batchsize:中文翻譯為批大小(批尺寸)。
簡單點說,批量大小將決定我們一次訓練的樣本數目。
batch_size將影響到模型的優化程度和速度。
為什么需要有 Batch_Size :
batchsize 的正確選擇是為了在內存效率和內存容量之間尋找最佳平衡。
Batch_Size的取值:
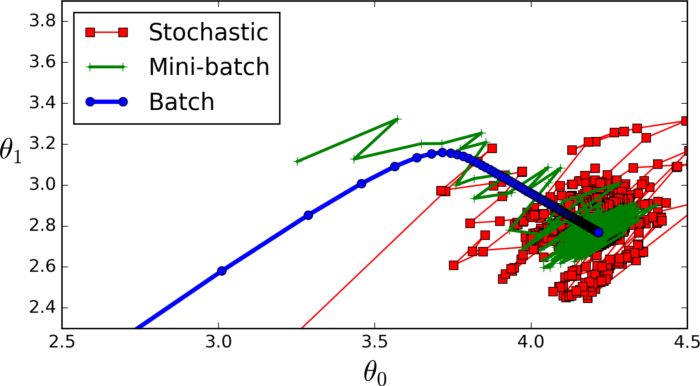
全批次(藍色)
如果數據集比較小我們就采用全數據集。全數據集確定的方向能夠更好地代表樣本總體,從而更準確地朝向極值所在的方向。
注:對于大的數據集我們不能使用全批次,因為會得到更差的結果。
迷你批次(綠色)
選擇一個適中的 Batch_Size 值。就是說我們選定一個batch的大小后,將會以batch的大小將數據輸入深度學習的網絡中,然后計算這個batch的所有樣本的平均損失,即代價函數是所有樣本的平均。
隨機(batch_size等于1的情況)(紅色)
每次修正方向以各自樣本的梯度方向修正,橫沖直撞各自為政,難以達到收斂。
適當的增加Batchsize 的優點:
1.通過并行化提高內存利用率。
2.單次epoch的迭代次數減少,提高運行速度。(單次epoch=(全部訓練樣本/batchsize) / iteration =1)
3.適當的增加Batch_Size,梯度下降方向準確度增加,訓練震動的幅度減小。(看上圖便可知曉)?
經驗總結:
相對于正常數據集,如果Batch_Size過小,訓練數據就會非常難收斂,從而導致underfitting。
增大Batch_Size,相對處理速度加快。
增大Batch_Size,所需內存容量增加(epoch的次數需要增加以達到最好結果)。
這里我們發現上面兩個矛盾的問題,因為當epoch增加以后同樣也會導致耗時增加從而速度下降。因此我們需要尋找最好的batch_size。
再次重申:batchsize 的正確選擇是為了在內存效率和內存容量之間尋找最佳平衡。
Iteration: 中文翻譯為迭代。
迭代是重復反饋的動作,神經網絡中我們希望通過迭代進行多次的訓練以到達所需的目標或結果。
每一次迭代得到的結果都會被作為下一次迭代的初始值。
一個迭代 = 一個正向通過+一個反向通過
epoch:中文翻譯為時期。
一個時期 = 所有訓練樣本的一個正向傳遞和一個反向傳遞。
提升子查詢案例分析)



-全面詳解(學習總結---從入門到深化))














