?
近年來,Transformer模型在自然語言處理(NLP)領域中橫掃千軍,以BERT、GPT為代表的模型屢屢屠榜,目前已經成為了該領域的標準模型。同時,在計算機視覺等領域中,Transformer模型也逐漸得到了重視,越來越多的研究工作開始將這類模型引入到算法中。本文基于2017年Google發表的論文,介紹Transformer模型的原理。
?
一、為什么要引入Transformer?
最早提出的Transformer模型[1]針對的是自然語言翻譯任務。在自然語言翻譯任務中,既需要理解每個單詞的含義,也需要利用單詞的前后順序關系。常用的自然語言模型是循環神經網絡(Recurrent Neural Network,RNN)和卷積神經網絡(Convolutional Neural Network,CNN)。
其中,循環神經網絡模型每次讀入一個單詞,并基于節點當前的隱含狀態和輸入的單詞,更新節點的隱含狀態。從上述過程來看,循環神經網絡在處理一個句子的時候,只能一個單詞一個單詞按順序處理,必須要處理完前邊的單詞才能開始處理后邊的單詞,因此循環神經網絡的計算都是串行化的,模型訓練、模型推理的時間都會比較長。
另一方面,卷積神經網絡把整個句子看成一個1*D維的向量(其中D是每個單詞的特征的維度),通過一維的卷積對句子進行處理。在卷積神經網絡中,通過堆疊卷積層,逐漸增加每一層卷積層的感受野大小,從而實現對上下文的利用。由于卷積神經網絡對句子中的每一塊并不加以區分,可以并行處理句子中的每一塊,因此在計算時,可以很方便地將每一層的計算過程并行化,計算效率高于循環神經網絡。但是卷積神經網絡模型中,為了建立兩個單詞之間的關聯,所需的網絡深度與單詞在句子中的距離正相關,因此通過卷積神經網絡模型學習句子中長距離的關聯關系的難度很大。
Transformer模型的提出就是為了解決上述兩個問題:(1)可以高效計算;(2)可以準確學習到句子中長距離的關聯關系。
?
二、Transformer模型介紹
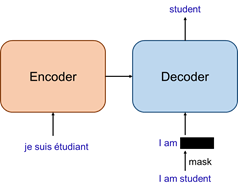
如下圖所示,Transformer模型采用經典的encoder-decoder結構。其中,待翻譯的句子作為encoder的輸入,經過encoder編碼后,再輸入到decoder中;decoder除了接收encoder的輸出外,還需要當前step之前已經得到的輸出單詞;整個模型的最終輸出是翻譯的句子中下一個單詞的概率。
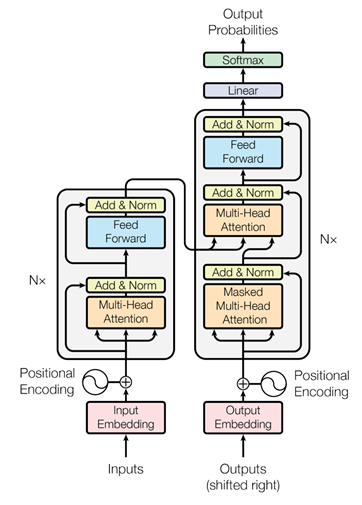
現有方法中,encoder和decoder通常都是通過多層循環神經網絡或卷積實現,而Transformer中則提出了一種新的、完全基于注意力的網絡layer,用來替代現有的模塊,如下圖所示。圖中encoder、decoder的結構類似,都是由一種模塊堆疊N次構成的,但是encoder和decoder中使用的模塊有一定的區別。具體來說,encoder中的基本模塊包含多頭注意力操作(Multi-Head Attention)、多層感知機(Feed Forward)兩部分;decoder中的基本模塊包含2個不同的多頭注意力操作(Masked Multi-Head Attention和Multi-Head Attention)、多層感知機(Feed Forward)三部分。
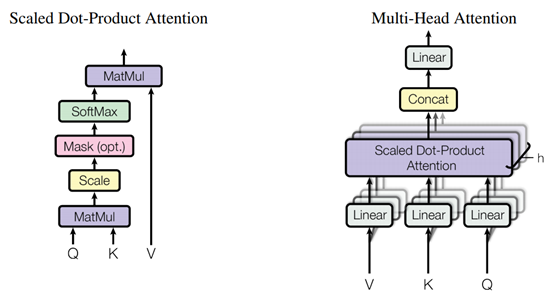
在上述這些操作中,最核心的部分是三種不同的Multi-Head Attention操作,該操作的過程如下圖所示,可以簡單理解為對輸入feature的一種變換,通過特征之間的關系(attention),增強或減弱特征中不同維度的強度。模型中使用的三種注意力模塊如下:
- Encoder中的Multi-Head Attention:encoder中的multi-head attention的輸入只包含編碼器中上一個基本模塊的輸出,使用上一個基本模塊的輸出計算注意力,并調整上一個基本模塊的輸出,因此是一種“自注意力”機制;
- Decoder中的Masked Multi-Head Attention:Transformer中,decoder的輸入是完整的目標句子,為了避免模型利用還沒有處理到的單詞,因此在decoder的基礎模塊中,在“自注意力”機制中加入了mask,從而屏蔽掉不應該被模型利用的信息;
- Decoder中的Multi-Head Attention:decoder中,除了自注意力外,還要利用encoder的輸出信息才能正確進行文本翻譯,因此decoder中相比encoder多使用了一個multi-head attention來融合輸入語句和已經翻譯出來的句子的信息。這個multi-head attention結合使用decoder中前一層“自注意力”的輸出和encoder的輸出計算注意力,然后對encoder的輸出進行變換,以變換后的encoder輸出作為輸出結果,相當于根據當前的翻譯結果和原始的句子來確定后續應該關注的單詞。
除核心的Multi-Head Attention操作外,作者還采用了位置編碼、殘差連接、層歸一化、dropout等操作將輸入、注意力、多層感知機連接起來,從而構成了完整的Transformer模型。通過修改encoder和decoder中堆疊的基本模塊數量、多層感知機節點數、Multi-Head Attention中的head數量等參數,即可得到BERT、GPT-3等不同的模型結構。
?
三、實驗效果
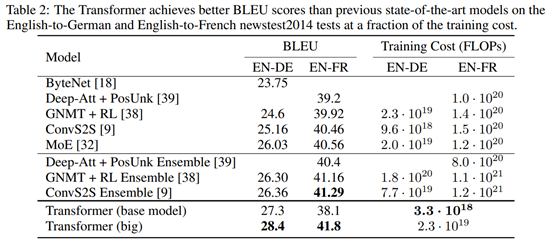
實驗中,作者在newstest2013和newstest2014上訓練模型,并測試了模型在英語-德語、英語-法語之間的翻譯精度。實驗結果顯示,Transformer模型達到了State-of-the-art精度,并且在訓練開銷上比已有方法低一到兩個數量級,展現出了該方法的優越性。
與已有方法的對比實驗,顯示出更高的BLEU得分和更低的計算開銷:
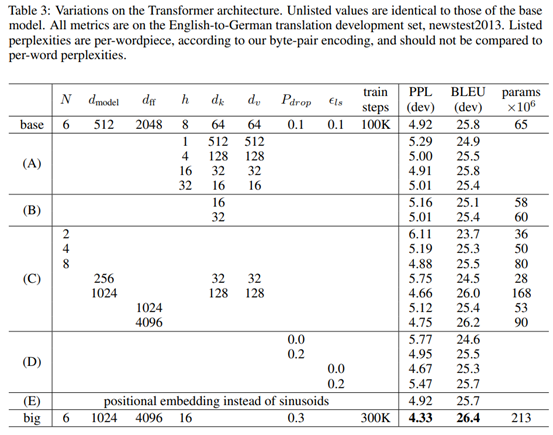
模塊有效性驗證,模型中每個單次的特征維度、多頭注意力中頭的數量、基本模塊堆疊數量等參數對模型的精度有明顯的影響:
參考文獻
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ?ukasz Kaiser, Illia Polosukhin. Attention Is All You Need. NIPS 2017.
?













)





