10月24日程序員節,「大模型數據計算系統」2023拓數派年度技術論壇在上海圓滿落幕,拓數派大模型數據計算系統(PieDataComputingSystem,縮寫:πDataCS)如約而至!πDataCS 以云原生技術重構數據存儲和計算,一份存儲,多引擎數據計算,讓 AI 模型更大更快,全面升級大數據系統至大模型時代。作為 πDataCS 的云存儲底座,簡墨存儲系統的目標是打造滿足各種云場景下的高性能計算系統的數據管理和存儲底座。
1 πDataCS:一份數據存儲,多引擎數據計算
πDataCS 旨在助力企業優化計算瓶頸,充分利用和發揮數據規模優勢,構建核心技術壁壘,更好地賦能業務發展,使得自主可控的大模型數據計算系統保持全球領先,讓大模型技術全面賦能各行各業。
計算平臺從大型機、PC 機到如今的云平臺經歷了三代大的變更。云平臺代表了目前最大的計算能力、存儲能力和水平擴展能力。在 PC 機年代,元數據和用戶數據映射在本地硬盤,計算映射在本地 CPU,存儲和計算緊密耦合在同一個服務器上。
πDataCS 以云原生技術重構數據存儲和計算,先將數據計算系統中的計算和數據分離,增強系統的彈性。接著,考慮到未來數據治理和交易,拓數派把元數據和用戶數據再次分離,實現了全新的 eMPP 架構。元數據被映射到塊存儲,由元數據管理系統「木牘」進行管理;用戶數據被映射到對象存儲,由「簡墨」存儲系統來管理;計算被映射到容器或者虛擬機,由計算系統來管理。
πDataCS 通過 Data Mesh,升級數據治理,實現數據價值。πDataCS 深入考慮了全球數據交易和數據治理的要求。數據作為一種新的生產要素,是模型發展的重要燃料。在隱私和安全的前提條件下,數據所有者可以把含數據目錄的元數據對其他用戶共享,數據經營者通過元數據來訪問所有者的用戶數據,并根據需要,通過授權來有償訪問所有者的用戶數據。數據經營者在訪問所有者的數據的時候,需要調用數據加工者提供的數據計算引擎。
πDataCS 的整體架構被分為四層,如下圖所示:

最上層是 πDataCS 所支持的計算引擎。目前 πDataCS 支持以下幾種計算引擎:
- PieCloudDB:作為拓數派首款云原生數倉計算引擎,支持 SQL 語言模型,兼容 HTAP
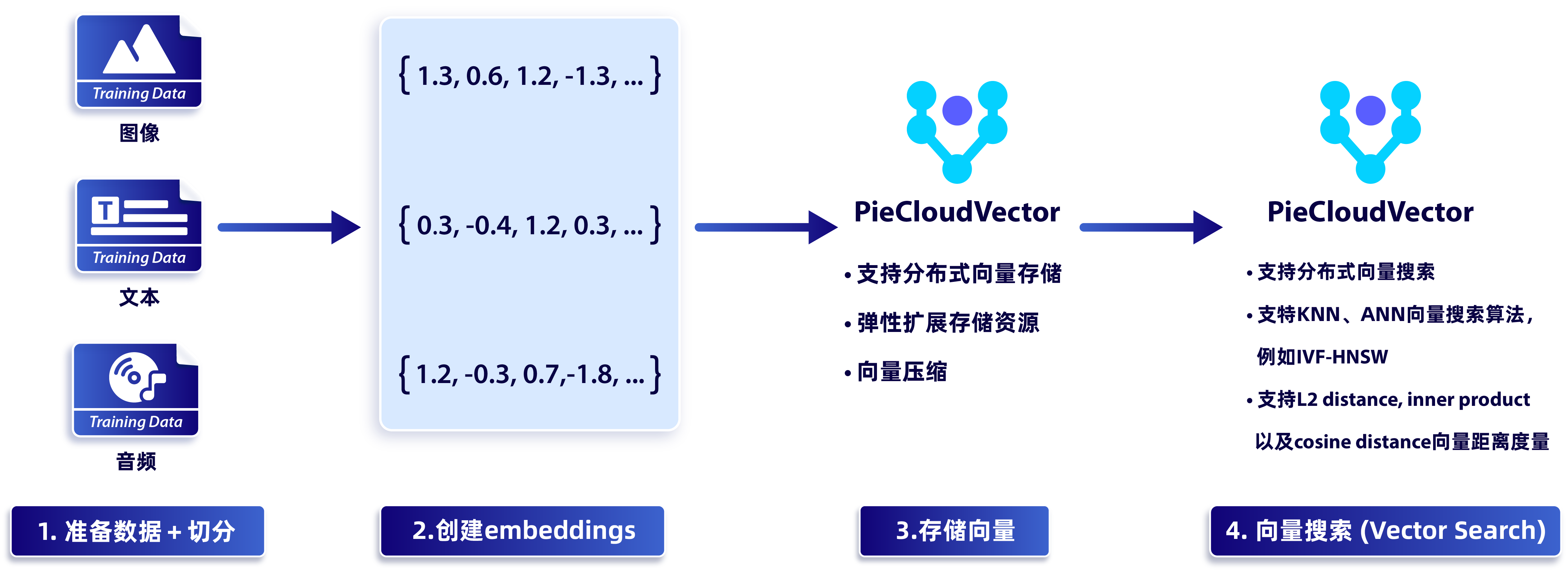
- PieCloudVector:為支持和大模型配合的向量計算而建立的云原生向量計算引擎
- PieCloudML:為支持 Python 和 R 等機器學習語言而建立的云原生機器學習引擎
1.1 PieCloudDB:首款云原生數倉計算引擎
作為 πDataCS 的首款計算引擎,PieCloudDB 云原生虛擬數倉全面支持 πDataCS 公有云版、社區版、企業版及一體機多個產品版本,提供公有云、私有云以及裸硬件三種部署方式,通過數倉虛擬化技術,幫助企業打破數據孤島,整合所有結構化數據資源,輕松應對強邏輯計算。
云原生存算分離架構運用元數據-計算-數據分離的三層架構,實現云上存儲資源與計算資源的獨立管理。在云上,PieCloudDB database 利用 eMPP(elastic Massive Parallel Processing)專利技術,實現多集群并發執行任務。企業可靈活進行擴縮容,隨著負載的變化實現高效的伸縮,輕松應對 PB 級海量數據。
1.2 PieCloudVector:云原生向量計算引擎
向量數據庫是一種專門用于存儲、查詢和分析向量數據(比如特征向量)的數據庫系統。
在對比了 pgvector,pgembedding 的實現和性能之后,我們并沒有使用開源的實現,而是完全獨立自研了 PieCloudVector 以使其滿足我們用戶的使用場景。PieCloudVector 具備高效存儲和檢索向量數據、相似性搜索、向量索引、向量聚類和分類、高性能并行計算、強大可擴展性和容錯性等功能。
1.3 PieCloudML:云原生機器學習引擎
然而隨著人工智能的日益發展,未來越來越多的經濟活動將由 AI 來推動。πDataCS 中建立了云原生機器學習引擎 PieCloudML,通過 PieCloudML 內置的各種 ML、圖和大模型的算法,數據科學家可通過 python/R 等熟悉的方式,利用數據計算系統來完成各項任務,生成所需的模型。
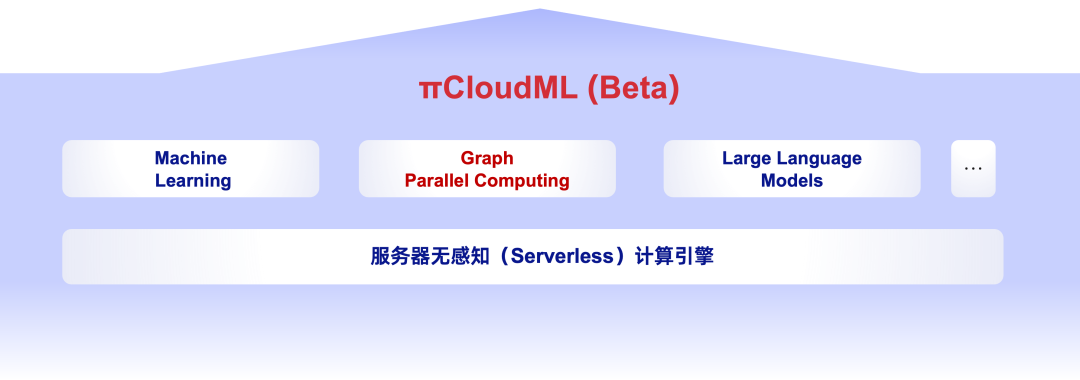
為了加速大數據處理和計算的性能,πDataCS 中充分依賴新的硬件來進行異步計算,例如 GPU、FPGA 等。并通過統一的元數據管理層 ——「木牘」,讓這三大計算引擎共享一個數據存儲底座 ——「簡墨」,實現一份數據,多引擎計算。
接下來我們將詳細介紹簡墨,這款大數據計算系統的云存儲底座。
2 簡墨:大數據計算系統的云存儲底座
作為 πDataCS 的云存儲底座,簡墨存儲系統的目標是打造滿足各種云場景下的高性能計算系統的數據管理和存儲底座。簡墨將基于現代化的硬件和設施,充分使用云的潛力,絕對的數據安全保證,致力于簡化大數據處理過程中的數據加載、讀取和計算的整個流程,并提供對數據的自適應治理、ACID 的事務支持等功能,保證絕對的數據安全,做到極致的性能優化,以完成各種場景下的數據計算和分析任務。
為了實現這一目標,簡墨的進化主要經歷三大階段:
- 階段一:新一代云原生存儲
- 階段二:大數據計算系統的云存儲底座
- 階段三:統一的大數據計算系統存儲引擎
2.1 進化階段一:新一代云原生存儲
第一階段的簡墨主要作為云原生虛擬數倉 PieCloudDB 的云原生存儲,目前研發工作已完成。
簡墨基于不同的云環境兼容公有云、私有云和混合云,使用對象存儲作為持久化存儲層,并充分考慮到了 eMPP(elastic MPP)架構下的數據分布和彈性,使用一致性哈希(hash)來保證分布式環境中的每個節點訪問大致相同的數據,即使擴縮容也可以盡可能的減少實現的緩存數量。簡墨充分考慮到了數據的安全性,結合云原生虛擬數倉 PieCloudDB 中的透明加密在存儲落盤時即完成對數據進行加密。透明加密使用了三級密鑰,保證了數據的絕對安全。此外,簡墨也針對讀寫性能進行了大量優化,大大提升了數據加載和查詢的效率。
2.1.1 全新的文件格式:janm
「簡墨」新一代云原生存儲圍繞 janm 文件格式打造。janm 文件格式使用了行列混合存儲設計。行列混合存儲讓系統在重組數據時,既具備了行存所具有的高效性能,又具備了列存的高壓縮比、cache line 友好等優勢。同時,jamn 文件格式也能支持向量化(SIMD)計算和并行計算。在設計時,簡墨也充分考慮到了內外存的存儲表達方式,重新定義了數據在磁盤和內存中的表數據格式,使表中的數據在磁盤上和內存中的數據轉換沒有額外的開銷。
在文件格式內,簡墨也會收集文件內數據統計信息來加速查詢,支持預計算等性能優化特性。為了加速 I/O,janm 文件格式內置多種壓縮算法,例如 zstd、lz 等。針對不同的類型,簡墨可以自適應選擇不同的編碼方式,包括 delta encoding、dictionary encoding 等。
通過塊(block)文件級別的 MVCC,使簡墨具備完整的事務支持。每個文件塊中的數據是否可見,簡墨將通過其所在文件的 MVCC 信息,根據當前的事務隔離級別來判斷。在 PieCloudDB 中,簡墨對訪問層進行了深度定制,以確保 PieCloudDB 充分使用簡墨中提供的各項優化。
目前,簡墨針對數據的讀取與查詢進行了大量優化,實現了包括數據裁剪(Data Skipping)、預計算加速聚集查詢、Smart Analyze、TOAST 的支持等眾多功能:
-
數據裁減:在查詢時,依據查詢條件盡可能減少要讀取的數據量,以達到節省 I/O,提升查詢性能的效果。
-
預計算:對于聚集查詢,當簡墨收集到每個數據塊的聚集數據時,可之間通過使用該數據庫的數據來加速數據聚集計算
-
Smart Analyze:通常來說,查詢優化器通過對整個表進行 analyze 收集來的表的數據分布信息來生成查詢執行計劃。對于分析場景來說,當數據量過大時,通過普通 analyze 收集來的表數據分布信息有較大誤差,導致產生較差的執行計劃。Smart Analyze 通過加載數據時計算每個數據塊的分布信息,再通過 merge 算法合并全部數據塊的統計信息來生成較為準確的表數據分布信息,其根本思想是在不影響性能的情況下盡可能多的對用戶數據進行采樣。
-
超大字段存儲的支持:簡墨對超大字段存儲的支持早已實現基本的讀寫操作。在全新版本中,PieCloudDB JAMN 已進一步優化,全面支持超大字段存儲的 UPDATE/DELETE 和 VACUUM 功能。
…
隨著這一階段的完成,結合 πDataCS 的需求,研發團隊對簡墨進行了第二階段的設計和實現,目標是將簡墨成為大數據計算系統的云存儲底座。
2.2 進化階段二:大數據計算系統的云存儲底座
在這一階段,簡墨將作為 πDataCS 的云存儲底座,目標是能夠真正做到「一份數據,多引擎計算」,相應的研發工作正在進行中。
為實現這一目標,簡墨計劃實現以下特性:
- 更多文件格式的支持
- 數據互通
- 更高效的外部數據提取和加載
- 流式數據處理
- 高性能的 ACID 事務處理
- 自適應數據管理
- CDC 場景的支持
- 更多云原生的 Index 支持
…
下圖詳細繪制了簡墨表格式(JANM Table Format)的所有層級,其中每個層級都依賴于其下面一層,并從中汲取所需的能力,用戶將數據以對應的文件格式存儲在極具擴展性的云存儲中來為上層計算提供數據。

2.2.1 存儲訪問抽象(Storage Access Abstract)層
最底層的是簡墨的存儲訪問抽象層,簡墨利用抽象 API 與任何類型的存儲進行交互,包括云對象存儲(例如 S3)、HDFS 等。通過這種方式,簡墨確保了所有存儲引擎的兼容性。此外,簡墨對文件系統進行了包裝,以進一步優化存儲功能,例如提供監控和各種讀寫策略等。
2.2.2 數據文件格式抽象(File Format Abstract)層
簡墨會在這一層支持多種文件格式,并具備統一的訪問接口來簡化對數據的訪問操作,從而讓用戶的數據可自由的選擇不同的文件格式來存儲,用戶數據。同時,在更高的層面上,簡墨獨特的文件布局方案涉及將對每個文件的所有更改進行記錄,這使簡墨能夠創建一個獨立的 redo 日志,可用于實現更多豐富的功能。
2.2.3 表格式(Table Format)的核心層
表格式的核心層提供各項特性的功能封裝和實現。核心層包括以下5個子系統:
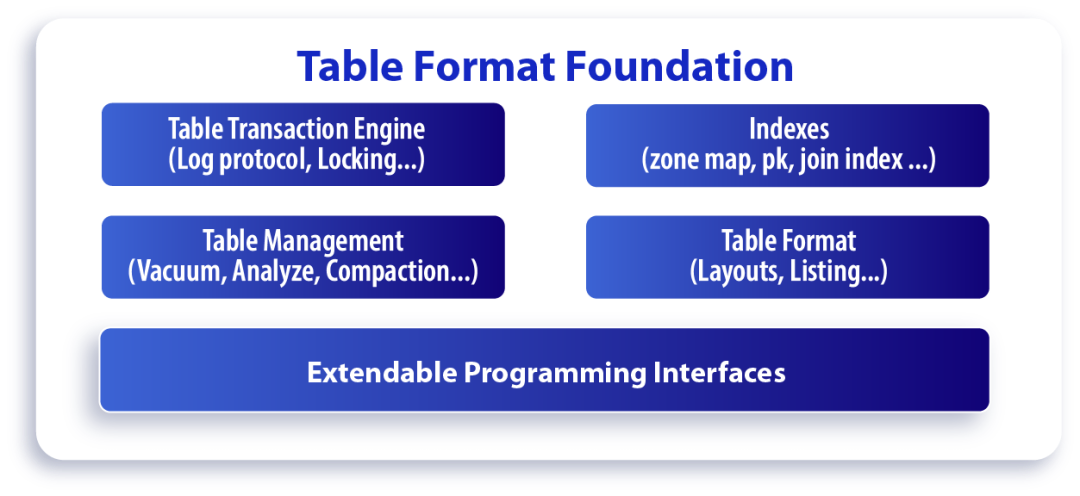
- 表的事務引擎(Table Transaction Engine)
核心層包含有表的事務引擎,實現了文件級別 MVCC,支持根據隔離級別進行數據庫的可見性判斷,保證一定的并發控制。對于事物保證,簡墨的基本思路是日志即數據,該數據指的是事務可見性信息。
- 索引(Index)
索引可幫助數據庫規劃更好的查詢,減少 I/O 總量并提供更快的響應時間。有關文件列表和列的索引信息在 OLAP(分析型)場景下,足以讓 OLAP 引擎快速生成高效的查詢計劃。目前 janm 中支持數據裁剪(Data Skipping)所需的索引,未來我們將持續探索更多的索引實現,甚至是行級索引。
- 表數據的自適應管理(Table Management)
簡墨所支持的表數據的自適應管理功能,主要包含:
? VACCUM:數據清理,回收操作留下的垃圾空間
? Smart Analyze:數據分布信息采樣
? Compaction:將小文件進行合并,提升 I/O 效率
? Cluster:將相近的數據盡可能聚集在相同文件,以提升數據裁減的效率,提升查詢速度
? Sort:根據指定的字段或條件對數據排序
…
- 表格式的相關操作和控制的封裝
在這一層,簡墨會支持對表的組成和布局控制,支持表文件的遍歷,和表數據大小的統計等功能的封裝。在對象存儲中,對文件進行 list 是開銷很大的操作,簡墨通過表格式層提供的功能來進行快速的文件遍歷和數據大小統計。
2.2.4 可擴展的編程接口
針對上層接口,簡墨提供了統一的 API 與外部服務交互,方便第三方應用的接入。簡墨支持擴展服務的不同實現,而無需額外的應用開發,節省用戶成本工作量。提供數據訪問的入口,提供了表的訪問服務,基于快照的操作,以及包括 Time Travel 在內的豐富功能。

針對表的應用服務,簡墨提供了無狀態數據管理的應用,可注冊到任意服務中,從而實現自適應數據管理。
在第二階段完成后,拓數派「簡墨」計劃擁抱開源,實現數據在不同服務之間的真正互通,全面支持包括 Spark,Clickhouse 在內的眾多服務,實現一份數據,多引擎計算。
2.3 進化階段三:統一的大數據計算系統存儲引擎(展望)
未來,在演進的第三階段,簡墨期待打造成為一款統一的大數據計算系統存儲引擎。打造統一的訪問協議,將表格式、數據湖、表引擎等統一到協議下,簡化用戶的訪問操作。希望大家能持續關注簡墨的進展!






)










Java+ssm+MYSQL酒店大數據資源管理系統的設計與實現02029)



