現在你能搜索到的SeaTunnel的安裝。部署基本都有坑,官網的文檔也是見到到相當于沒有,基本很難找到一個適合新手小白第一次上手就能成功安裝部署的版本,于是就有了這個部署指南的分享,小主已經把可能遇到的坑都填過了,希望大家都能安安穩穩上路,不掉坑,話不多說,走起~
1.預置環境
1.1.所需軟件包及版本要求
-
CentOS 7.6.18_x86_64
-
JDK >= 1.8.151
-
Maven >= 3.6.3
-
Apache Seatunnel ==2.3.3
-
Apache Seatunnel Web == 1.0.0
-
MySQL >= 5.7.28

1.2.下載地址
官網下載入口: 下載入口
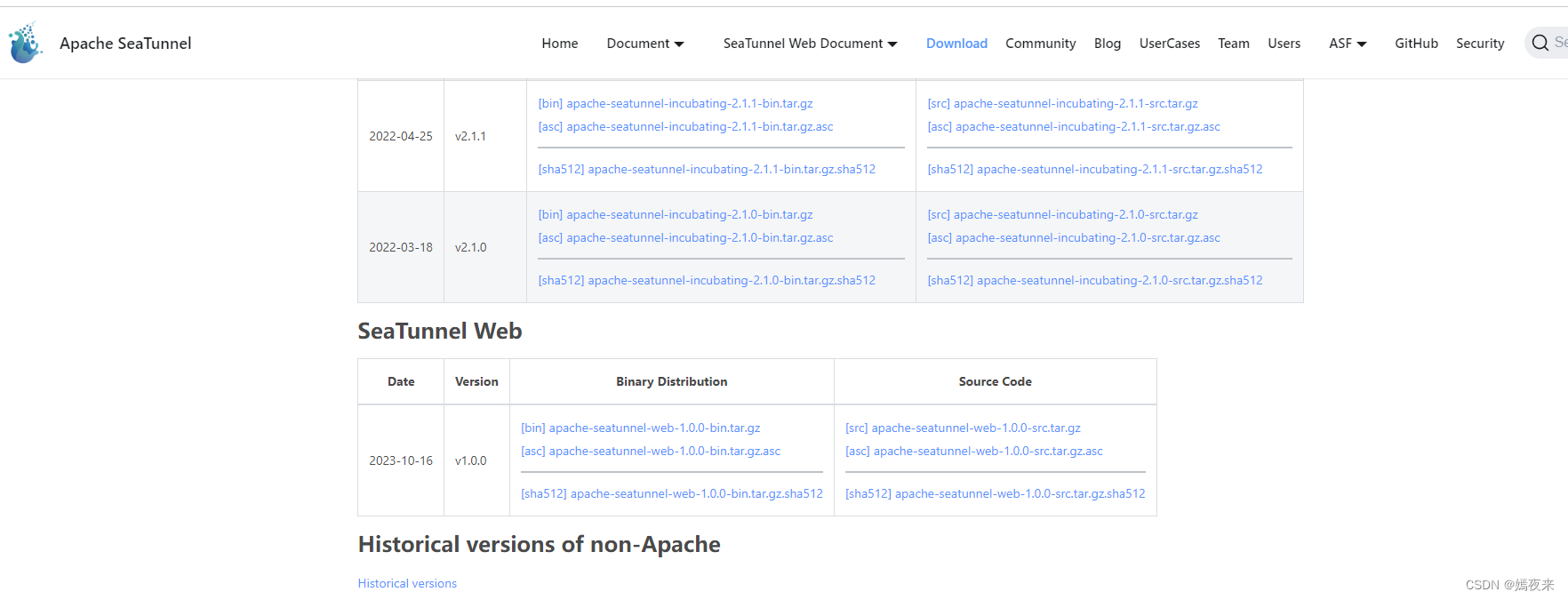
apache-seatunnel-2.3.3: apache-seatunnel-2.3.3-bin.tar.gz
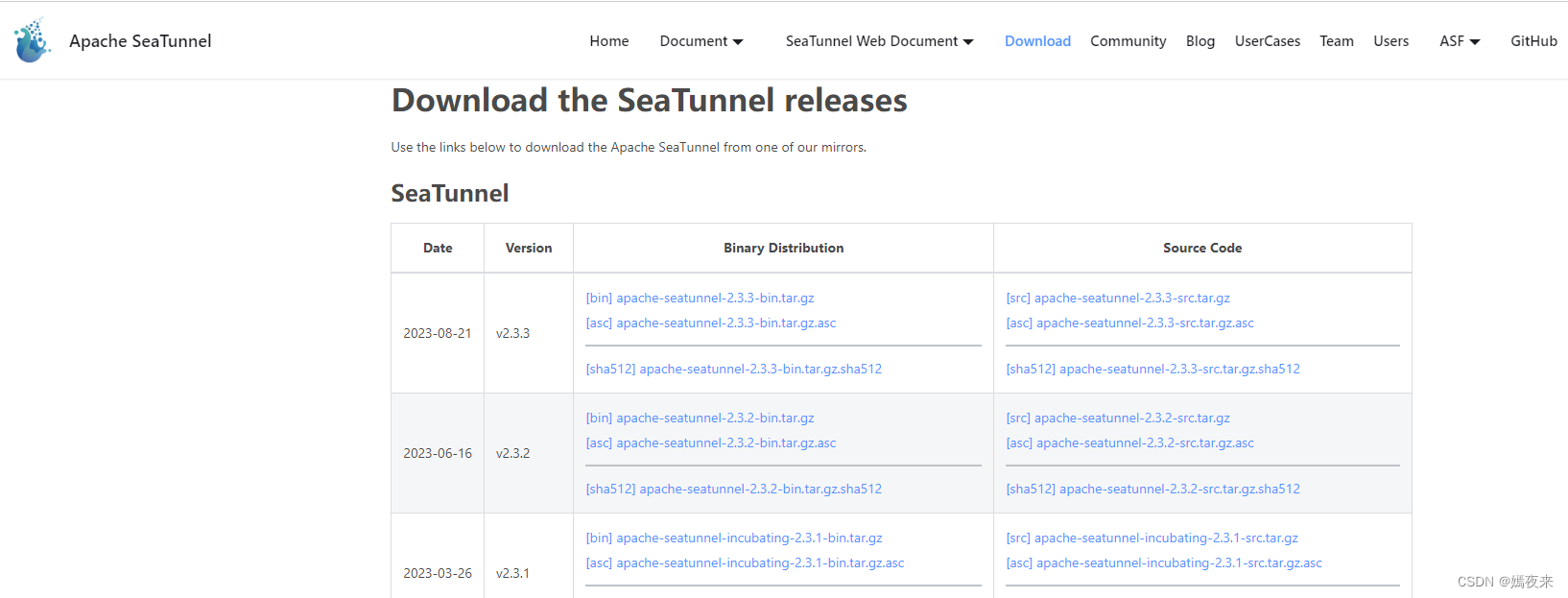
apache-seatunnel-web-1.0.0: apache-seatunnel-web-1.0.0
1.3.準備工作
1.3.1.安裝JDK
安裝及配置系統環境變量略過,自行百度
1.3.2.安裝Maven
安裝及配置系統環境變量、配置阿里云倉庫鏡像, 略過,自行百度
1.3.3.創建安裝軟件目錄
創建seatunnel后端服務安裝目錄
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend
**創建seatunnel前端服務安裝目錄
mkdir -p /opt/bigdata/seatunnel-2.3.3/web

1.3.4.下載或者本地上傳安裝包
下載apache-seatunnel-2.3.3-bin.tar.gz
#進入1.3.2中創建好的安裝目錄
cd /opt/bigdata/seatunnel-2.3.3/backend
#下載安裝包
wget https://dlcdn.apache.org/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz
下載[apache-seatunnel-web-1.0.0.tar.gz
#進入1.3.2中創建好的安裝目錄
cd /opt/bigdata/seatunnel-2.3.3/web
#下載安裝包
wget https://dlcdn.apache.org/seatunnel/seatunnel-web/1.0.0/apache-seatunnel-web-1.0.0-bin.tar.gz
如果你已經將安裝包下載到本地, 可通過FTP工具上傳安裝包到前后端各自的安裝目錄。
2.安裝Apache Seatunnel
2.1.解壓安裝包
#解壓后端安裝包
tar -zxf /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3-bin.tar.gz
#重命名安裝包
mv apache-seatunnel-2.3.3-bin apache-seatunnel-2.3.3

#解壓前端安裝包
tar -zxf /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0-bin.tar.gz
#重命名安裝包
mv apache-seatunnel-web-1.0.0-bin apache-seatunnel-web-1.0.0

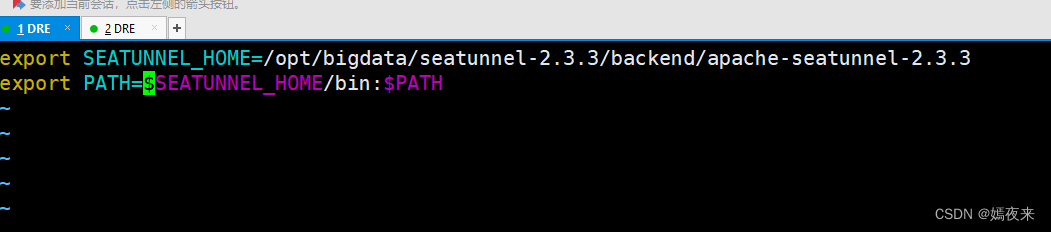
2.2.配置環境變量
在/etc/profile中配置環境變量
讓修改配置立即生效
source /etc/profile
2.3.下載JAR包
2.3.1.創建目錄
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/flink
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/flink-sql
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/spark
mkdir -p /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/seatunnel
 ### 2.3.2.修改下載腳本
### 2.3.2.修改下載腳本
下載腳本的位置
/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/bin
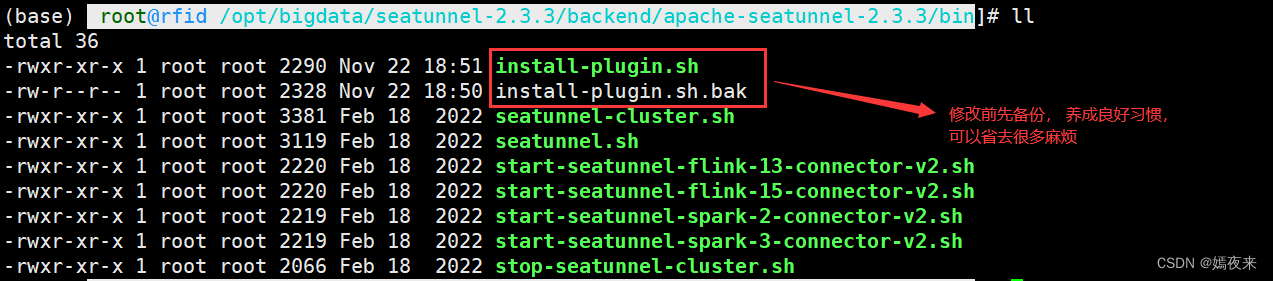
修改install-plugin.sh之前請先備份
mvn加速下載seatunnel相關jar包
安裝seatunnel過程中,解壓文件后官方默認提供的connector的jar包只有2個,要想連接mysql,oracle,SqlServer,hive,kafka,clickhouse,doris等時,還需下載對應的jar包。
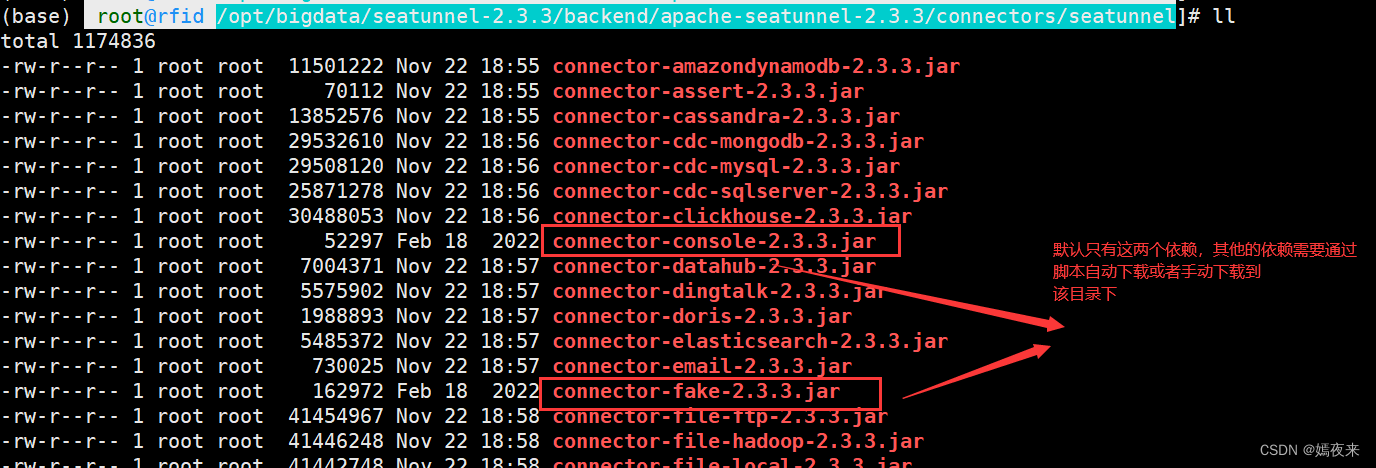
使用本地Maven加速下載connector相關jar包
seatunnel下載connector的jar時,使用mvnw來下載jar包,默認是從https://repo.maven.apache.org 下載,速度及其緩慢。我們可以改成自己在linux系統上安裝的mvn,配置阿里云遠程倉庫地址,從阿里云mvn源下載會快很多, 下面教大家如何進行修改。
修改其安裝插件相關腳本,復制bin目錄下install-plugin.sh重命名為install-plugin.sh.bak
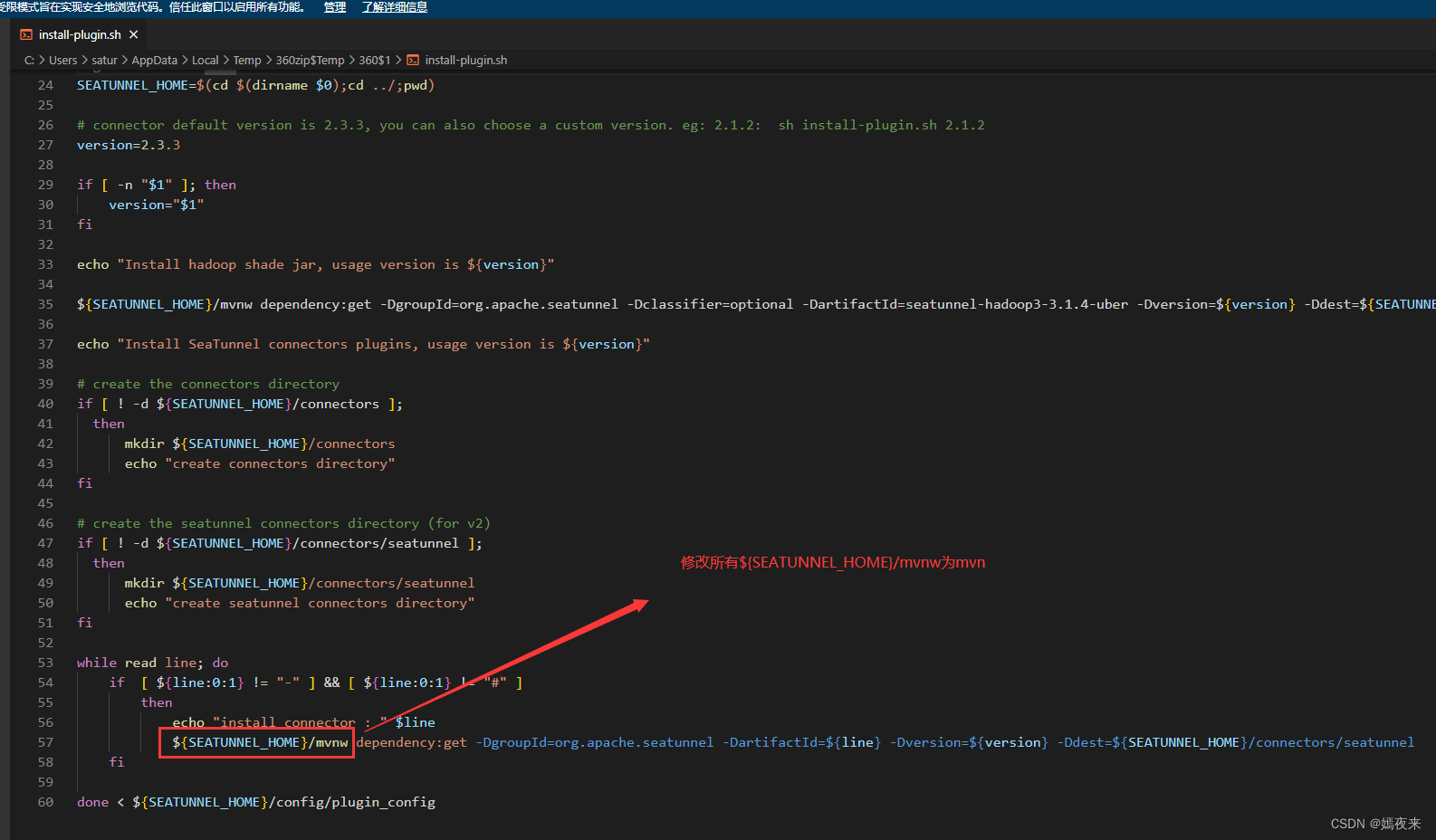
替換腳本中的${SEATUNNEL_HOME}/mvnw為mvn,即可使用本地mvn,配合阿里云的mvn源,可加速下載。
2.3.3.執行下載
2.3.3.1.自動下載
執行命令即可,一般不推薦,因為從官網下載速度太慢,可以通過修改相關的代碼進行手動加速下載。
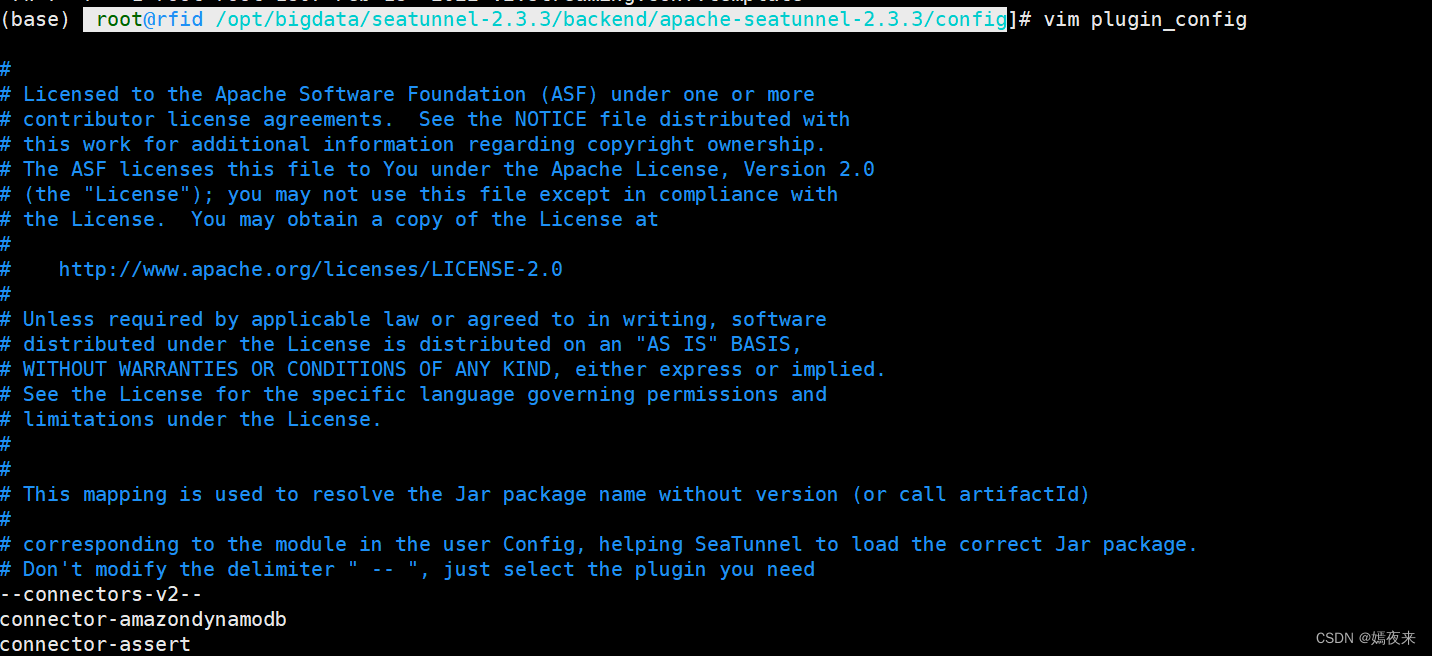
系統默認自動下載時會下載所有的連接器JAR, 如果暫時不需要使用, 可以在執行下載腳本執行之前先在/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/config/pulgun_config配置中注釋掉不需要的連接器
sh /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/bin/install-plugin.sh
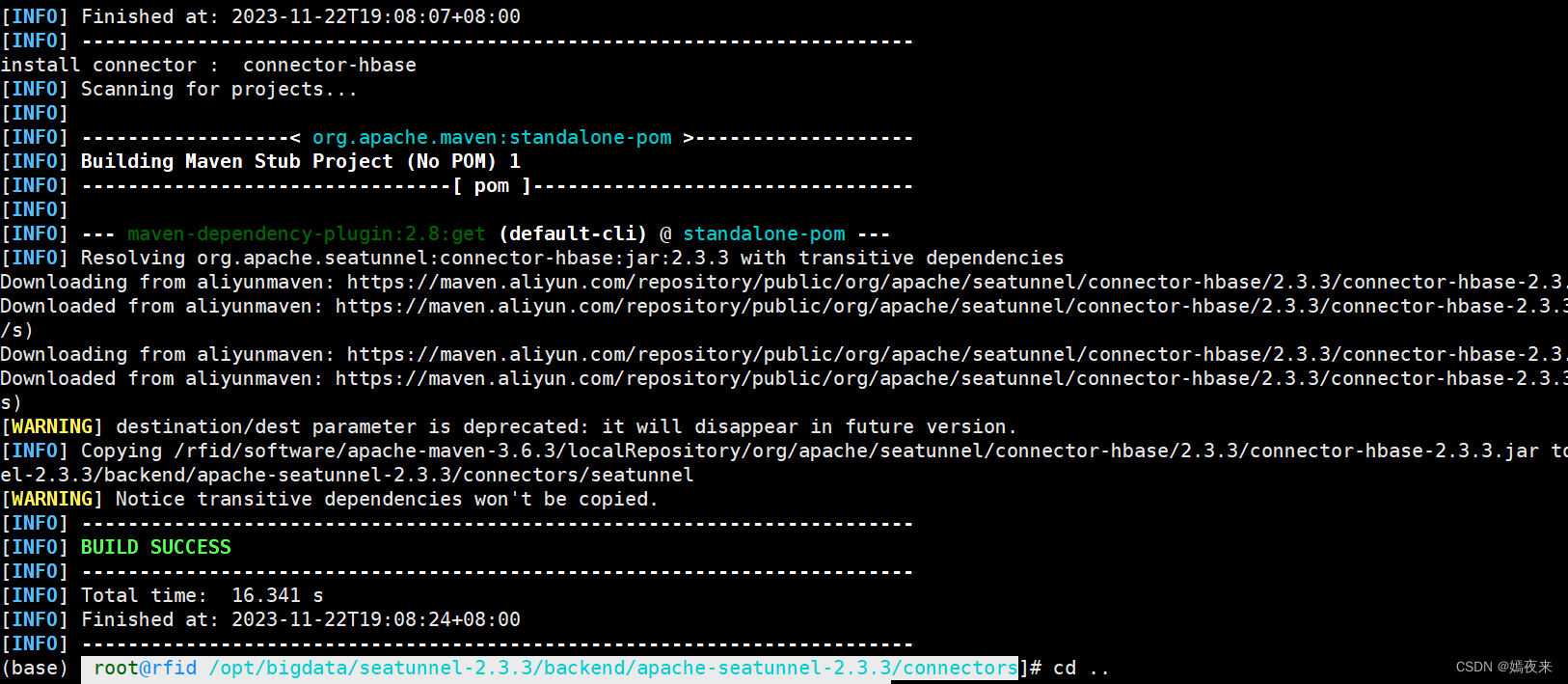
自動下載完成之后, 將/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/seatunnel下所有的jar包都拷貝到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib目錄下
2.3.3.2.手動下載
修改代碼,通過阿里云的mvn源快速下載,然后將相關jar包復制到對應目錄即可。
seatunnel-connectors下載地址
注意:下載jar復制到兩個文件夾,一個是lib文件夾,一個是connectors/seatunnel文件夾。
2.3.4.測試驗證
#進入安裝目錄
cd /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3
#啟動服務
./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
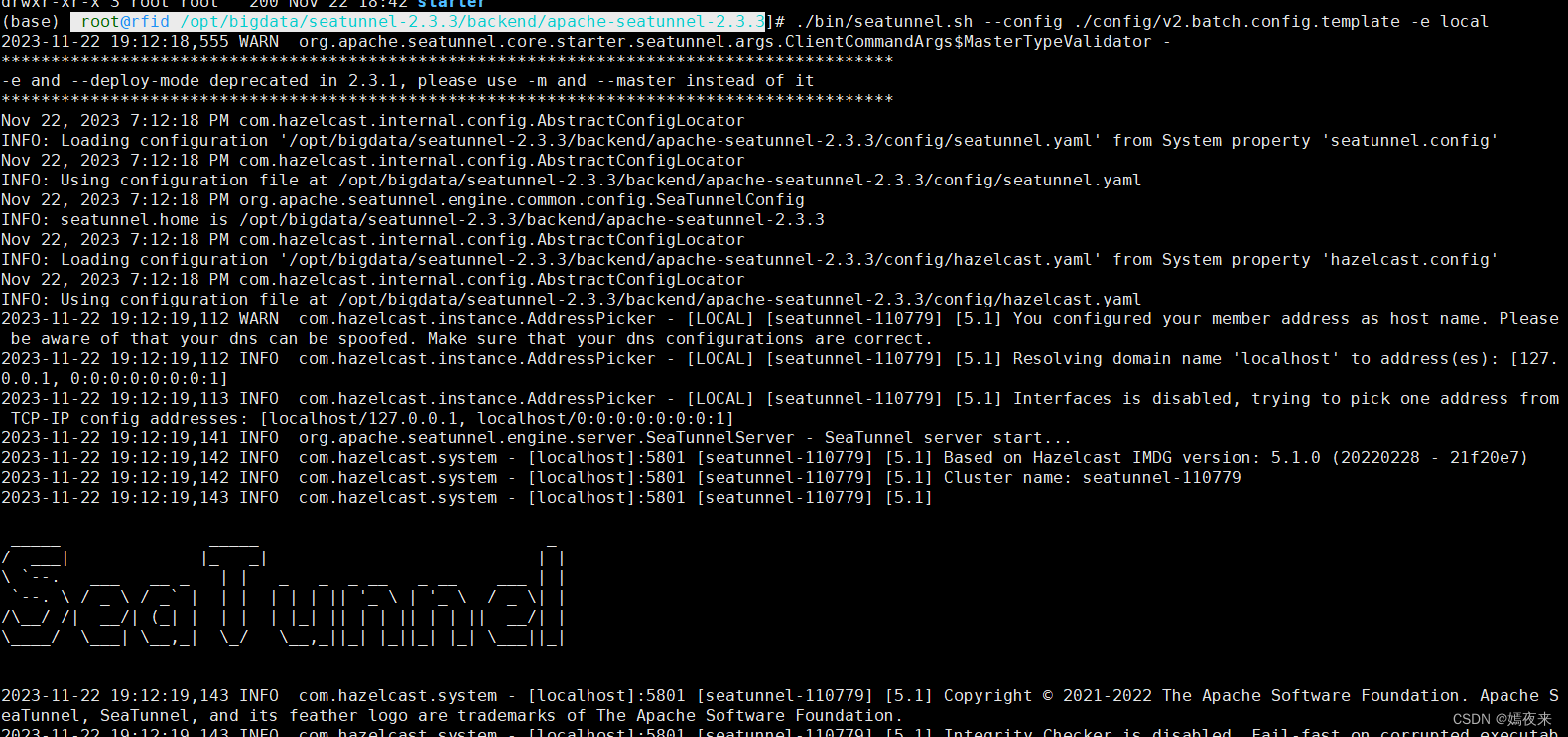
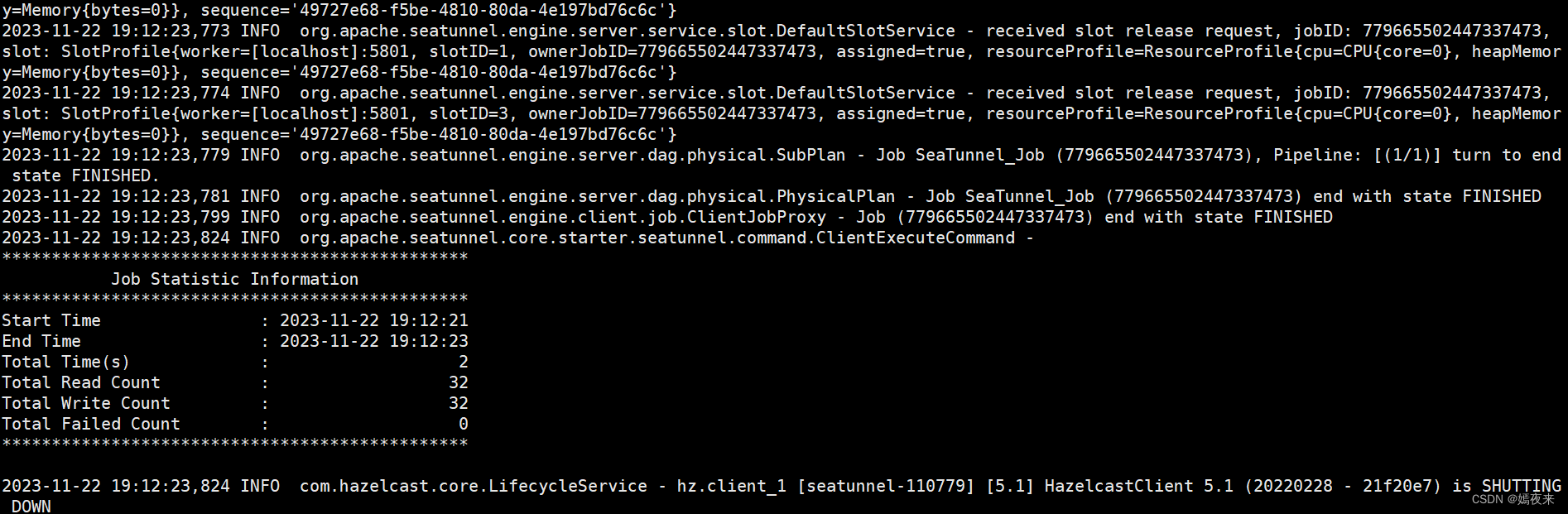
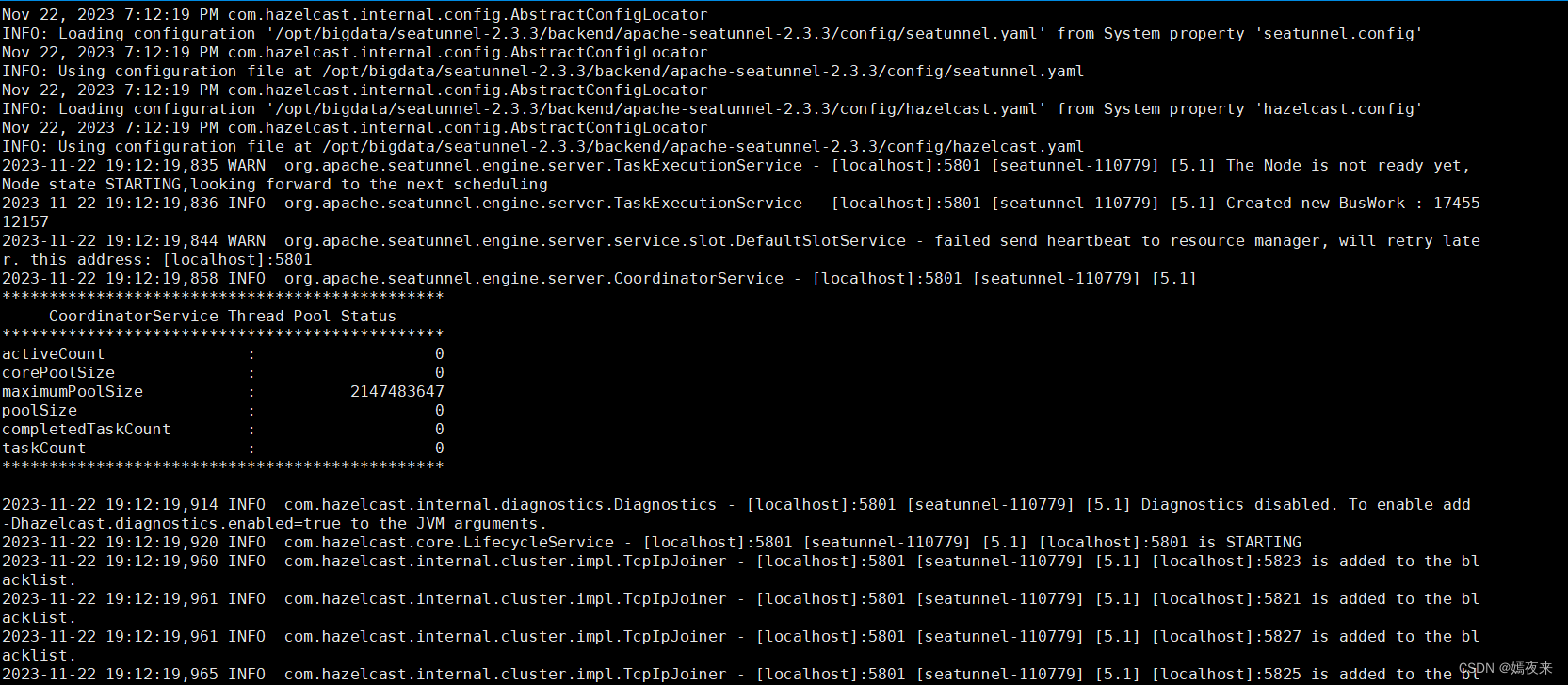
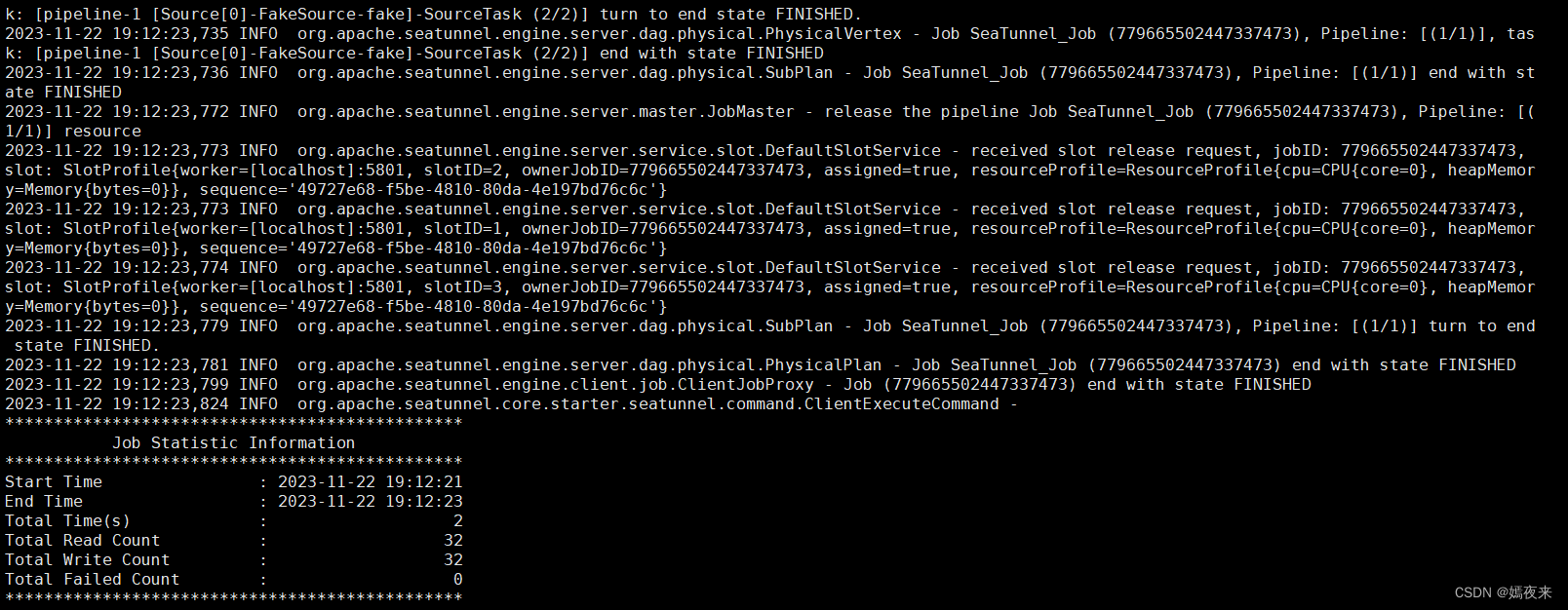
2.4.啟動服務
#進入安裝目錄
cd /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3
#啟動服務
nohup sh bin/seatunnel-cluster.sh 2>&1 &
在seatunnel的安裝目錄下查看日志
tail -f logs/seatunnel-engine-server.log 有以下類似信息打印出,說明啟動成功。
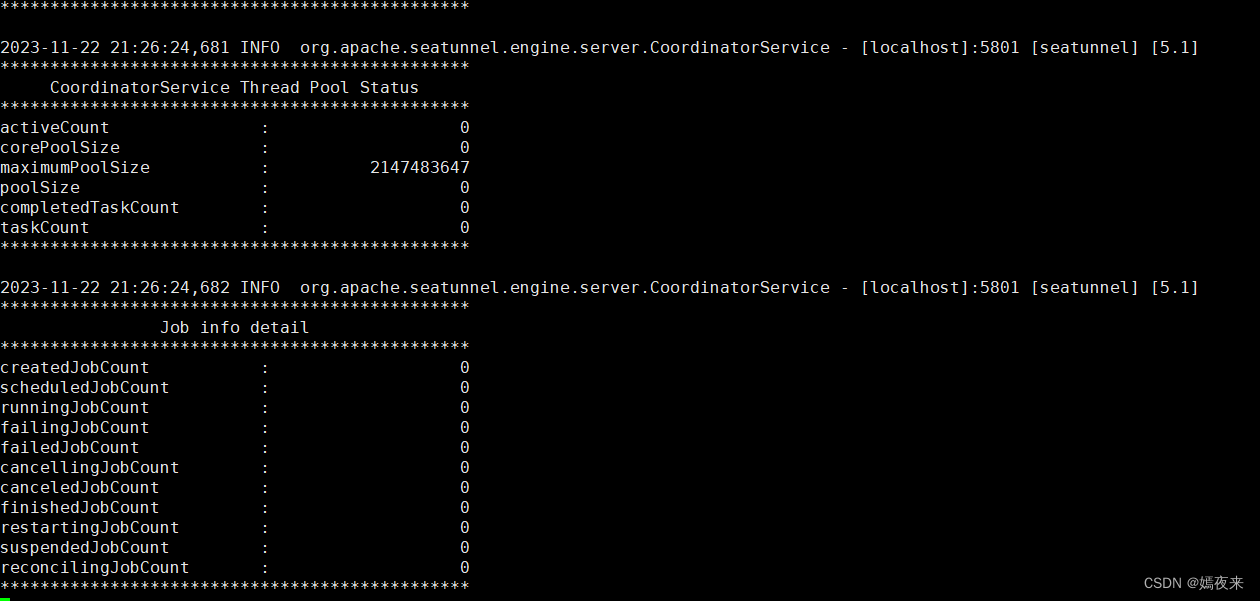
必須保證Apache SeaTunnel的Server正常運行,Web端服務才能正常運行。
3.安裝Apache Seatunnel Web
3.1.安裝配置Seatunnel引擎集群
在SeaTunnel的Web端機器上需要安裝SeaTunnel客戶端,如果服務端與Web端在同一臺機器,則可直接跳過這個步驟。
本文檔的安裝過程中,Seatunnel服務端和web是安裝在同一臺機器上, 所以直接跳過此步安裝步驟。
這里所說的Seatunnel引擎客戶端其實就是我們章2中安裝的Seatunnel服務端, 下面講解一下如何進行Seatunnel集群的安裝配置
3.1.1.準備服務器節點
我們現在需要搭建Seatunnel引擎集群,需要準備n臺服務器節點, 我這里使用了3臺服務器。比如, 已知我們的3臺服務器的IP分別是
192.168.1.110
192.168.1.111
192.168.1.112
我們直接在章2中已經安裝部署好的Seatunnel單節點中進行集群的配置,主要的配置修改包含以下幾項:
3.1.2.修改JVM參數
在seatunnel的安裝目錄,找到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh

將 JVM 選項添加到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh第一行
JAVA_OPTS=“-Xms2G -Xmx2G”
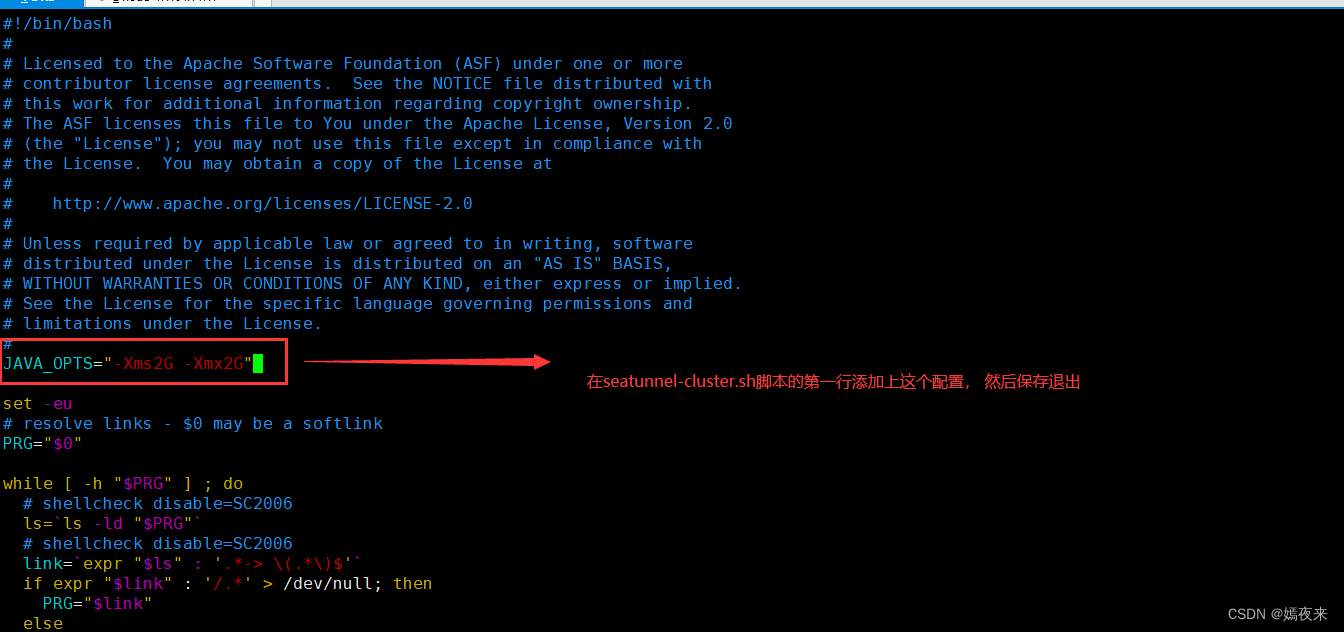
如果不想這樣進行修改,也可以, 不過需要在進行集群啟動時,自行增加JVM參數進行啟動, 啟動命令如下:
nohup sh $SEATUNNEL_HOME/bin/seatunnel-cluster.sh -DJvmOption="-Xms2G -Xmx2G" 2>&1 &
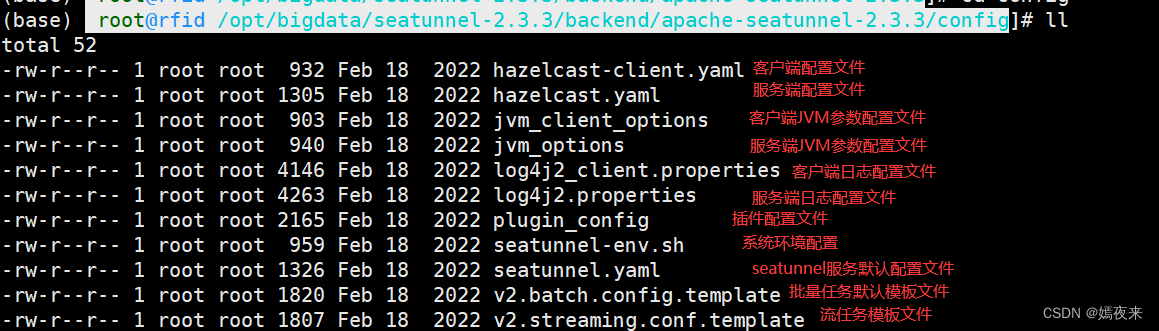
3.1.3.SeaTunnel Engine配置
SeaTunnel Engine Server配置是在sh $SEATUNNEL_HOME/config/seatunnel.yaml .
詳細配置想可參考官方文檔4. Config SeaTunnel Engine,這里不贅述
3.1.4.SeaTunnel Engine Server配置
SeaTunnel Engine Server配置是在sh $SEATUNNEL_HOME/config/hazelcast.yaml .
3.1.4.1.集群名稱配置
SeaTunnel Engine 節點使用集群名稱來確定對方是否與自己是一個集群。 如果兩個節點之間的集群名稱不同,SeaTunnel 引擎將拒絕服務請求。
3.1.4.2.網絡配置
SeaTunnel Engine 集群基于 Hazelcast,是運行 SeaTunnel Engine Server 的集群成員的網絡。 集群成員自動連接在一起形成集群。 這種自動加入是通過集群成員用來查找彼此的各種發現機制來實現的。
請注意,集群形成后,集群成員之間的通信始終通過 TCP/IP 進行,無論使用何種發現機制。
SeaTunnel 引擎使用以下發現機制。
TCP
您可以將 SeaTunnel Engine 配置為完整的 TCP/IP 集群。 有關配置詳細信息,請參閱通過 TCP 發現成員部分。
hazelcast.yaml配置示例如下:
hazelcast:cluster-name: seatunnelnetwork:join:tcp-ip:enabled: truemember-list:- hostname1port:auto-increment: falseport: 5801properties:hazelcast.logging.type: log4j2
在獨立 SeaTunnel 引擎集群中我們建議使用TCP方式。
另一方面,Hazelcast 提供了一些其他的服務發現方法。 詳情請參考hazelcast網
3.1.4.3 Map配置
- type
imap持久化類型,目前僅支持hdfs。
- namespace
命令空間用于區分不同業務的數據存儲位置,例如OSS的桶名。
- clusterName
這個參數主要用于集群隔離,我們可以通過這個來區分不同的集群,比如cluster1、cluster2,這個也可以用來區分不同的業務
- fs.defaultFS
We used hdfs api read/write file, so used this storage need provide hdfs configuration
if you used HDFS, you can config like this:
map:engine*:map-store:enabled: trueinitial-mode: EAGERfactory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactoryproperties:type: hdfsnamespace: /tmp/seatunnel/imapclusterName: seatunnel-clusterstorage.type: hdfsfs.defaultFS: hdfs://localhost:9000
如果沒有 HDFS 并且您的集群只有一個節點,您可以配置為使用本地文件,如下所示:
map:engine*:map-store:enabled: trueinitial-mode: EAGERfactory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactoryproperties:type: hdfsnamespace: /tmp/seatunnel/imapclusterName: seatunnel-clusterstorage.type: hdfsfs.defaultFS: file:///
如果你使用OSS,你可以這樣配置:
map:engine*:map-store:enabled: trueinitial-mode: EAGERfactory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactoryproperties:type: hdfsnamespace: /tmp/seatunnel/imapclusterName: seatunnel-clusterstorage.type: ossblock.size: block size(bytes)oss.bucket: oss://bucket name/fs.oss.accessKeyId: OSS access key idfs.oss.accessKeySecret: OSS access key secretfs.oss.endpoint: OSS endpointfs.oss.credentials.provider: org.apache.hadoop.fs.aliyun.oss.AliyunCredentialsProvider
3.1.5.SeaTunnel Engine Client配置
SeaTunnel Engine Client配置是在sh $SEATUNNEL_HOME/config/hazelcast-client.yaml .
3.1.5.1.集群名稱配置
客戶端必須與 SeaTunnel 引擎具有相同的集群名稱。 否則,SeaTunnel 引擎將拒絕客戶端請求。
3.1.5.2.網絡配置
cluster-members
所有 SeaTunnel 引擎服務器節點地址都需要添加到此處。
hazelcast-client:cluster-name: seatunnelproperties:hazelcast.logging.type: log4j2network:cluster-members:- hostname1:5801
3.1.6.啟動Seatunnel引擎服務端節點
mkdir -p $SEATUNNEL_HOME/logscd $SEATUNNEL_HOME./bin/seatunnel-cluster.sh -d
如果集群存在多臺節點, 需要啟動所有節點上的Seatunnel引擎服務。
3.1.7.安裝Seatunnel引擎客戶端并啟動
您只需將SeaTunnel引擎節點上的安裝目錄目錄復制到客戶端節點主機的相同安裝目錄下,并像SeaTunnel引擎服務器節點一樣配置SEATUNNEL_HOME,之后啟動服務即可。
3.2.配置Seatunnel Web服務
3.2.1.數據庫初始化
3.2.1.1.修改數據庫連接配置
將script/seatunnel_server_env.sh相關配置改為你的對應的數據庫信息

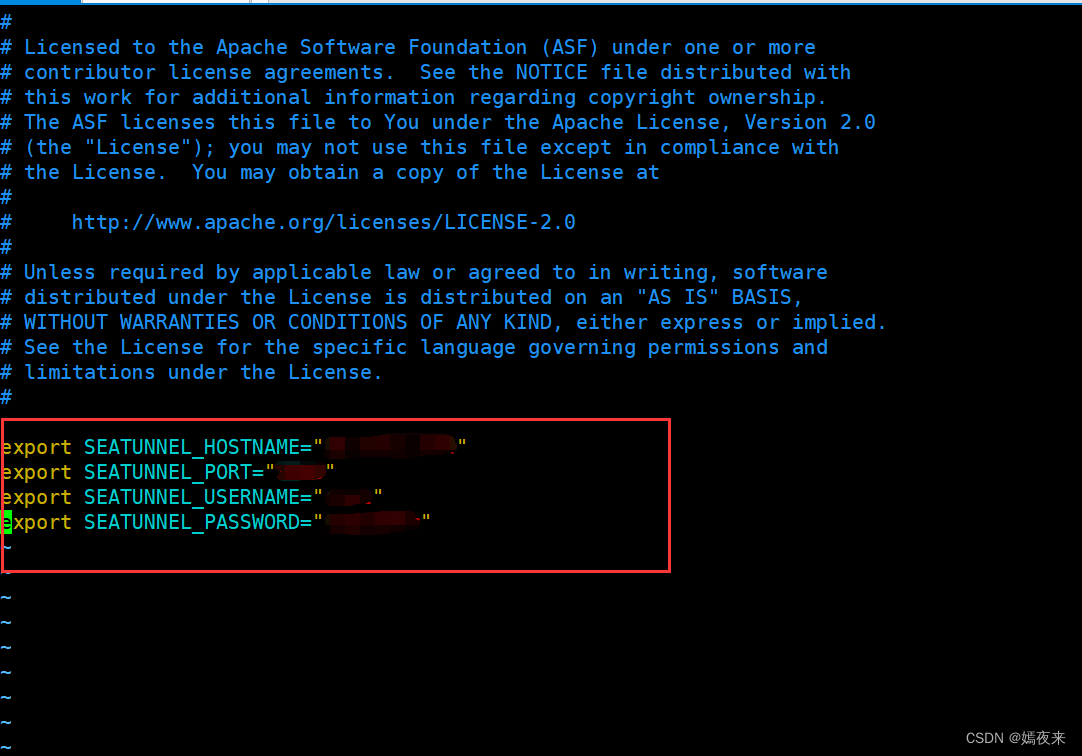
以上截圖中原始文件中配置的是HOSTNAME,PORT,USERNAME,PASSWORD等,但是因為的機器上有全局配置文件也用了這幾個變量名,但是鏈接的數據庫信息和seatunnel連接的數據庫不是一個數據庫, 因為名稱沖突導致在啟動web服務時連接數據哭失敗,
所以我這里修改了seatunnel_server_env.sh和init_sql.sh腳本中的HOSTNAME,PORT,USERNAME,PASSWORD可以加上前綴SEATUNNEL_,變成了
SEATUNNEL_HOSTNAME,SEATUNNEL_PORT,SEATUNNEL_USERNAME,SEATUNNEL_PASSWORD
一定要記住, 如果你按照文檔修改了seatunnel_server_env.sh腳本的變量名, 一定要將init_sql.sh腳本中對應的變量名稱進行同步修改,如下圖:
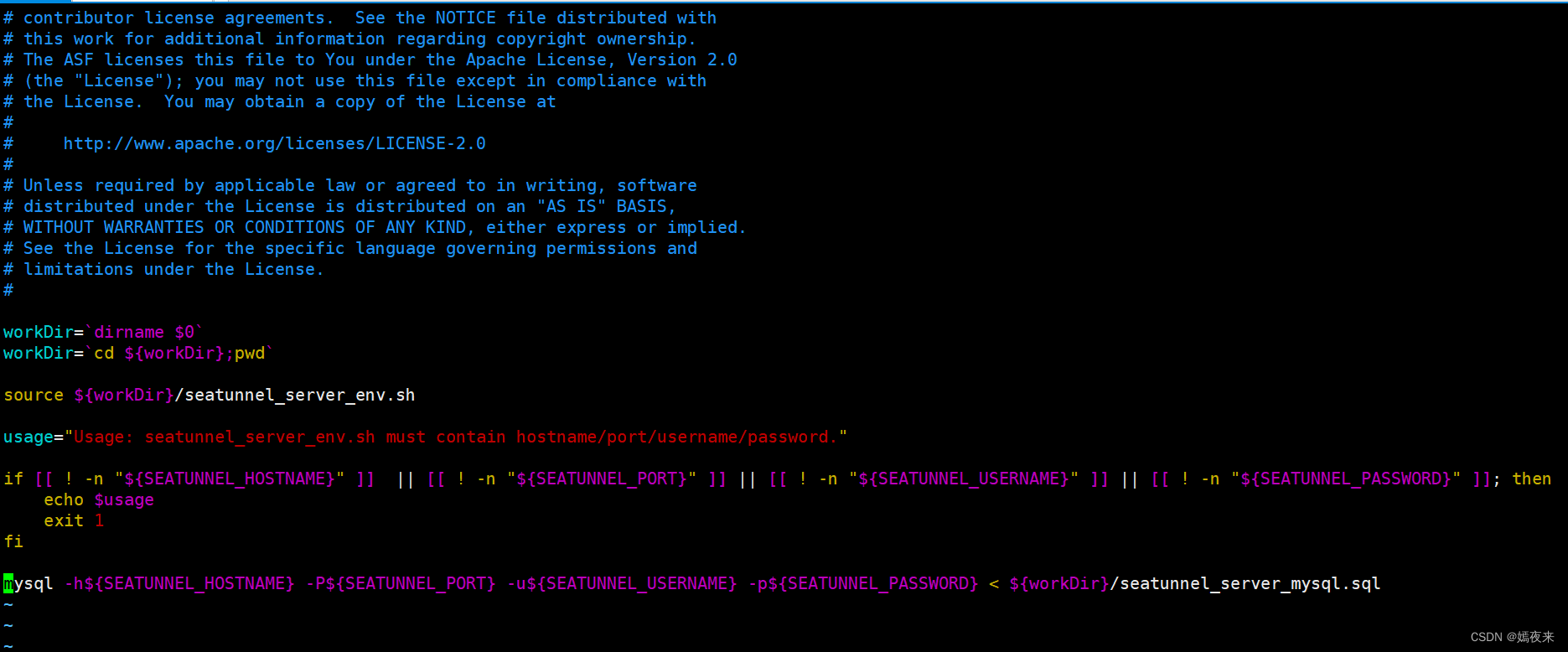

3.2.1.2. 執行初始化數據庫命令
進入seatunnel-web的安裝目錄,然后執行命令sh init_sql.sh,無異常則執行成功。

3.2.2.配置WEB后端服務
3.2.2.1.修改后端基礎配置
web后端服務的配置文件都在${web安裝目錄}/conf下

vim conf/application.yml修改端口號和數據源連接信息
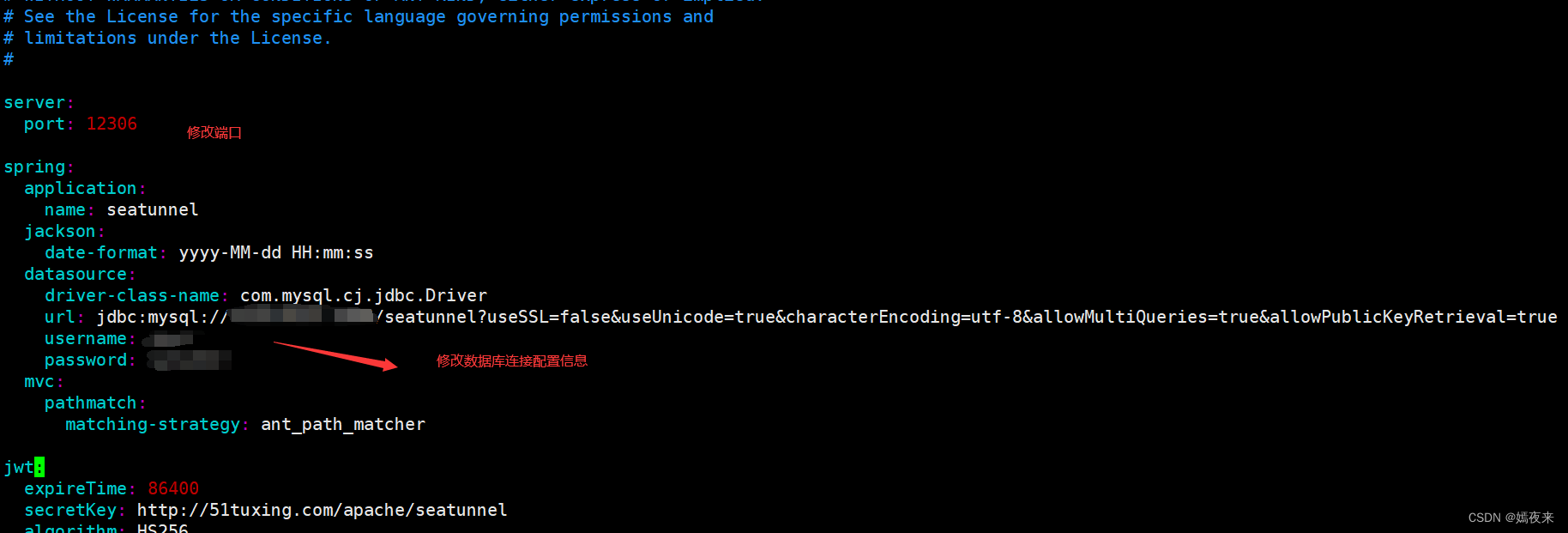
3.2.2.2.配置client信息
將seatunnel引擎服務節點的安裝目錄下的config目錄下的關于引擎客戶端的配置文件拷貝到seatunnel-web安裝目錄下的conf目錄下
同一臺機器下部署直接使用以下拷貝命令(注意修改服務的安裝目錄為你自己的安裝目錄)
sudo cp /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/config/hazelcast-client.yaml /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/conf
如果不在同一臺機器上, 可以使用scp命令或者下載下來然后上傳到web服務的安裝主機的安裝目錄下的conf目錄下即可。
3.2.2.3.配置支持的插件信息
將seatunnel引擎服務節點的安裝目錄下的connectors目錄下的plugin-mapping.properties配置文件拷貝到seatunnel-web安裝目錄下的conf目錄下
sudo cp /opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/connectors/plugin-mapping.properties /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/conf
同一臺機器下部署直接使用以下拷貝命令(注意修改服務的安裝目錄為你自己的安裝目錄)如果不在同一臺機器上, 可以使用scp命令或者下載下來然后上傳到web服務的安裝主機的安裝目錄下的conf目錄下即可。
3.2.3.下載配置數據源JAR包
這一步非常關鍵, 這一步如果沒有配置好, 即使你正常啟動了web應用,可能也會遇到下列問題:
- 數據源類型選擇頁面為空, 我這里因為正常配置, 所以正常顯示

-
沒有Source或者Sink進行選擇
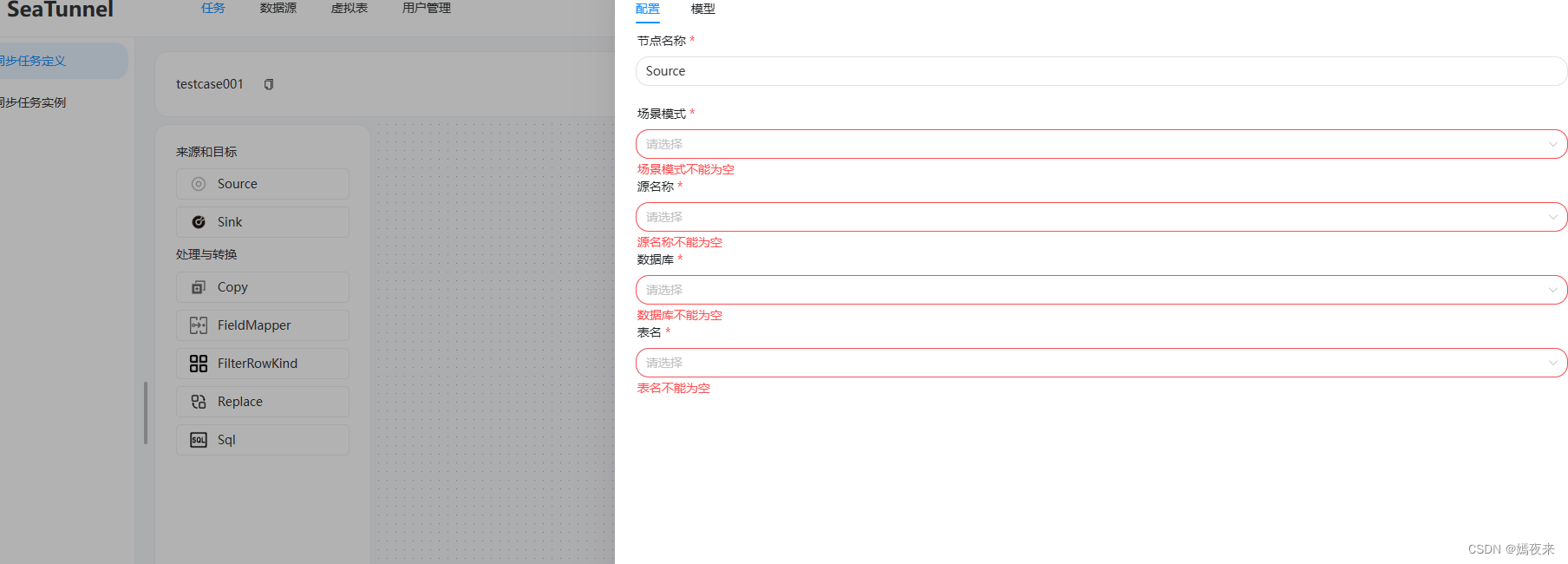
-
任務無法正常執行
3.2.3.1.獲取下載腳本
數據源JAR包的下載腳本在seatunnel-web的源碼包中存在,它的目錄在:
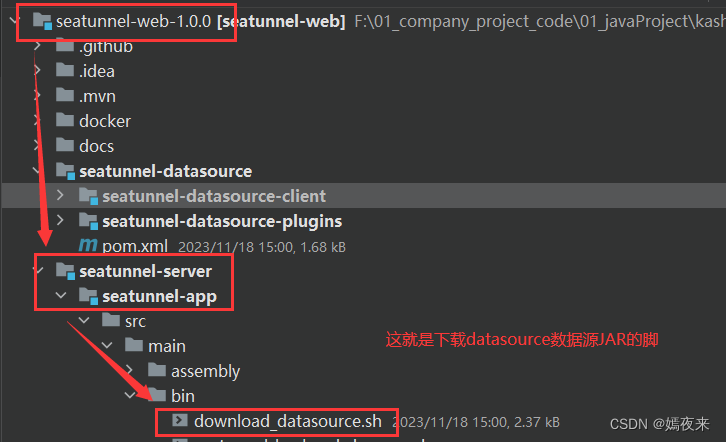
修改配置文件如下:
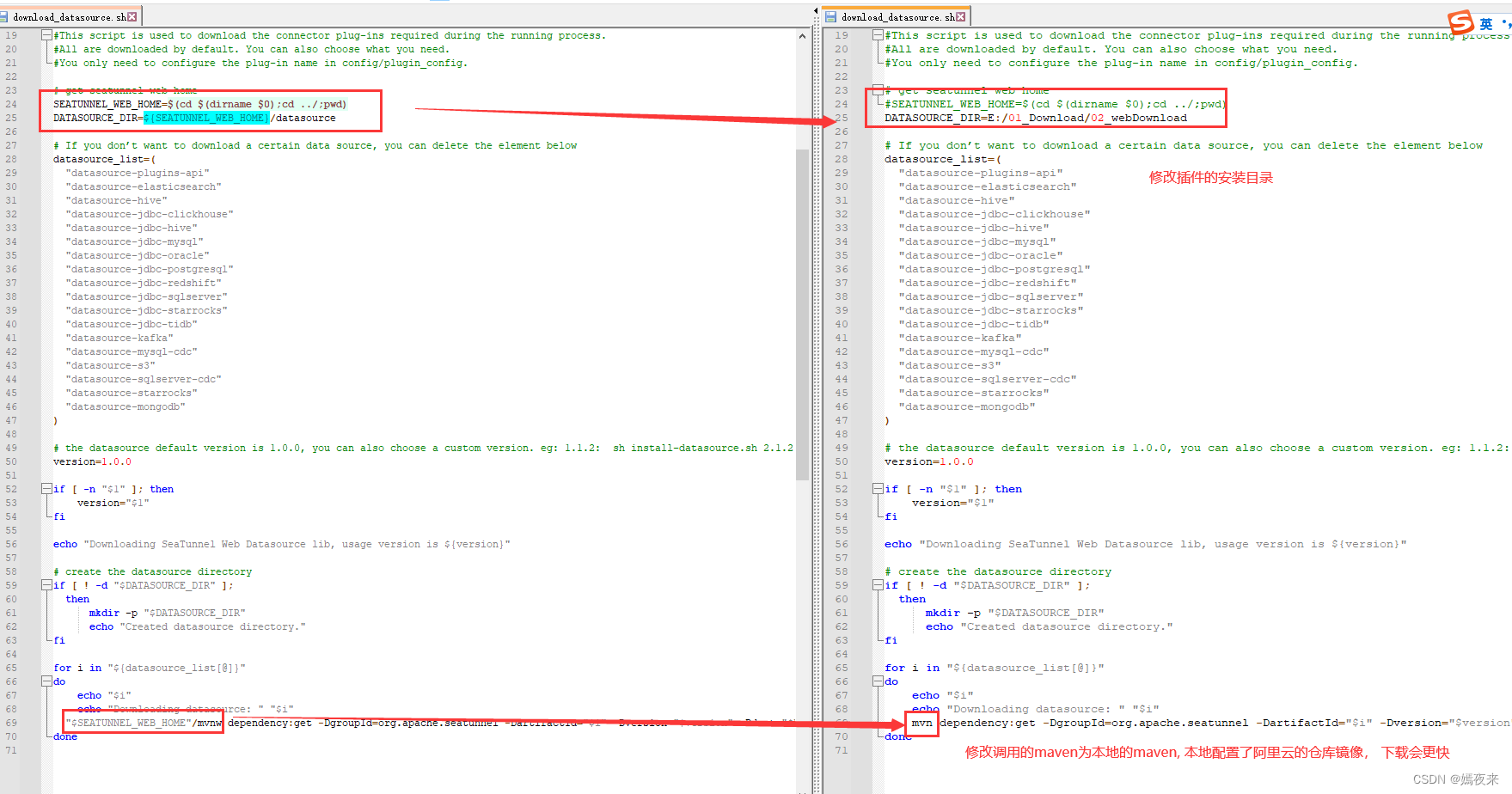
執行腳本,下載數據源JAR包
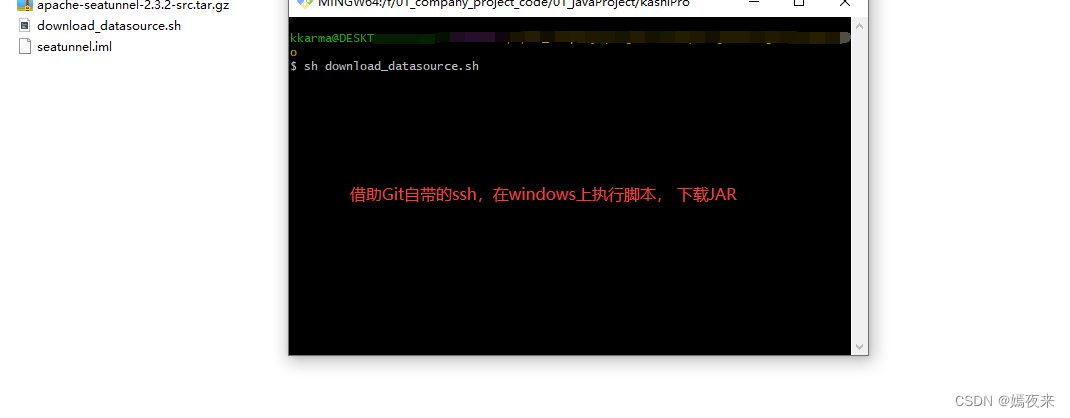
正在下載
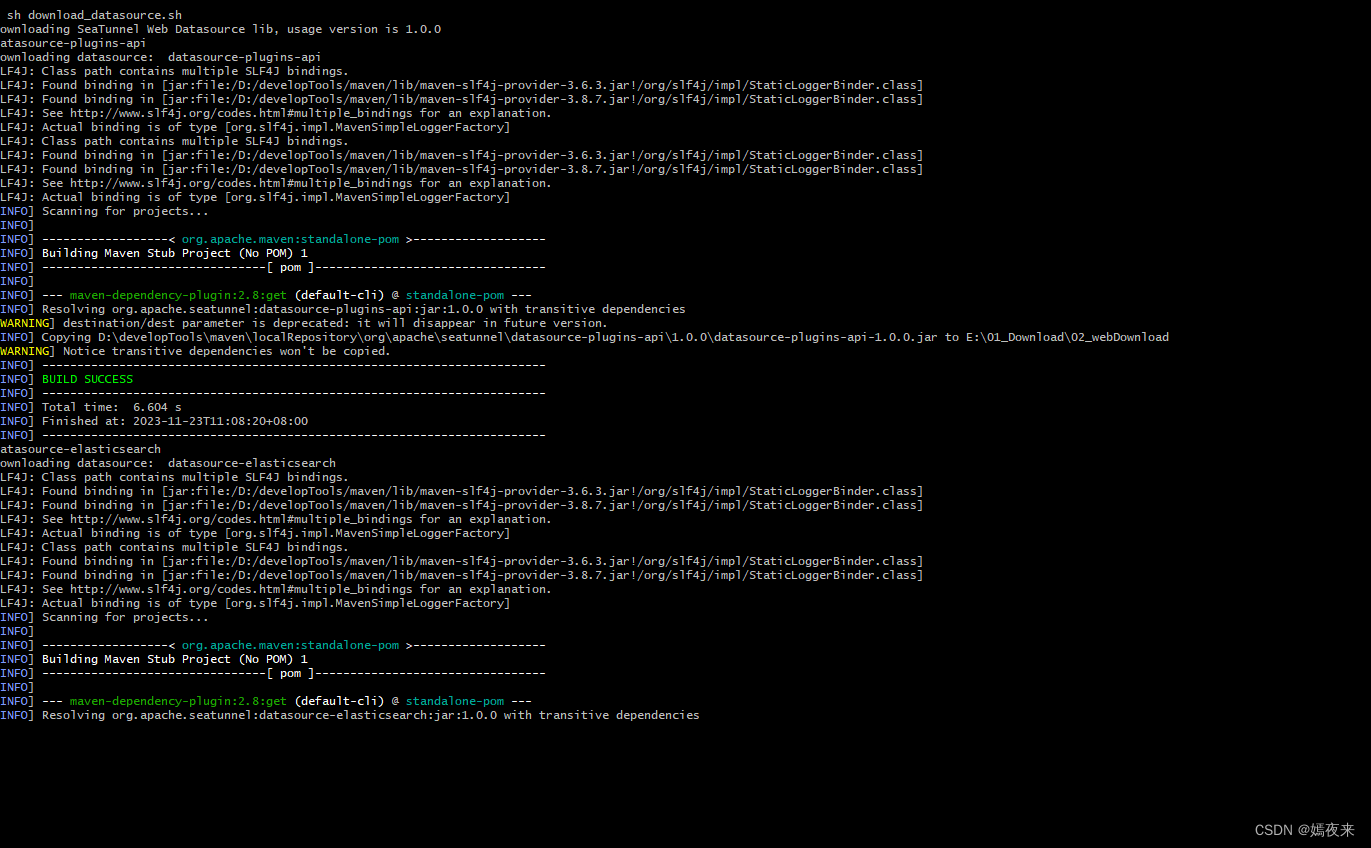
成功下載下所有的datasourceJAR包
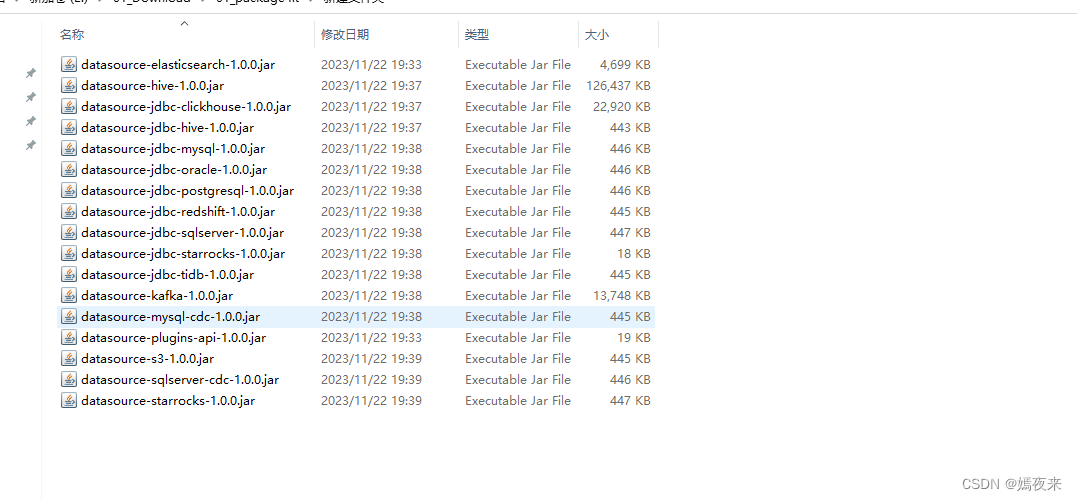
3.2.3.2.上傳到Seatunnel-Web項目的libs目錄
將以上所有jar包復制到/opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0/libs目錄下
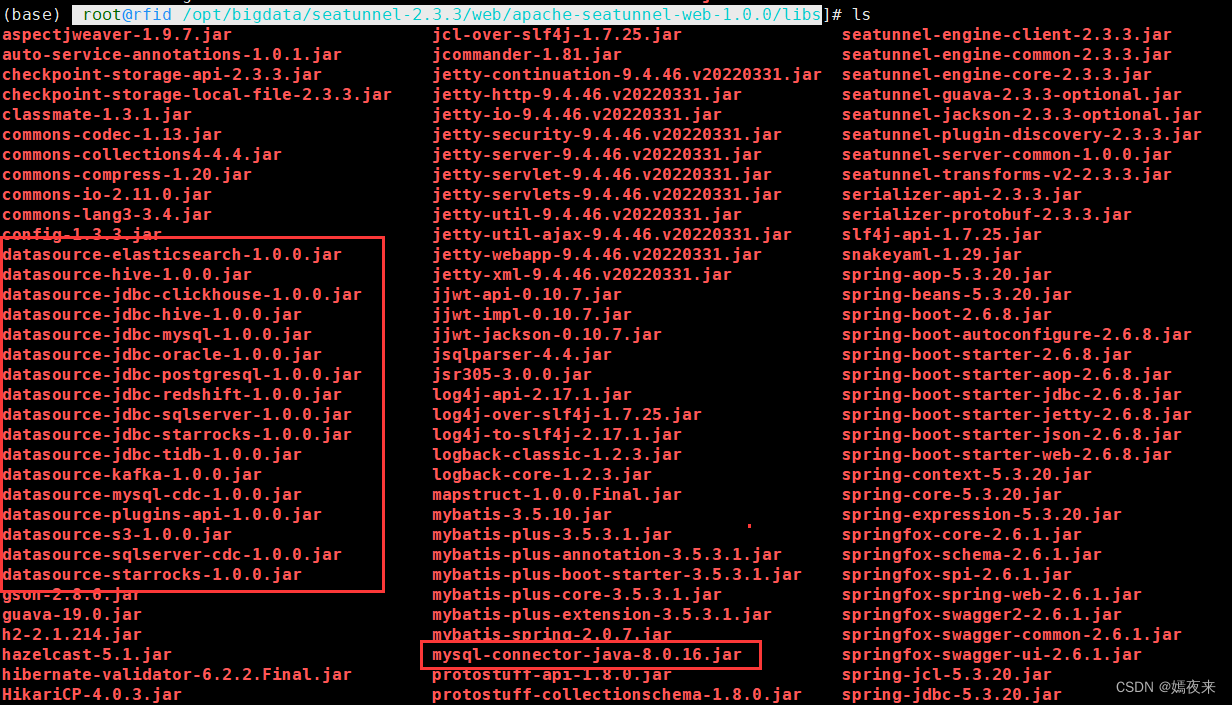
3.2.3.3.上傳到Seatunnel引擎服務的lib目錄
將以上所有jar包復制到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib目錄下
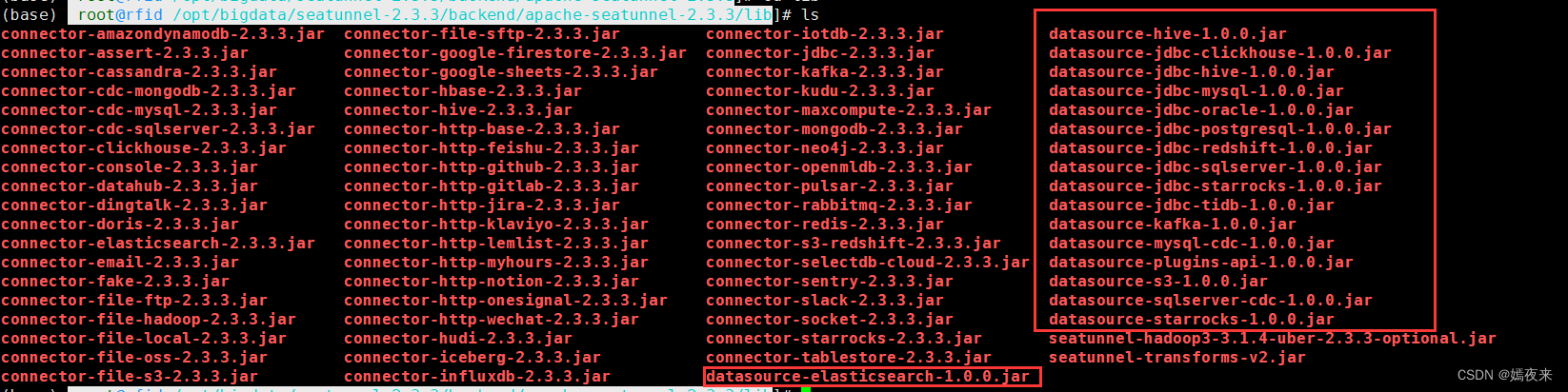
3.2.4.配置元數據MySQL的驅動JAR包
MySQL的驅動包mysql-connector-java-8.0.20.jar自行下載
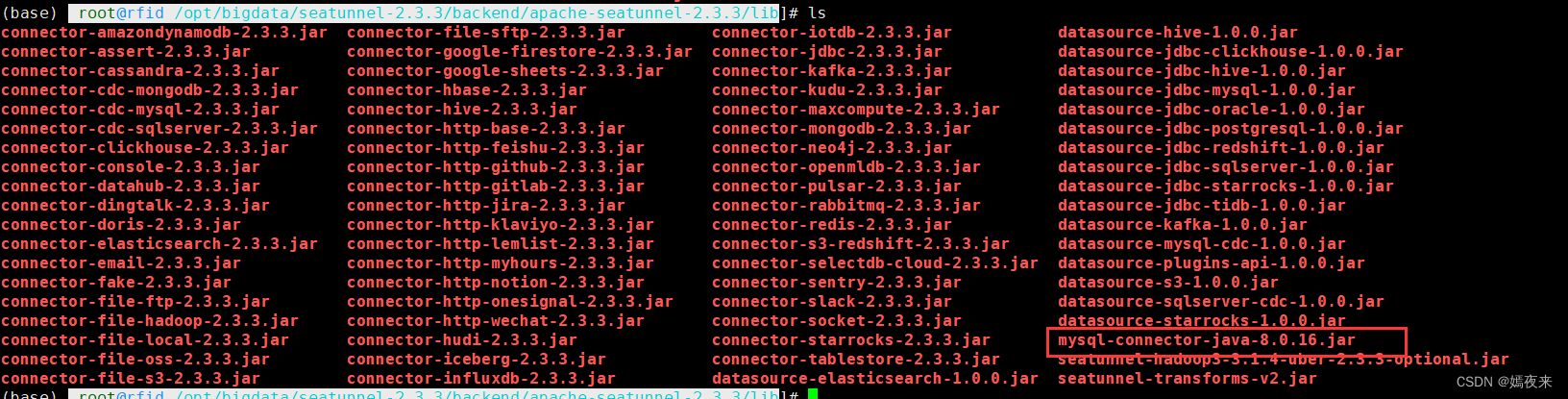
3.2.4.2.上傳到Seatunnel引擎服務的lib目錄
將mysql-connector-java-8.0.20.jar包復制到/opt/bigdata/seatunnel-2.3.3/backend/apache-seatunnel-2.3.3/lib下
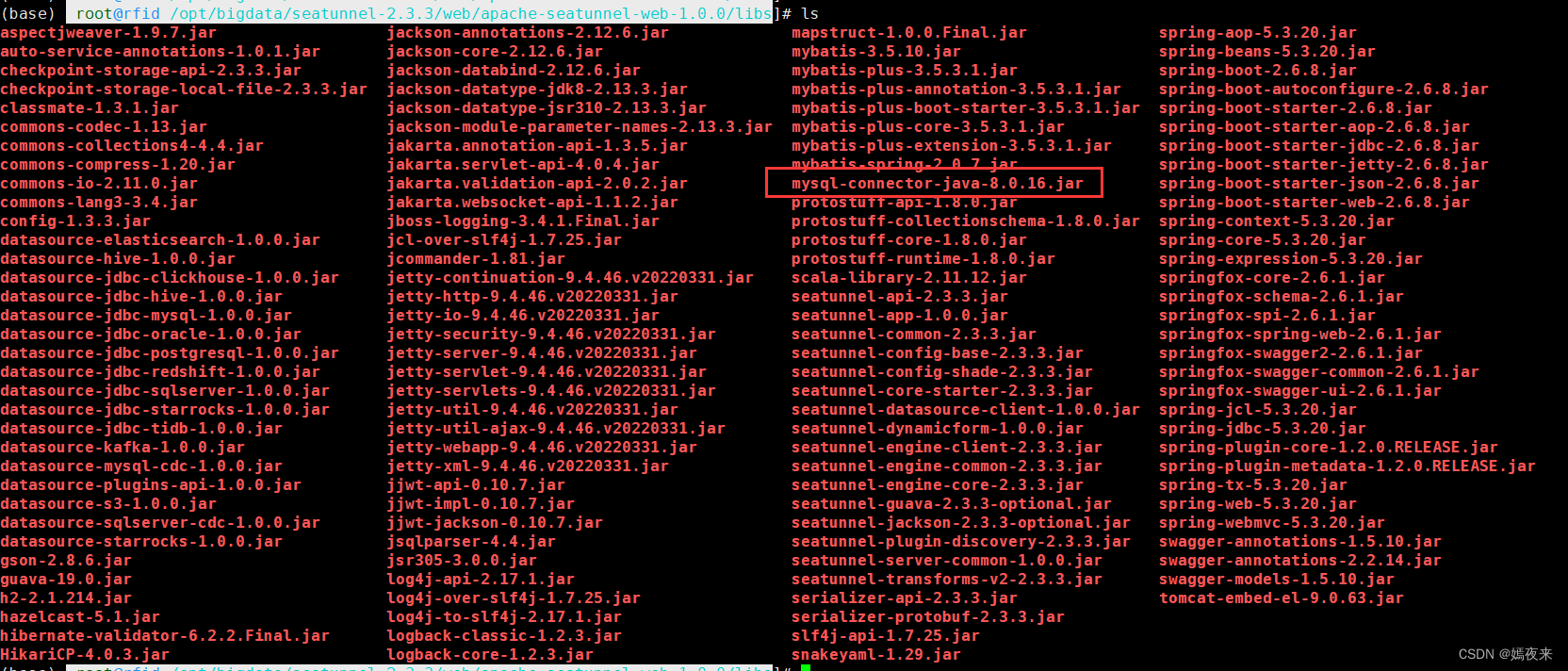
3.2.5.啟動WEB服務
這一步也很容易出錯,很多人都配置對了,但是最后啟動起來,發現無法通過瀏覽訪問, 查看日志打印如下:
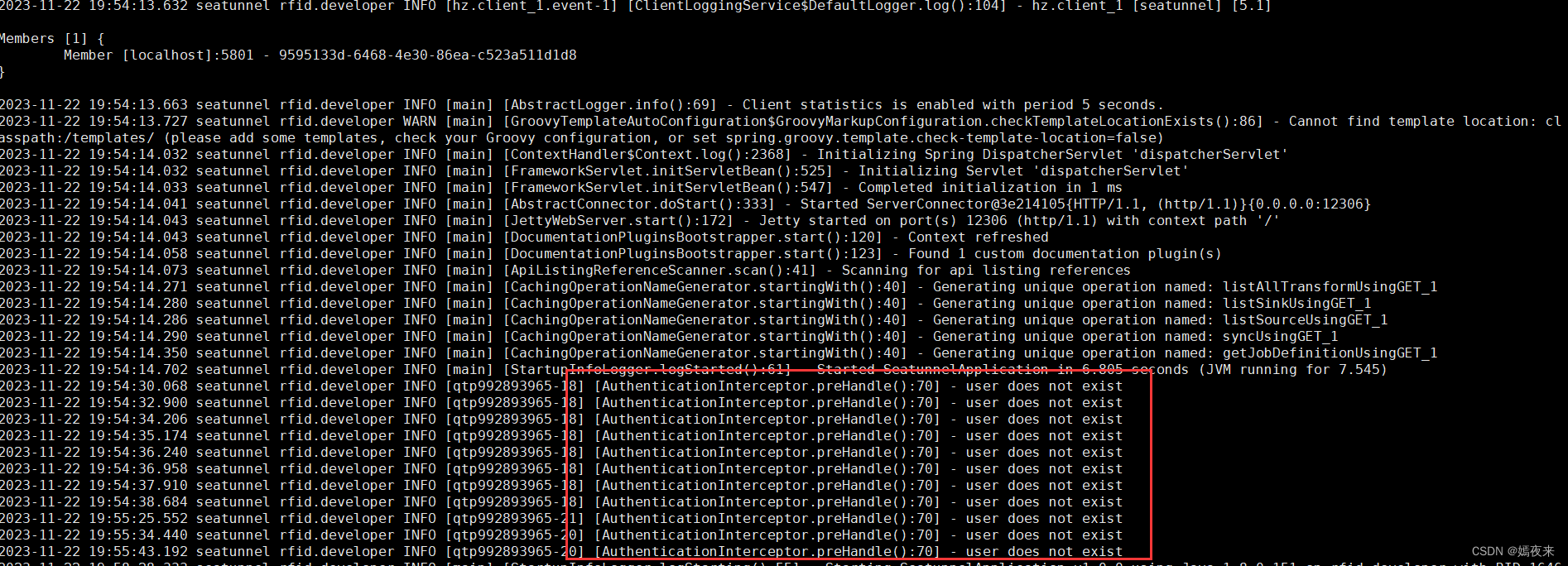
造成這樣的問題就是你執行啟動命令的位置不對, 注意web服務安裝之后的目錄結構如下圖:
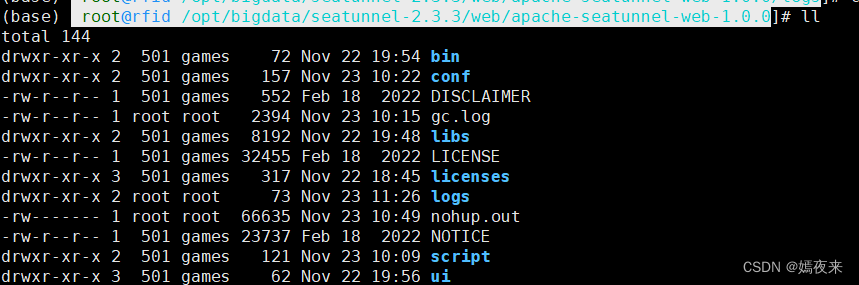
所以啟動服務必須要保證服務可以訪問到ui目錄下的index.html文件才可以,因為項目啟動前端的項目路徑默認添加了/ui的前綴,所以后端項目的啟動路徑必須在ui目錄的父級目錄才可以,所以這里需要再web服務的安裝目錄下執行啟動腳本,舉例:
我這里的安裝目錄是/opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0, 所以我這里直接切換到該目錄下,執行以下啟動命令:
#進入web服務的安裝目錄
cd /opt/bigdata/seatunnel-2.3.3/web/apache-seatunnel-web-1.0.0
#執行啟動腳本
sudo sh bin/seatunnel-backend-daemon.sh start
訪問http://主機IP:12306 (此端口為conf/application.yml中配置的端口), 頁面自動跳轉到http://主機IP:12306/ui,
默認登錄的用戶名和密碼:
username:admin
password:admin
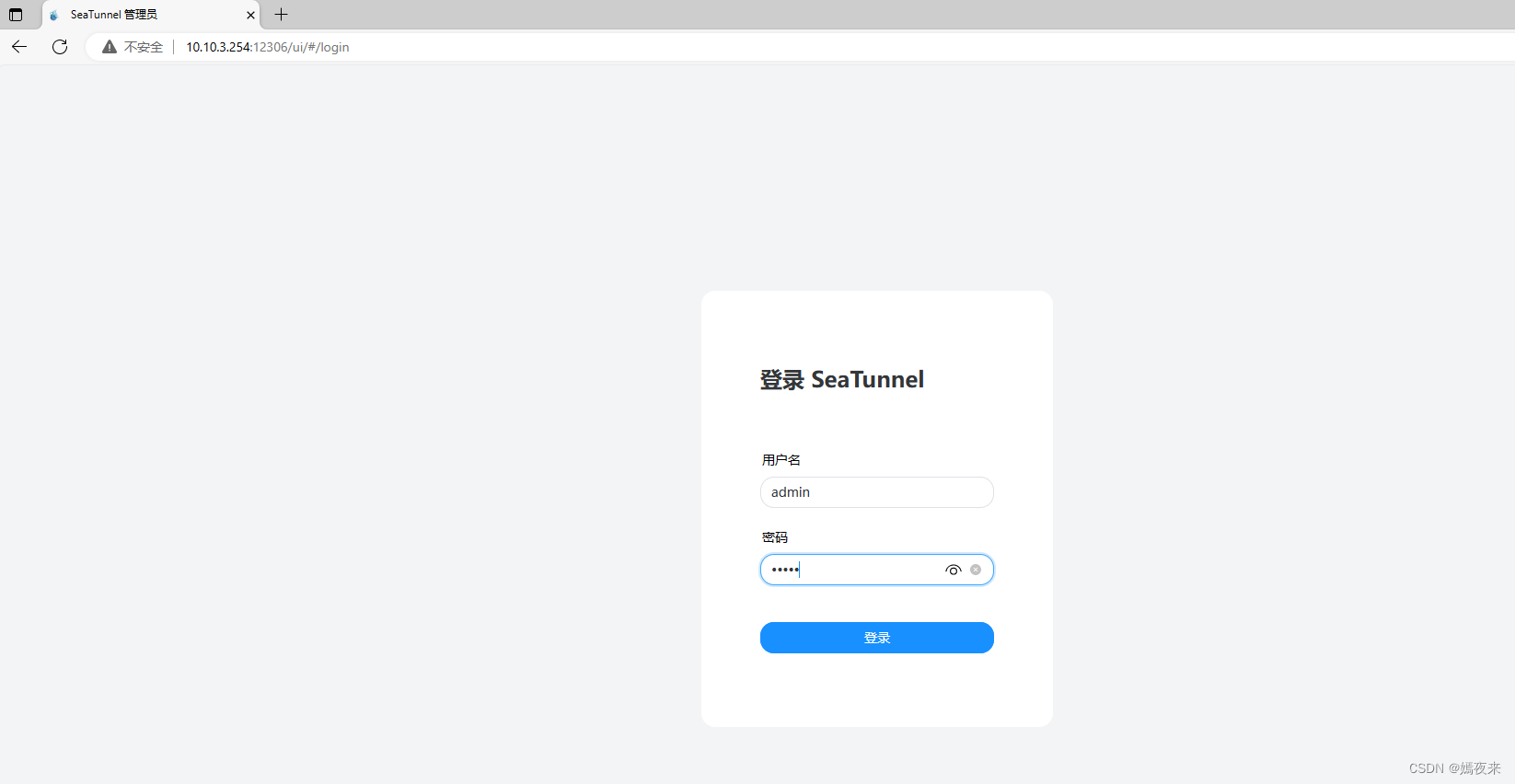
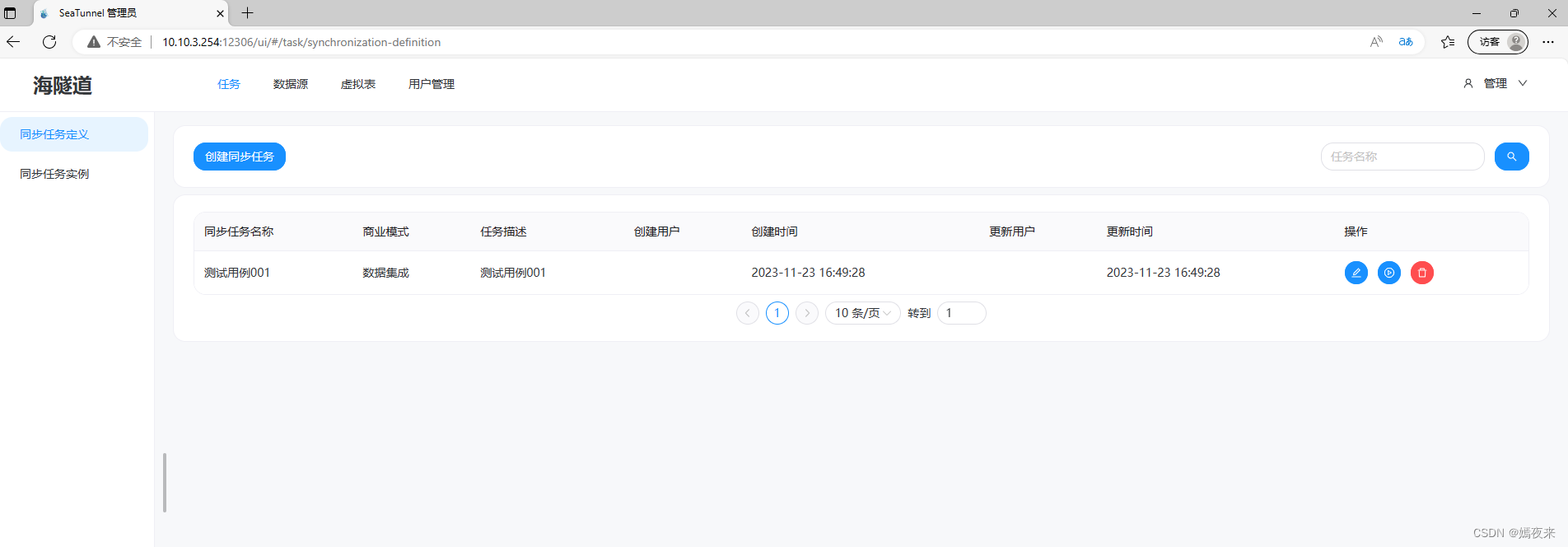
OK, 至此所有的搭建流程就結束了。
4.資源鏈接
這里面有些資源的下載特別慢, 這里將整個配置好的前后端的項目資源打包存放到百度網盤,地址如下:
Seatunnel引擎及Web服務一鍵安裝包
下載下來之后,修改所有涉及數據庫連接的配置文件為你自己的連接配置信息, 然后執行3.2.1.2小節的初始化數據庫命令, 然后依次啟動Seatunnel引擎服務、web服務即可。
創作不易,對您有幫助,點個贊唄,感謝~~~~
)

)



提升子查詢案例分析)



-全面詳解(學習總結---從入門到深化))








