunao.cn/2023年中國釩鐵產量及行業進出口現狀分析[圖])
